
Go позволяет писать на ассемблере. Но авторы языка написали такую стандартную библиотеку, что бы этого делать не пришлось. Есть способы писать переносимый и быстрый код одновремено. Как? Добро пожаловат под cut.
Начать писать писать функции в на ассемблере в go очень просто. Для примера, объявим(forward declaration) функцию
Add, которая складывает 2 int64:
func Add(a int64, b int64) int64
Это обычная функция, то тело функции отсутствует. Компилятор будет обосновано ругаться при попытке собрать пакет.
% go build
examples/asm
./decl.go:4:6: missing function body
Добавим файл с расширением .s и реализуем функцию на ассемблере.
TEXT ·Add(SB),$0-24
MOVQ a+0(FP), AX
ADDQ b+8(FP), AX
MOVQ AX, ret+16(FP)
RET
Теперь можно собрать, протестировать и использовать Add как обычную функцию. Этим широко пользуются сами разработчики языка в пакетах runtime, math, bytealg, syscall, reflect, crypto. Это позволяет использовать аппаратные оптимизации процессора и команды, не представленные в языке.Но есть проблема — функции на asm не могут быть оптимизированы и встроены(inline). Без этого накладные расходы могут быть непозволительно большими.
var Result int64
func BenchmarkAddNative(b *testing.B) {
var r int64
for i := 0; i < b.N; i++ {
r = int64(i) + int64(i)
}
Result = r
}
func BenchmarkAddAsm(b *testing.B) {
var r int64
for i := 0; i < b.N; i++ {
r = Add(int64(i), int64(i))
}
Result = r
}
BenchmarkAddNative-8 1000000000 0.300 ns/op
BenchmarkAddAsm-8 606165915 1.930 ns/op
Было несколько предложений для inline асемблера, как директива asm(...) в gcc. Ни оно из них не было принято. В место этого, в go добавили встаиваемые(intrinsic) функции.Встраиваемые функции go написаны на обычном go. Но компилятору известно, что их можно заменить на что-то более оптимальное. В Go 1.13 встраиваемые функции содержатся в
math/bits и sync/atomic.Функции в этих пакетах имеют причудливые сигнатуры. Фактически они повторяют сигнатуры процессорных комманд. Это позволяет компилятору, если целевая архитектура поддерживает, прозрачно заменять вызовы функции на ассемблерные инструкции.
Ниже хочу рассказать о двух разных путях, которыми компилятор go создаёт более эффективный код с использовнием встроенных функций.
Population count
это количество единиц в двоичном представлении числа — важный криптографический примитив. Так как это важная операция, большинство современных cpu предосталяют реализацию в железе.
Пакет
math/bits предоставляет эту операцию в функциях OnesCount*. Они распознаются и заменяются на инструкцию процессора POPCNT.Что бы посмотреть, насколько это может быть эффективнее, давайте сравним 3 реализации. Первая — алгоритм Кернигана.
func kernighan(x uint64) (count int) {
for x > 0 {
count++
x &= x - 1
}
return count
}
Количество циклов алгоритма совпадает с количеством установленных бит. Больше бит — больше время выполнения, что потенциально приводит к утечке информации по сторонним каналам.Второй алгоритм взят из книги Hacker’s Delight.
func hackersdelight(x uint64) uint8 {
const m1 = 0b0101010101010101010101010101010101010101010101010101010101010101
const m2 = 0b0011001100110011001100110011001100110011001100110011001100110011
const m4 = 0b0000111100001111000011110000111100001111000011110000111100001111
const h1 = 0b0000000100000001000000010000000100000001000000010000000100000001
x -= (x >> 1) & m1
x = (x & m2) + ((x >> 2) & m2)
x = (x + (x >> 4)) & m4
return uint8((x * h1) >> 56)
}
Стратегия «разделяй и властвуй» позволяет этой версии работать за O(log₂) от длинны числа, и за константное время от количества бит, что важно для криптографии. Давайте сравним производительность с math/bits.OnesCount64.
func BenchmarkKernighan(b *testing.B) {
var r int
for i := 0; i < b.N; i++ {
r = kernighan(uint64(i))
}
runtime.KeepAlive(r)
}
func BenchmarkPopcnt(b *testing.B) {
var r int
for i := 0; i < b.N; i++ {
r = hackersdelight(uint64(i))
}
runtime.KeepAlive(r)
}
func BenchmarkMathBitsOnesCount64(b *testing.B) {
var r int
for i := 0; i < b.N; i++ {
r = bits.OnesCount64(uint64(i))
}
runtime.KeepAlive(r)
}
Что бы быть честным, мы передаём функциям одни и теже параметры: последовательность от 0 до b.N. Это справедливее к методу Кернигана, так как её время выполнения увеличивается с количеством бит входного аргумента. ➚
BenchmarkKernighan-4 100000000 12.9 ns/op
BenchmarkPopcnt-4 485724267 2.63 ns/op
BenchmarkMathBitsOnesCount64-4 1000000000 0.673 ns/op
math/bits.OnesCount64 выигрывает по скорости в 4 раза. Но действительно ли оно использует аппаратную реализацию, или компилятор просто лучше оптимизировал алгоритм из Hackers Delight? Пора залезть в assembler.
go test -c # компилируем тесты без запуска
Есть простая утилита для дизасемблирования go tool objdump, но я (в отличии от автора оригинальной статьи), воспользуюсь IDA.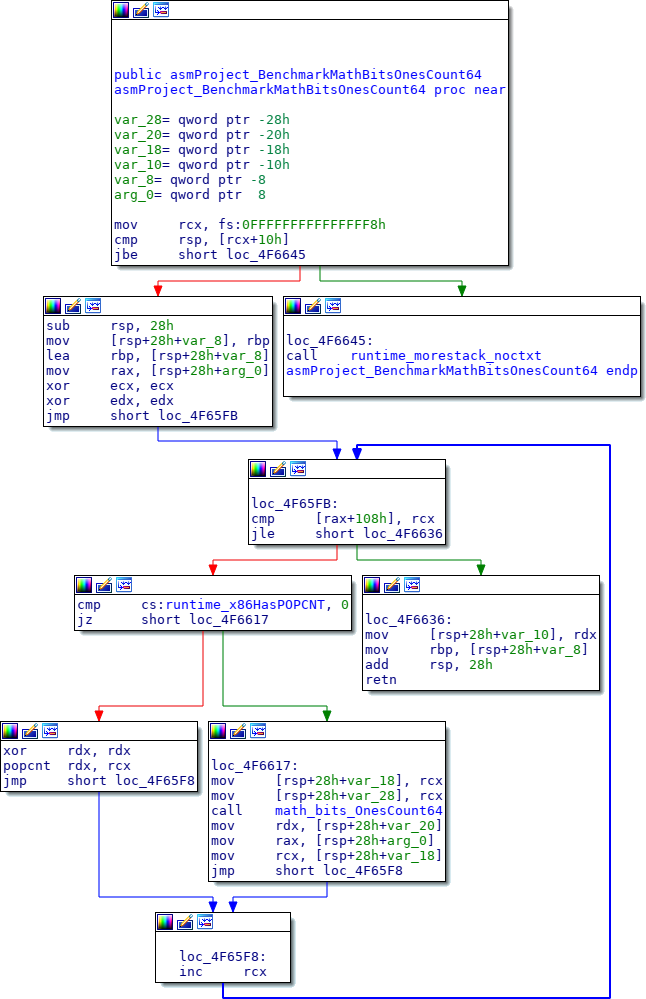
POPCNT встроена в код самого теста, как мы и надеялить. Благодаря этому banchmark работает быстрее, чем альтернативы.Интересно вот это ветвление.
cmp cs:runtime_x86HasPOPCNT, 0
jz lable
Да, это полифил на асемблере. Не все процессоры поддерживают POPCNT. При запуске программы, до вашего main функция runtime.cpuinit проверяет, есть ли необходимая инструкция и сохраняет в runtime.x86HasPOPCNT. Каждый раз программа проверяет, можно ли использовать POPCNT, или воспользоваться полифилом. Так как значение runtime.x86HasPOPCNT не меняется после инициализации, предсказание ветвления процессора отрабатывает относительно точно.
Атомарный счётчик
Встроенные(intrinsic) функции — это обычный код Go, они могут быть встроены(inline) в поток инструкций. Для примера сделаем из странных сигнатур функций пакета atomic абстракцию счётчика с методами.
package main
import (
"sync/atomic"
)
type counter uint64
func (c *counter) get() uint64 {
return atomic.LoadUint64((*uint64)(c))
}
func (c *counter) inc() uint64 {
return atomic.AddUint64((*uint64)(c), 1)
}
func (c *counter) reset() uint64 {
return atomic.SwapUint64((*uint64)(c), 0)
}
func F() uint64 {
var c counter
c.inc()
c.get()
return c.reset()
}
func main() {
F()
}
Кто-то подумает, что такое ООП добавит накладные расходы. Но Go не Java — язык не использует связывание в runtime, если явно не использовать интерфейсы. Код выше будет свёрнут в эффективный поток процессорных инструкций. Как будет выглядеть main?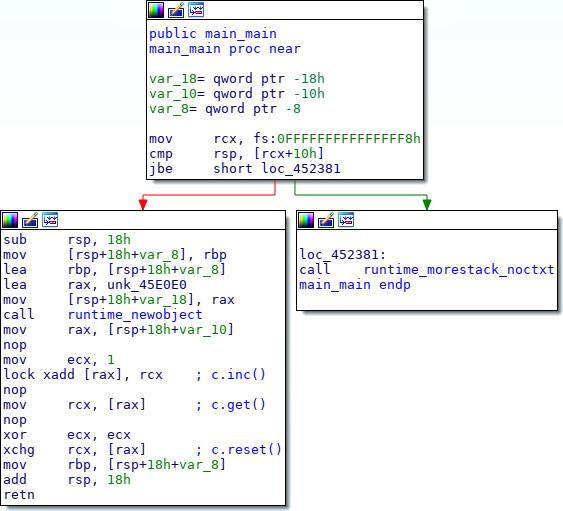
c.inc превращается в lock xadd [rax], 1 — атомарное сложение x86. c.get становится обычной инструкцией mov, которая уже является атомарной в x86. c.reset становится атомарным обменом xchg между обнулённым регистром и памятью.
Заключение
Встраиваемые функции — аккуратное решение, которое предоставляет доступ к низкоуровневым операциям без расширения спецификации языка. Если архитектура не имеет специфических примитивов sync/atomic (как некоторые варианты ARM), или операций из math/bits, то компилятор вставляет полифил на чистом go.
Комментариев нет:
Отправить комментарий