
Kubernetes в значительной мере упрощает эксплуатацию приложений. Он забирает на себя ответственность за развертывание, масштабирование и отработку отказов, а декларативная природа описания ресурсов упрощает управление сложными приложениями.
Тarantool может выполнять роль сервера приложений, исполняя stateless-приложения. Но по-настоящему его можно оценить только воспользовавшись им как базой данных и сервером приложений одновременно. Tarantool не используется там, где можно обойтись парой MySQL-серверов. Он используется там, где от нагрузки трещит сеть, где одно лишнее поле в таблицах выливается в сотни гигабайт потраченного места, и где шардинг — это не задел на светлое бизнес-будущее, но суровая необходимость.
Мы занимаемся разработкой решений на базе Tarantool, Tarantool Cartridge и их экосистемы. Как мы докатились до запуска базы данных на Kubernetes? Все очень просто: скорость доставки и стоимость эксплуатации. Сегодня мы представляем Tarantool Kubernetes Operator, за подробностями прошу под кат.
Оглавление:
- Вместо тысячи слов
- Чем вообще занимается оператор
- Немного про нюансы
- Как оператор работает
- Что оператор разворачивает
- Итог
Tarantool — это не только опенсорсная база данных и сервер приложений, но еще и команда инженеров, которая занимается разработкой enterprise-систем «под ключ».
Глобально наши задачи можно поделить на два направления: разработка новых систем и аугментация уже существующих решений. Например, есть большая база от известного вендора. Чтобы отмасштабировать ее на чтение, за ней ставят eventually consistent кэш на Tarantool. Или наоборот: чтобы отмасштабировать запись, ставят Tarantool в конфигурации горячий/холодный, где по мере «остывания» данные скидываются на холодное хранилище и параллельно в очередь для аналитики. Или чтобы подпереть уже существующую систему, пишется облегченная версия этой системы (функциональный резерв), которая резервирует основную «по-горячему» с репликацией данных из основной системы. Подробнее можно узнать из докладов с T+ 2019.
У всех этих систем есть одна общая черта: их довольно сложно эксплуатировать. Быстро раскатать кластер на 100+ инстансов с резервированием в 3 ЦОДа, обновить приложение, которое хранит данные без простоев и просадок в обслуживании, сделать бэкап рестор на случай катастрофы или рукотворных ошибок, обеспечить незаметную отработку отказов компонентов, организовать управление конфигурацией… В общем, масса интересного.
Tarantool Cartridge, который буквально только что зарелизился в open source, в значительной мере упрощает разработку распределенных систем: несет на борту компоненты кластеризации, service discovery, управления конфигурацией, детектирования отказов инстансов и автоматического failover’a, управления топологией репликации, компонент шардинга.
А было бы здорово, если бы все это еще и эксплуатировалось так же просто, как разрабатывается. Kubernetes дает возможность достичь нужного результата, но использование специализированного оператора делает жизнь еще проще.
Сегодня мы анонсируем альфа-версию Tarantool Kubernetes Operator.
Вместо тысячи слов
Мы подготовили небольшой пример на основе Tarantool Cartridge, с ним и будем работать. Простенькое приложение типа «распределенное key value хранилище с HTTP интерфейсом». После запуска получим вот такую картину:
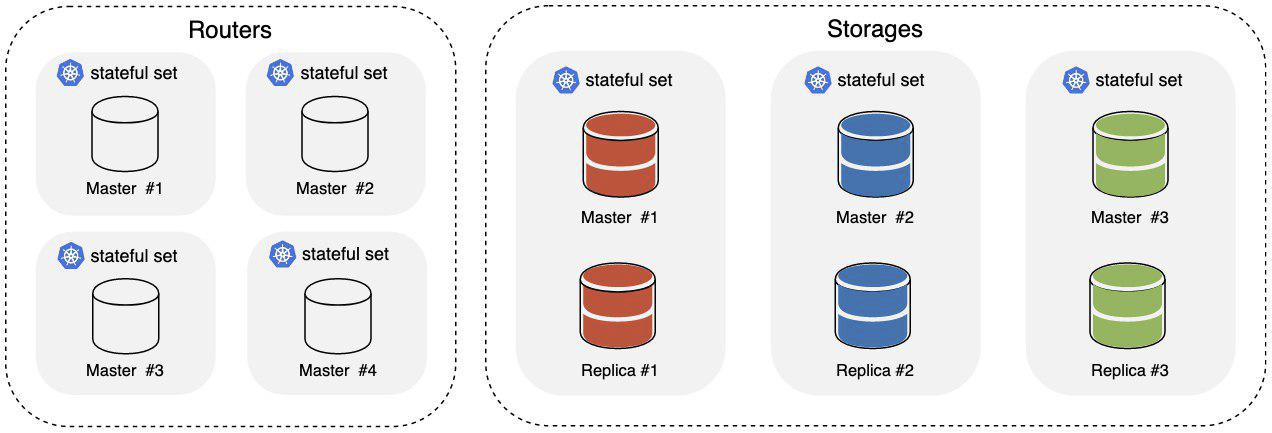
Где:
- Routers — часть кластера, которая отвечает за принятие и обработку входящих HTTP-запросов;
- Storages — часть кластера, отвечающая за хранение и обработку данных, из коробки поднимается 3 шарда, в каждом мастер и реплика.
Для балансировки входящего HTTP-трафика по роутерам используется кубернетовский Ingress. Данные распределяются в хранилище на уровне самого Tarantool с помощью компонента vshard.
Нам понадобится kubernetes 1.14+, сойдет и minikube. Также не помешает наличие kubectl. Для запуска оператора потребуется создать для него ServiceAccount, Role и RoleBinding:
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/master/deploy/service_account.yaml
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/master/deploy/role.yaml
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/master/deploy/role_binding.yaml
Tarantool Operator расширяет Kubernetes API своими определениями ресурсов, создадим и их:
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/master/deploy/crds/tarantool_v1alpha1_cluster_crd.yaml
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/master/deploy/crds/tarantool_v1alpha1_role_crd.yaml
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/master/deploy/crds/tarantool_v1alpha1_replicasettemplate_crd.yaml
К запуску оператора все готово, поехали:
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/master/deploy/operator.yaml
Ждем, когда оператор запустится, и можем переходить к запуску приложения:
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/master/examples/kv/deployment.yaml
В yaml-файле с примером объявлен Ingress на web UI; он доступен на
cluster_ip/admin/cluster. Когда хотя бы один Pod из Ingress’а поднимется, можно будет зайти туда и понаблюдать за тем, как в кластер добавляются новые инстансы и как меняется его топология.
Дожидаемся, когда кластер можно использовать:
$ kubectl describe clusters.tarantool.io examples-kv-cluster
Ожидаем, что в Status’е кластера будет следующее:
…
Status:
State: Ready
…
Все, приложение готово к использованию!
Нужно больше места в хранилище? Добавим шардов:
$ kubectl scale roles.tarantool.io storage --replicas=3
Шарды не справляются с нагрузкой? Увеличим количество инстансов в шарде, отредактировав шаблон replicaset’а:
$ kubectl edit replicasettemplates.tarantool.io storage-template
Установим
.spec.replicas, равное например 2, чтобы увеличить количество инстансов в каждом репликасете до двух.
Кластер больше не нужен? Удаляем его вместе со всеми ресурсами:
$ kubectl delete clusters.tarantool.io examples-kv-cluster
Что-то пошло не так? Забивайте тикет, будем оперативно разбирать. :)
Чем вообще занимается оператор
Запуск и эксплуатация кластера Tarantool Cartridge — это история о выполнении определенных действий, в определенном порядке, в определенный момент.
Сам по себе кластер управляется в первую очередь через админское API: GraphQL поверх HTTP. Можно, конечно, пойти уровнем ниже и вбивать команды прямо в консоль, но такое случается редко. Например, вот так выглядит запуск кластера:
- Поднимаем нужное количество инстансов Tarantool, например под systemd.
- Объединяем инстансы в membership:
mutation { probe_instance: probe_server(uri: "storage:3301") } - Присваиваем инстансам роли, прописываем идентификаторы инстанса и репликасета. Для этого также используется GraphQL API:
mutation { join_server( uri:"storage:3301", instance_uuid: "cccccccc-cccc-4000-b000-000000000001", replicaset_uuid: "cccccccc-0000-4000-b000-000000000000", roles: ["storage"], timeout: 5 ) } - Выполняем bootstrap компонента, отвечающего за шардинг. Также через API:
mutation { bootstrap_vshard cluster { failover(enabled:true) } }
Несложно, правда?
Все становится интереснее, когда речь заходит о расширении кластера. Роль Routers из примера масштабируется просто: поднимаем больше инстансов, подцепляем их к существующему кластеру — готово! Роль Storages несколько хитрее. Хранилище шардированное, поэтому при добавлении/удалении инстансов необходимо выполнить перебалансировку, чтобы данные переехали на новые инстансы/переехали с удаляемых инстансов. Если этого не сделать, то в одном случае получим недогруженные инстансы, во втором — потеряем данные. А если в эксплуатации не один, а десяток вот таких кластеров с разными топологиями?
В общем, этим всем и занят Tarantool Operator. Пользователь описывает желаемое состояние кластера Tarantool Cartridge, а оператор транслирует это в набор действий над ресурсами k8s и в определенные вызовы к админскому API кластера Tarantool’ов — в определенном порядке, в определенный момент, и вообще всячески старается скрыть от пользователя все нюансы.
Немного про нюансы
В работе с админским API кластера Tarantool Cartridge важны как порядок вызовов, так и куда они приходят. Почему так?
Tarantool Cartridge несет на борту свое хранилище топологии, свой компонент service discovery и свой компонент работы с конфигурацией. Каждый инстанс кластера хранит копию топологии и конфигурации в yaml-файле.
servers:
d8a9ce19-a880-5757-9ae0-6a0959525842:
uri: storage-2-0.examples-kv-cluster:3301
replicaset_uuid: 8cf044f2-cae0-519b-8d08-00a2f1173fcb
497762e2-02a1-583e-8f51-5610375ebae9:
uri: storage-0-0.examples-kv-cluster:3301
replicaset_uuid: 05e42b64-fa81-59e6-beb2-95d84c22a435
…
vshard:
bucket_count: 30000
...
Обновление происходит согласованно с использованием механизма двухфазного коммита. Для успешного обновления необходим 100 % кворум: каждый инстанс должен ответить, иначе откат. Что это означает с точки зрения эксплуатации? Все запросы к админскому API, модифицирующие состояние кластера, надежнее всего отправлять на один инстанс, на лидера, иначе мы рискуем получить разные конфиги на разных инстансах. Tarantool Cartridge не умеет делать leader election (пока что не умеет), а Tarantool Operator умеет — и вам об этом можно знать только как о занимательном факте, потому что оператор всё разрулит.
Также каждый инстанс должен обладать фиксированным identity, то есть набором instance_uuid и replicaset_uuid, а также advertise_uri. Если вдруг случится перезапуск storage и изменится один из этих параметров, то вы рискуете развалить кворум — этим тоже занимается оператор.
Как оператор работает
Задача оператора — приводить систему в заданное пользователем состояние и поддерживать систему в этом состоянии до поступления новых указаний. Для того чтобы оператор мог выполнять свою работу, ему нужны:
- Описание состояния системы.
- Код, который приводит систему в это состояние.
- Механизм интеграции этого кода в k8s (например, чтобы получать уведомления об изменениях в состоянии).
Кластер Tarantool Cartridge описывается в терминах k8s через Custom Resource Definition (CRD); оператору нужно 3 таких кастомных ресурса, объединенных под группой tarantool.io/v1alpha:
- Cluster — ресурс верхнего уровня, соответствует одному кластеру Tarantool Cartridge.
- Role — в терминах Tarantool Cartridge это пользовательская роль.
- ReplicasetTemplate — шаблон, по которому будут создаваться StatefulSet’ы (почему stateful — расскажу чуть позже; не путать с k8s ReplicaSet).
Все эти ресурсы напрямую отражают модель описания кластера Tarantool Cartridge. Имея общий словарь, эксплуатации проще общаться с разработчиками и понимать, что те хотят увидеть в проде.
Код, приводящий систему в заданное состояние — в терминах k8s это Controller. В случае с Tarantool Operator контроллеров несколько:
- ClusterController — отвечает за взаимодействие с кластером Tarantool Cartridge, подключает инстансы к кластеру, отключает инстансы от кластера.
- RoleController — контроллер пользовательской роли, отвечает за развертывание StatefulSet’ов из шаблона и поддержание их числа в заданном количестве.
Что из себя представляет контроллер? Набор кода, поэтапно приводящего мир вокруг себя в порядок. ClusterController схематически можно изобразить вот так:
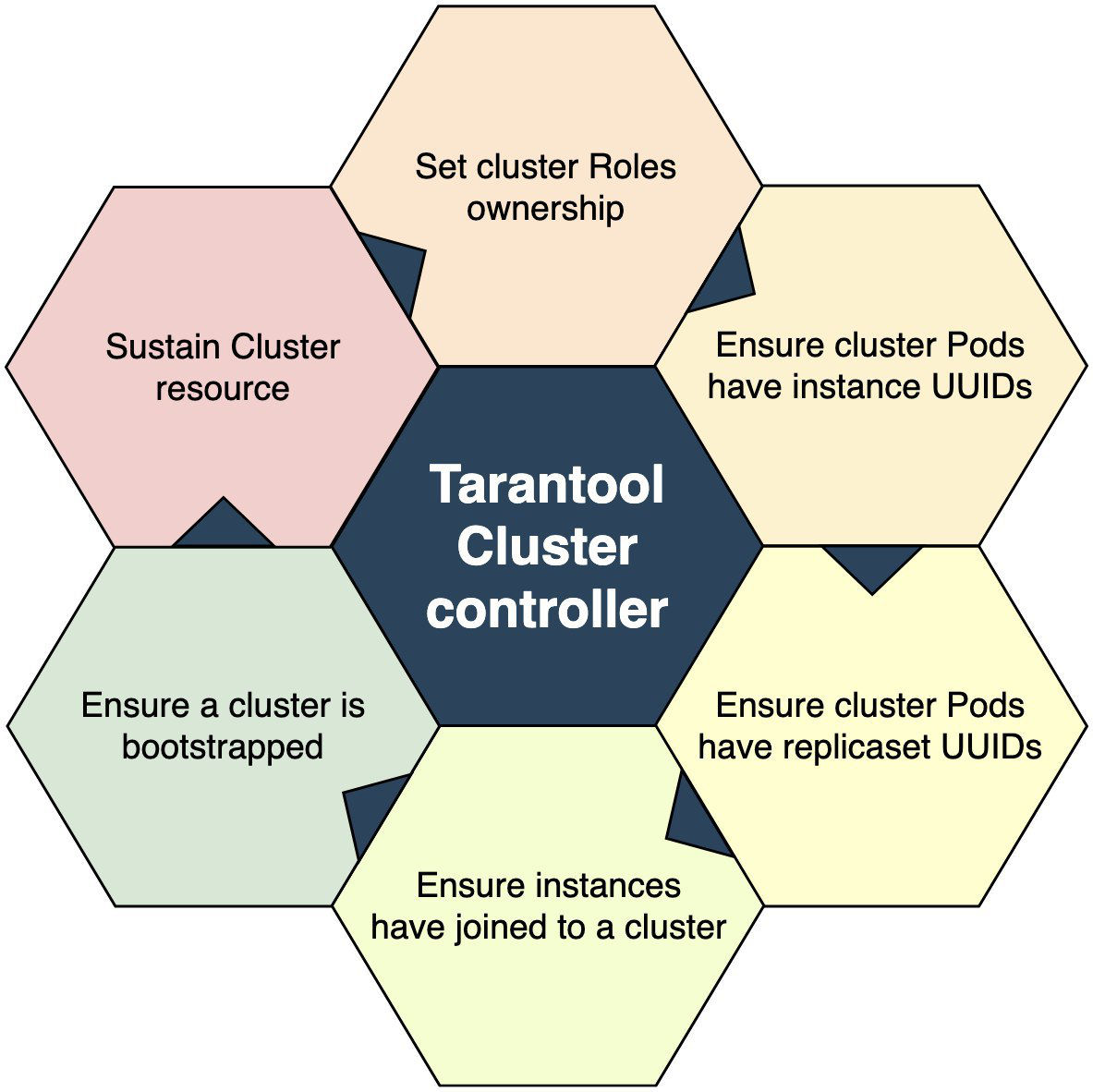
Точка входа — это проверка, существует ли ресурс Cluster’a, относительно которого произошло событие. Не существует? Выходим. Существует? Переходим к следующему блоку: захватываем Ownership над пользовательскими ролями. Захватили одну — вышли, на втором круге захватываем вторую. И так далее, пока не захватим все. Все роли захвачены? Значит переходим к следующему блоку операций. И так, пока не дойдем до последнего; вот тогда можно считать, что контролируемая система в заданном состоянии.
В целом все просто. Важно определить критерии успешности прохождения каждого этапа. Например, успешной мы считаем операцию присоединения к кластеру не тогда, когда она вернула условный success=true, а когда она вернула ошибку типа «already joined».
И последняя часть этого механизма — интеграция контроллера с k8s. С высоты птичьего полета, весь k8s состоит из набора контроллеров, порождающих события и реагирующих на них. События ходят через очереди, на которые мы можем подписываться. Схематически это можно изобразить вот так:
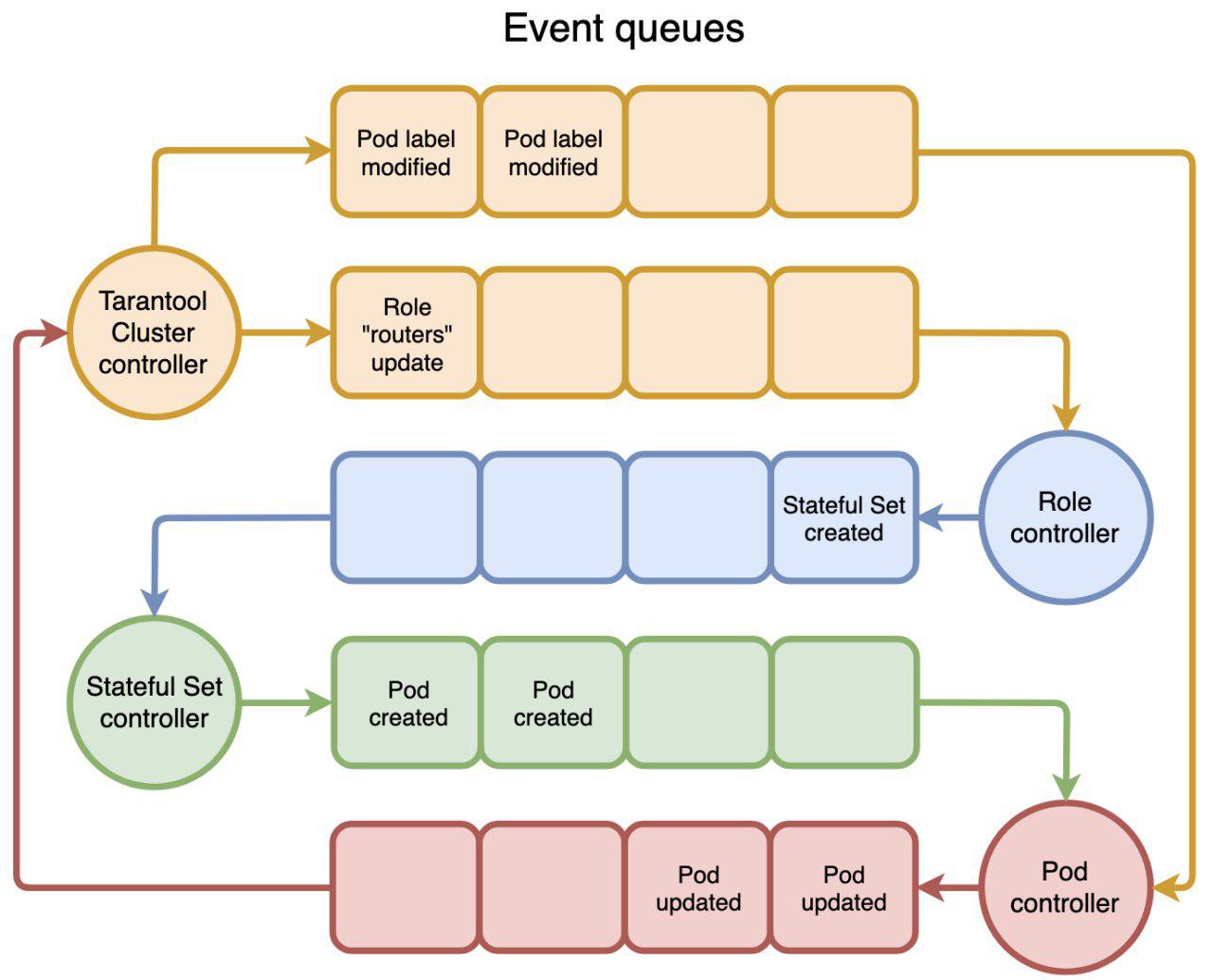
Пользователь вызывает kubectl create -f tarantool_cluster.yaml, создается соответствующий ресурс Cluster. ClusterController получает уведомление о создании ресурса Cluster. И первое, что он пытается сделать — найти все ресурсы Role, которые должны входить в этот кластер. Если находит, то назначает Cluster как Owner для Role и обновляет ресурс Role. RoleController получает уведомление об обновлении Role, видит, что у ресурса появился Owner, и начинает создавать StatefulSet’ы. И так далее по кругу: первый стриггерил второго, второй стриггерил третьего — и так, пока кто-нибудь не остановится. А еще можно триггериться по времени, например раз в 5 секунд, что иногда бывает полезно.
Вот и весь оператор: создаем кастомный ресурс и пишем код, который реагирует на события над ресурсами.
Что оператор разворачивает
Действия оператора в итоге приводят к тому, что k8s создает Pod’ы и контейнеры. В кластере Tarantool Cartridge, развернутом на k8s, все Pod’ы объединены в StatefulSet’ы.
Почему именно StatefulSet? Как я писал ранее, каждый инстанс Tarantool Cluster хранит у себя копию топологии и конфигурации кластера, а еще частенько на app server’ах нет-нет, да и используют какой-нибудь спейс, например под очереди или справочные данные, а это уже полноценное состояние. А еще StatefulSet дает гарантию сохранения identity Pod’ов, что важно при объединении инстансов в кластер: identity инстансов должен быть фиксированным, в противном случае мы рискуем потерять кворум при перезапуске.
Когда все ресурсы кластера созданы и приведены в нужное состояние, они формируют следующую иерархию:
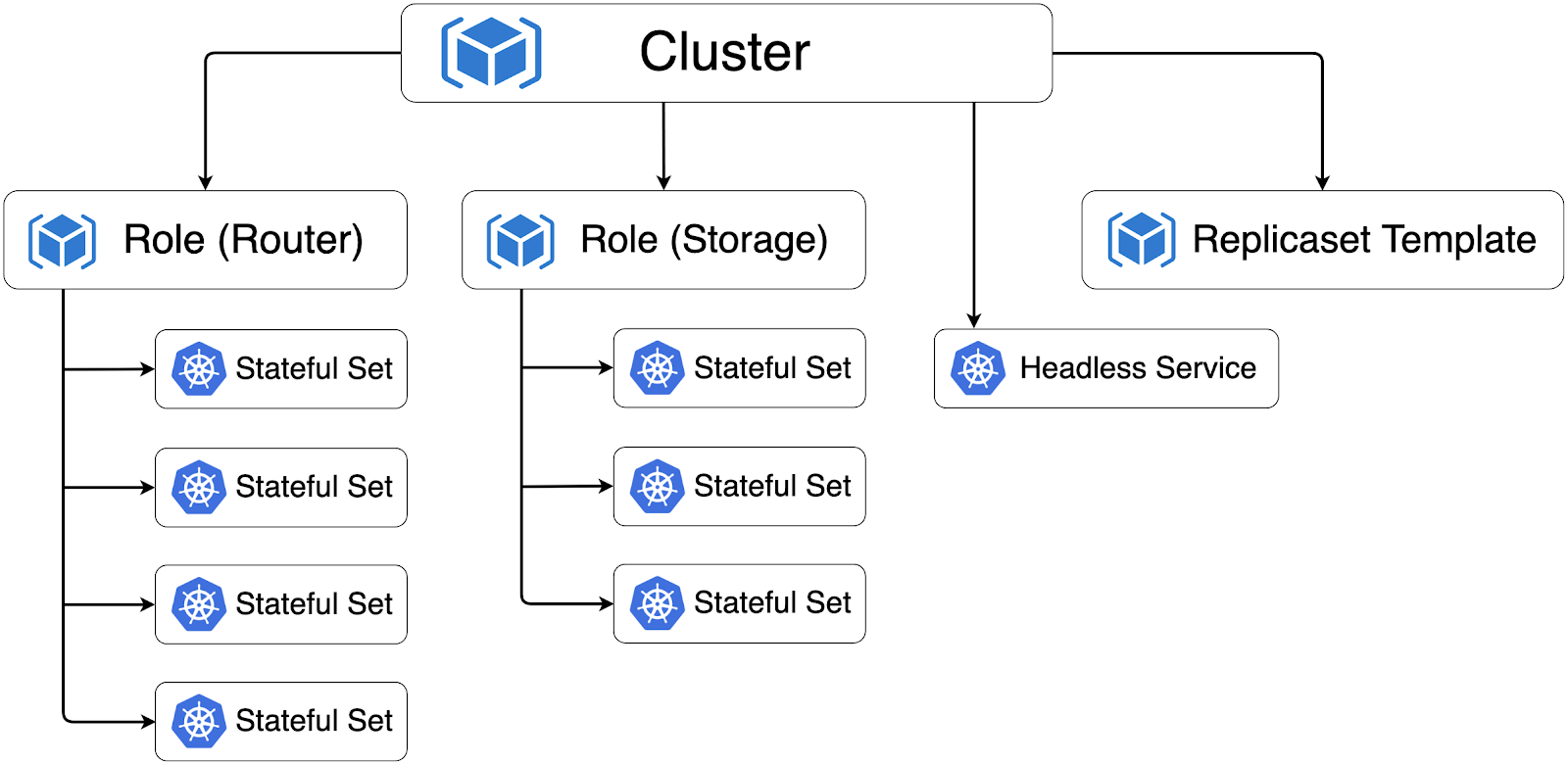
Стрелками обозначено отношение Owner-Dependant между ресурсами. Оно нужно, чтобы Garbage Collector прибирал за нами в случае, например, удаления Cluster.
В дополнение к StatefulSet’ам Tarantool Operator создает Headless Service, который нужен для leader election, и через него инстансы общаются между собой.
Под капотом Tarantool Operator лежит Operator Framework, сам код оператора — на golang, здесь ничего экстраординарного.
Итог
Вот, в общем-то, и все! Ждем от вас фидбэка и тикетов — куда ж без них, альфа-версия все-таки. Что дальше? А дальше предстоит масса работы по доведению этого всего до ума:
- Unit, E2E-тестирование;
- тестирование Chaos Monkey;
- нагрузочное тестирование;
- backup/restore;
- внешний topology provider.
Каждая из этих тем обширна сама по себе и заслуживает отдельного материала, ждите апдейтов!
Комментариев нет:
Отправить комментарий