
В Америке очень сложно жить без машины, и, так как мы наши машины продали перед переездом, теперь нам надо было купить новое семейное средство передвижения. Я решил подойти к решению этой задачи так, как подошёл бы любой хороший специалист по обработке и анализу данных. Я решил воспользоваться данными.
Сбор данных
Часто самой сложной частью проекта по изучению данных является этап сбора данных. Особенно в том случае, если речь идёт о некоем домашнем проекте. Тут весьма вероятно то, что загрузить из интернета нечто готовое к обработке, оформленное в виде CSV-файла, не получится. А без данных не удастся ни построить модель, ни сделать прогноз.
Как раздобыть данные по рынку автомобилей? Решить эту задачу нам поможет веб-скрапинг.

Инструменты разработчика Google Chrome
Веб-скрапинг — это автоматизированный процесс сбора данных с веб-сайтов. Я не эксперт в вопросах веб-скрапинга, да и статья эта не является руководством по сбору данных с сайтов. Но, если немного попрактиковаться и вникнуть в особенности работы некоторых Python-модулей, можно удовлетворить самые безумные фантазии, касающиеся сбора данных.
В этом проекте я использовал Python-пакет Selenium, который представляет собой браузер без пользовательского интерфейса. Такой браузер открывает страницы и работает с ними так же, как работал бы с ними пользователь (в отличие от чего-то вроде Python-библиотеки Beautiful Soup, которая просто читает HTML-код).
Благодаря инструментам разработчика Google Chrome процесс подготовки к сбору данных сильно упрощается. Всё сводится к щелчкам правой кнопкой мыши по интересующим нас элементам веб-страниц и к копированию их xpath, element_id, или чего угодно другого. Всё это хорошо воспринимает Selenium. Но иногда для поиска нужного элемента и текста приходится немного повозиться.
Код, который я использовал для сбора информации по сотням машин, можно найти здесь.
Очистка данных
Одна из проблем данных, собранных с помощью веб-скрапинга, заключается в том, что эти данные, весьма вероятно, окажутся довольно-таки неопрятными. Дело тут в том, что взяты они не из некоего хранилища, а собраны с веб-сайта, который создан для того, чтобы показывать информацию людям. В результате такие данные нуждаются в серьёзной очистке. Часто это означает, что для получения нужных данных потребуется парсить строки.
После того, как я сохранил результаты веб-скрапинга в CSV-файле, я смог загрузить эти данные в датафрейм Pandas и заняться их очисткой.
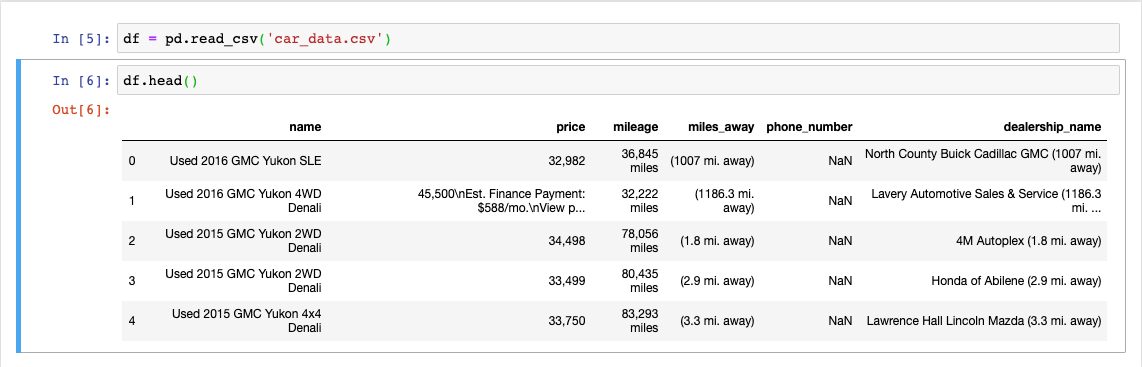
Данные перед очисткой
Теперь я мог, пользуясь чем-то вроде регулярных выражений, приступать к извлечению из собранных данных нужной мне информации, и к созданию признаков, которые я мог бы исследовать, и на основе которых мог бы строить модели.
Сначала я создал функцию для работы с регулярными выражениями, подходящую для многократного использования, которую я мог бы передать методу Pandas .apply.
def get_regex_item(name, pattern):
item = re.search(pattern, name)
if item is None:
return None
else:
return item.group()В столбце
name имеется много полезных данных. На его основе я, воспользовавшись созданной мной функцией, мог создать четыре новых признака.
df['4wd'] = df.name.apply(lambda x: 1 if get_regex_item(x, pattern= r'4[a-zA-Z]{2}') else 0)
df['year'] = df.name.apply(lambda x: get_regex_item(x, pattern= r'\d{4}'))
df['type'] = df.name.apply(lambda x: x.split()[-1])
df['certified'] = df.name.apply(lambda x: 1 if get_regex_item(x.lower(), r'certified') else 0)
df['price'] = df.price.apply(lambda x: x[:6].replace(",", "")).astype('int')
df['mileage'] = df.mileage.apply(lambda x: x.split()[0].replace(",", "")).astype('int')В результате у меня получился датафрейм, показанный на следующем рисунке.

Данные после очистки
Разведочный анализ данных
Теперь пришло время заняться кое-чем интересным. А именно — разведочным анализом данных. Это очень важный шаг в работе дата-сайентиста, так как он позволяет понять особенности данных, увидеть тренды и взаимодействия. Моей целевой переменной была цена, в результате я строил графические представления данных, ориентируясь именно на цену.
import matplotlib.pyplot as plt
import seaborn as sns
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
#box plots
sns.boxplot(x = df.year, y=df.price, data=df[['year', 'price']], color='purple')
sns.boxplot(x = df.type, y=df.price, data=df[['year', 'price']], color='cyan')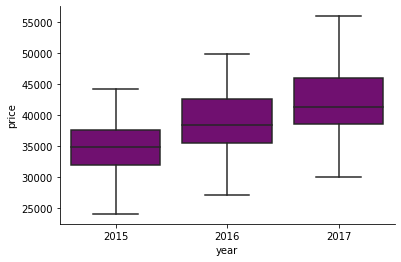
Зависимость цены автомобиля от года его выпуска
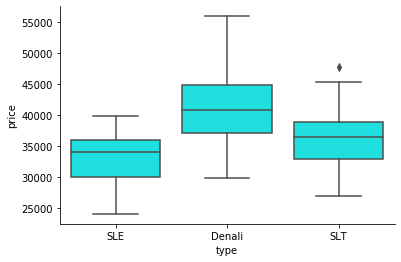
Зависимость цены от типа автомобиля
Эти коробчатые диаграммы, отражающие взаимосвязь цены и некоторых категориальных переменных, дают очень чёткие сигналы о том, что цена сильно зависит от года выпуска и от типа автомобиля.
А вот — диаграмма разброса.
import matplotlib.pyplot as plt
import seaborn as sns
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
#scatter plot
sns.regplot(x=df.mileage, y=df.price , color='grey')
Диаграмма разброса
Тут, анализируя зависимость цены от пробега, я снова увидел сильную корреляцию между независимой переменной (mileage) и ценой автомобиля. Налицо сильная отрицательная связь, так как по мере роста пробега автомобиля его цена падает. Учитывая то, что все знают об автомобилях, это вполне понятно.
Зная о взаимоотношениях между некоторыми из независимых переменных и целевой переменной, мы можем получить довольно-таки хорошее представление о том, какие признаки являются особенно важными, и о том, модель какого типа нужно использовать.
Кодирование независимых признаков
Ещё один шаг, который нужно было выполнить до построения модели, заключается в кодировании независимых признаков. Признаки
4wd и certified уже представлены в логическом виде. Они не нуждаются в дополнительной обработке. А вот признаки type и year нужно закодировать. Для решения этой задачи я воспользовался методом Pandas .get_dummies, который позволяет выполнять кодирование с одним активным состоянием.
Pandas — довольно интеллектуальная система, которая позволила мне передать ей все признаки и закодировала только независимые переменные, а также позволила мне убрать один из только что созданных столбцов для того, чтобы избавиться от полностью коррелирующих друг с другом признаков. Использование подобных данных привело бы к ошибкам в модели и в её интерпретации. Обратите внимание на то, что в итоге у меня осталось только два столбца с информацией о годе выпуска машины, так как столбец _2015 был удалён. То же самое касается и столбцов type.
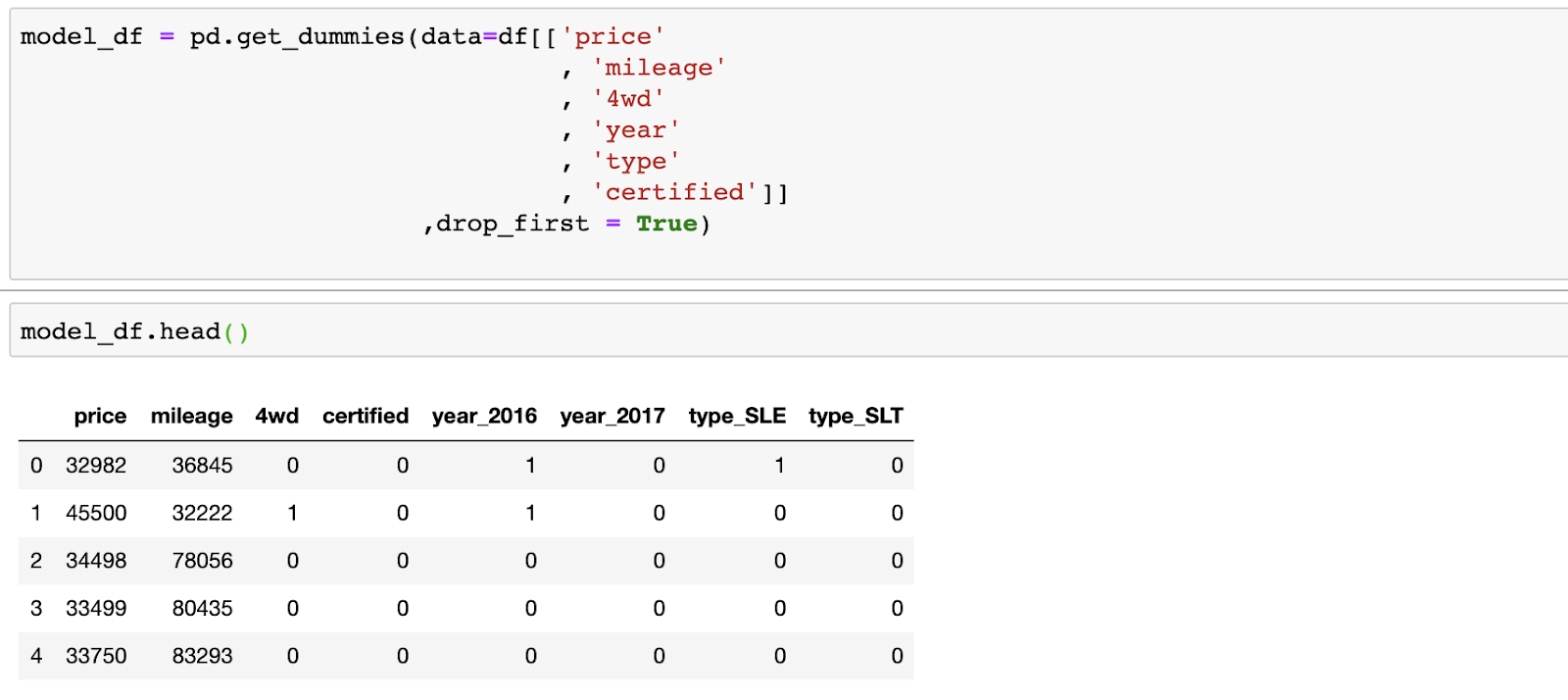
Данные после кодирования независимых переменных
Теперь мои данные оказались преобразованными в формат, на основе которого я мог построить модель.
Создание модели
Основываясь на анализе вышеприведённых диаграмм, и на том, что я знаю об автомобилях, я решил, что в моём случае подойдёт линейная модель.
Я воспользовался моделью линейной регрессии OLS (Ordinary Least Squares, обычный метод наименьших квадратов). Для построения модели применён Python-пакет statsmodel.
import statsmodels.api as sm
y = model_df.price
X = model_df.drop(columns='price')
model = sm.OLS(y, X).fit()
print(model.summary())Вот результаты моделирования.
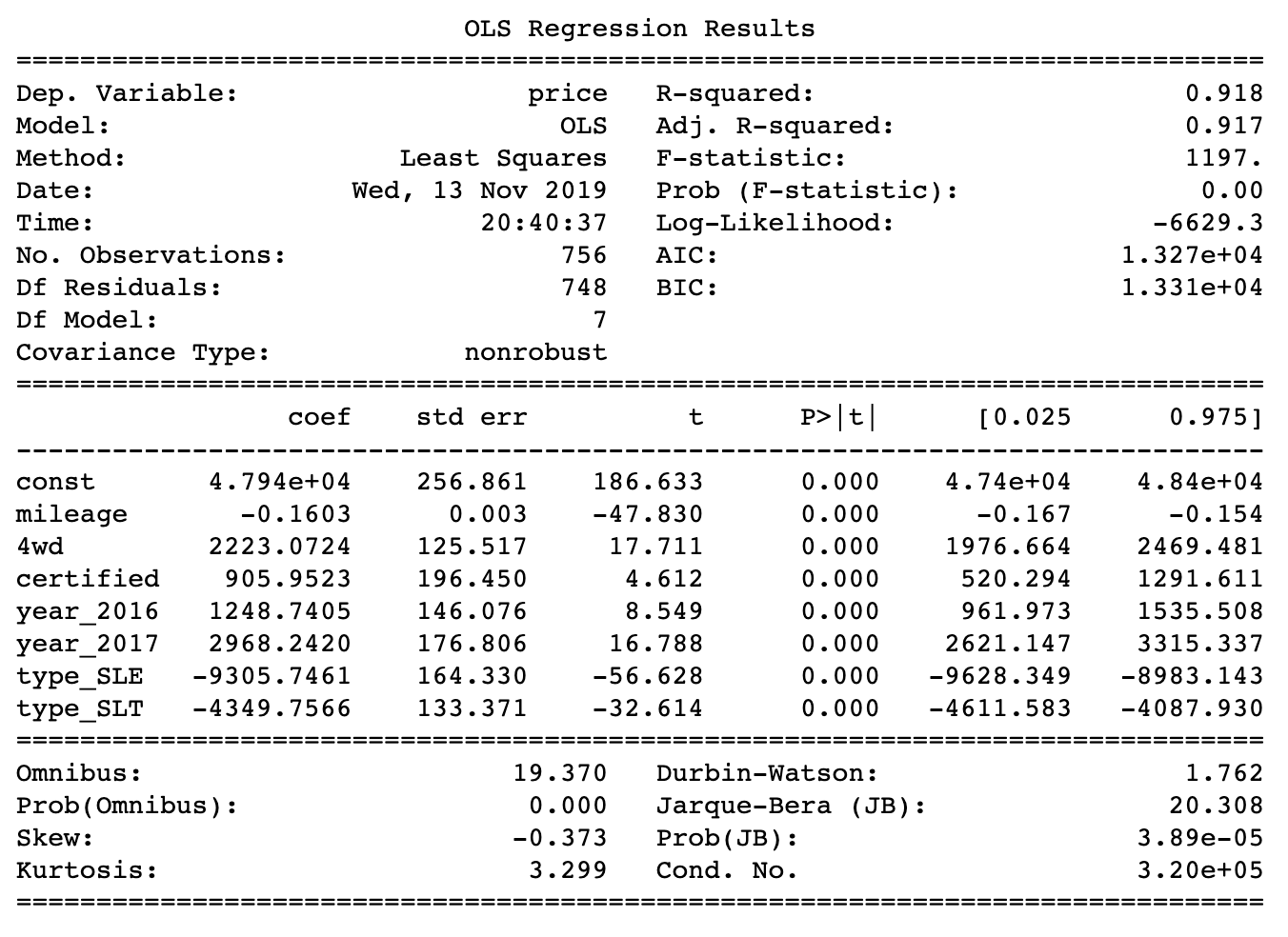
Моделирование привело к получению среднеквадратичной ошибки в 1556.09
Полученные коэффициенты соответствуют тому, что можно было видеть на диаграммах в ходе разведочного анализа данных. Пробег оказывает отрицательное воздействие на цену. В среднем, каждая дополнительная тысяча миль пробега приводит к снижению цены на $1600. Это справедливо для автомобилей GMC Yukon, возможно, не для всех. Вероятно, самыми шокирующими результатами из всех стали те, которые указывают на разницу в цене между SLE (автомобили Yukon низшего класса) и Denali (автомобили Yukon высшего класса). Разница составляет более $9000. Это означает, что покупателю автомобиля более высокого класса приходится платить немалые деньги за все получаемые им премиальные опции. Как результат — хорошо было бы, если бы всё это ему было по-настоящему нужно.
Какую же машину стоит купить?
Итак, я собрал, очистил, распарсил, исследовал, визуализировал данные и построил на их основе модель. Но исходный вопрос о том, что же всё-таки купить, пока остался без ответа. Как узнать о том, что некое предложение достойно того, чтобы его принять?
Подход к поиску ответа на этот вопрос очень прост. Нужно использовать модель для формирования прогноза и найти разницу между спрогнозированной ценой и ценой, которую предлагают продавцы машин. Затем нужно отсортировать список разниц цен так, чтобы самые недооценённые предложения оказались бы в его верхней части. Это и даст список самых выгодных предложений.
После учёта некоторых дополнительных ограничений (мой бюджет и предпочтения жены), я смог выйти на отсортированный список предложений и начал обзванивать продавцов.
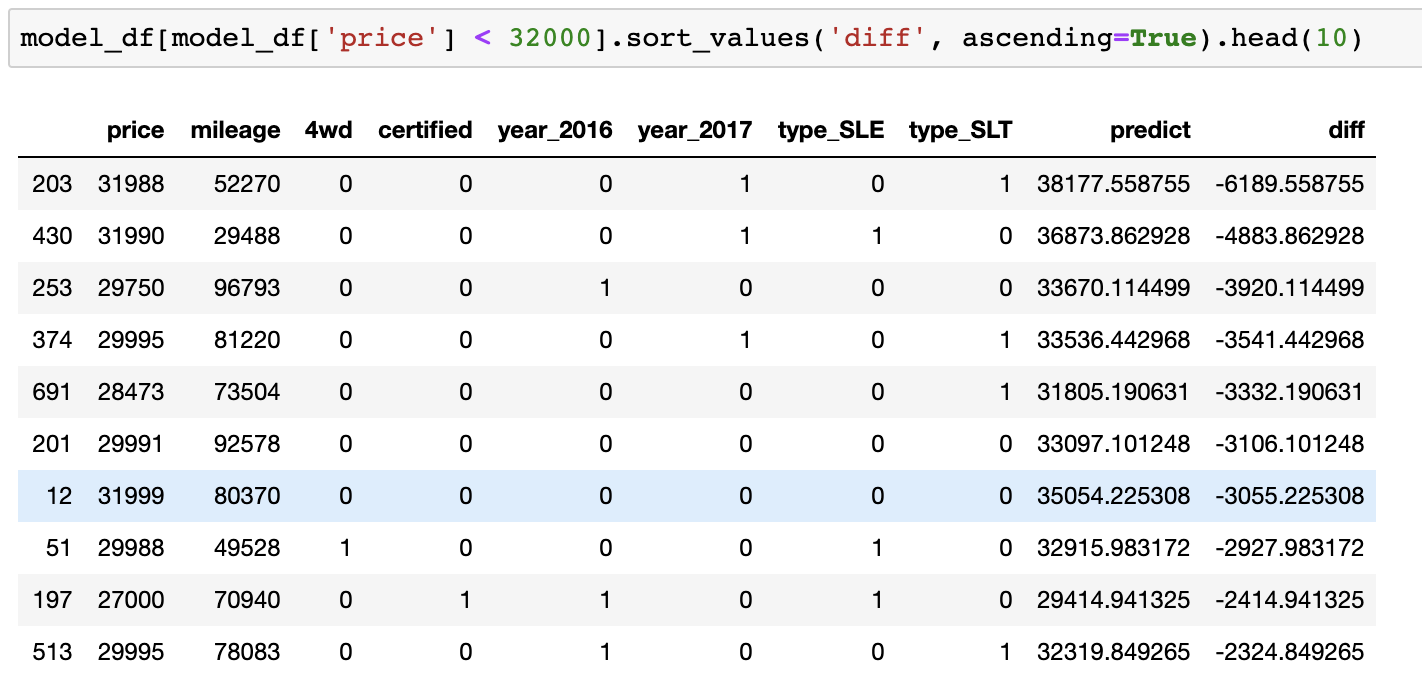
Купленная нами машина выделена синим
В итоге мы купили 2015 GMC Yukon Denali за $32000. Это было на $3000 дешевле прогноза, выданного моделью.
Хотя на рынке были и более выгодные предложения, машина, которую мы купили, находилась недалеко от нас, что значительно упростило и ускорило процесс покупки. Учитывая то, что на тот момент автомобиля у нас не было, нам важны были быстрота и удобство в решении этого вопроса.
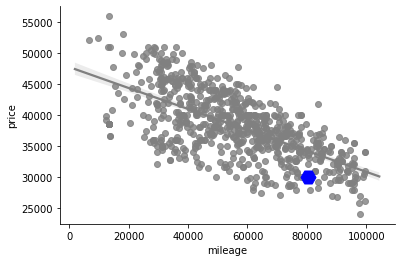
Наша покупка выделена на диаграмме синим цветом
В конце концов, мы смогли взглянуть на одну из ранее составленных диаграмм, выведя на ней сведения о купленной машине. Это показало нам, что мы, и правда, нашли хороший вариант.
Моей жене её новая машина очень нравится, а мне нравится цена этой машины. В общем, подводя итог вышеизложенному, можно сказать, что машину мы купили удачно.
Уважаемые читатели! Пользуетесь ли вы инструментами для анализа данных при решении каких-нибудь бытовых задач?


Комментариев нет:
Отправить комментарий