Котаны, привет.Сегодня мы выберем архитектуру нашей нейросети, проверим ее и соберем свой первый набор данных для обучения.
Я Саша и я балуюсь нейронками.По просьбам трудящихся я, наконец, собрался с мыслями и решил запилить серию коротких и почти пошаговых инструкций.
Инструкций о том, как с нуля обучить и задеплоить свою нейросеть, заодно подружив ее с телеграм ботом.
Инструкций для чайников, вроде меня.
Выбор архитектуры
После относительно успешного запуска selfie2anime бота (использующего готовую модель UGATIT), мне захотелось сделать то же самое, но свое. Например, модель, превращающую ваши фото в комиксы.
Вот несколько примеров из моего photo2comicsbot, и мы с вами сделаем нечто подобное.



Поскольку модель UGATIT была слишком тяжела для моей видеокарты, я обратил внимание на более старую, но менее прожорливую аналогию — CycleGAN
В данной реализации есть несколько архитектур моделей и удобное визуальное отображение процесса обучения в браузере.
CycleGAN, как и архитектуры для переноса стилей по одному изображению, не требует парных изображенией для обучения. Это важно, потому что иначе нам пришлось бы самим перерисовывать все фото в комиксы для создания обучающей выборки.
Задача, которую мы поставим перед нашим алгоритмом, состоит из двух частей.
На выходе мы должны получить картинку, которая:
а) похожа на комикс
б) похожа на исходное изображение
Пункт “а” может быть реализован с помощью обычной GAN, где за “похожесть на комиксы” будет отвечать обучаемый Критик.
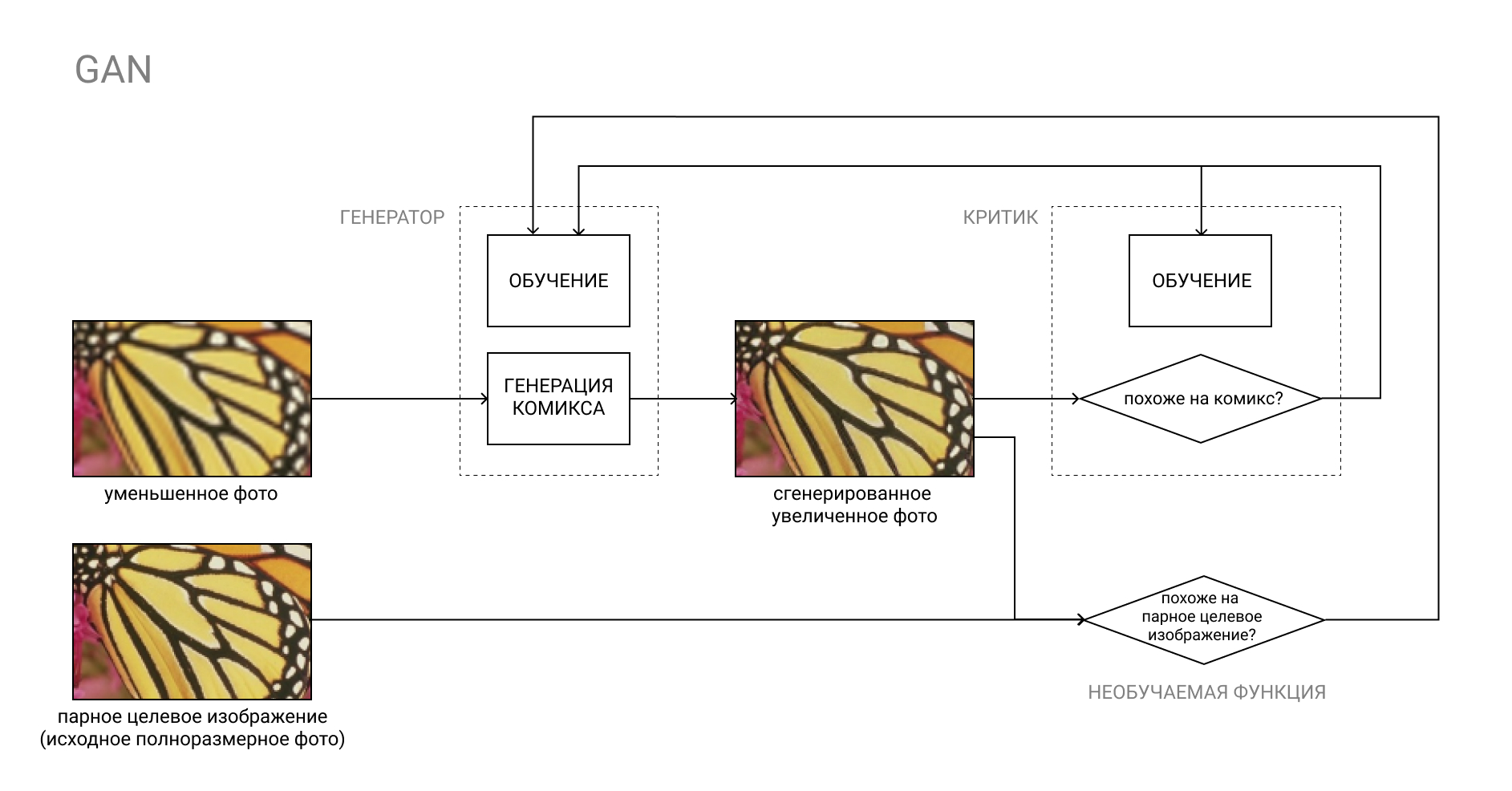
GAN, или Generative Adversarial Network — это пара из двух нейросетей: Генератора и Критика.
Генератор преобразует входные данные, например, из фото в комикс, а критик сравнивает полученный “фейковый” результат с настоящим комиксом. Задача Генератора — обмануть Критика, и наоборот.
В процессе обучения Генератор учится создавать комиксы, все больше похожие на настоящие, а Критик учится лучше их различать.
Со второй частью несколько сложнее. Если бы у нас были парные картинки, где в наборе “А” были бы фотографии, а в наборе “Б” — они же, но перерисованные в комиксы (т.е. то, что мы и хотим получить от модели), мы могли бы просто сравнить результат, выданный Генератором, с парным изображением из набора «Б» нашей обучающей выборки.
В нашем случае наборы “А” и “Б” никак не связаны друг с другом. В наборе “А” — случайные фото, в наборе “Б” — случайные комиксы.
Сравнивать же фейковый комикс с каким-то случайным комиксом из набора “Б” бессмысленно, так как это, как минимум, будет дублировать функцию Критика, не говоря уже о непредсказуемом результате.
Тут-то и приходит на помощь архитектура CycleGAN.
Если коротко, то это пара GAN, первая из которых преобразует изображение из категории “А” (например, фото) в категорию “Б” (например, комикс), а вторая — обратно, из категории “Б” в категорию “А”.
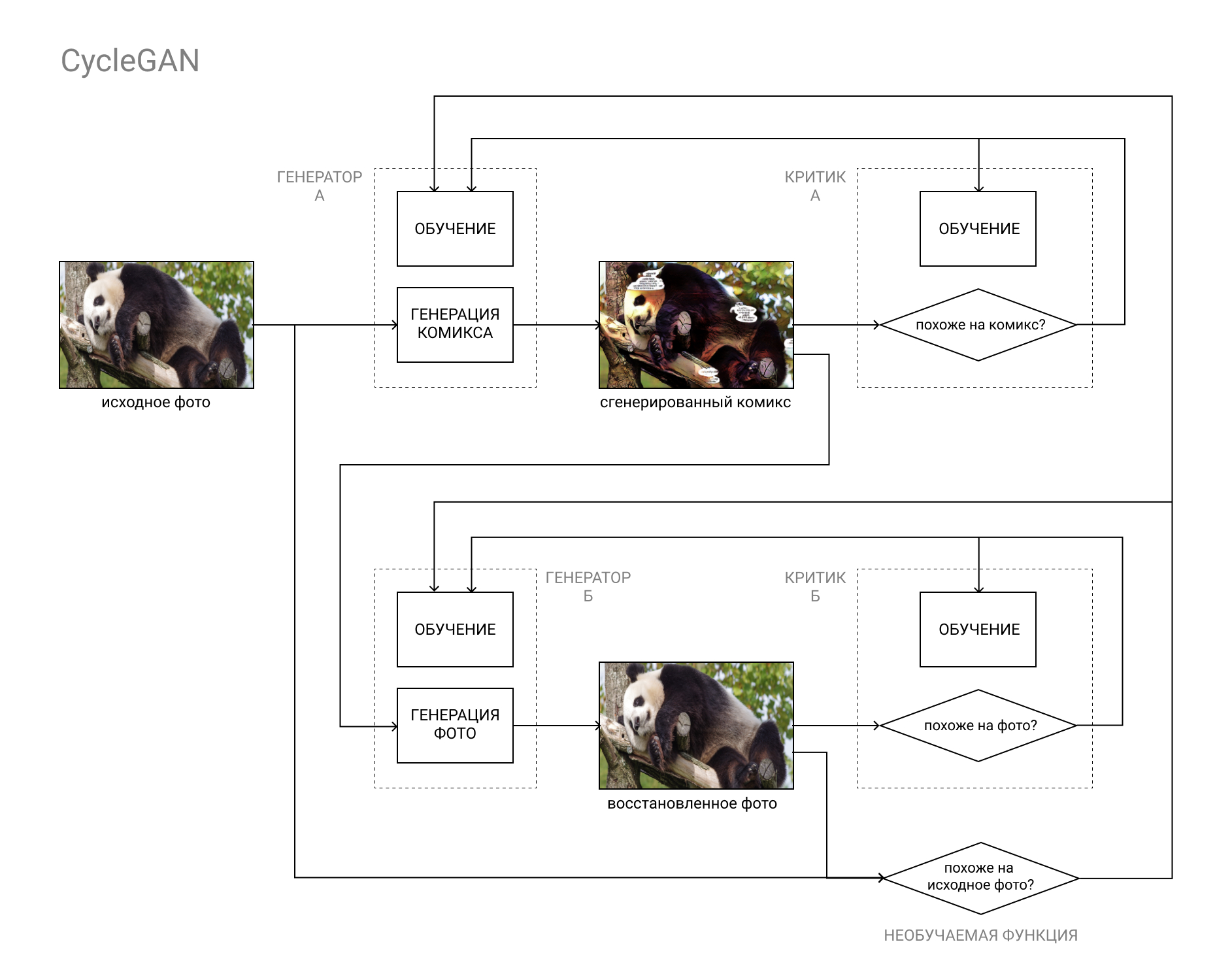
Модели обучаются как на основе сравнения исходного фото с восстановленным (в результате цикла “А”-”Б”-”А”, “фото-комикс-фото), так и данных Критиков, как в обычной GAN.
Это дает возможность выполнить обе части нашей задачи: сгенерировать комикс, неотличимый от других комиксов, и при этом похожий на исходное фото.
Установка и проверка модели
Для реализации нашего хитрого плана нам понадобятся:
- Видеокарта с поддержкой CUDA и 8гб RAM
- ОС Linux
- Miniconda/Anaconda c Python 3.5+
Видеокарты с менее чем 8гб RAM тоже могут подойти, если поколдовать с настройками. На Windows тоже будет работать, но медленнее, у меня разница была, как минимум, в 1,5-2 раза.
Если у вас нет GPU с поддержкой CUDA, или вам лень все это настраивать, всегда можно воспользоваться Google Colab. Если найдется достаточное количество желающих, запилю туториал и по тому, как провернуть все нижеперечисленное в гугловом облаке.
Miniconda можно взять здесь
Инструкции по установке
После установки Anaconda/Miniconda (далее — conda), создадим новую среду для наших экспериментов и активируем ее:
(Пользователям Windows нужно сначала запустить Anaconda Prompt из меню Пуск)
conda create --name cyclegan
conda activate cycleganТеперь все пакеты будут установлены в активную среду, не затрагивая остальные среды. Это удобно, если нужны определенные комбинации версий различных пакетов, например если вы используете чей-то старый код и вам нужно установить устаревшие пакеты, не испортив себе жизнь и основную рабочую среду.
Далее просто следуем инструкциям README.MD из дистрибутива:
Сохраним себе дистрибутив CycleGAN:
(или же просто скачаем архив с GitHub)
git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
cd pytorch-CycleGAN-and-pix2pixУстановим нужные пакеты:
conda install numpy pyyaml mkl mkl-include setuptools cmake cffi typing
conda install pytorch torchvision -c pytorch
conda install visdom dominate -c conda-forgeСкачаем готовый датасет и соответствующую модель:
bash ./datasets/download_cyclegan_dataset.sh horse2zebra
bash ./scripts/download_cyclegan_model.sh horse2zebraОбратите внимание на то, какие фотографии есть в скачанном датасете.
Если открыть файлы скриптов из предыдущего абзаца, можно увидеть, что есть и другие готовые датасеты и модели для них.
Наконец, протестируем модель на скачанном наборе данных:
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout
Результаты будут сохранены в папке /results/horse2zebra_pretrained/
Создание обучающей выборки
Не менее важным этапом после выбора архитектуры будущей модели (и поиска готовой реализации на github) является составление dataset’a, или набора данных, на которых мы будем обучать и проверять нашу модель.
От того, какие данные мы будем использовать, зависит практически все. Например, UGATIT для selfie2anime бота была натренирована на женских селфи и женских лицах из аниме. Поэтому с мужскими фото она ведет себя как минимум забавно,В качестве образцов фотографий я использовал DIV2K и Urban100, приправленные фотками звезд из гугла для пущего разнообразия.
заменяя брутальных бородатых мужчин на маленьких девочек с высоким воротником. На фото ваш покорный слуга после того, как узнал, что смотрит аниме.
Как вы уже поняли, стоит отбирать те фото\комиксы, которые вы хотите использовать на входе и получить на выходе. Планируете обрабатывать селфи — добавляете селфи и крупные планы лиц из комиксов, фото зданий — добавляете фото зданий и страницы из комиксов со зданиями.

Комиксы я взял из вселенной Marvel, страницы целиком, выкинув рекламу и анонсы, где рисовка не похожа на комикс. Ссылку приложить не могу по понятным причинам, но по запросу Marvel Comics вы легко найдете отсканированные варианты на любимых сайтах с комиксами, если вы понимаете, о чем я.
Важно обращать внимание на рисовку, она отличается у разных серий, и на цветовую гамму.

У меня было много дедпула и спайдермена, поэтому кожа сильно уходит в красный.
Неполный список остальных публичных датасетов вы найдете тут.
Структура папок в нашем датасете должна быть следующей:
selfie2comics
├── trainA
├── trainB
├── testA
└── testB
trainA — наши фото (порядка 1000шт)
testA — несколько фото для тестов модели (30шт. будет достаточно)
trainB — наши комиксы (порядка 1000шт.)
testB — комиксы для тестов (30шт.)
Датасет желательно разместить на SSD, если есть такая возможность.
На сегодня это все, в следующем выпуске мы начнем обучать модель и получим первые результаты!
Обязательно пишите, если у вас что-то пошло не так, это поможет улучшить руководство и облегчит страдания последующих читателей.
Если вы уже попробовали обучить модель, не стесняйтесь делиться результатами в комментариях. До новых встреч!
Комментариев нет:
Отправить комментарий