Во-первых, хоть тесты и работали, причем вполне успешно, мы не имели четкого понимания, что у нас покрыто тестами, а что нет. Какое-то представление о степени покрытия, конечно, было, но количественно мы его не измеряли. Во-вторых, состав тестов со временем увеличился и разные тесты зачастую тестировали одно и то же, т.к. на разных скриншотах какая-нибудь часть да совпадала с этой же частью, но на другом скриншоте. В итоге, даже незначительные изменения в CSS могли завалить сразу много тестов и требовали обновления большого количества эталонов. В-третьих, в нашем продукте появилась темная тема, и, чтобы хоть как-то покрыть ее тестами, некоторые тесты выборочно были переведены на использование темной темы, что также не добавило ясности к проблеме с определением степени покрытия.
Оптимизация быстродействия
Начали, как ни странно, с оптимизации быстродействия. Объясню, почему. Наши визуальные тесты базируются на Storybook. Каждая story в storybook — это не отдельно взятая компонента, а целый «блок» (например, грид со списком сущностей, карточка сущности, диалог или даже приложение в целом). Чтобы отобразить этот блок, необходимо «накачать» story данными, причем не только данными, отображаемыми пользователю, но и состоянием компонент, используемых внутри блока. Эта информация хранятся вместе с исходным кодом в виде json-файлов, содержащих сериализованное представление состояния приложения (redux store). Да, эти данные, мягко говоря, избыточны, но зато сильно упрощают создание тестов. Чтобы создать новый тест, мы просто открываем в приложении нужную карточку, список или диалог, делаем снимок текущего состояния приложения и сериализуем его в файл. Затем добавляем новую story и тесты, которые делают скриншоты этой story (все это в несколько строк кода).
Такой подход неизбежно увеличивает размер бандла. Степень дублирования данных в нем просто «зашкаливает». При прогоне тестов движок gemini выполняет каждый тестовый набор (test suite) в отдельной сессии браузера. Каждая сессия грузит бандл заново и размер бандла в такой схеме имеет далеко не последнее значение.
Чтобы уменьшить время прогона тестов, мы уменьшили количество test-suite, увеличив количество тестов в них. Таким образом, один test suite мог затрагивать сразу несколько story. В такой схеме мы практически потеряли возможность «скринить» только определенную область экрана из-за того, что Gemini позволяет задавать область скриншота только для test suite в целом (хотя API и позволяет делать это перед каждым скриншотом, но на практике это не работает).
Отсутствие возможности ограничивать область скриншота в тестах привело к дублированию визуальной информации на эталонных снимках. Пока тестов было не много, эта проблема не казалась значительной. Да и UI менялся не особо часто. Но вечно это продолжаться не могло — на горизонте замаячил редизайн.
Забегая вперед, скажу, что в Hermione область скриншота можно задавать для каждого снимка и, на первый взгляд, переход на новый движок решил бы все вопросы. Но большие test suites нам все равно пришлось бы «дробить». Дело в том, что визуальные тесты по своей природе не отличаются стабильностью (это может быть связано с разными причинами, например, с сетевыми лагами, с использованием анимации или с «погодой на Марсе») и без автоматических переповторов обойтись очень сложно. И Gemini и Hermione выполняют переповторы для test suite в целом, и чем «толще» test-suite, тем меньше вероятность его успешного прохождения при переповторах, т.к. на очередном прогоне могут упасть тесты, ранее успешно выполненные. Для толстых test suite нам пришлось реализовать альтернативную встроенной в движок Gemini схему переповторов и делать это еще раз при переходе на новый движок очень не хотелось.
Поэтому, чтобы ускорить загрузку test-suite, мы разбили монолитный бандл на части, выделив каждый снимок состояния приложения в отдельный «кусок», подгружаемый " по требованию" для каждой story в отдельности. Код создания stories теперь выглядит так:
// visual-regression.stories.js
import React from 'react';
import StoryProvider from './story-provider';
const stories = storiesOf('visual-regression', module);
[
{ name: 'Contract', loadData: import('./snapshots/contract.testdata') },
{ name: 'ExecutionTask', loadData: import('./snapshots/execution-task.testdata') },
{ name: 'ExecutionAssignment', loadData: import('./snapshots/execution-assignment.testdata') },
{ name: 'DocumentTemplate', loadData: import('./snapshots/document-template.testdata') },
{ name: 'Explorer', loadData: import('./snapshots/explorer.testdata') },
{ name: 'Inbox', loadData: import('./snapshots/inbox.testdata') },
]
.map(story => {
stories
.add(story.name, () => <StoryProvider loadSnapshot={story.loadData} />)
.add(`${story.name}Dark`, () => <StoryProvider loadSnapshot={story.loadData} theme='night' />);
});
Для создания story используется компонента StoryProvider (ее код будет приведен чуть ниже). Снимки состояний подгружаются с использованием функции динамического импорта. Разные story отличаются друг от друга только снимками состояний. Для темной темы генерируется своя story, использующая тот же самый снимок состояния, что и story для светлой темы. В контексте storybook это выглядит так:
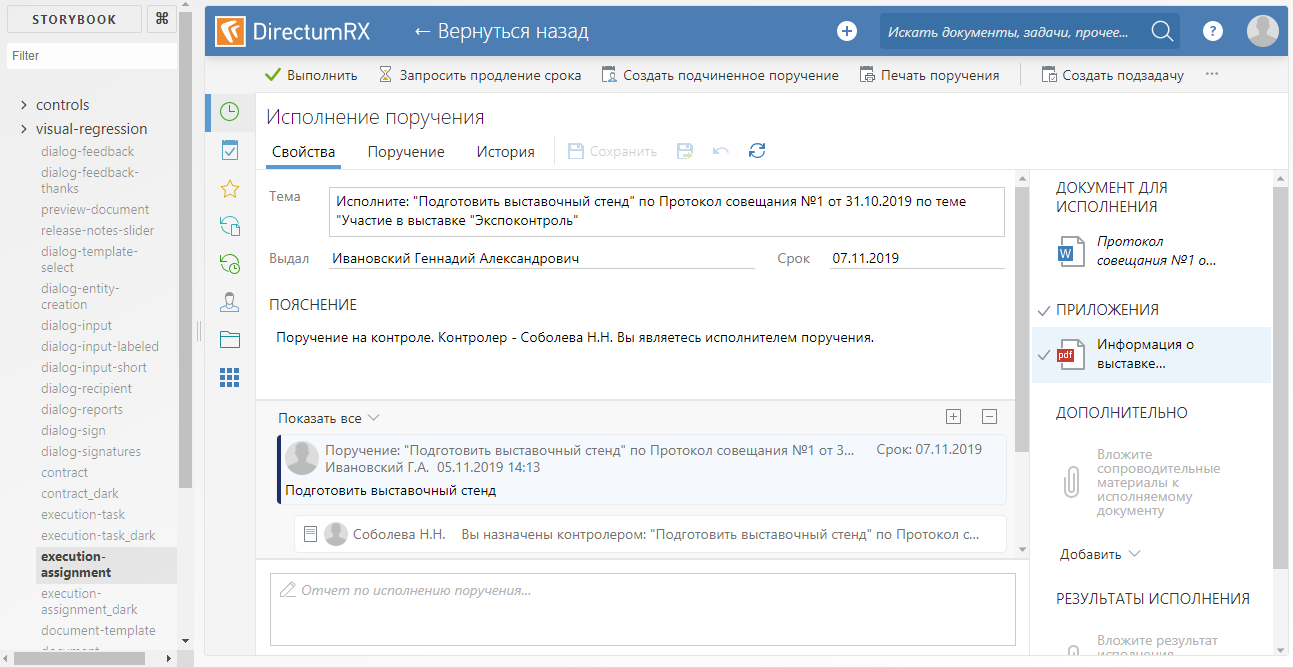
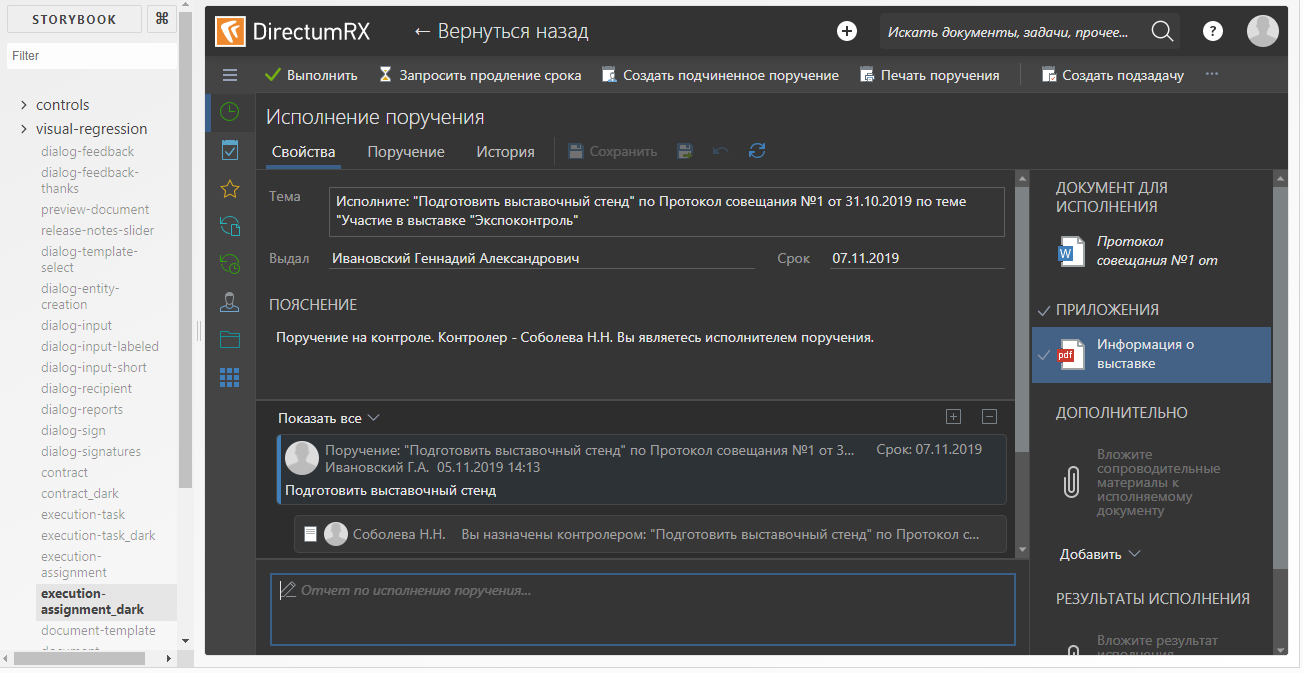
Компонент StoryProvider принимает на вход callback для загрузки снимка, в котором вызывается функция import(). Функция import() работает асинхронно, поэтому снимать скриншот сразу после загрузки story нельзя — мы рискуем снять пустоту. Для того, чтобы отловить момент окончания загрузки, на все время загрузки провайдер рендерит маркерный DOM-элемент, сигнализирующий движку тестов, что со скриншотом надо повременить:
// story-provider.js
const propsStub = {
// Свойства-заглушки, для отключения запросов к серверу
. . .
};
type Props = {
loadSnapshot: () => Object,
theme: ?string
};
const StoryProvider = (props: Props) => {
const [ snapshotState, setsnapshotState ] = React.useState(null);
React.useEffect(() => {
// Асинхронно грузим снимок
(async() => setsnapshotState((await props.loadSnapshot).default))();
});
if (!snapshotState)
// Информируем движок тестов о том, что скриншот делать рано
return <div className={'loading-stub'}>Loading...</div>;
// Подгружаем снимок метаданных
snapshotState.metadata = require('./snapshots/metadata');
// Создаем redux-хранилище из снимка
const store = createMockStore(snapshotState);
// Применяем тему
applyTheme(props.theme);
return (
<Provider store={store}>
<MemoryRouter>
<App {...propsStub} />
</MemoryRouter>
</Provider>
);
};
export default StoryProvider;
Дополнительно, чтобы уменьшить размер бандла, отключаем добавление в бандл source maps. Но чтобы не потерять возможность отладки story (мало ли что), делаем это под условием:
// .storybook/webpack.config.js
...
module.exports = {
...
devtool: process.env.NODE_ENV === 'vr-test' ? '(none)' : 'eval-source-map'
};
// package.json
{
...
"scripts": {
...
"storybook": "start-storybook",
"build-storybook": "cross-env NODE_ENV=vr-test build-storybook -o ./storybook-static",
...
},
Скрипт npm run build-storybook собирает статический storybook без sourcemap в папку storybook-static. Он используется при выполнении тестов. А скрипт npm run storybook используется для разработки и отладки тестовых story.
Устранение дублирования визуальной информации
Как я уже говорил выше, Gemini позволяет задавать селекторы области скриншота для test suite в целом, а значит для полного решения проблемы с дублированием визуальной информации на скриншотах нам пришлось бы делать свой test suite для каждого скриншота. Даже с учетом проведенной оптимизации загрузки story это выглядело не слишком оптимистично с точки зрения быстродействия и мы задумались о смене тестового движка.
Собственно, почему Hermione? На текущий момент репозиторий Gemini помечен как deprecated и нам, рано или поздно, нужно было куда-то «переезжать». Структура файла конфигурации Hermione идентична структуре файла конфигурации Gemini и мы смогли этот конфиг повторно использовать. Плагины у Gemini и Hermione также общие. Кроме того, мы смогли повторно использовать инфраструктуру тестов — виртуальные машины и развернутый selenium-grid.
В отличие от Gemini, Hermione не позиционируется как инструмент только для регрессивного тестирования верстки. Его возможности по манипуляции браузером гораздо шире и ограничены только возможностями Webdriver IO. В сочетании с mocha этот движок удобно использовать скорее для функционального тестирования (имитирующего действия пользователя), чем для тестирования верстки. Для регрессивного тестирования верстки Hermione предоставляет только метод assertView(), сравнивающий скриншот страницы браузера с эталоном. Скриншот можно ограничить заданной с помощью css-селекторов областью.
Применительно к нашему случаю тест для каждой отдельно взятой story выглядел бы примерно так:
// Тестируем визуальную регрессию
describe('Visual regression', function() {
it('Contract card should equal to etalon', function() {
return this.browser
// Загрузить story в браузер
.url('http://localhost:8080/iframe.html?selectedKind=visual-regression&selectedStory=ContractDark')
// Ждать, пока подгрузятся данные и отрисуется story
.waitForVisible('.loading-stub', true)
// Снять скриншот области экрана и сравнить его с эталоном
.assertView('layout', '.form');
})
});
Метод waitForVisible(), несмотря на свое название, позволяет ожидать не только появления, но и скрытия элемента, если выставить второму параметру значение true. Здесь мы используем его для ожидания скрытия маркерного элемента, сигнализирующего о том, что снимок данных еще не загружен и story еще не готова для скриншота.
Если вы попытаетесь отыскать, метод waitForVisible() в документации Hermione, то ничего не найдете. Дело в том, что метод waitForVisible() — это метод API Webdriver IO. Метод url(), соответственно, тоже. В метод url() мы передаем адрес фрейма конкретного story, а не всего storybook. Во-первых, это нужно для того, чтобы в окне браузера не отображался список stories — его нам тестировать не нужно. Во-вторых, в случае необходимости мы можем иметь доступ к DOM-элементам внутри фрейма (методы webdriverIO позволяют выполнять JavaScript код в контексте браузера).
Для упрощения написания тестов мы сделали свою обертку над mocha-тестами. Дело в том, что особого смысла в детальной проработке тестовых случаев (test cases) для регрессивного тестирования нет. Все тестовые случаи одинаковы — 'should equal to etalon'. Ну и дублировать код ожидания загрузки данных в каждом тесте тоже не хочется. Поэтому одинаковая для всех тестов «обезьянья» работа делегируется функции-обертке, а сами тесты пишутся декларативно (ну, почти). Вот текст этой функции:
const themes = [ 'default', 'dark' ];
const rootClassName = '.explorer';
const loadingStubClassName = '.loading-stub';
const timeout = 2000;
function createTestSuite(testSuite) {
const { name, storyName, browsers, testCases, selector } = testSuite;
// Если необходимо, ограничиваем выполнение только в заданными браузерами
browsers && hermione.only.in(browsers);
// Создаем тесты для всех тем
themes.forEach(theme => {
describe(`${name}_${theme}`, () => it('should equal to etalon', function() {
let browser = this.browser
// Открываем страницу story
.url(`${storybookUrl}/iframe.html?selectedKind=visual-regression&selectedStory=${storyName}-${theme}`)
// Ждем окончания загрузки данных
.waitForVisible(loadingStubClassName, timeout, true)
.waitForVisible(rootClassName);
// Отрабатываем тестовые случаи (если они заданы)
if (testCases && testCases.length > 0) {
testCases.forEach(testCase => {
if (testCase.before)
browser = testCase.before(browser);
browser = browser.assertView(`${name}__${testCase.name}_${theme}`,
testCase.selector || selector || rootClassName, testCase.options);
});
return browser;
}
// Если тестовых случаев нет, просто выполняем скриншот
return browser.assertView(`${name}_${theme}`, selector || rootClassName);
}));
});
}
На вход функции передается объект, описывающий test suite. Каждый test suite строится по следующему сценарию: делаем скриншот основного layout-а (например, области карточки сущности или области списка сущности), затем программно нажимаем кнопки, которые могут привести к появлению других элементов (например, всплывающих панелей или контекстных меню) и «скриним» каждый такой элемент в отдельности. Таким образом, мы имитируем действия пользователя в браузере, но не с целью протестировать какой-то бизнес-сценарий, а просто для того, чтобы «заснять» максимально возможное число визуальных компонент. При этом дублирование визуальной информации на скриншотах минимально, т.к. скриншоты делаются «точечно», с использованием селекторов. Пример test suite:
// explorer-suite.js
// Набор тестов для регрессивного тестирования верстки проводника системы
module.exports = {
// Имя story, используемой для скриншотов
storyName: 'explorer',
// Имя тестового набора
name: 'explorer',
// Перечень браузеров, в которых должен запускаться тестовый набор
browsers: [
'chrome-1920x1080', 'ie-1920x1080'
],
// Тестовые случаи
testCases: [
{
// Тестируем общий вид
name: 'layout'
},
{
// Тестируем область уведомлений
name: 'notification-area',
selector: '.notification-area__popup',
before: b => b
.click('.notification-area__popup-button')
.waitForVisible('.notification-area__popup')
.execute(function() {
// Этот код выполняется в контексте браузера
document.querySelectorAll('.expandable-item__content')[2].click();
})
},
//...
]
};
// tests.js
[
require('./suites/explorer-suite'),
//...
]
.forEach(suite => createTestSuite(suite));
Определение степени покрытия
Итак, с быстродействием и избыточностью разобрались, осталось разобраться, с эффективностью нашего тестирования, то есть определить степень покрытия кода тестами (здесь под кодом я понимаю таблицы стилей CSS).
Для тестовых story мы эмпирически выбирали максимально сложные по наполнению карточки, списки и другие элементы, чтобы одним скриншотом покрыть по возможности большее количество стилей. Например, для тестирования карточки сущности выбирались карточки с большим количеством разнотипных контролов (текстовых, числовых, перечислений, дат, гридов и т.п). Для разных типов сущностей карточки имеют свою специфику, например, из карточки документа можно показать панель со списком версий документа, а в карточке задачи отображается переписка по выполнению этой задачи. Соответственно, для каждого типа сущности создавалась своя story и набор тестов, специфичных для этого типа и т.п. В конце концов мы прикинули, что вроде все покрыли тестами, но хотелось чуть большей уверенности чем «вроде».
Для оценки покрытия в Chrome DevTools есть инструмент с очень подходящим для этого случая названием Coverage:
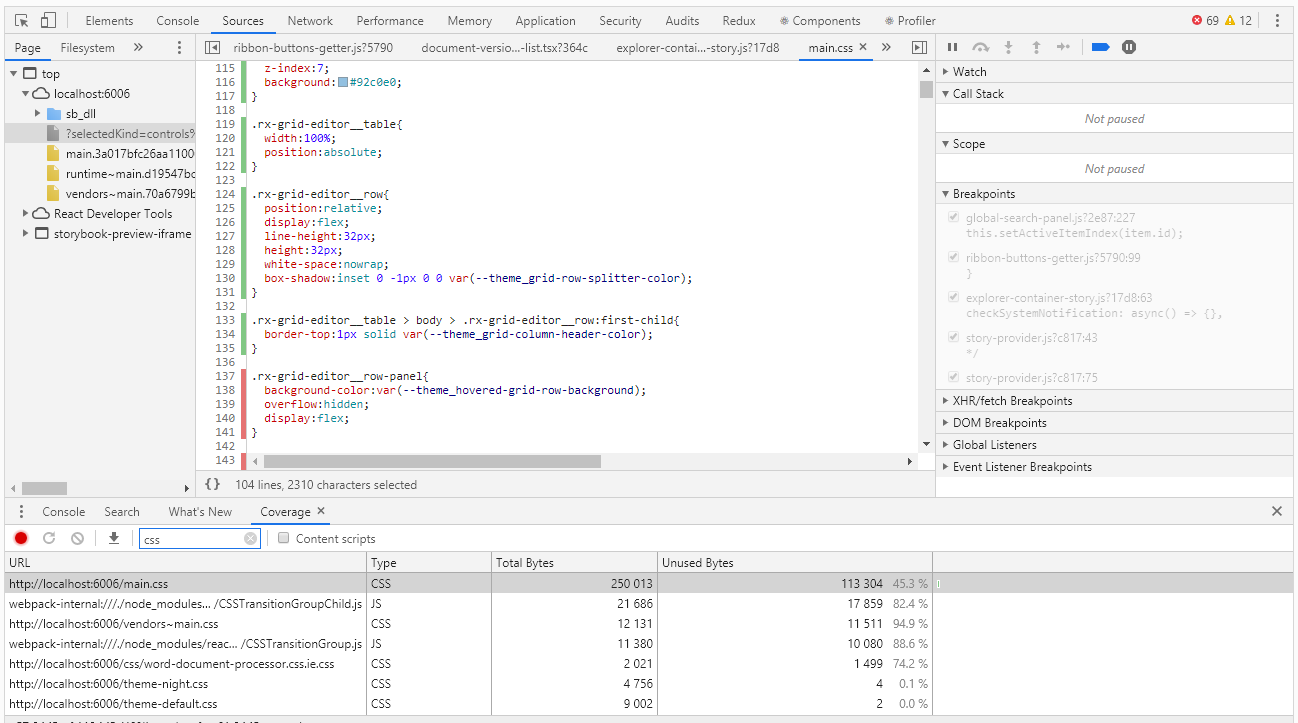
Coverage позволяет определить, какие стили или какой js-код был использован при работе со страницей браузера. В отчете об использовании зелеными полосками помечается использовавшийся код, красными — не использовавшийся. И все бы хорошо, если бы у нас было приложение уровня «hello, world», но что делать, когда у нас тысячи строк кода? Разработчики Coverage это хорошо понимали и предусмотрели возможность экспорта отчета в файл, с которым уже можно работать программно.
Сразу скажу, что пока мы не нашли способа собирать степень покрытия автоматически. Теоретически это можно сделать с иcпользованием headless-браузера pupeteer, но pupeteer не работает под управлением selenium, а значит повторно использовать код наших тестов не получится. Поэтому пока пропустим эту чрезвычайно интересную тему и поработаем ручками.
Прогнав тесты в ручном режиме получаем отчет о покрытии, который представляет собой json-файл. В отчете для каждого css, js, ts и т.п. файла указаны его текст (в одну строку) и интервалы используемого в этом тексте кода (в виде индексов символов этой строки). Ниже приведен кусочек отчета:
[
{
"url": "http://localhost:6006/theme-default.css",
"ranges": [
{
"start": 0,
"end": 8127
}
],
"text": "... --theme_primary-accent: #5b9bd5;\r\n --theme_primary-light: #ffffff;\r\n --theme_primary: #f4f4f4;\r\n ..."
},
{
"url": "http://localhost:6006/main.css",
"ranges": [
{
"start": 0,
"end": 610
},
{
"start": 728,
"end": 754
}
]
"text": "... \r\n line-height:1;\r\n}\r\n\r\nol, ul{\r\n list-style:none;\r\n}\r\n\r\nblockquote, q..."
]
На первый взгляд, нет ничего сложного в том, чтобы найти неиспользуемые css-селекторы. Но что потом делать с этой информацией? Ведь в конечном счете нам нужно найти не конкретные селекторы, а компоненты, которые мы забыли покрыть тестами. Стили одной компоненты могут быть заданы не одним десятком селекторов. В итоге по результатам анализа отчета мы получим сотни неиспользуемых селекторов, и, если разбираться с каждым из них, можно убить кучу времени.
Здесь нам в помощь — регулярные выражения. Конечно, они будут работать только при выполнении соглашений об именовании css-классов (в нашем коде css-классы именуются в соответствии с методологией БЭМ — имя-блока__имя-элемента_модификатор). С помощью регулярных выражений мы вычисляем уникальные значения имен блоков, которые уже не составляет труда связать с компонентами. Элементы и модификаторы нас, конечно, тоже интересуют, но далеко не в первую очередь, сначала надо разобраться с более крупной «рыбой». Ниже приведен скрипт для обработки отчета Coverage
const modules = require('./coverage.json').filter(e => e.url.endsWith('.css'));
function processRange(module, rangeStart, rangeEnd, isUsed) {
const rules = module.text.slice(rangeStart, rangeEnd);
if (rules) {
const regex = /^\.([^\d{:,)_ ]+-?)+/gm;
const classNames = rules.match(regex);
classNames && classNames.forEach(name => selectors[name] = selectors[name] || isUsed);
}
}
let previousEnd, selectors = {};
modules.forEach(module => {
previousEnd = 0;
for (const range of module.ranges) {
processRange(module, previousEnd, range.start, false);
processRange(module, range.start, range.end, true);
previousEnd = range.end;
}
processRange(module, previousEnd, module.length, false);
});
console.log('className;isUsed');
Object.keys(selectors).sort().forEach(s => {
console.log(`${s};${selectors[s]}`);
});
Выполняем скрипт, предварительно положив рядом экспортированный из Chrome DevTools файл coverage.json и записываем выхлоп в .csv-файл:
node coverage.js > coverage.csv
Этот файл можно открыть помощью excel и проанализировать данные, в том числе определить процент покрытия кода тестами.

Вместо резюме
Использование storybook в качестве основы для визуальных тестов вполне себя оправдало — мы имеем достаточную степень покрытия css-кода тестами при относительно небольшом количестве stories и минимальных затратах на создание новых.
Переход на новый движок позволил нам устранить дублирование визуальной информации в скриншотах, что существенно упростило поддержку существующих тестов.
Степень покрытия css-кода измеряема и, время от времени, контролируется. Тут конечно большой вопрос – как не забыть про необходимость этого контроля и как не пропустить что-либо в процессе сбора информации о покрытии. В идеале хотелось бы измерять степень покрытия автоматически при каждом прогоне тестов, чтобы при достижении заданного порога тесты падали бы с ошибкой. Будем над этим работать, если появятся новости – обязательно расскажу.
Комментариев нет:
Отправить комментарий