 В WinAPI есть функция CreateRemoteThread, позволяющая запустить новый поток в адресном пространстве другого процесса. Её можно использовать для разнообразных DLL-инъекций как с нехорошими целями (читы в играх, кража паролей, и т. д.), так и для того, чтобы на лету исправить баг в работающей программе, или добавить плагины туда, где они не были предусмотрены.
В WinAPI есть функция CreateRemoteThread, позволяющая запустить новый поток в адресном пространстве другого процесса. Её можно использовать для разнообразных DLL-инъекций как с нехорошими целями (читы в играх, кража паролей, и т. д.), так и для того, чтобы на лету исправить баг в работающей программе, или добавить плагины туда, где они не были предусмотрены.
В целом эта функция обладает сомнительной прикладной полезностью, поэтому не удивительно, что в Linux готового аналога CreateRemoteThread нет. Однако, мне было интересно, как он может быть реализован. Изучение темы вылилось в неплохое приключение.
Я подробно расскажу о том, как с помощью спецификации ELF, некоторого знания архитектуры x86_64 и системных вызовов Linux написать свой маленький кусочек отладчика, способный загрузить и исполнить произвольный код в уже запущенном и работающем процессе.
Для понимания текста потребуются базовые знания о системном программировании под Linux: язык Си, написание и отладка программ на нём, осознание роли машинного кода и памяти в работе компьютера, понятие системных вызовов, знакомство с основными библиотеками, навык чтения документации.
В итоге у меня получилось «добавить» возможность предпросмотра паролей в Gnome Control Center:
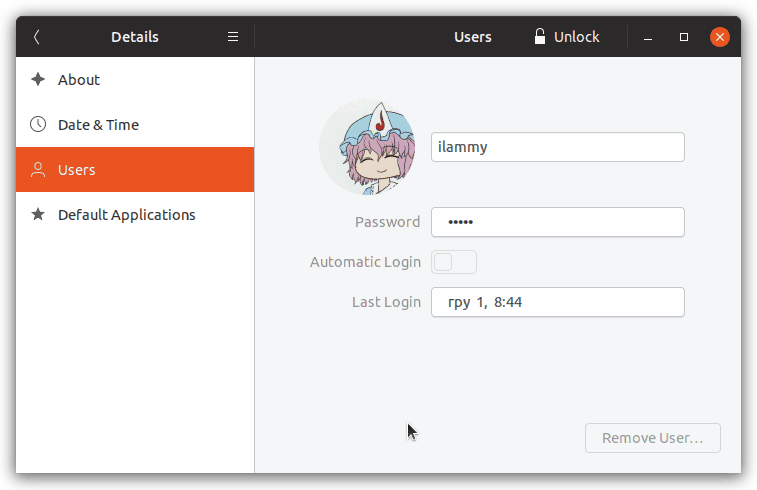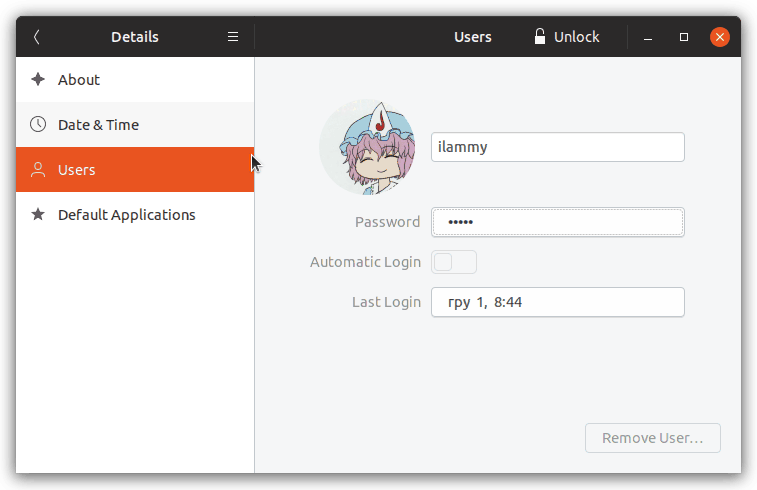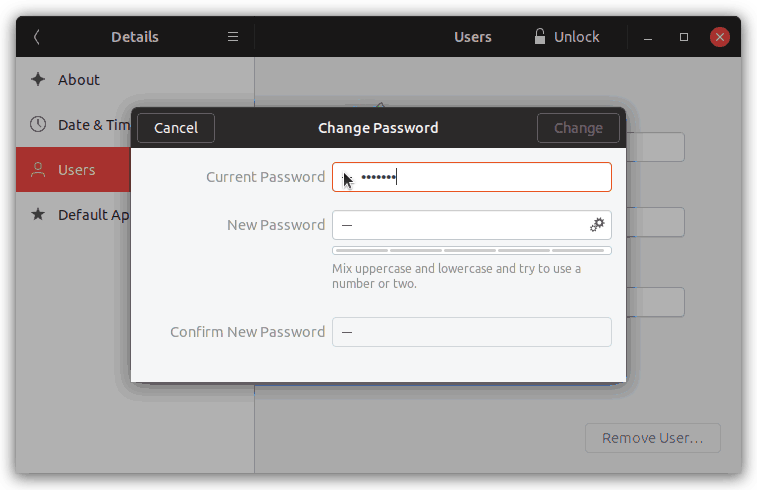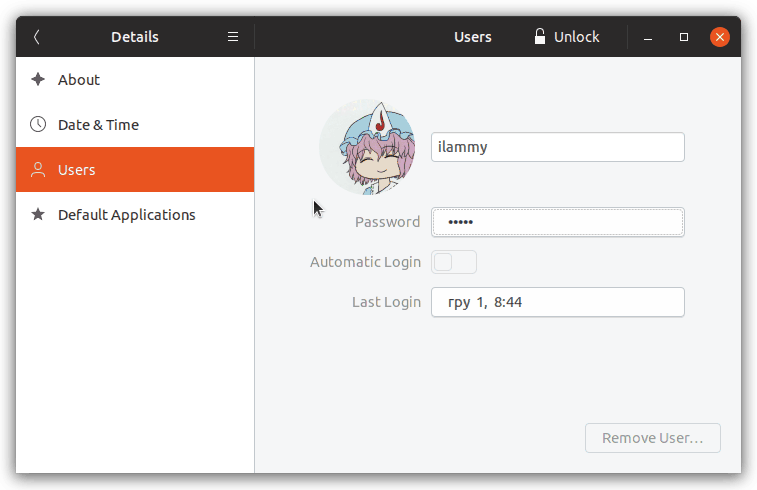
Основные идеи
Если бы в требованиях не было пункта о загрузке кода в уже работающий процесс, то решение было бы предельно простым: LD_PRELOAD. Эта переменная окружения позволяет подгрузить вместе с приложением произвольную библиотеку. В разделяемых библиотеках можно определять функции-конструкторы, исполняемые при загрузке библиотеки.
Вместе LD_PRELOAD и конструкторы позволяют выполнить произвольный код в любом процессе, использующем динамический загрузчик. Это относительно широко известная возможность, часто используемая для отладки. Например, вместе с приложением можно загрузить свою библиотеку, определяющую функции malloc() и free(), которая бы могла помочь отловить утечки памяти.
К сожалению, LD_PRELOAD работает только в процессе запуска процесса. С её помощью нельзя загрузить библиотеку в уже запущенный процесс. Для загрузки библиотек во время работы процесса существует функция dlopen(), но, очевидно, процесс сам должен её вызывать для загрузки плагинов.
О статических исполняемых файлахLD_PRELOAD работает только с программами, использующими динамический загрузчик. Если программа собиралась с ключом
-static, то она включает в себя все необходимые библиотеки. В этом случае разрешение зависимостей в библиотеках выполняется во время сборки и программа обычно не готова и не способна динамически загружать библиотеки после сборки, во время исполнения.В статически собранные программы можно внедрять код во время исполнения, но это следует делать чуть-чуть по-другому. И это не вполне безопасно, так как программа может быть не готова к такому повороту.
В общем, готового удобного решения нет, придётся писать свой велосипед. Иначе вы бы не читали этот текст :)
Концептуально, чтобы заставить чужой процесс выполнить какой-то код, надо произвести следующие действия:
- Получить управление в целевом процессе.
- Загрузить код в память целевого процесса.
- Подготовить загруженный код к исполнению в целевом процессе.
- Организовать исполнение загруженного кода целевым процессом.
Поехали...
Получение управления в процессе
Прежде всего нам потребуется подчинить целевой процесс своей воле. Ведь обычно процессы исполняют только свой собственный код, или код загруженных библиотек, или результаты JIT-компиляции. Но точно не наш код.
Один из вариантов — это использовать какую-нибудь уязвимость в процессе, позволяющую перехватить управление. Классический пример из учебников: переполнение буфера, позволяющее переписать адрес возврата на стеке. Это весело, иногда даже работает, но не подходит для общего случая.
Мы будем использовать другой, честный способ получить управление: отладочные системные вызовы. Интерактивные отладчики отлично умеют останавливать сторонние процессы, вычислять выражения, и многие другие вещи. Могут они — сможем и мы.
В Linux основным отладочным системным вызовом является ptrace(). Он позволяет подключаться к процессам, исследовать их состояние, управлять ходом их исполнения. ptrace() вполне прилично задокументирован сам по себе, но детали его использования становятся ясны только на практике.
Загрузка кода в память процесса
В случае с переполнением буфера полезная нагрузка (шелл-код) обычно включается в содержимое, переполняющее тот самый буфер. При использовании отладчика нужный код можно записать в память процесса напрямую. В WinAPI для этого есть специальная функция WriteProcessMemory. Linux же для этих целей соблюдает UNIX way: для каждого процесса в системе есть файл /proc/$pid/mem, отображающий память этого процесса. Записать чего-нибудь в память процессу можно с помощью обычного ввода-вывода.
Подготовка кода к исполнению
Просто записать код в память мало. Его ещё надо записать в исполняемую память. В случае записи через уязвимость с этим есть нетривиальные сложности, но так как мы можем полностью контролировать целевой процесс, то для нас не будет проблемой найти или выделить себе «правильной» памяти.
Другой важный момент подготовки — это сам шелл-код. В нём мы наверняка захотим использовать какие-нибудь функции из библиотек, вроде ввода-вывода, графических примитивов, и так далее. Однако, записывать нам придётся голый машинный код, который сам по себе понятия не имеет об адресах всех этих классных функций в библиотеках. Откуда же их взять?
Чтобы упростить жизнь операционной системе и усложнить жизнь вредоносному коду, библиотеки обычно не используют фиксированные адреса (и содержат так называемый позиционно-независимый код). Так что адреса не получится угадать.
При нормальном запуске процесса за определение точных адресов библиотек отвечает загрузчик, выполняющий релокации. Однако, он отрабатывает только один раз на старте. Если процесс позволяет динамическую загрузку библиотек, то в нём присутствует динамический загрузчик, умеющий делать то же самое во время работы процесса. Однако, адрес динамического загрузчика тоже не фиксированный.
В общем, с библиотеками можно выделить четыре варианта действий:
- не использовать библиотеки вовсе, всё делать на чистых системных вызовах
- вкладывать в шелл-код копии всех нужных библиотек
- выполнить работу динамического загрузчика самостоятельно
- найти динамический загрузчик и заставить его загрузить наши библиотеки
Мы выберем последний, так как библиотеки хочется, а писать свой полноценный загрузчик долго. Это не самый скрытный способ, и не самый интересный, зато наиболее простой, мощный и надёжный.
Передача управления коду
ptrace() позволяет изменять регистры процессора, так что проблем с передачей управления загруженному и подготовленному коду возникнуть не должно: просто записываем в регистр %rip адрес нашего кода — и вуаля! Однако, на деле всё не так просто. Сложности связаны с тем, что отлаживаемый процесс вообще-то никуда не делся и у него тоже есть какой-то код, который исполнялся и будет исполняться дальше.
Эскиз решения
Итого, внедрять свой поток в сторонний процесс мы будем следующим образом:
- Подключаемся к целевому процессу для отладки.
- Находим в памяти нужные библиотеки:
- libdl — для загрузки новой библиотеки
- libpthread — для запуска нового потока
- Находим в библиотеках нужные функции:
- libdl: dlopen(), dlsym()
- libpthread: pthread_create(), pthread_detach()
-
Внедряем в память целевого процесса шелл-код:
void shellcode(void) { void *payload = dlopen("/path/to/payload.so", RTLD_LAZY); void *entry = dlsym(payload, "entry_point"); pthread_t thread; pthread_create(&thread, NULL, entry, NULL); pthread_detach(thread); } - Даём шелл-коду исполниться.
В результате для нас всё правильно сделают библиотеки: загрузят в память нашу библиотеку с нужным нам кодом и запустят новый поток, исполняющий этот код.
Ограничения
Описанный выше подход накладывает определённые ограничения:
- У загрузчика должны быть достаточные права для отладки целевого процесса.
- Процесс должен использовать libdl (готов к динамической загрузке модулей).
- Процесс должен использовать libpthread (готов к многопоточности).
- Не поддерживаются приложения, собранные статически.
Кроме того, лично мне лень заморачиваться с поддержкой всех-всех архитектур, так что мы ограничимся только x86_64. (Даже 32-битная x86 была бы сложнее.)
Как можно заметить, всё это ставит крест на скрытном применении с вредоносными целями. Однако, задача всё ещё сохраняет исследовательский интерес и даже оставляет слабую возможность для промышленного использования.
Отступление: об использовании libdl и libpthread
Опытный читатель-специалист может задаться вопросом: зачем требовать наличие libdl, если в glibc уже встроены внутренние функции __libc_dlopen_mode() и __libc_dlsym(), а libdl — это просто обёртка над ними? Аналогично, зачем требовать libpthread, если новый поток можно легко создать с помощью системного вызова clone()?
Ведь в интернетах есть далеко не один пример того, как ими пользуются:
Они даже упоминаются в популярной хакерской литературе:
- Learning Linux Binary Analysis
- The Art of Memory Forensics
Так почему нет? Ну, как минимум потому, что мы пишем не вредоносный код, где подойдёт решение, опускающее 90% проверок, занимающее в 20 раз меньше места, но и работающее в 80% случаев. Кроме того, я хотел попробовать всё своими руками.
Действительно, libdl не является необходимостью для загрузки библиотеки в случае glibc. Её использование процессом говорит о том, что он явно готов к динамической загрузке кода. Не смотря на это, в принципе, от использования libdl можно отказаться (учитывая, что нам потом всё равно понадобится искать и glibc).
Зачем вообще dlopen() внутри glibc?Это по своему интересный вопрос. Короткий ответ: детали реализации.
Дело в name service switch (NSS) — одной из частей glibc, обеспечивающей трансляцию разнообразных имён: имён машин, протоколов, пользователей, почтовых серверов, и т. д. Именно она ответственна за такие функции как getaddrinfo() для получения IP-адресов по доменному имени и getpwuid() для получения информации о пользователе по его числовому идентификатору.
У NSS модульная архитектура и модули загружаются динамически. Собственно, для этого в glibc и потребовались механизмы для динамической загрузки библиотек. Именно поэтому, когда вы пытаетесь использовать getaddrinfo() в статически собранном приложении, линкер печатает «непонятное» предупреждение:
/tmp/build/socket.o: In function `Socket::bind': socket.o:(.text+0x374): warning: Using 'getaddrinfo' in statically linked applications requires at runtime the shared libraries from glibc version used for linking
Что касается потоков, то поток — это обычно не только стек и исполняемый код, а ещё и глобальные данные, хранимые в thread-local storage (TLS). Корректная инициализация нового потока требует координированной работы ядра ОС, загрузчика бинарного кода и рантайма языка программирования. Поэтому простого вызова clone() достаточно для создания потока, способного записать в файл «Hello world!», но это может не сработать для более сложного кода, которому нужен доступ к TLS и прочим интересным штукам, скрытым от взора прикладного программиста.
Ещё один момент, связанный с многопоточностью — это однопоточные процессы. Что будет, если мы создадим новый поток в процессе, который не задумывался как многопоточный? Правильно, неопределённое поведение. Ведь в процессе отсутствует какая-либо синхронизация работы между потоками, что рано или поздно приведёт к порче данных. Если же мы потребуем, чтобы приложение использовало libpthread, то мы можем быть уверены в том, что оно готово к работе в многопоточном окружении (по крайней мере, должно быть готово).
Шаг 1. Подключение к процессу
Для начала нам потребуется подключиться к целевому процессу для отладки, а позже — отключиться от него обратно. Здесь в дело вступает системный вызов ptrace().
Первый контакт с ptrace()
В документации на ptrace() можно найти почти всю необходимую информацию:
Attaching and detaching
A thread can be attached to the tracer using the call
ptrace(PTRACE_ATTACH, pid, 0, 0);
or
ptrace(PTRACE_SEIZE, pid, 0, PTRACE_O_flags);
PTRACE_ATTACH sends SIGSTOP to this thread. If the tracer wants this
SIGSTOP to have no effect, it needs to suppress it. Note that if
other signals are concurrently sent to this thread during attach, the
tracer may see the tracee enter signal-delivery-stop with other sig‐
nal(s) first! The usual practice is to reinject these signals until
SIGSTOP is seen, then suppress SIGSTOP injection. The design bug
here is that a ptrace attach and a concurrently delivered SIGSTOP may
race and the concurrent SIGSTOP may be lost.
Так что первый шаг — это использовать PTRACE_ATTACH:
int ptrace_attach(pid_t pid)
{
/* Подключаемся к целевому процессу */
if (ptrace(PTRACE_ATTACH, pid, 0, 0) < 0)
return -1;
/* Дожидаемся его остановки */
if (wait_for_process_stop(pid, SIGSTOP) < 0)
return -1;
return 0;
}После ptrace() целевой процесс ещё не совсем готов к отладке. Мы подключились к нему, но для интерактивного исследования состояния процесса он должен быть остановлен. ptrace() отправляет процессу сигнал SIGSTOP, но нам ещё нужно дождаться собственно остановки процесса.
Для ожидания следует использовать системный вызов waitpid(). При этом стоит отметить несколько интересных граничных случаев. Во-первых, процесс может попросту завершиться или умереть, так и не получив SIGSTOP. В этом случае мы ничего не можем поделать. Во-вторых, процессу может быть ранее отправлен какой-нибудь другой сигнал. В этом случае нам следует дать процессу его обработать (с помощью PTRACE_CONT), а самим — продолжить дальше ждать наш SIGSTOP:
static int wait_for_process_stop(pid_t pid, int expected_signal)
{
for (;;) {
int status = 0;
/* Ждём, пока с процессом что-то произойдёт */
if (waitpid(pid, &status, 0) < 0)
return -1;
/* Если процесс умер или завершился — ну ок */
if (WIFSIGNALED(status) || WIFEXITED(status))
return -1;
/* Если процесс остановлен, то надо проверить причину */
if (WIFSTOPPED(status)) {
/*
* Макрос WSTOPSIG() напрямую использовать нельзя,
* так как ptrace() возвращает дополнительную
* информацию в старших байтах статуса.
*/
int stop_signal = status >> 8;
/* Если это наш сигнал, то мы приехали */
if (stop_signal == expected_signal)
break;
/* Иначе продолжаем исполнение процесса и ждём дальше */
if (ptrace(PTRACE_CONT, pid, 0, stop_signal) < 0)
return -1;
continue;
}
/* Всё остальное — непонятные ошибки */
return -1;
}
return 0;
}Отключение от процесса
Прекратить отлаживать процесс значительно проще: достаточно использовать PTRACE_DETACH:
int ptrace_detach(pid_t pid)
{
if (ptrace(PTRACE_DETACH, pid, 0, 0) < 0)
return -1;
return 0;
}Строго говоря, явное отключение отладчика необходимо не всегда. Когда процесс отладчика завершается, он автоматически отключается от всех отлаживаемых процессов, а сами процессы возобновляют работу, если они были остановлены ptrace(). Однако, если отлаживаемый процесс был явно остановлен отладчиком с помощью сигнала SIGSTOP без использования ptrace(), то он не проснётся без соответствующего сигнала SIGCONT или PTRACE_DETACH. Поэтому лучше всё же отключаться от процессов культурно.
Настройка ptrace_scope
Отладчик обладает полным контролем над отлаживаемым процессом. Если бы кто попало мог отлаживать что попало, то какое бы раздолье было для вредоносного кода! Очевидно, что интерактивная отладка — это достаточно специфичная деятельность, обычно необходимая только разработчикам. При нормальной эксплуатации системы чаще всего надобности в отладке процессов нет.
Из этих соображений, ради безопасности в системах обычно по умолчанию отключается возможность отлаживать какие попало процессы. За это отвечает модуль безопасности Yama, управляемый через файл /proc/sys/kernel/yama/ptrace_scope. Он предоставляет четыре модели поведения:
- 0 — пользователь может отлаживать любые процессы, которые он запустил
- 1 — режим по умолчанию, можно отлаживать только процессы, запущенные отладчиком
- 2 — только администратор системы с правами root может отлаживать процессы
- 3 — отладка запрещена вообще всем, режим не отключается до перезагрузки системы
Очевидно, для наших целей потребуется иметь возможность отлаживать процессы, запущенные до нашего отладчика, так что для экспериментов вам потребуется или переключить систему в режим разработки, записав 0 в специальный файл ptrace_scope (что требует прав администратора):
$ sudo sh -c 'echo 0 > /proc/sys/kernel/yama/ptrace_scope'или же запускать отладчик от имени администратора:
$ sudo ./inject-thread ...Результаты первого шага
В итоге, на первом шаге мы в состоянии подключиться к целевому процессу как отладчик и позже отключиться от него.
Целевой процесс будет остановлен и мы сможем убедиться, что операционная система действительно видит нас как отладчик:
$ sudo ./inject-thread --target $(pgrep docker)
$ cat /proc/$(pgrep docker)/status | head
Name: docker
State: t (tracing stop) <--- внимание на статус
Tgid: 31330
Ngid: 0
Pid: 31330
PPid: 1
TracerPid: 2789 <--- PID процесса отладчика
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 64
$ ps a | grep [2]789
2789 pts/5 S+ 0:00 ./inject-thread --target 31330Шаг 2. Поиск библиотек в памяти
Следующий шаг более простой: надо найти в памяти целевого процесса библиотеки с нужными нам функциями. Но памяти-то много, откуда начинать искать и что именно?
Файл /proc/$pid/maps
В этом нам поможет специальный файл, через который ядро рассказывает о том, что и где у процесса в памяти расположено. Как известно, в директории /proc для каждого процесса есть поддиректория. А в ней есть файл, описывающий карту памяти процесса:
$ cat /proc/self/maps 00400000-0040c000 r-xp 00000000 fe:01 1044592 /bin/cat 0060b000-0060c000 r--p 0000b000 fe:01 1044592 /bin/cat 0060c000-0060d000 rw-p 0000c000 fe:01 1044592 /bin/cat 013d5000-013f6000 rw-p 00000000 00:00 0 [heap] 7f9920bd1000-7f9920d72000 r-xp 00000000 fe:01 920019 /lib/x86_64-linux-gnu/libc-2.19.so 7f9920d72000-7f9920f72000 ---p 001a1000 fe:01 920019 /lib/x86_64-linux-gnu/libc-2.19.so 7f9920f72000-7f9920f76000 r--p 001a1000 fe:01 920019 /lib/x86_64-linux-gnu/libc-2.19.so 7f9920f76000-7f9920f78000 rw-p 001a5000 fe:01 920019 /lib/x86_64-linux-gnu/libc-2.19.so 7fc3f8381000-7fc3f8385000 rw-p 00000000 00:00 0 7fc3f8385000-7fc3f83a6000 r-xp 00000000 fe:01 920012 /lib/x86_64-linux-gnu/ld-2.19.so 7fc3f83ec000-7fc3f840e000 rw-p 00000000 00:00 0 7fc3f840e000-7fc3f8597000 r--p 00000000 fe:01 657286 /usr/lib/locale/locale-archive 7fc3f8597000-7fc3f859a000 rw-p 00000000 00:00 0 7fc3f85a3000-7fc3f85a5000 rw-p 00000000 00:00 0 7fc3f85a5000-7fc3f85a6000 r--p 00020000 fe:01 920012 /lib/x86_64-linux-gnu/ld-2.19.so 7fc3f85a6000-7fc3f85a7000 rw-p 00021000 fe:01 920012 /lib/x86_64-linux-gnu/ld-2.19.so 7fc3f85a7000-7fc3f85a8000 rw-p 00000000 00:00 0 7ffdb6f0e000-7ffdb6f2f000 rw-p 00000000 00:00 0 [stack] 7ffdb6f7f000-7ffdb6f81000 r-xp 00000000 00:00 0 [vdso] 7ffdb6f81000-7ffdb6f83000 r--p 00000000 00:00 0 [vvar] ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
Содержимое этого файла генерируется ядром операционной системы на лету из внутренних структур, описывающих регионы памяти интересующего нас процесса, и содержит следующую информацию:
- диапазон адресов, выделенный региону
- права доступа на регион
r/-: чтениеw/-: записьx/-: исполнениеp/s: разделение памяти с другими процессами
- смещение в файле (если есть)
- код устройства, где расположен отображаемый файл
- номер inode отображаемого файла (если есть)
- путь к отображаемому файлу (если есть)
Некоторые регионы памяти отображаются на файлы: когда процесс читает такую память, то он на самом деле считывает данные из соответствующих файлов по определённому смещению. Если в регион можно писать, то изменения в памяти могут быть либо видимы только самому процессу (механизм copy-on-write, режим p — private), так и синхронизироваться с диском (режим s — shared).
Другие регионы являются анонимными — эта память не соответствует никакому файлу. Операционная система просто выдаёт процессу кусочек физической памяти, которым он пользуется. Такие регионы используются, например, для «обычной» памяти процесса: стека и кучи. Анонимные регионы могут быть как личными для процесса, так и разделяться между несколькими процессами (механизм shared memory).
Кроме того, в памяти есть несколько специальных регионов, отмеченные псевдоименами [vdso] и [vsyscall]. Они используются для оптимизации некоторых системных вызовов.
Нас интересуют регионы, куда отображается содержимое файлов с библиотеками. Если мы прочитаем карту памяти и отфильтруем в ней записи по имени отображаемого файла, то мы найдём все адреса, занимаемые нужными нам библиотеками. Формат карты памяти специально сделан удобным для программной обработки и элементарно разбирается с помощью функций семейства scanf():
static bool read_proc_line(const char *line, const char *library,
struct memory_region *region)
{
unsigned long vaddr_low = 0;
unsigned long vaddr_high = 0;
char read = 0;
char write = 0;
char execute = 0;
int path_offset = 0;
/* Разбираем одну строку /proc/$pid/maps */
sscanf(line, "%lx-%lx %c%c%c%*c %*lx %*x:%*x %*d %n",
&vaddr_low, &vaddr_high, &read, &write, &execute,
&path_offset);
/* Проверяем, совпадает ли имя файла с искомым */
if (!strstr(line + path_offset, library))
return false;
/* Запоминаем нужную нам информацию о диапазоне адресов и правах доступа */
if (region) {
region->vaddr_low = vaddr_low;
region->vaddr_high = vaddr_high;
region->readable = (read == 'r');
region->writeable = (write == 'w');
region->executable = (execute == 'x');
region->content = NULL;
}
return true;
}Тайна третьей планеты
Если обратить внимание на диапазоны памяти, используемые libc-2.19.so, то можно заметить странную вещь:
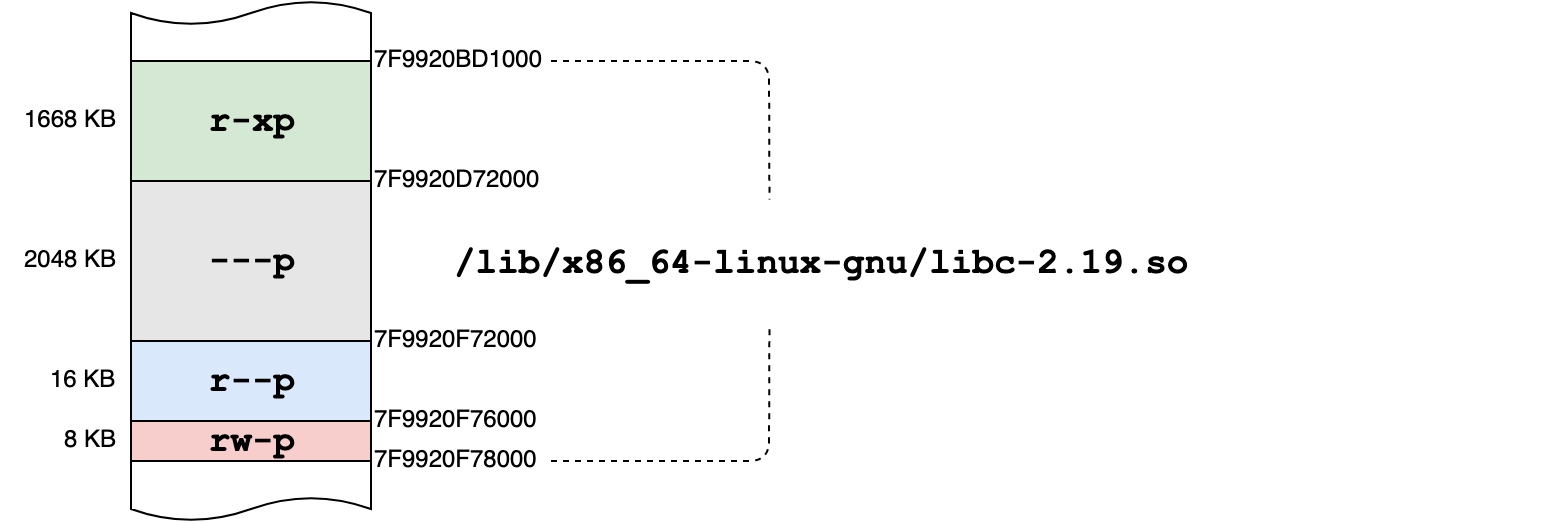
Что вот это за пустой регион на 2 мегабайта без каких-либо прав доступа к нему? Зона 51? Призрак Денниса Ричи? Сокровища нибелунгов?
Оказывается, это особенность реализации компилятора, который таким образом старается оптимизировать использование физической памяти в системе.
Как известно, одним из главных преимуществ разделяемых библиотек является то, что их можно загружать в память в единственном экземпляре. Механизм виртуальной памяти позволяет загрузить библиотеку в физическую память лишь один раз, после чего все приложения, которым нужна библиотека, будут совместно использовать одни и те же регионы физической памяти (но, возможно, под разными виртуальными адресами в своих адресных пространствах).
Операционная система управляет памятью не побайтово, а страницами (обычно по 4 КБ каждая). Память выдаётся процессам страницами, права доступа устанавливаются постранично и только целые страницы можно разделять между процессами.
Компилятор хочет, чтобы исполняемый код и данные библиотеки находились на отдельных страницах памяти. В этом случае неизменяемый код библиотеки — её наибольшую часть — можно будет разделять между всеми процессами. Именно для этого компилятор и вставляет между кодом и данными 2 мегабайта пустого места — максимальный размер страницы, с которыми скорее всего придётся иметь дело (архитектура x86_64 поддерживает страницы размером 4 КБ, 2 МБ, 1 ГБ). Тогда при загрузке библиотеки код и данные никогда не будут находиться на одной и той же странице памяти.
Результаты второго шага
Проанализировав карту памяти целевого процесса, мы получаем адреса загрузки библиотек с необходимыми для нас функциями:
- библиотека libdl: dlopen() и dlsym()
- библиотека libpthread: pthread_create() и pthread_detach()
Это достаточно важная информация, так как она необходима для использования функций, содержащихся в библиотеках. Чтобы усложнить жизнь вредоносному коду Linux обычно загружает библиотеки по случайным адресам (address space layout randomization, ASLR). Случайный адрес загрузки не мешает самим программам (загрузчик-то знает, куда и что он загружал), но сторонние процессы вынуждены будут самостоятельно искать базовый адрес во время исполнения — вместо простого использования какой-нибудь константы.
Если нам и другим отладчикам это позволительно, то у внедряемого вредоносного кода обычно очень жёсткие ограничения на размер, которые не позволяют втиснуть туда открытие, чтение и разбор файла /proc/$pid/maps. Не говоря уже о том, что факт чтения этого файла позволяет тривиально обнаруживать подозрительную активность.
Шаг 3. Разбор ELF-образов библиотек
Теперь, когда мы знаем адреса загрузки библиотек, в этих библиотеках хорошо бы найти сами функции, которые нам нужны.
Можно поступить прагматично:
$ nm -D /lib/x86_64-linux-gnu/libdl-2.19.so | grep dlopen
0000000000001090 T dlopenУтилита nm разбирает таблицу символов из файла с библиотекой и выдаёт смещения интересующих нас функций. Прибавляя смещение к базовому адресу исполняемого региона библиотеки мы получаем собственно адрес функции в конкретном процессе.
Но это как-то недостаточно интересно, поэтому мы будем сами себе nm и выполним то же самое, но основываясь исключительно на загруженной в память информации. Примерно так, как это делает сама функция dlsym().
Чтение памяти целевого процесса
Первый шаг — это собственно прочитать ELF-образ, загруженный в целевой процесс. С этим нам опять поможет файловая система procfs. В лучших традициях UNIX way, память отлаживаемого процесса можно прочитать из специального файла /proc/$pid/mem, смещение в котором — это виртуальный адрес в процессе (который мы знаем из файла /proc/$pid/maps).
Давным давно Linux позволял отобразить этот файл в память с помощью системного вызова mmap(), но это приводило к проблемам с правами доступа (отображающий процесс мог читать память, недоступную её хозяину). Поэтому придется копировать все нужные регионы памяти целевого процесса в свою память:
static int map_region(pid_t pid, struct memory_region *region)
{
size_t length = region->vaddr_high - region->vaddr_low;
off_t offset = region->vaddr_low;
char path[32] = {0};
snprintf(path, sizeof(path), "/proc/%d/mem", pid);
/* Открываем память целевого процесса */
int fd = open(path, O_RDONLY);
if (fd < 0)
goto error;
/* Выделяем буфер под свою копию */
void *buffer = malloc(length);
if (!buffer)
goto error_close_file;
/* Читаем память */
if (read_region(fd, offset, buffer, length) < 0)
goto error_free_buffer;
region->content = buffer;
close(fd);
return 0;
error_free_buffer:
free(buffer);
error_close_file:
close(fd);
error:
return -1;
}
static int read_region(int fd, off_t offset, void *buffer, size_t length)
{
/* Смещаемся до нужного виртуального адреса */
if (lseek(fd, offset, SEEK_SET) < 0)
return -1;
size_t remaining = length;
char *ptr = buffer;
/*
* Читаем всю интересующую нас память. Обязательно в цикле,
* потому что ядро может отдавать столько, сколько хочет.
*/
while (remaining > 0) {
ssize_t count = read(fd, ptr, remaining);
if (count < 0)
return -1;
remaining -= count;
ptr += count;
}
return 0;
}После этого мы можем исследовать ELF-образ библиотеки. Наша копия останется верной, во-первых, потому что она неизменяема в целевом процессе, а во-вторых, потому что целевой процесс остановлен для отладки.
Двуликий ELF
Вот сейчас наконец нам потребуется открыть спецификацию на формат ELF — наиболее популярный формат исполнимых файлов и библиотек в Linux. Она поможет нам разобраться с тем, что искать в образе, который был получен на предыдущем этапе.
Одним из главных понятий в ELF является двойственность представления. Во время компиляции ELF представляется как набор секций с кодом или данными. Во время загрузки — как набор сегментов, которые надо загрузить в память перед работой программы. Секции описывают регионы файла на диске, сегменты — регионы образа в памяти. В начале файла или образа всегда располагается ELF-заголовок.
Например, моя библиотека libdl-2.19.so выглядит так:
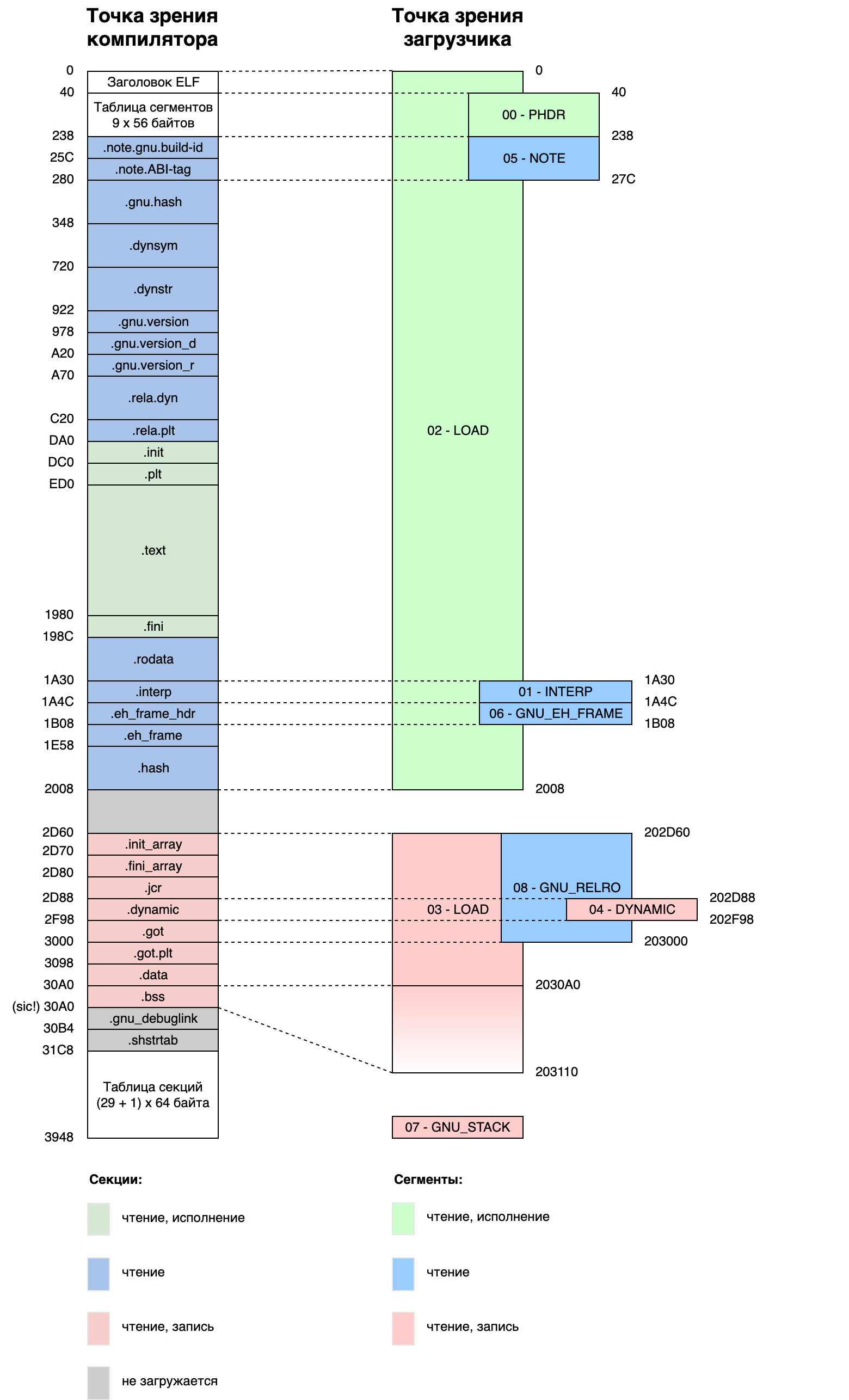
(Эту информацию можно получить в текстовом виде с помощью команды readelf --headers.)
Как можно заметить, секций в библиотеке больше, чем сегментов (29 против 9). Компиляция и сборка — это достаточно сложный процесс, так что компилятор в файле для себя всё раскладывает по полочкам, отсюда и большое количество секций. Загрузка ELF — это сравнительно простая работа, большую часть которой загрузчик выполняет самостоятельно. Ядру Linux, например, важны только сегменты LOAD, а остальными пользуется уже загрузчик (отрабатывающий в самом начале исполнения программы).
Некоторые части ELF-файла в память вообще не загружаются, так как они не нужны во время работы программы. Например, это таблица секций и разнообразная отладочная информация.
Некоторые сегменты занимают в памяти больше меньше места, чем на диске. «Лишнее» место загрузчик заполняет нулями. Именно так реализуется секция .bss, хранящая глобальные переменные, которые в программе инициализированы нулями (значение по умолчанию в Си).
В общем, устройство формата ELF и работа с ним — это отдельная, очень весёлая и интересная тема. Но нас сейчас интересует лишь один вопрос...
Где лежит таблица символов?
В каждой библиотеке хранится таблица соответствия между именами объектов (символами) и их адресами. Этой таблицей пользуется загрузчик во время загрузки программы, а также функции вроде dlsym(), чтобы искать в библиотеке функции по именам. Вот она-то нам и нужна.
Механизм загрузки программ описывается во второй части спецификации ELF (стр. 2-10). Оттуда можно узнать, что информация для загрузчика хранится в секции .dynamic, которой соответствует загружаемый сегмент DYNAMIC. В секции .dynamic хранятся ссылки на другие секции, необходимые загрузчику:
- .dynsym — собственно таблица символов с адресами;
- .dynstr — массив строк с именами символов;
- .hash — хеш-таблица, ускоряющая поиск символов.
Сегменты описываются таблицей сегментов, обычно расположенной в начале образа, а расположение таблицы сегментов определяется заголовком ELF:
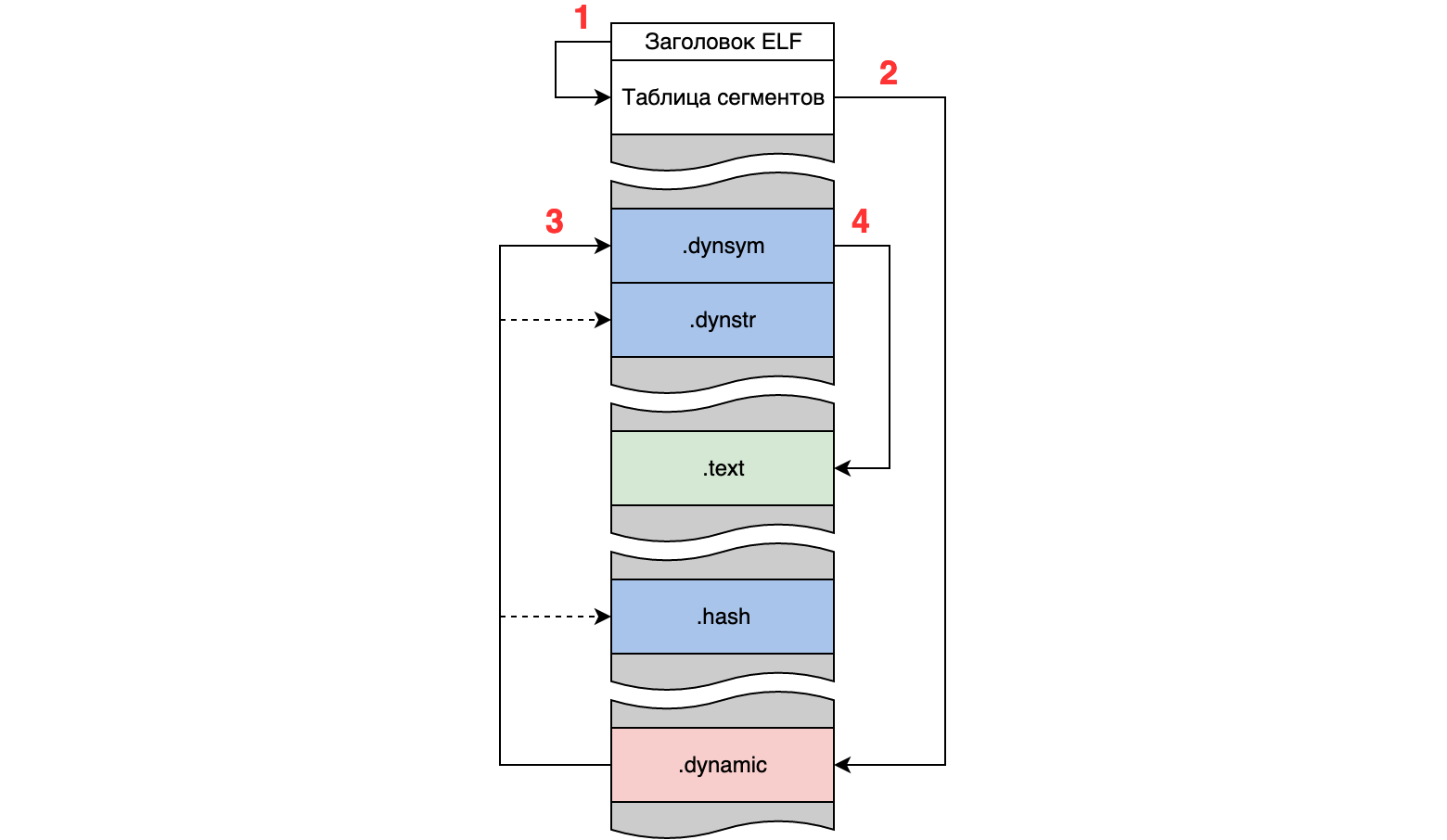
Начинаем мы с заголовка ELF, в котором находим таблицу сегментов (1), в которой находим нужный сегмент (2), в котором находим нужные секции (3), в которых находим нужные функции (4) в доме, который построил Джек.
Заголовок ELF → таблица сегментов
(Почти) все структуры ELF заботливо описаны в заголовочном файле <elf.h>, который, в свою очередь, хорошо описан в документации. Сразу стоит отметить, что ELF — это очень гибкий и расширяемый формат. Он может поддерживать 32-битные и 64-битные файлы, с прямым и обратным порядком байтов, с бинарным кодом для любой архитектуры, и много другое. Если мы ограничимся только родными бинарными файлами для архитектуры x86_64, то задача разбора ELF существенно упрощается.
Любой ELF-файл начинается с заголовка (структура Elf64_Ehdr). В нём нас интересуют координаты и размеры таблицы сегментов (program headers), хранимые в полях e_phoff и e_phnum:

Остальные поля — магическое число в начале, целевую архитектуру процессора, тип ELF-файла и прочие — есть смысл проверить на согласованность, чтобы убедиться в том, что мы действительно попали туда, куда надо, и наши предположения оправдываются.
В итоге мы получаем смещение таблицы сегментов e_phoff, по которому легко вычислить её виртуальный адрес, прибавив к смещению адрес загрузки библиотеки. Таблица сегментов содержит e_phnum записей размером e_phentsize байтов каждая.
В нашем случае (как обычно и бывает), таблица сегментов расположена сразу же после заголовка ELF — по смещению в 64 байта.
Таблица сегментов → сегмент DYNAMIC
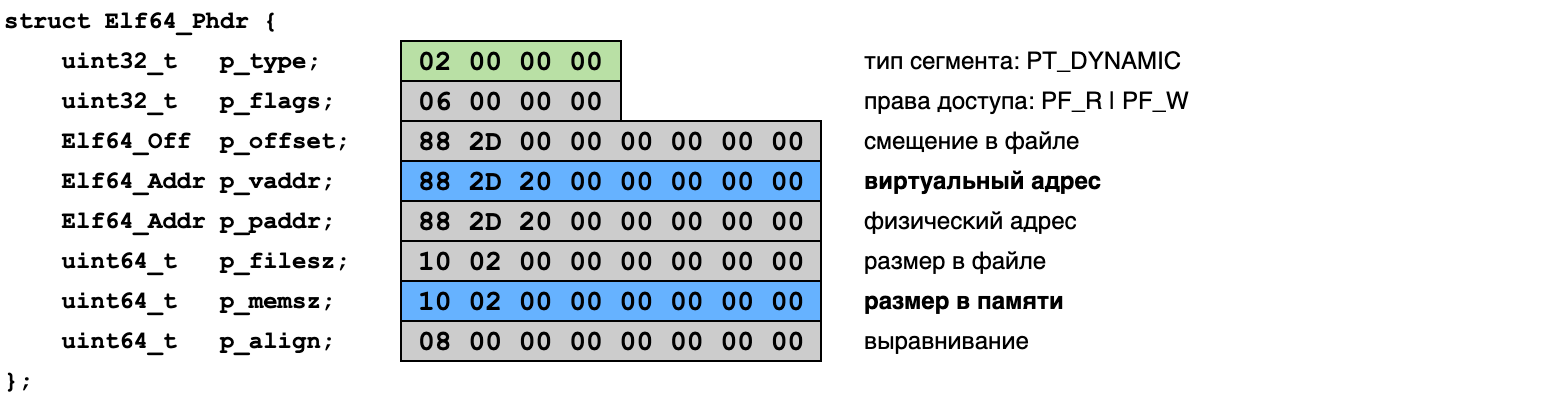
Теперь надо найти нужный нам сегмент. Таблица сегментов — это просто массив структур типа Elf64_Phdr (для 64-битных ELF-файлов), описывающих заголовки сегментов. Нужный нам заголовок содержит значение PT_DYNAMIC в поле p_type:
Другие поля заголовка содержат информацию о размере и расположении сегмента:
- p_vaddr — смещение виртуального адреса, куда сегмент будет загружен;
- p_memsz — размер сегмента в памяти в байтах.
В нашем случае секция .dynamic располагается в файле по смещению 0x2D88 (можете сравнить с картой файла выше). В память же она загружается как сегмент DYNAMIC на два мегабайта дальше — по смещению 0x202D88. Секция имеет длину 0x210 (8448) байтов. Прибавив смещение к базовому адресу загрузки библиотеки мы получим виртуальный адрес сегмента в памяти целевого процесса.
Сегмент DYNAMIC → секции .dynsym, .dynstr, .hash
Секция .dynamic, загружаемая в сегмент DYNAMIC, содержит информацию для динамического загрузчика библиотек. Она хранится в виде массива структур Elf64_Dyn, описывающих разнообразные вещи:

Каждая структура несёт 8 байтов информации в поле d_val или d_ptr, а также 8-байтовую метку d_tag, которая определяет, как эту информацию интерпретировать. Для нас будут интересны следующие метки:
- DT_HASH (4) — виртуальный адрес секции .hash (в d_ptr)
- DT_STRTAB (5) — виртуальный адрес секции .dynstr (в d_ptr)
- DT_SYMTAB (6) — виртуальный адрес секции .dynsym (в d_ptr)
- DT_STRSZ (10) — размер в байтах секции .dynstr (в d_val)
- DT_NULL (0) — последняя структура в списке
Все эти записи обязательны для разделяемых библиотек. Кроме этих записей секция .dynamic содержит и другие интересные вещи: имя библиотеки, имена её зависимостей, информацию для выполнения релокаций, адреса конструкторов и деструкторов.
Обратите внимание на то, что сегмент DYNAMIC располагается в изменяемом регионе памяти и соответствующие записи в нём содержат не смещения, а абсолютные виртуальные адреса. В файле хранятся как раз смещения, но загрузчик во время загрузки вписывает в память уже готовые виртуальные адреса, ведь он-то знает, куда загрузил библиотеку.
После разбора секции .dynamic у нас на руках будут адреса всех других секций, которые необходимы для поиска адресов интересующих нас функций в библиотеке. Постойте-ка, вот длина .dynstr у нас есть, а что с длинами остальных секциями? Тут история становится более интересной.
Поиск функций в библиотеке
Таблица символов хранит соответствие между именами объектов и их адресами в программе. Нас интересует динамическая таблица символов, расположенная в секции .dynsym и описывающая объекты, импортируемые и экспортируемые из библиотеки при динамической загрузке. (Есть ещё «просто» таблица символов .symtab, которая хранит все символы и используется, например, для отладки. Она нам не нужна.)
Таблица символов
Таблица символов представляется массивом структур Elf64_Sym, содержащих описания объектов программы с точки зрения ELF — переменных, функций, секций, файлов. Вот так выглядит запись для символа dlopen:
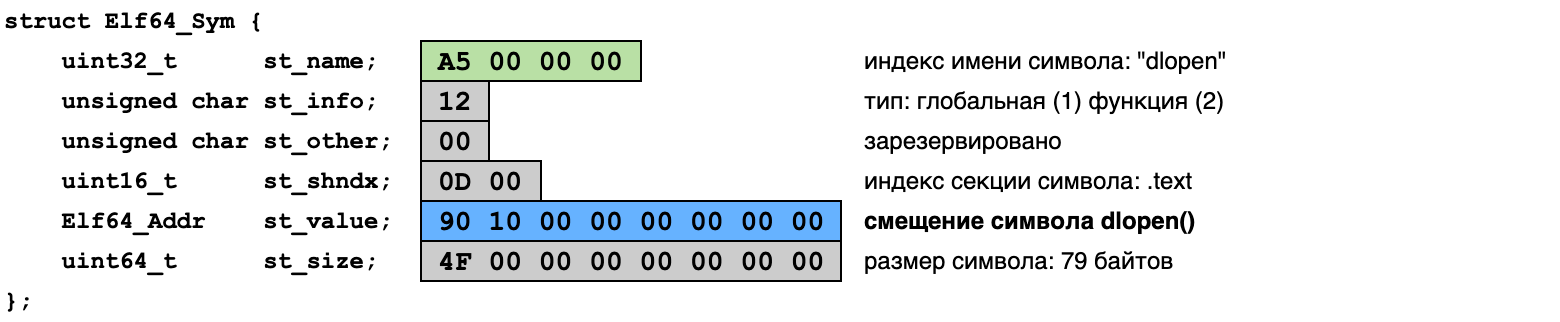
Нас здесь будут интересовать следующие поля:
- st_name — имя символа, в виде индекса в таблице строк
- st_info — тип и видимость символа (младший и старший полубайты)
- st_value — смещение символа в памяти
(Как можно убедиться, сравнив значения с выводом nm и картой секций, функция dlopen() действительно расположена в секции .text, по смещению 0x1090 от начала файла.)
Чтобы найти символ по имени, необходимо знать соответствующий индекс в таблице строк.
Таблица строк
Таблица строк — это просто огромный массив нуль-терминированных строк, склеенных и расположенных подряд. Все строки в программе хранятся в единственном экземпляре в таких таблицах (их может быть несколько). Строки для динамического загрузчика хранятся в секции .dynstr, начало которой в моей библиотеке libdl-2.19.so выглядит так:
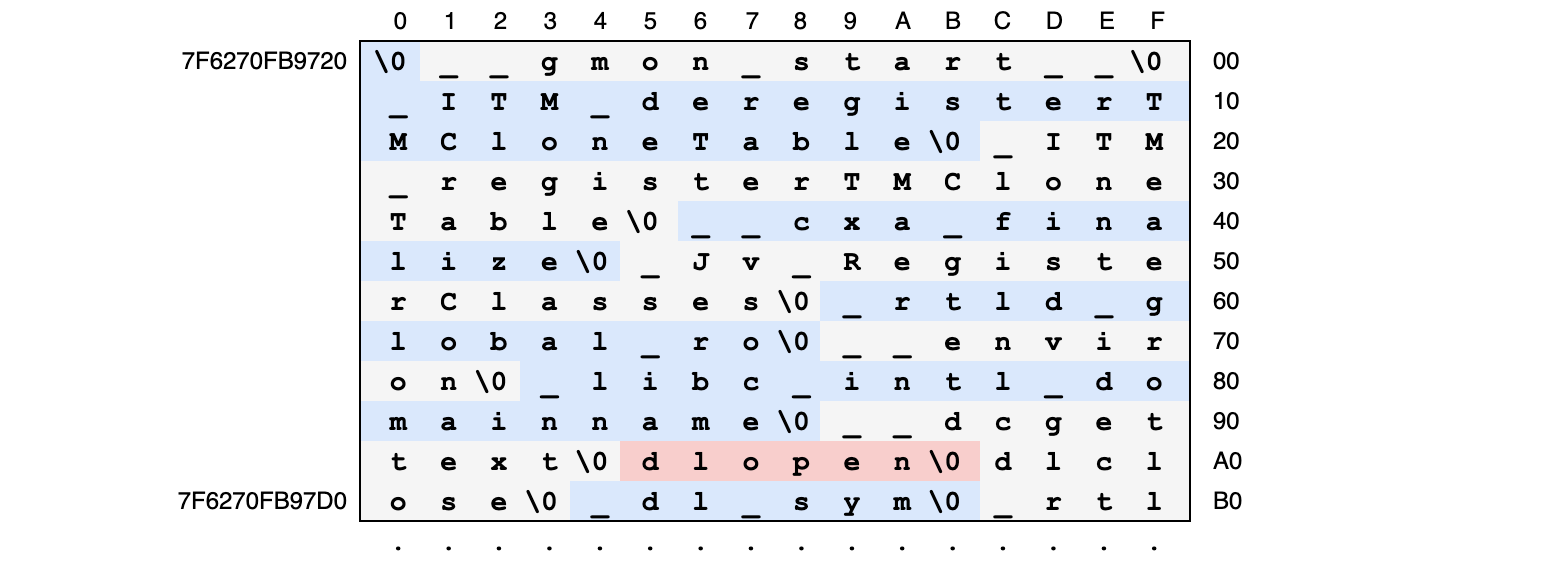
Конечно, мы можем просканировать всю таблицу строк в поисках нужных нам (вроде «dlopen», расположенной смещению 0xA5) и таким образом найти соответствующие индексы, но это жутко неэффективно. На самом деле загрузчик поступает чуть более умно.
Хеш-таблица
Секция .hash содержит хеш-таблицу, помогающую быстро находить символы по их именам. Эта же хеш-таблица — по истерическим причинам — является единственным загружаемым местом в ELF-файле, где упоминается количество символов в таблице символов. Вообще, количество символов можно косвенно получить из длины секции .dynsym, но длины секций хранятся в таблице секций, которая обычно не загружается в память. Поэтому мы (и загрузчик) вынуждены всегда смотреть в хеш-таблицу символов.
Структура хеш-таблицы не описана в заголовочном файле <elf.h>, она есть только в спецификации (стр. 2-19). Это классическая хеш-таблица с открытой адресацией, устроенная следующим образом:
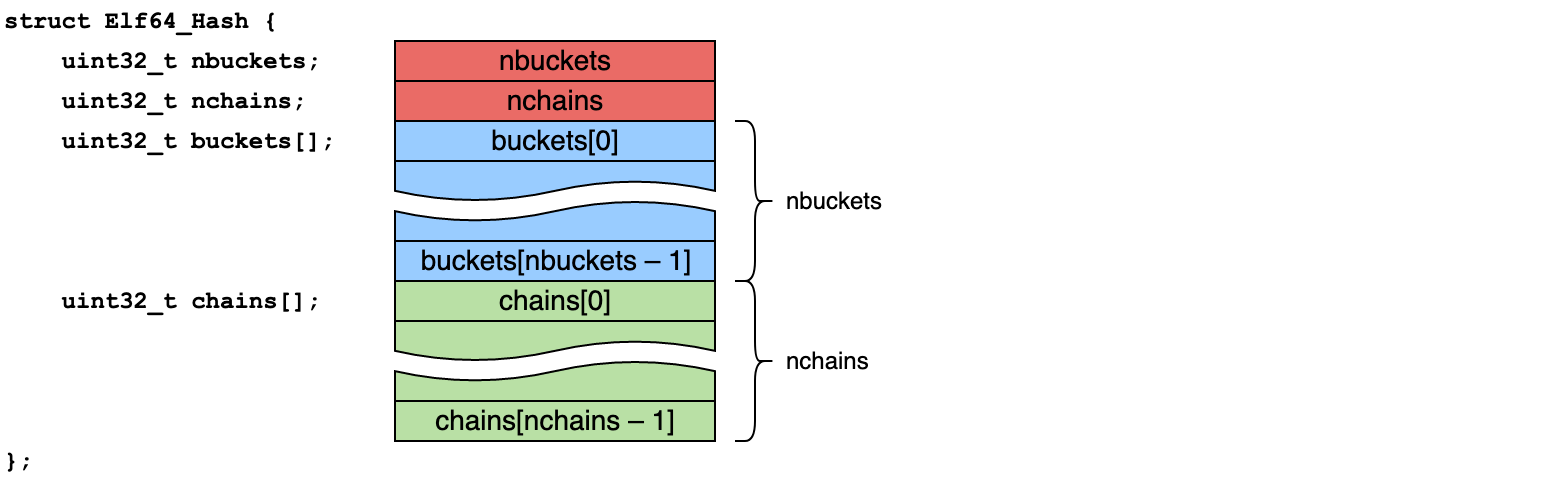
где
- nbuckets — количество ячеек массива buckets
- nchains — количество ячеек массива chains (и количество символов)
- buckets — индексы символов в таблице символов
- chains — индексы следующих символов при коллизиях
Пользоваться хеш-таблицей следует так:
- Вычисляем хеш h от имени искомого символа.
- Получаем индекс i как
buckets[h % nbuckets], это индекс в таблице символов. - Если имя в таблице символов (получаемое по индексу из таблицы строк) соответствует нужному, то мы приехали.
- Иначе следующий индекс — это
chains[i % nchains]. - Повторяем шаги 3—4 до нахождения нужного символа или пока индекс не станет равным нулю, что означает отсутствие соответствующего символа в таблице.
Волшебная хеш-функция, используемая ELF:
static uint32_t elf_hash(const char *name)
{
uint32_t h = 0;
uint32_t g;
while (*name) {
h = (h << 4) + *name++;
g = h & 0xF0000000;
if (g)
h ^= g >> 24;
h &= ~g;
}
return h;
}Например, для строки "dlopen" хеш-функция даёт значение 112420542 и поиск происходит следующим образом:
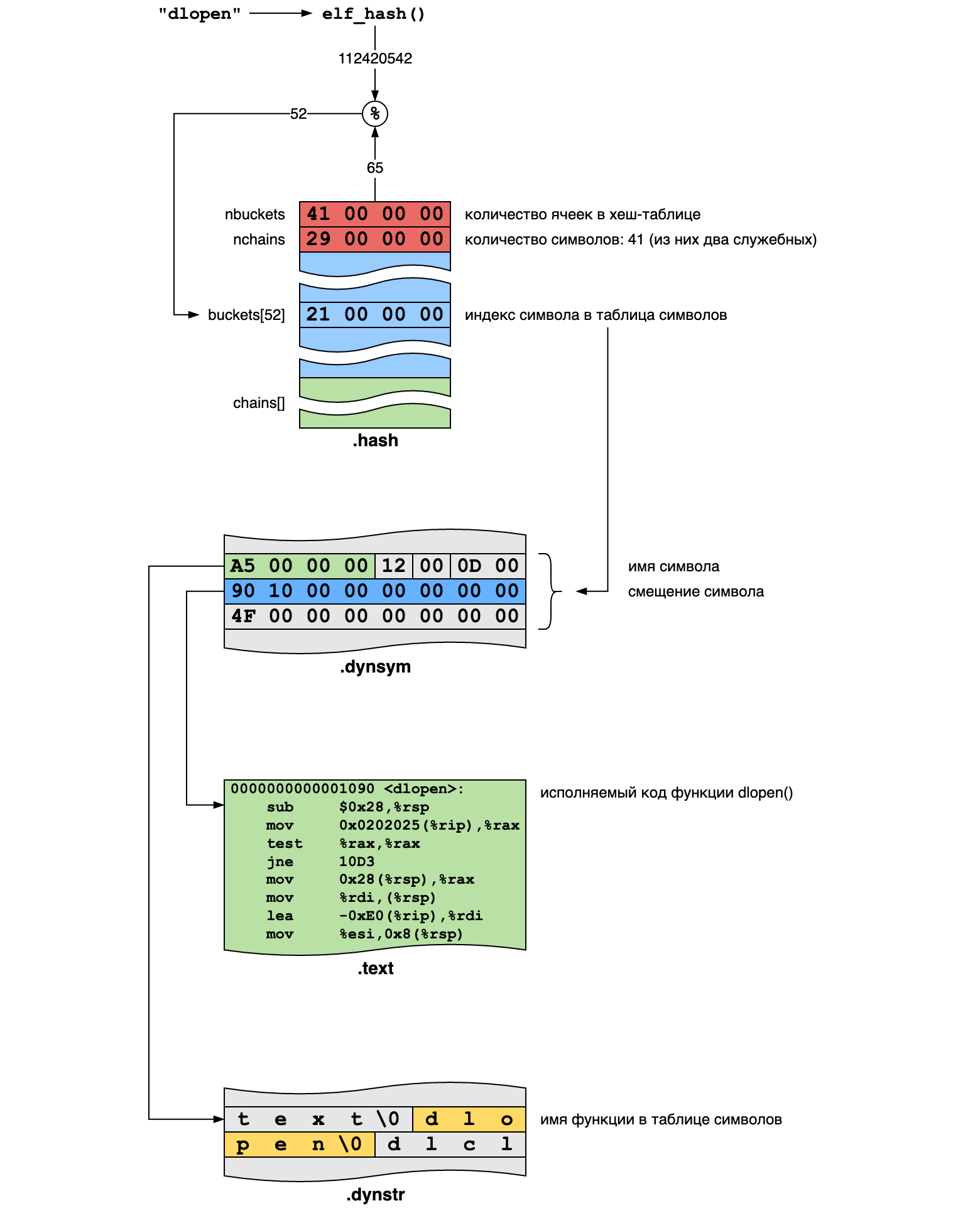
libdl — это достаточно небольшая библиотека, у неё всего 39 символов в таблице, так что вероятность коллизий здесь небольшая. Используя хеш-таблицы мы можем быстро отыскать в библиотеках все нужные нам четыре функции.
Результаты третьего шага
Под конец этого довольно объёмного раздела мы получили абсолютные виртуальные адреса всех библиотечных функций, которые понадобятся для загрузки и исполнения кода в целевом процессе:
- dlopen() и dlsym() из библиотеки libdl
- pthread_create() и pthread_detach() из библиотеки libpthread
Зная адрес функции, мы можем её вызывать.
В норме за адреса импортируемых библиотечных функций отвечает загрузчик. Он их находит в загружаемых библиотеках и записывает в таблицу компоновки функций. Мы не можем полагаться на загрузчик, поэтому вынуждены находить и заполнять адреса самостоятельно.
Честный подход с разбором ELF-образа на лету довольно громоздкий. В нашем случае он дополнительно усложнён тем, что производится в другом процессе (а не целевом). Подобный подход будет сложно применить во вредоносном коде, который вынужден быть компактным. Однако, это вполне возможно осуществить, зная базовый адрес загрузки библиотеки. Но обычно в таком случае смещения нужных функций рассчитываются заранее под известные версии известных библиотек.
Шаг 4. Внедрение шелл-кода
Зная адреса функций, которые мы хотим использовать, можно приняться за шелл-код, который будет выполнять следующий этап: загружать библиотеку с полезной нагрузкой и запускать новый поток, выполняющий внедрённый код. Для начала шелл-код следует написать.
Содержимое шелл-кода
Хорошо, вот наш шелл-код:
void shellcode(void)
{
void *payload = dlopen("/path/to/payload.so", RTLD_LAZY);
void (*entry)(void) = dlsym(payload, "entry_point");
pthread_t thread;
pthread_create(&thread, NULL, entry, NULL);
pthread_detach(thread);
}Как нам его загрузить в целевой процесс?
Очевидно, что скопировать и вставить его как текст — это не вариант. Если этот код скомпилировать, то мы получим объектный файл, но от него будет мало толку, потому что этот код надо будет как-то загрузить — что мы-то как раз и пытаемся сделать! Нам нужен вариант попроще.
Наиболее удобный способ — это написать шелл-код на ассемблере. В этом случае мы обладаем полным контролем над тем, что будет выполнять процессор, а также сможем тривиально загрузить итоговый машинный код в целевой процесс: просто скопировать его из своего процесса в другой.
/*
* Разместить результат ассемблирования в секции .rodata: для неизменяемых
* данных. Мы не собираемся исполнять получившийся машинный код в загрузчике,
* нам надо только скопировать его в целевой процесс.
*/
.section .rodata
/*
* Объявления экспортируемых символов. Эти метки будут видны в других файлах.
* Они отмечают важные места в шелл-коде: его начало и конец, расположение
* ячеек памяти, куда надо будет вписать адреса внешних функций.
*/
.global shellcode_start
.global shellcode_address_dlopen
.global shellcode_address_dlsym
.global shellcode_address_pthread_create
.global shellcode_address_pthread_detach
.global shellcode_address_payload
.global shellcode_address_entry
.global shellcode_end
/*
* Константа для dlopen(). Мы не можем сделать #include <dlfcn.h>,
* так что вынуждены объявлять все константы самостоятельно.
*/
.set RTLD_LAZY, 1
.align 8
shellcode_start:
/*
* void *payload = dlopen(shellcode_address_payload, RTLD_LAZY);
*
* Здесь важно помнить соглашение о вызове функций x86_64:
*
* - аргументы передаются через регистры %rdi, %rsi, %rdx, %rcx
* - результат возвращается в регистре %rax
* - остальные моменты нам не важны
*
* Мы сами себе компилятор и вынуждены всё делать вручную.
*
* Адрес вызываемой функции мы помещаем в %rax, так как функции
* нам нужны лишь один раз.
*/
lea shellcode_address_payload(%rip),%rdi
mov $RTLD_LAZY,%rsi
mov shellcode_address_dlopen(%rip),%rax
callq *%rax
/*
* void (*entry)(void) = dlsym(payload, shellcode_address_entry);
*/
mov %rax,%rdi
lea shellcode_address_entry(%rip),%rsi
mov shellcode_address_dlsym(%rip),%rax
callq *%rax
/*
* pthread_t thread;
* pthread_create(&thread, NULL, entry, NULL);
*
* В этот раз нам нужно выделить место на стеке под локальную
* переменную, потому что этого требует pthread_create().
*/
sub $8,%rsp
mov %rsp,%rdi
xor %rsi,%rsi
mov %rax,%rdx
xor %rcx,%rcx
mov shellcode_address_pthread_create(%rip),%rax
callq *%rax
/*
* pthread_detach(thread);
*
* Не забываем освободить память, выделенную на стеке, когда
* она нам больше не нужна.
*/
mov (%rsp),%rdi
add $8,%rsp
mov shellcode_address_pthread_detach(%rip),%rax
callq *%rax
/*
* Так как шелл-код — это не совсем функция, то мы не можем
* просто вернуться из неё через ret. Для возврата управления
* отладчику обычно используются точки останова, которые
* реализуются с помощью специального отладочного прерывания.
*/
int $3
/*
* Зарезервируем немного места под адреса и данные, которые мы
* заполним правильными значениями, когда будем переносить шелл-
* код в память целевого процесса. Это наша “таблица смещений
* глобальных символов” (global offset table, GOT), а также
* сегмент данных под путь к библиотеке и имя функции в ней.
*/
.align 8
shellcode_address_dlopen:
.space 8
shellcode_address_dlsym:
.space 8
shellcode_address_pthread_create:
.space 8
shellcode_address_pthread_detach:
.space 8
shellcode_address_payload:
.space 256
shellcode_address_entry:
.space 256
/*
* Здесь шелл-код заканчивается.
*/
shellcode_end:
.endМногословно, но очень точно. Собирать этот код следует ассемблером напрямую:
$ as -o shellcode.o shellcode.SОбратите внимание, что все внешние функции вызываются косвенно, через указатели, хранимые в памяти. В настоящих программах все функции из динамически загружаемых библиотек вызываются похожим образом: через промежуточную таблицу компоновки функций (procedure linkage table, PLT), в которую загрузчик вписывает абсолютные адреса соответствующих функций.
Сам по себе наш шелл-код использует только относительную адресацию, так что его можно тривиально скопировать в любое (ну, почти) место в памяти и он будет работать. Это позиционно-независимый или перемещаемый код.
Размещение шелл-кода в памяти
Результат ассемблирования надо разместить где-то в памяти целевого процесса. Однако, скорее всего у процесса нет лишней памяти, которую он выделил, но сам не использует и не собирается использовать в будущем. Куда же нам пристроить наш код?
Требования к памяти под шелл-код
Один важный момент состоит в том, что нам подойдёт не всякий регион памяти. Так как мы собираемся записать исполняемый код, то соответствующий регион памяти должен разрешать исполнение. Если этого не сделать, то процессор бросится исключением и операционная система убьёт процесс. Это специальная защита от исполнения вредоносного или ошибочного кода, который оказался на стеке или в куче.
Если в сегменте данных мы бы ещё могли надеяться найти ненужный кусочек памяти (нам-то надо немного), то в сегменте кода лишнего места наверняка не будет: компилятор точно знает, сколько кода он сгененрировал, и подгоняет размер впритык. Есть, конечно, варианты с JIT-компиляторами и всем таким, но это не подходит в общем случае. Так что же делать?
Подходы к размещению в памяти
Обычно в таком случае поступают одним из двух способов:
- записывают шелл-код поверх существующего, потом возвращают как было
- выделяют под шелл-код новый, собственный регион памяти
Подход с перезаписью не такой простой, каким кажется. Во-первых, предыдущее содержимое надо где-то сохранить, чтобы его можно было вернуть. Во-вторых, сегмент с кодом обычно защищён от записи. В-третьих, такой подход несёт с собой риск, что какой-нибудь другой поток исполнит шелл-код, когда мы этого не хотим.
Тем не менее, настоящие отладчики часто пользуются этим подходом. Именно так реализуются точки останова. На x86_64 инструкция int $3 занимает ровно один байт — 0xCC — так что много памяти для резервной копии кода не надо. Механизм ptrace() позволяет обходить защиту от записи с помощью команды PTRACE_POKETEXT — правда, записывать при этом можно 8 байтов за раз, целиком. Наконец, отладчик может остановить все ненужные потоки или автоматически перезапускать те, где точка останова не интересна.
Мы, к сожалению, не настоящий отладчик, поэтому для простоты будем использовать второй подход: выделим лично для себя память с нужными атрибутами. Она будет подходить для шелл-кода и о ней никто не будет знать, кроме нас.
Как выделить новую память?
Я знаю, я знаю! Надо использовать функцию malloc()!
Агащас. Для этого нам потребуется её найти, а потом выделить память под шелл-код, который бы её вызывал. Так что этот вариант нам не подходит. Вместо удобной функции память придётся просить у операционной системы напрямую, с помощью системного вызова mmap():
void inject_shellcode(const void *shellcode_src, size_t shellcode_size)
{
void *shellcode_dst = mmap(NULL, shellcode_size,
PROT_READ | PROT_WRITE | PROT_EXEC,
MAP_ANONYMOUS | MAP_PRIVATE, -1, 0);
copy_shellcode(shellcode_dst, shellcode_src, shellcode_size);
}К счастью, с помощью ptrace() можно выкрутиться и заставить отлаживаемый процесс выполнять системные вызовы, не изменяя ничего в памяти.
Выполнение системных вызовов
Как же нам выполнить системный вызов, не изменяя ничего в памяти? Для этого надо знать, каким образом выполняются системные вызовы для интересующих нас операционной системы и архитектуры. Linux на x86_64 использует следующий интерфейс:
- номер системного вызова помещается в регистр %rax
- аргументы системного вызова — не более шести — помещаются по порядку в регистры %rsi, %rdi, %rdx, %r10, %r8, %r9
- выполняется инструкция SYSCALL, передающая управление в ядро
- код возврата системного вызова забирается из %rax
Механизм ptrace() позволяет изучать и изменять состояние регистров процессора с помощью команд PTRACE_GETREGS и PTRACE_SETREGS. Таким образом, мы сможем подготовить номер и аргументы системного вызова. Остаётся только как-то выполнить инструкцию SYSCALL.
На самом деле это просто: если мы знаем адрес этой инструкции, то его достаточно поместить в регистр %rip. Тогда следующей инструкцией, которую выполнит процессор, будет наша SYSCALL.
Поиск инструкции SYSCALL
Где же найти SYSCALL? Там, где она может быть. Приложение определённо как-то выполняет системные вызовы, так что где-то в памяти эта инструкция должна быть. Наиболее вероятный кандидат — это библиотека libc. Но нам, в принципе, подойдёт какой угодно исполняемый кусочек памяти, содержащий нужные байты:
unsigned long find_syscall_instruction(struct library *library)
{
for (size_t i = 0; i < library->region_count; i++) {
struct memory_region *region = &library->regions[i];
if (!(region->readable && region->executable))
continue;
const uint8_t *region_data = region->content;
size_t region_size = region->vaddr_high - region->vaddr_low;
if (region_size < 2)
continue;
/*
* 0F 05 syscall
*/
for (size_t offset = 0; offset < region_size - 1; offset++) {
if (region_data[offset + 0] == 0x0F &&
region_data[offset + 1] == 0x05)
{
return region->vaddr_low + offset;
}
}
}
return 0;
}Здесь нам очень помогает информация о регионах памяти, полученная из /proc/$pid/maps. Архитектура x86_64 также немного облегчает задачу тем, что не требует какого-либо выравнивания исполняемого кода. Поэтому нам действительно подойдёт любое место в памяти, где есть байты 0x0F 0x05. Если бы мы имели дело, например, с ARM, то нам бы потребовалось искать байты 0xDF 0x00 (инструкция SVC #0), расположенные по чётному адресу.
Использование PTRACE_{GET,SET}REGS
Сами по себе эти команды тривиальны:
int get_registers(pid_t pid, struct user_regs_struct *registers)
{
int err = 0;
if (ptrace(PTRACE_GETREGS, pid, registers, registers) < 0)
err = -errno;
return err;
}Интерес здесь представляет структура struct user_regs_struct, определяемая в файле <sys/user.h>. Она описывает регистры конкретного процессора. Именно её нам надо заполнить правильными аргументами в правильном порядке. Зная машинный интерфейс системных вызовов, это можно довольно удобно сделать с помощью varargs:
static int set_regs_for_syscall(struct user_regs_struct *registers,
unsigned long syscall_insn_vaddr,
long syscall_number, int args_count, va_list args)
{
registers->rip = syscall_insn_vaddr;
registers->rax = syscall_number;
for (int i = 0; i < args_count; i++) {
switch (i) {
case 0:
registers->rdi = va_arg(args, long);
break;
case 1:
registers->rsi = va_arg(args, long);
break;
case 2:
registers->rdx = va_arg(args, long);
break;
case 3:
registers->r10 = va_arg(args, long);
break;
case 4:
registers->r8 = va_arg(args, long);
break;
case 5:
registers->r9 = va_arg(args, long);
break;
default:
return -E2BIG;
}
}
return 0;
}
static long perform_syscall(pid_t pid, unsigned long syscall_insn_vaddr,
long syscall_number, int args_count, ...)
{
struct user_regs_struct old_registers;
struct user_regs_struct new_registers;
/*
* Сохраним оригинальное состояние регистров, чтобы иметь
* возможность его восстановить после системного вызова.
*/
get_registers(pid, &old_registers);
/*
* После этого делаем копию всех регистров, заполняем их
* аргументами, и устанавливаем новое состояние регистров.
*/
new_registers = old_registers;
va_list args;
va_start(args, args_count);
set_regs_for_syscall(&new_registers, syscall_insn_vaddr,
syscall_number, args_count, args);
va_end(args);
set_registers(pid, &new_registers);
/*
* Здесь мы совершаем магию, чтобы отлаживаемый процесс
* получил управление назад, выполнил системный вызов
* (и только его), после чего опять остановился.
* Об этом в следующем разделе.
*/
wait_for_syscall_completion(pid);
/*
* Забираем результат выполнения системного вызова и
* восстанавливаем оригинальное состояние регистров.
* Теперь целевой процесс ни о чём не догадается.
*/
get_registers(pid, &new_registers);
long result = new_registers.rax;
set_registers(pid, &old_registers);
return result;
}Использование PTRACE_SYSCALL
В коде выше есть один непонятный момент: как нам подождать выполнения системного вызова после того, как мы заполнили регистры?
Для этого следует воспользоваться командой PTRACE_SYSCALL. Как и PTRACE_CONT, она возвращает управление отлаживаемому процессу. Далее процесс исполняется, пока не получит какой-нибудь сигнал: либо отправленный другим процессом, либо сгенерированный точкой останова.
PTRACE_SYSCALL останавливает процесс сигналом SIGTRAP в двух дополнительных местах: непосредственно перед выполнением системного вызова (позволяя отладчику изучать и изменять аргументы) и непосредственно после завершения системного вызова (чтобы отладчик успел посмотреть на код возврата). К сожалению, ptrace() не позволяет узнать, мы сейчас входим в системный вызов или выходим из него, так что отладчик должен помнить и отслеживать это самостоятельно.
Таким образом, после подготовки регистров нам надо дважды подождать остановки процесса сигналом SIGTRAP:
static int wait_for_syscall_enter_exit_stop(pid_t pid)
{
if (ptrace(PTRACE_SYSCALL, pid, 0, 0) < 0)
return -1;
if (wait_for_process_stop(pid, SIGTRAP) < 0)
return -1;
return 0;
}
void wait_for_syscall_completion(pid_t pid)
{
wait_for_syscall_enter_exit_stop(pid);
wait_for_syscall_enter_exit_stop(pid);
}Другие сигналы — отправленные другими процессами, пока мы ждём — следует возвращать назад в отлаживаемый процесс (wait_for_process_stop() это делает). Они скорее всего приведут к прерыванию или перезапуску выполняемого системного вызова. Нам ничего не надо с ними делать, за это отвечает операционная система.
Опция PTRACE_O_TRACESYSGOOD
Как описано выше, PTRACE_SYSCALL не позволяет просто отследить причину остановки: это может быть вход в системный вызов, выход из него, или какой-нибудь другой сигнал. В частности, отлаживаемому процессу могут отправить сигнал SIGTRAP и полностью сбить с толку отладчик (он ведь вынужден считать остановки).
Конкретно этот момент с SIGTRAP может быть исправлен с помощью специальной опции. Если после подключения к процессу установить опцию PTRACE_O_TRACESYSGOOD, то остановки на системных вызовах будут помечены старшим битом в номере сигнала:
- SIGTRAP — кто-то другой прикалывается с сигналами
- SIGTRAP | 0x80 — остановка по системному вызову
int ptrace_attach(pid_t pid)
{
if (ptrace(PTRACE_ATTACH, pid, 0, 0) < 0)
return -1;
if (wait_for_process_stop(pid, SIGSTOP) < 0)
return -1;
+ /* Упрощаем отслеживание системных вызовов */
+ unsigned long options = PTRACE_O_TRACESYSGOOD;
+ if (ptrace(PTRACE_SETOPTIONS, pid, 0, options) < 0)
+ return -1;
return 0;
}
static int wait_for_syscall_enter_exit_stop(pid_t pid)
{
if (ptrace(PTRACE_SYSCALL, pid, 0, 0) < 0)
return -1;
- if (wait_for_process_stop(pid, SIGTRAP) < 0)
+ if (wait_for_process_stop(pid, SIGTRAP | 0x80) < 0)
return -1;
return 0;
}Загрузка шелл-кода в память
Шелл-код загружается в целевой процесс в два этапа:
void write_shellcode(void)
{
char shellcode_text[SHELLCODE_TEXT_SIZE];
size_t shellcode_size = shellcode_end - shellcode_start;
/* Подготавливаем адреса функций, имена библиотек, и т. п. */
prepare_shellcode(shellcode_text, shellcode_size);
/* Собственно переносим шелл-код в процесс */
write_remote_memory(target, shellcode_text_vaddr,
shellcode_text, shellcode_size);
}Для начала в нашу заглушку шелл-кода необходимо вписать изменяющуюся информацию: таблицу адресов импортируемых функций вроде dlopen(), а также имя загружаемой библиотеки с полезной нагрузкой и имя точки входа в эту библиотеку.
static inline void copy_shellcode(char *shellcode_text,
const char *shellcode_addr,
const void *data, size_t length)
{
ptrdiff_t offset = shellcode_addr - shellcode_start;
memcpy(shellcode_text + offset, data, length);
}
static void prepare_shellcode(char *shellcode_text, size_t shellcode_size)
{
copy_shellcode(shellcode_text, shellcode_start,
shellcode_start, shellcode_size);
copy_shellcode(shellcode_text, shellcode_address_dlopen,
&dlopen_vaddr, sizeof(dlopen_vaddr));
copy_shellcode(shellcode_text, shellcode_address_dlsym,
&dlsym_vaddr, sizeof(dlsym_vaddr));
copy_shellcode(shellcode_text, shellcode_address_pthread_create,
&pthread_create_vaddr, sizeof(pthread_create_vaddr));
copy_shellcode(shellcode_text, shellcode_address_pthread_detach,
&pthread_detach_vaddr, sizeof(pthread_detach_vaddr));
copy_shellcode(shellcode_text, shellcode_address_payload,
payload, sizeof(payload));
copy_shellcode(shellcode_text, shellcode_address_entry,
entry, sizeof(entry));
}При этом мы пользуемся символами, экспортируемыми из ассемблерного файла, чтобы рассчитать правильные смещения в шелл-коде:
extern const char shellcode_start[];
extern const char shellcode_address_dlopen[];
extern const char shellcode_address_dlsym[];
extern const char shellcode_address_pthread_create[];
extern const char shellcode_address_pthread_detach[];
extern const char shellcode_address_payload[];
extern const char shellcode_address_entry[];
extern const char shellcode_end[];Так как мы собираемся копировать байты, то для кода на Си мы объявляем эти символы как указатели внутрь массива байтов.
После подготовки загрузить шелл-код в память по известному адресу не составляет труда. Для этого можно воспользоваться всё тем же файлом /proc/$pid/mem, из которого мы читали библиотеки:
int write_remote_memory(pid_t pid, unsigned long vaddr,
const void *data, size_t size)
{
char path[32] = {0};
snprintf(path, sizeof(path), "/proc/%d/mem", pid);
/* Открываем память целевого процесса на запись */
int fd = open(path, O_WRONLY);
if (fd < 0)
return -1;
/* Переходим к нужному адресу */
if (lseek(fd, vaddr, SEEK_SET) < 0) {
close(fd);
return -1;
}
/* Собственно пишем данные */
int err = do_write_remote_memory(fd, data, size);
close(fd);
return err;
}
static int do_write_remote_memory(int fd, const void *data, size_t size)
{
size_t left = size;
/*
* Как и при чтении, не забываем, что ядро может записать
* не весь буфер, так что нам надо отслеживать записанный
* кусок и дописывать остаток в цикле.
*/
while (left > 0) {
ssize_t wrote = write(fd, data, left);
if (wrote < 0)
return -1;
data += wrote;
left -= wrote;
}
return 0;
}Результаты четвёртого шага
Итого, на данный момент у нас есть подготовленный и загруженный в целевой процесс шелл-код — «первая ступень» загрузчика. Мы разрешили все зависимости и поместили код в исполняемом регионе памяти. Остаётся только передать шелл-коду управление, чтобы тот наконец загрузил в память настоящую библиотеку с полезной нагрузкой и передал управление уже ей.
Шаг 5. Запуск нового потока
Имея загруженный в память шелл-код нам остаётся только заставить целевой процесс его исполнить. В принципе, это должно быть просто: кладём в регистр %rip адрес шелл-кода, выполняем PTRACE_SETREGS, затем PTRACE_CONT и дожидаемся точки останова. После этого восстанавливаем значения регистров.
Однако, здесь возникает затруднение, аналогичное поиску подходящей памяти. Какой поток будет исполнять наш шелл-код? Один из существующих потоков или специально созданный новый?
Почему нужен новый поток
К сожалению, существующие потоки использовать опасно. Связано это с тем, что в процессе отладки мы по сути исполняем код «на правах» обработчика сигналов. Как известно, на обработчики сигналов накладываются существенные ограничения. В них можно делать очень немногое:
- читать и изменять атомарные глобальные переменные
- вызывать безопасные (async-signal-safe) функции
Причём практически все безопасные функции — это обёртки над системными вызовами. dlopen() и pthread_create() в их число не входят. Что если прерванный поток именно сейчас находился где-то внутри dlopen(), когда мы заставим его выполнить dlopen() ещё раз?
Поэтому нам потребуется создать отдельный поток для шелл-кода, который, в свою очередь, создаст ещё один поток под полезную нагрузку. Очевидно, мы не сможем использовать pthread_create() для создания нового потока. Как и при выделении памяти, мы можем пользоваться только системными вызовами (их можно выполнять из обработчиков сигналов). Нам потребуется системный вызов clone().
Зачем тогда pthread_create()?У вас может возникнуть вопрос, зачем шелл-коду запускать ещё один новый поток, если мы и так исполняем его в отдельном потоке?
Ответ: потому что запуск потока не сводится к одному вызову clone().
Создание и управление потоками требует очень тесного взаимодействия операционной системы, библиотеки времени исполнения (libc) и библиотеки потоков (pthread). Помимо вызова clone() полноценный поток должен иметь корректно проинициализированный управляющий блок (thread control block, TCB) и локальную память (thread-local storage, TLS), новый поток надо внести в глобальный список потоков, и т. д. Всё это делается внутри pthread_create() и только она знает, как это сделать правильно.
Поэтому мы создадим «неполноценный», простой поток с помощью только clone() и переложим большую часть работы на библиотеки libc и pthread. Наш поток сможет вызвать нужные нам четыре функции, но не более того.
Подготовка к запуску потока
Прежде чем выполнять системный вызов clone() нам потребуется решить несколько сопутствующих вопросов:
- Какой стек будет использовать наш поток?
- Как корректно завершить поток?
- Когда можно удалять шелл-код?
Обработка завершения потока
Первым мы решим самый простой вопрос: что делать после исполнения шелл-кода?
До этого момента мы предполагали, что шелл-код будет использовать существующий поток подобно обработчику сигнала: прервёт существующий поток, воспользуется его стеком, а в конце наткнётся на точку останова, которую мы перехватим и восстановим состояние регистров.
Теперь же у нас будет создаваться новый поток. После того, как он выполнит свою работу, он больше не нужен и его следует завершить. Как? Очень просто: с помощью системного вызова exit(). Именно так на самом деле завершаются все потоки после того, как их коллбек возвращает управление.
В этом случае нам даже не нужна точка останова. Мы можем поместить вызов exit() прямо в шелл-код:
+.set __NR_exit, 60
.set RTLD_LAZY, 1
@@
- /*
- * Точка останова.
- */
- int $3
+ /*
+ * exit(0);
+ */
+ xor %rdi,%rdi
+ mov $__NR_exit,%rax
+ syscallОбратите внимание: системный вызов exit() — это не функция exit() из стандартной библиотеки. Системный вызов exit() завершает только текущий поток, тогда библиотечная функция exit() завершает весь процесс — группу потоков в терминологии ядра. Эта функция на Linux реализуется через системный вызов exit_group().
Выделение памяти под стек
Новому потоку понадобится свой стек. Его надо выделить вместе с памятью под исполняемый код. Это можно сделать одним куском, но правильнее будет выделить отдельный регион, без флага PROT_EXEC:
shellcode_stack_vaddr =
remote_mmap(target, syscall_vaddr, 0,
SHELLCODE_STACK_SIZE,
PROT_READ | PROT_WRITE,
MAP_ANONYMOUS | MAP_PRIVATE | MAP_STACK |
MAP_GROWSDOWN, -1, 0);Здесь важно помнить, что в Linux на x86_64 стек растёт вниз — адрес «верхушки» стека уменьшается, когда в него добавляются элементы. От mmap() мы получаем самый младший адрес стека, а в clone() надо будет передать самый старший. Кроме того, мы передаём в mmap() флаг MAP_GROWSDOWN, который говорит ядру автоматически увеличивать размер стека, пока остаётся свободная память.
Опция PTRACE_O_TRACECLONE
После запуска потока нам потребуется подождать его завершения. Только после этого мы можем освободить память, выделенную под шелл-код и его стек. Подождать завершения потока можно с помощью системного вызова waitpid(), но здесь есть важный момент: если процесс в данный момент отлаживается, то для ожидания потока к нему тоже надо подключиться отладчиком.
Наиболее удобный способ получить новый отлаживаемый поток — это опция PTRACE_O_TRACECLONE. С ней отладчик будет автоматически подключаться ко всем свежесозданным потокам. Кроме того, отладчику отправляются уведомления о создании новых потоков. Наконец, сами потоки создаются в остановленном состоянии, чтобы отладчик мог запустить их, когда ему будет удобно. Без этой опции возникает гонка потоков, в которой отладчику надо успеть сделать PTRACE_ATTACH до того, как новый поток умрёт.
Во-первых, новую опцию надо установить в самом начале:
- unsigned long options = PTRACE_O_TRACESYSGOOD;
+ unsigned long options = PTRACE_O_TRACESYSGOOD | PTRACE_O_TRACECLONE;
if (ptrace(PTRACE_SETOPTIONS, pid, 0, options) < 0)
return -1;Во-вторых, когда мы заставим целевой процесс выполнить системный вызов clone(), нам отправят событие PTRACE_EVENT_CLONE, которое придёт между двумя остановками, вызванными PTRACE_SYSCALL. Это событие надо будет получить и не пропустить:
-void wait_for_syscall_completion(pid_t pid)
+void wait_for_syscall_completion(pid_t pid, long syscall)
{
wait_for_syscall_enter_exit_stop(pid);
+
+ /* Для clone() надо подождать PTRACE_EVENT_CLONE */
+ if (syscall == __NR_clone)
+ wait_for_clone_event(pid);
wait_for_syscall_enter_exit_stop(pid);
}Само ожидание в целом тривиально:
static int wait_for_clone_event(pid_t pid)
{
if (ptrace(PTRACE_CONT, pid, 0, 0) < 0)
return -1;
int event = SIGTRAP | (PTRACE_EVENT_CLONE << 8);
if (wait_for_process_stop(pid, event) < 0)
return -1;
return 0;
}После завершения всех ожиданий clone() вернёт PID нового потока, с которым нам работать. Перед запуском свежесозданного потока с него следует сбросить опции:
void clear_ptrace_options(pid_t pid)
{
ptrace(PTRACE_SETOPTIONS, pid, 0, 0);
}Это необходимо сделать, так как clone() копирует все опции ptrace(), включая PTRACE_O_TRACECLONE. Когда мы запустим этот поток, он создаст ещё один поток, но его-то нам отлаживать уже не надо.
Запуск нового потока
После выделения памяти под стек потока, его можно наконец-то запустить. Для этого следует воспользоваться системным вызовом clone() с правильными флагами:
static int spawn_shell_thread()
{
shell_tid = remote_clone(target, syscall_ret_vaddr,
CLONE_FILES | CLONE_FS | CLONE_IO | CLONE_SIGHAND |
CLONE_SYSVSEM | CLONE_THREAD | CLONE_VM,
/* Указатель на *верхушку* стека */
shellcode_stack_vaddr + SHELLCODE_STACK_SIZE);
if (!shell_tid)
return -1;
return 0;
}В зависимости от флагов clone() может делать много вещей: создавать потоки и процессы, изменять пространства имён, записывать идентификаторы потоков в память, и прочее. Мы используем самую простую комбинацию флагов, создающую поток.
CLONE_FILES, CLONE_FS, CLONE_IO, CLONE_SIGHAND, CLONE_SYSVSEM, CLONE_VM — новый поток разделяет ядерные структуры данных с родительским потоком. Например, без флага CLONE_FILES новый поток получит копию таблицы файловых дескрипторов, которая изменяется независимо (как при fork()). В нашем же случае поток — как и положено потоку — использует ту же таблицу файловых дескрипторов, что и все остальные потоки этого целевого процесса. Другие флаги отвечают за другие ядерные ресурсы. Например, CLONE_VM отвечает за то, что поток использует ту же виртуальную память, что и другие потоки.
Флаг CLONE_THREAD отвечает за создание потока именно как потока: в терминах ядра Linux — как «процесса внутри группы потоков», ведущего себя как положено потоку. Этот флаг, например, заставляет getpid() возвращать одно и то же значение во всех потока, kill() — отправлять сигнал какому-нибудь из потоков группы, execve() — завершать все потоки при смене исполняемого файла, и многое другое.
Стоит отметить, что clone() работает подобно fork(): свежесозданный поток продолжает исполнение с той же точки, что и родительский поток. Сразу же после системного вызова clone() потоки отличаются только его возвращаемым значением: новый поток видит ноль, родительский — идентификатор свежесозданного потока. Остальное пользовательское состояние у них пока что идентично. (Внутри ядра, естественно, для потоков создаются отдельные структуры данных и прочее.)
В то же время, в pthread_create() передаётся указатель на функцию, содержащую исполняемый код для нового потока, и он её вызывает. Как нам сделать так же?
Передача управления
Программы обычно используют fork() следующим образом:
pid_t child = fork();
if (child < 0) {
/* fork() сломался, здесь обработка ошибок */
}
if (child == 0) {
/* Дочерний процесс здесь делает execve() */
}
/* Родительский процесс продолжается здесь */К сожалению, мы так сделать не можем. Наш clone() вызывается с помощью модификации регистров и мы не контролируем захваченный в заложники поток за пределами системного вызова. Так что мы не можем вставить в код условных ветвлений по вкусу.
Вместо этого мы можем воспользоваться интересным хаком. Вспомните, что в clone() передаётся адрес нового стека для потока, который мы полностью контролируем. Если новый поток за инструкцией syscall выполнит инструкцию ret, то он самостоятельно передаст управление по адресу, который мы положим в стек. Таким образом мы можем заставить новый поток выполнить нужный нам код.
Поиск пары инструкций SYSCALL + RET
Новый подход накладывает более строгие требования на машинный код целевого процесса, который мы используем для выполнения системных вызовов. Теперь нам нужен кусок исполняемого кода, в котором за инструкцией syscall следует инструкция ret:
-if (region_size < 2)
+if (region_size < 3)
continue;
/*
* 0F 05 syscall
+ * C3 retq
*/
-for (size_t offset = 0; offset < region_size - 1; offset++) {
+for (size_t offset = 0; offset < region_size - 2; offset++) {
if (region_data[offset + 0] == 0x0F &&
- region_data[offset + 1] == 0x05)
+ region_data[offset + 1] == 0x05 &&
+ region_data[offset + 2] == 0xC3)
{
return region->vaddr_low + offset;
}
}К счастью, подобная последовательность байтов легко обнаруживается в библиотеках.
Подготовка стека
Собственно запись не представляет сложностей. После вызова функции prepare_shellcode(), которая подготавливает исполняемый код, нам надо будет положить на вершину стека адрес этого кода:
void write_shellcode(void)
{
char shellcode_text[SHELLCODE_TEXT_SIZE];
size_t shellcode_size = shellcode_end - shellcode_start;
/* Подготавливаем адреса функций, имена библиотек, и т. п. */
prepare_shellcode(shellcode_text, shellcode_size);
/* Собственно переносим шелл-код в процесс */
write_remote_memory(target, shellcode_text_vaddr,
shellcode_text, shellcode_size);
+ /* Записываем в стек «правильный» адрес возврата */
+ unsigned long retaddr_vaddr =
+ shellcode_stack_vaddr + SHELLCODE_STACK_SIZE - 8;
+ write_remote_memory(target, retaddr_vaddr,
+ &shellcode_text_vaddr, sizeof(shellcode_text_vaddr));
}Обратите внимание, что адрес располагается в конце стека, потому что стек растёт вниз.
Кроме того, со стеком есть интересный момент, связанный с выравниванием. System V ABI требует, чтобы стек (регистр %rsp) был выравнен по границе 16 байтов перед вызовом функции. Адрес shellcode_stack_vaddr + SHELLCODE_STACK_SIZE выравнен правильно: память под стек мы выделяли страницами (выравнены по 4096 байтов), размер стека у нас 1 МБ. Дополнительные 8 байтов, которые мы только что записали, будут сняты со стека инструкцией retq, поэтому и на входе в шелл-код стек тоже выравнен правильно. Однако в шелл-коде у нас ошибка:
- sub $8,%rsp
+ sub $16,%rsp /* соблюдаем выравнивание */
mov %rsp,%rdi
xor %rsi,%rsi
mov %rax,%rdx
xor %rcx,%rcx
mov shellcode_address_pthread_create(%rip),%rax
callq *%raxОчень легко пропустить такую ошибку, где значение %rsp оказывается не кратным 16 сразу же перед входом в функцию pthread_create(). Причём проблема может как проявиться в виде падения с SIGSEGV, а может и нет — в зависимости от реализации pthread_create() и параноидальности компилятора, который может вставлять проверки на выравненность стека.
Запуск потока
Так как теперь стек у нас не пустой, то его адрес для нового потока чуть-чуть поменяется, что надо отразить в аргументах clone():
static int spawn_shell_thread()
{
shell_tid = remote_clone(target, syscall_ret_vaddr,
CLONE_FILES | CLONE_FS | CLONE_IO | CLONE_SIGHAND |
CLONE_SYSVSEM | CLONE_THREAD | CLONE_VM,
/* Указатель на *верхушку* стека */
- shellcode_stack_vaddr + SHELLCODE_STACK_SIZE);
+ shellcode_stack_vaddr + SHELLCODE_STACK_SIZE - 8);
if (!shell_tid)
return -1;
return 0;
}При запуске нового трассируемого потока ptrace() отправляет ему сигнал SIGSTOP, который необходимо получить и проигнорировать:
int ignore_thread_stop(pid_t pid)
{
return wait_for_process_stop(pid, SIGSTOP);
}Всё. После всей проведённой подготовки остаётся лишь собственно запустить наш поток с помощью простого вызова ptrace():
void resume_thread(pid_t pid)
{
ptrace(PTRACE_CONT, pid, 0, 0);
}Завершение потока
После того, как новый поток отработает, он завершается, выполняя системный вызов exit(). Мы можем дождаться его завершения с помощью waitpid(). Обычно это не работает — флаг CLONE_THREAD намеренно отключает wait() для потоков,— но мы используем PTRACE_O_TRACECLONE, который включает эту возможность для отладчика:
int wait_for_process_exit(pid_t pid)
{
int status = 0;
if (waitpid(pid, &status, 0) < 0)
return -1;
if (!WIFEXITED(status))
return -1;
return WEXITSTATUS(status);
}Если исследовать библиотеку pthread глубже, то можно узнать, что pthread_join() работает похожим образом и библиотека pthread тоже запускает потоки изначально приостановленными и отлаживаемыми, как раз чтобы иметь возможность дожидаться их завершения. Действительно, потоки — это сложно. Они требуют очень тонкого взаимодействия операционной системы, стандартной библиотеки языка, и отладчиков.
Освобождение памяти
После завершения потока мы знаем, что шелл-код больше не выполняется. Это позволяет нам освободить память, выделенную под шелл-код и его стек, с помощью элементарного системного вызова munmap():
void remote_munmap(pid_t pid, unsigned long syscall_insn_vaddr,
unsigned long addr, size_t len)
{
perform_syscall(pid, syscall_insn_vaddr,
__NR_munmap, 2, (long) addr, (long) len);
}
static void unmap_shellcode()
{
remote_munmap(target, syscall_ret_vaddr,
shellcode_text_vaddr, SHELLCODE_TEXT_SIZE);
remote_munmap(target, syscall_ret_vaddr,
shellcode_stack_vaddr, SHELLCODE_STACK_SIZE);
}Однако, перед тем, как выполнять этот системный вызов, нам необходимо остановить целевой поток — иначе ptrace() работать не будет. Для этого следует отправить процессу любой сигнал (например, SIGSTOP), дождаться его получения процессом, а потом не дать процессу его обработать (чтобы тот ничего не подозревал):
int stop_thread(pid_t pid)
{
if (kill(pid, SIGSTOP) < 0)
return -1;
if (wait_for_process_stop(pid, SIGSTOP) < 0)
return -1;
return 0;
}Отключение отладчика
Наконец, нам остаётся отключиться от целевого процесса, перестав быть его отладчиком. Для этого надо воспользоваться PTRACE_DETACH:
int ptrace_detach(pid_t pid)
{
if (ptrace(PTRACE_DETACH, pid, 0, 0) < 0)
return -1;
return 0;
}Результаты пятого шага
После выполнения всех вышеизложенных махинаций нам удалось загрузить в целевой процесс нужную нам библиотеку и создать в процессе поток, который выполнит функцию из загруженной библиотеки. После завершения функции поток завершится, но его стек и загруженная библиотека останутся в памяти. Их освобождать некому, но они и никому не мешают.
Заключение
Что можно со всем этим сделать? Да что угодно. Например, показывать содержимое полей ввода с паролями там, где разработчики не предусмотрели такую возможность.
Графические приложения для Linux могут использовать разные тулкиты. Мы для определённости возьмём GTK+ как один из наиболее распространённых. Собрать загружаемую библиотеку можно очень просто, с помощью примерно следующего правила для make:
libpayload.so: payload.c
$(CC) $(CFLAGS) $(shell pkg-config --cflags --libs gtk+-3.0) -shared -o $@ $<Точку входа мы назовём entry() и единственной её задачей будет запланировать выполнение коллбека на главном потоке GTK-приложения — потому что в GTK с UI можно взаимодействовать только из главного потока, содержащего цикл обработки событий:
#include <glib.h>
#include <gtk/gtk.h>
static gboolean actual_entry(gpointer _arg)
{
/* Здесь мы добавим и реализуем показ паролей: */
hook_gtk_entry_constructor();
/* И вернём FALSE, чтобы коллбек выполнился только один раз */
return FALSE;
}
void entry(void)
{
/* Попросим выполнить коллбек когда-нибудь, когда удобно */
g_idle_add_full(G_PRIORITY_DEFAULT_IDLE, actual_entry, NULL, NULL);
}Виджет, использующийся в GTK для ввода паролей, называется GtkEntry. Его свойство "input-purpose" отвечает за скрытие парольных символов. У него также есть возможность устанавливать «иконку», располагаемую слева или справа, которую можно использовать в качестве кнопки.
GTK основан на glib — очень динамической объектной системе — где для изменения поведения всех GtkEntry можно изменять их класс во время исполнения. Нас интересует коллбек constructed(), вызываемый после завершения конструирования объекта. Заменим его на свой:
static void (*old_gtk_entry_constructed)(GObject *object);
static void new_gtk_entry_constructed(GObject *object)
{
GtkEntry *entry = GTK_ENTRY(object);
/* Вызываем оригинальную реализацию */
old_gtk_entry_constructed(object);
/* Дальше мы можем творить, что хотим, со свежесозданным entry */
}
static void hook_gtk_entry_constructor(void)
{
/* Получаем доступ к классу GtkEntry */
GTypeClass *entry_type_class = g_type_class_peek(GTK_TYPE_ENTRY);
GObjectClass *entry_object_class = G_OBJECT_CLASS(entry_type_class);
/*
* Заменяем в нём коллбек "constructed" на свой и сохраняем оригинал.
*/
old_gtk_entry_constructed = entry_object_class->constructed;
entry_object_class->constructed = new_gtk_entry_constructed;
}Нам от GtkEntry надо две вещи:
- чтобы у полей, содержащих пароли, появлялась кнопка
- чтобы при нажатии на кнопку пароль показывался
К счастью, для этого у GtkEntry есть сигналы, уведомляющие о событиях, происходящих с полем ввода. Мы можем добавить свои обработчики, выполняющие нужные нам действия:
static void new_gtk_entry_constructed(GObject *object)
{
GtkEntry *entry = GTK_ENTRY(object);
old_gtk_entry_constructed(object);
/* Уведомление о смене режима отображения поля */
g_signal_connect(entry, "notify::input-purpose",
G_CALLBACK(input_purpose_changed), NULL);
/* Вызовется при удержании кнопки мыши */
g_signal_connect(entry, "icon-press",
G_CALLBACK(icon_pressed), NULL);
/* Вызовется при отпускании кнопки мыши */
g_signal_connect(entry, "icon-release",
G_CALLBACK(icon_released), NULL);
}Дальше всё просто. При получении уведомления о смене режима отображения нам надо добавлять или убирать иконку с подходящим изображением, а также включать или выключать обработку нажатий на иконку. Наша кнопка должна показываться только для полей с паролями.
static void input_purpose_changed(GtkEntry *entry)
{
GtkInputPurpose purpose = gtk_entry_get_input_purpose(entry);
if (purpose == GTK_INPUT_PURPOSE_PASSWORD) {
gtk_entry_set_icon_activatable(entry, GTK_ENTRY_ICON_PRIMARY,
TRUE);
gtk_entry_set_icon_from_icon_name(entry, GTK_ENTRY_ICON_PRIMARY,
"list-remove");
} else {
gtk_entry_set_icon_activatable(entry, GTK_ENTRY_ICON_PRIMARY,
FALSE);
gtk_entry_set_icon_from_icon_name(entry, GTK_ENTRY_ICON_PRIMARY,
NULL);
}
}Обработка нажатий элементарная: проверяем, на какую иконку из двух нажали, и если надо, то включаем-выключаем отображение содержимого и меняем изображение на иконке, чтобы пользователь получил визуальное подтверждение нажатия:
static void icon_pressed(GtkEntry *entry, GtkEntryIconPosition position)
{
if (position != GTK_ENTRY_ICON_PRIMARY)
return;
gtk_entry_set_visibility(entry, TRUE);
gtk_entry_set_icon_from_icon_name(entry, GTK_ENTRY_ICON_PRIMARY,
"list-add");
}
static void icon_released(GtkEntry *entry, GtkEntryIconPosition position)
{
if (position != GTK_ENTRY_ICON_PRIMARY)
return;
gtk_entry_set_visibility(entry, FALSE);
gtk_entry_set_icon_from_icon_name(entry, GTK_ENTRY_ICON_PRIMARY,
"list-remove");
}Вот и всё.
На GitHub можно найти полный исходный код загрузчика и библиотеки (GPLv2).
Кстати, я вам соврал об отсутствии готового решения. Конечно же gdb умеет загружать и исполнять произвольный код в чужих процессах:
$ gdb --pid $(pgrep target) \
--batch \
-ex 'compile file -raw shell-code.c'
Комментариев нет:
Отправить комментарий