Меня зовут Андрей Рыбалка, я участвую в Russian AI Cup под ником lama и я снова расскажу вам, как не выиграть макбук. Благо, я в этом человек опытный — вот этими вот руками не выиграл уже целых 7 штук.
Итак, задачей этого года был платформер/2D-шутер, для которого нужно было написать бота.
Выглядела игра вот так:
Бот выглядел так:

Если вам интересно, как картинка #2 играла в картинку #1, прошу под кат.
Если вы не участвовали и не читали другие статьи, рекомендую первым делом посмотреть, как это всё выглядит в динамике на сайте либо на тюбике:
Турнирная система
Для начала даётся 2 с лишним недели на программирование. Затем стартует первый раунд. Длится 2 дня и 300 лучших из него проходят дальше. После раунда правила игры меняются (теперь мы управляем сразу двумя персонажами) и даётся ещё неделя, по истечению которой проходит второй раунд. Затем правила снова усложняются (теперь мы играем на гораздо более сложных картах), даётся ещё неделя и, наконец, играем финал.
Но и это не конец. После финала есть ещё неделя, в конце которой песочница просто останавливается, и 6 лучших в ней, исключая призёров финала, также награждаются. Принципиальная разница между финалом песочницы и финалом чемпионата в том, что в песочнице игры создаются в случайном формате, а не только в формате текущего раунда.
Куда же без неё? Можно пропускать, кому неинтересно. Техническая часть будет ниже.
Неделя Beta-тестирования и Первый раунд
Начал программировать, кажется, на следующий день после начала Open Beta Test. Но лично на меня несколько демотивирующе подействовало то, что организаторы в этот раз, в отличие от прошлого, решили снова отойти от практики публикации псевдокода симулятора. Наверняка среди участников были и те, кому нравится писать симулятор путём реверс-инжиниринга, но я не один из них, и мне было скучно этим заниматься. Поскольку это был далеко не первый мой чемпионат, я знал, что рано или поздно втянусь, но по описанной выше причине, втянулся я поздно. В итоге, то, что некоторые участники сделали в первые пару-тройку дней, я смог себя заставить закончить только за полторы недели. В результате первую строку кода самого бота я написал за 5 суток до первого раунда. Короче говоря, к началу первого раунда у меня ничего не было готово, и раунд прошёл без моего участия. Я же решил, что буду пробиваться сразу во второй раунд, через донабор.
Второй раунд
К этому моменту я уже программировал на полную катушку, в среднем 4-6 часов в день. За пару дней до старта второго раунда я залил первую версию бота. Она сразу бодро пошла вверх и быстро влезла в топ-10 песочницы. Затем начался раунд, где я занял пятое место.
Финал
Первый вечер финальной недели (из четырёх, ибо на пятницу был назначен старт) потратил на поиск пути. Идей было ещё много, а на чём сконцентрироваться и что из идей потенциально даст наибольший результат было непонятно, поэтому пытался улучшать в первую очередь то, что являлось причиной наибольшего числа поражений. Во вторник и среду это были улучшения прицеливания и стрельбы, а также контроль аптечек.
Затем я увидел, что всё же произошло то, чего я давно ждал, но надеялся, что это не случится — некоторые противники начали активно использовать мины.
Дело в том, что во время OBT, организаторы прислушались к предложению участников и изменили одну из игровых механик. В общем случае это, конечно же, хорошо, когда к участникам прислушиваются. Но конкретно в этот раз наличие фидбека сыграло злую шутку. Короче говоря, организаторы сделали так, чтобы мины можно было взрывать выстрелом.
Само по себе это логично. Если бы я был миной и в меня стреляли, я бы тоже взрывался. Но проблема в том, что играли мы на очки, а очки давались не только за убийства, но и за урон. Таким образом получалось, что если ты подходишь достаточно близко к противнику, ставишь под себя мины и стреляешь в них, ты взрывом убиваешь и противника и себя. Увернуться невозможно. Вы оба получаете 1000 очков за то, что оба персонажа умерли, но ты получаешь ещё и очки за урон. Таким образом, если противник был здоров, ты получишь 1000 очков за убийство и 100 за урон, а противник — только 1000.
Хотя все об этом знали, но в топе практически никто до последнего не пользовался минами. Не знаю как другие, а лично я не пользовался просто потому, что не хотелось злоупотреблять ненамеренно допущенным просчётом. Но, как говорили в одном фильме, я знал, что рано или поздно мы перейдем и на эту дрянь.
Короче говоря, в середине ночи со среды на четверг, я на скорую руку реализовал самоподрыв. Чисто ситуативный, ничего продвинутого. Просто по принципу, что если на текущем тике моему персонажу выгодно самоубиться, и он может это сделать, он так и поступает. Как показала практика, некоторые другие участники планировали использование мин заранее, так что реализовали более продвинутый суицид, но стратегически планировали зарелизить его перед самым финалом. В итоге, получилось что получилось — 9 место в финале, равно как и в прошлом году.
Финал песочницы
После финала я уехал из города на праздники. Вернулся через неделю и в первый вечер, буквально за 2-3 часа работы, сильно улучшил мины, о чём подробнее напишу в технической части. Остальные изменения в основном касались правки багов и допиливания оценочной функции. Короче говоря, мало программирования и много тестов.
То ли быстродействие Java, то ли радиус кривизны рук, а скорее, и то и другое вместе, в очередной раз не позволили мне обойтись чистой симуляцией. Поэтому движение, нормальная стрельба и установка мин у меня разделены.
Симуляция
Глазами бота, мир выглядел вот так:
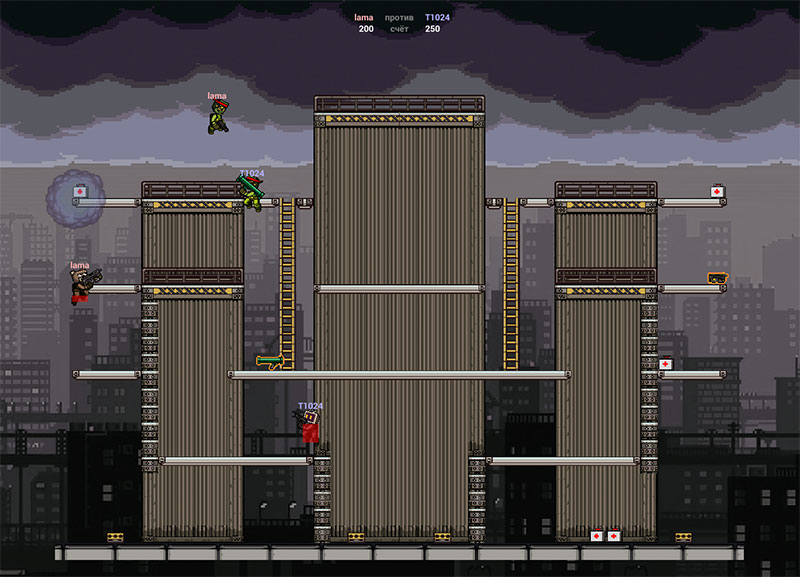
На видео, думаю, и так всё примерно понятно. В левом верхнем углу дебаг оценочной функции. Можно посмотреть, из чего состоит Score каждой траектории. Желтые силуэты (к примеру, на 2:30) — это те самые траектории движения в 9 направлениях, о них будет ниже. Линии из стрелок где-то начиная с 2:50 — это поиск пути (красная — к врагу, зеленая — к аптечке, желто-зеленая — к оружию, синяя — к мине). Зелёные квадраты в конце видео — это мой PVS — тайлы, которые видны из выбранного тайла. Красные точки в их центрах показывают, откуда есть обратная видимость.
Движения персонажа симулирую без микротиков. Полёты пуль тоже, но в них я использую несколько хаков, чтобы реже случались ситуации, когда в полном тике пуля "проходит насквозь" персонажа, не задевая его, хотя с микротиками должна была бы задеть. Например, если задуматься, описанная ситуация может возникнуть только на углах:
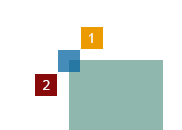
В тике 1 пуля находится в позиции 1, на тике 2 — в позиции 2 соответственно. Без микротиков — Борис-хрен-попадёшь, с микротиками — отстреленное ухо. Так вот, чтобы такое произошло, позиция пули в тиках 1 и 2 должна находиться по разные стороны от хотя бы одной из граней персонажа или тайла (прямоугольник мятного цвета). Таким образом можно симулировать пулю без микротиков до тех пор, пока, применительно к картинке выше, не выполнится условие old_bullet.x > character_left_side.x != new_bullet.x > character_left_side.x, а если это случилось, значит следует проанализировать этот тик более тщательно.
Далее, каждый тик я пересчитывал траектории всех летящих пуль до их столкновения со стеной и сохранял их положение в каждом тике в массив, чтобы затем в симуляции можно было быстро проверять коллизии с ними.
Для базуки, после попадания в стену я, математически, без микротиков, высчитывал точную точку удара, чтобы правильно вычислить эпицентр взрыва.
Также, каждый тик я заполнял массив dodge_trajectories — симулировал движение каждого персонажа, включая врагов, в 8 направлениях на 25 тиков (жёлтые силуэты на видео из визуализатора, после включения чекбокса possible traj. К примеру, на 2:30). И, как и с пулями, сохранял все возможные положения в каждом тике. Это затем использовалось во многих местах, некоторые из которых я ещё упомяну.
Ещё я заранее высчитывал PVS по тайлам. Для каждой клетки я хранил список тайлов, центр которых можно увидеть, стоя в ней. Вычислялось трассировкой луча. На это можно посмотреть в видео из визуализатора, в конце. Зелёные квадраты — это тайлы, которые видны из выбранной клетки. Красные точки в их центрах показывают, откуда есть обратная видимость.
Поиск пути
Реализован алгоритмом Дейкстры по Waypoint-ам. Вейпоинтом считался тайл, в котором можно стоять. Адаптация алгоритма для 2D-платформера своя, доморощенная, а потому, в угоду оптимизации, построена на костылях. Но работал достаточно быстро: я предварительно строил Дейкстру (не придумал как правильнее это сказать) от каждого предмета на уровне до каждого тайла. Пути я строил только такие, которые обладали двухсторонней проходимостью. Это нужно было для того, чтобы позже можно было очень быстро получить путь из любого тайла к любой аптечке/оружию/мине. От этого ограничения можно было избавиться, но на практике, я посчитал более разумным потратить время на другие вещи, ибо большого вреда от этого ограничения не было.
Кроме того, каждый раз при переходе в другой тайл любым персонажем (своим и вражеским), я пересчитывал для него путь к ближайшему противнику, аптечке, а также, к мине и к оружию, если они ему ещё были нужны.
На моём домашнем компьютере в игре в 1000 тиков весь поиск пути занимал порядка 100 мс в сумме.
Если путь пересекает врага или друга, я просто прибавляю к его весу пару десятков единиц. Таким образом, если есть относительно короткий обход, или если после этого выгоднее бежать к другому объекту, я так и сделаю. На видео из визуализатора выше это можно увидеть на 2:55, где путь к ближайшему врагу проложен в обход, т.к. прямой путь пересекает второго персонажа.
Визуализация поиска пути:
Полупрозрачные фиолетовые квадратики — вейпоинты, они же — вершины графа. Салатовые стрелки — рёбра^1^ графа^2^
^1^не путать с рёбрышками, ^2^ любые совпадения монархического характера случайны [прим.]
Передвижение
Два персонажа ходили по очереди. Если вы сейчас подумали — "и вот это попало в топ 10?!", то вы подумали правильно. :) На то, чтобы ходить обоими, не хватало ресурсов. Исключением был случай появления новой летящей пули.
В основе выбора траектории лежит генетика без скрещивания. Но если в прошлом году, в футболе, генетика отлично себя показала, то в этом году она давала весьма небольшое преимущество. Мои эксперименты показали очень близкий результат как генетикой, так и случайным поиском. Причин тому я вижу несколько, но главной мне видится следующая: В футболе у нас была фиксированная цель — мяч. Его поведение большую часть времени было предсказуемо — если мы нашли хорошую траекторию для удара мяча по воротам и следуем ей, то и через 20 тиков, вероятно, эта траектория по-прежнему будет хорошей, т.к. мяч не может самопроизвольно изменить свою траекторию. А вот в этом году мы играли не с мячом, а с вражескими персонажами. Они каждый тик меняли своё поведение. Так что актуальность траектории сохранялась очень недолго.
Я же всё равно использовал генетику по двум причинам:
- Я просто скопировал её код с прошлого года. Это было даже забавно, как мало мне пришлось внести изменений, за исключением оценочной функции, чтобы бот начал сносно двигаться. Короче говоря, я полторы недели писал симулятор, а затем где-то за час скопировал логику движения с прошлого года, ещё за час накидал простейшую оценку и бот, при стрельбе а-ля Quick Start, стал у оного достаточно стабильно выигрывать.
- Я, по всей видимости, люблю боль. Иначе не знаю, как объяснить, почему я снова писал на Java, а не как все нормальные топы:

Так что мне приходилось всячески извращаться, чтобы стратегия просто не падала с таймаутом в каждой первой игре. А подход с генетикой позволял мне сохранять snapshot симуляции мира и посчитанных очков и затем, при просчете следующих поколений, инвалидировать снепшоты только начиная с первого мутировавшего гена.
Т.е. грубо говоря, если в первом поколении я 10 тиков шёл вправо, а затем прыгал вверх, а во втором поколении я оцениваю мутанта, который 10 тиков идёт вправо, а затем спрыгивает вниз, то точкой отсчёта для мутанта будет ранее вычисленный snapshot мира и очки после 10 движений вправо. Тем самым я значительно сокращал вычисления.
Игого, примерный алгоритм движения:
- Генерируем N случайных генотипов. Каждый состоит из M случайных генов. Каждый ген представляет собой закодированный числами Action: одно число отвечает за направление движения, второе — за прыжки/ходьбу/спрыгивание вниз, третье — за базовую стрельбу (чисто для оценочной функции, основной алгоритм стрельбы будет описан ниже), четвертое — за количество повторений этого действия. Общее количество действий в генотипе, вместе с повторениями, не превышает глубину симуляции — 40 тиков.
- Добавляем к ним некоторое количество hard-coded генотипов: прямое движение по 9 направлениям (8 сторон + стояние на месте) и ещё пару простых пресетов, которые на практике немного помогали быстрее выбираться из некоторых типичных ситуаций в лабиринте. Например, вот такие траектории: ⮤ ⮥
- Добавляем лучший генотип с предыдущего хода.
- Оцениваем все, оставляем M лучших.
- Создаём следующее поколение, в котором в каждом генотипе один или более ген мутировал.
- Добавляем их в общий пулл, в котором уже хранятся M лучших из прошлого поколения.
- Повторяем, начиная с пункта 4, ещё несколько раз.
Оценочная функция
Собственно, место, где живёт стратегия.
На протяжении чемпионата была добавлена целая куча всевозможных метрик (если быть точным, 57). Часть из них не дожила до финала. Другая часть дожила, но на фоне инфляции Score-ов на протяжении чемпионата, в итоге практически не влияла на результат, ну а остальные, порядка 20-25 штук, как раз и отвечали за передвижение и базовую стрельбу.
Приведу несколько примеров важных метрик, в произвольном порядке:
- Пенальти за попадание в меня пули / взрыва базуки.
- Бонус за степени свободы. Т.е. за количество направлений (вверх/вниз/влево/вправо), куда я могу перемещаться из текущего тайла. Как несложно догадаться, чем больше степеней свободы — тем больше шансов увернуться от пули. Этот бонус заставлял бота придерживаться платформ и лестниц. Бонус в три раза выше если у противника базука.
- Пенальти за расстояние (через поиск пути) до ближайшей аптечки; за среднее расстояние (через поиск пути) до всех аптечек; за то, что путь от него к ближайшей к нему аптечке меньше, чем путь от меня к его(!) аптечке.
- Пенальти за то, что враг видит мою голову.
- Пенальти за то, что враг видит мои ноги (4 и 5 пункты заставляли бота прятаться за частичными укрытиями).
- Бонус за атаку во время перезарядки оружия врага.
- Бонус за сделанные выстрелы.
- Пенальти за слишком большое или слишком малое расстояние от врага. Зависело от нескольких факторов: здоровье обоих, перезаряжены ли оружия обоих и т.д.
- Бонус за опасные условия труда.
- Пенальти за состояние падения и за состояние полёта на джамппаде (ибо эти два состояния невозможно прервать, а следовательно, в них гораздо меньше шансов уклониться от пули).
- Бонус за количество аптечек, которые находятся с противоположной стороны от меня, в сравнении с врагом (т.е. к примеру, если враг справа от меня, то я получу бонус за количество аптечек, которые слева от меня. Это в основном имело смысл в 1 и 2 раундах, где единственный путь от врага к этим аптечкам проходил через меня).
- Бонус за следование пути к врагу, к аптечке (если я ранен), к мине (если у меня их меньше двух), к оружию (если его нет).
- Пенальти за близость стен в случае, если у врага базука. Конкретнее, я считал, за сколько тиков ракета врага, если он её выпустит, долетит до стены возле меня, и на основании этого та зона возле стены, из которой невозможно успеть убежать от взрыва, считалась опасной и за нахождение в ней я получал штраф.
- Новогодний бонус.
Уклонение от пуль
Происходит автоматически, за счёт вышеописанного
Прицеливание
Тут происходит много всего. Пожалуй, самым важным является простой и эффективный алгоритм, решающий следует ли мне наводить оружие на врага (ибо прицеливание увеличивает разброс оружия):
- Считаем угол между (last_angle — min_spread) и (last_angle + max_spread).
- Пускаем лучи от центра моего персонажа к двум наиболее близким к перпендикуляру углам AABB противника. Если какой-то из них находится вне диапазона (last_angle — min_spread)… (last_angle + max_spread), обрезаем по этому диапазону.
- Считаем угол между этими лучами.
- Делим первый второй угол на первый, получаем Coverage (покрытие). Представляет собой текущую вероятность в процентах, что траектория выпущенной пули будет пересекаться с боксом противника.
- Симулируем Action, в котором происходит прицеливание во врага, вместе с изменением разброса.
- Повторяем пункты 1..4 для нового набора [last_angle, min_spread, max_spread]. Таким образом, считаем, каким будет coverage в случае, если мы прицелимся.
- В результате у нас есть текущий coverage, а также предсказанный coverage в случае, если мы наведём оружие на врага. Если предполагаемое покрытие больше текущего, мы целимся.
Демо 2 пункта:
Если линии зелёные, значит противник целиком попадает в область прицеливания. Оранжевые — частично, красные — не попадает совсем.
Но целюсь я обычно не в пузо врага, а в какую-то более оптимальную точку.
Для пистолета и штурмовой винтовки, если враг находится в воздухе, я считаю, за сколько тиков пуля долетит до его текущего положения, затем беру из описанного выше массива dodge_trajectories все его возможные положения через это количество тиков, усредняю все 8 позиций и при прицеливании считаю, что враг находится в этой усреднённой точке.
Если же он стоит на земле, целюсь "в голову", исходя из тех соображений, что прыгать он может только вверх, так что он выстрела в голову гораздо сложнее увернуться, чем от выстрела в живот, и, уж тем более, в ноги.
Для базуки я подобным же образом беру 8 возможных положений через столько тиков, за сколько ракета долетит до врага. Для них строю конус (точнее, сектор круга), описывающий все эти положения и внутри этого конуса перебираю траектории с некоторым шагом. Для каждой траектории я симулирую полёт ракеты, вместе со взрывом в случае попадания в стену. Ту траекторию, в которой у врага меньше всего шансов увернуться, я использую для прицеливания.
Ещё в некоторых случаях для падения и полёта с джамппада (т.е. тех состояний, которые противник не может прервать) я просто считаю точку перехвата пулей врага, путём решения системы уравнений движения. Код скопировал из своего же бота для хоккея 2014 года, где он использовался для перехвата шайбы. :)
Кроме прочего, в определенных ситуациях я отменял прицеливание, если в моей траектории движения на ближайшие 10 тиков есть позиция, в которой луч из центра этой позиции в направлении текущего last_angle пересекается с врагом. Это позволяло мне целиться движением, без изменения угла, а следовательно, без увеличения разброса.
Стрельба
Базовая стрельба была зашита в найденную траекторию и была чисто ситуативной. Но также, каждый тик мой бот пытался вычислить, имеет ли смысл выстрелить прямо сейчас, и, если имеет, стрелял. К примеру:
- если враг гарантированно не может увернуться;
- если coverage был выше некоторого фиксированного значения.
Также, если моим оружием была базука, я симулировал всевозможные траектории в пределах spread в случае немедленного выстрела, с некоторым шагом. И если результат показывал, что потенциальная польза превышает потенциальный вред, я стрелял. Пользу я оценивал по 4-м метрикам по убыванию важности для себя и для врага: гарантированная смерть (моя или врага), возможная смерть, гарантированный урон, возможный урон. Если была хотя бы одна траектория, при которой, к примеру, я гарантированно убью себя и только возможно убью врага, я не стрелял.
Были и другие проверки. К примеру, я мог отменить выстрел в случае, если в следующем тике моей траектории потенциальный coverage выше, чем в текущем.
Вообще, логика мне подсказывала, что базовую стрельбу нужно отключить, но тесты показывали обратное. Не представляю, почему.
Мины
На момент финала были в самом зачаточном состоянии: я каждый тик симулировал, что будет, если я прямо сейчас поставлю 1 или 2 мины, в зависимости от здоровья соперника, и выстрелю в них. Если я гарантированно убиваю противника и если это мне выгодно (либо по очкам, либо потому, что умрёт только противник), я это делал.
После нового года, вернувшись из поездки, я первый вечер написал алгоритм, который вывел меня на 2-4 места в таблице. Алгоритм был простым: я всего лишь каждый тик симулировал, что будет, если я прямо сейчас переключусь в режим берсерка и побегу навстречу врагу с тем, чтобы подорвать его миной при первой возможности. Для врага я при этом симулировал простое уклонения, используя всё тот же dodge_trajectories: я брал три траектории, увеличивающие дистанцию от меня. К примеру, если я был слева от врага, то я анализировал три случая: враг убегает вправо; враг убегает вправо и прыгает; убегает вправо и спрыгивает вниз. Если во всех трёх случаях я гарантированно успевал убить его миной и он гарантированно не мог поставить мины раньше меня, я это делал.
Также алгоритм умел прыгать или спрыгивать на уровне Quick Start стратегии — просто на основании разницы в Y координате.
В результате на картах финала почти каждый матч заканчивался менее чем за 1000 тиков самоподрывом обоих моих персонажей.
Пацифизм
Увидев, насколько эффективны мои мины, я решил проверить высказанное мной ранее в telegram канале предположение, что в финале потенциально можно было взять место в топе вообще без стрельбы. Так что я просто взял и отключил стрельбу в моём боте, за исключением выстрела в мину. Единственное только — чтобы не терять рейтинг, этот режим включался только в случае, если у меня есть достаточно мин для убийства врага.
Короче говоря, мой бот стал пацифистом. Чтобы продемонстрировать своё миролюбие и смирение, он даже не смотрел на врага (см. видео). Ну стрелял он иногда в мины, подумаешь. В противников ведь не стрелял! А если они при этом погибали — ну что поделаешь, трагическая случайность.
В общем, залил я эту версию на сайт, создал по 4 игры с каждым из тогдашнего топ3 и...

… выиграл 3 из 4 игр против каждого. В общем, странно, что соседи не приходили жаловаться на мой гомерический хохот посреди ночи. :)
Полюбуйтесь сами:
Эх, если бы я потратил эти 2-3 часа до финала, а не после, может быть эта статья рассказывала бы, как макбук выиграть, а не как этого всеми силами избегать, кто знает. Увы, история не знает сослагательного наклонения.
В целом, любые изменения тестировал столько раз, чтобы результат был статистически значим. А точнее, чтобы нижняя граница доверительного интервала превышала 50%. Для финала песочницы скриптом подбирал коэффициенты. В предыдущие годы пробовал генетикой, но это работало плохо — для нормального результата нужно было сыграть слишком много игр. Так что в этот раз я просто менял один коэффициент за раз и отыгрывал штук 200 игр. В тех случаях, когда результат получался хорошим, проводил дополнительные тесты. Короче говоря, оставлял на ночь перебор двух десятков коэффициентов и к утру имел результат.
Вот как-то так оно всё и работало с горем пополам.
В последние пару дней перед концом песочницы я большую часть времени держался на втором месте в таблице с весомым отрывом от третьего, но за несколько часов до окончания песочницы мне не повезло и у меня пошла череда игр по правилам 1 и 2 раундов, в то время как моя стратегия играла сильнее всего по правилам финала. К примеру, вот тут из 13 игр всего 1 по финальным правилам. Так я к тому же, ещё и мой win rate в этих играх вышел значительно хуже обычного. В общем, всемогущий рандом:
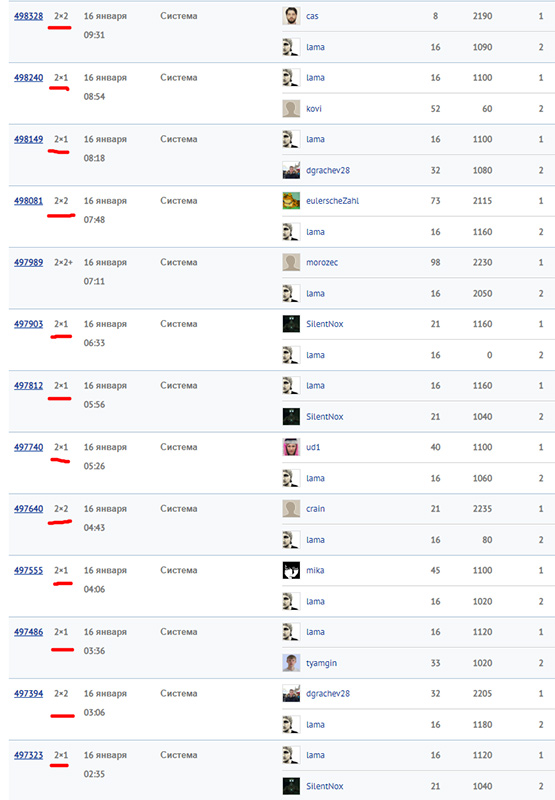
В итоге я проиграл слишком много игр, потерял всё своё преимущество и свалился со 2 на 4 место, а отыграться уже не успел, ибо чемпионат закончился. Хорошо хоть, что в списке победителей песочницы не потерял первое место.
В очередной раз хочу поблагодарить Mail.ru Group за этот очередной замечательный чемпионат. Было очень интересно, что, как мне кажется, показало и достаточно высокое количество участников в этом году (около 1100 человек). А что были некоторые недостатки — ну, всего не предвидишь. Но надеюсь, в следующий раз хотя бы псевдокод симуляции будет доступен. Короче говоря, спасибо, ребята, было круто!
Также спасибо всем, кто составил достойную конкуренцию. На этом, думаю, чемпионат для меня наконец можно считать завершённым. Пора готовиться к статье на тему "Как не выиграть 8 макбуков".
Комментариев нет:
Отправить комментарий