В докладе я коротко упомяну о сделанных ранее правках (патчах), которые существенно расширяют возможности системы и готовят базу для кластера (выгрузка истории в «Кликхаус», асинхронный поллинг). И подробно рассмотрю вопросы, возникшие при кластеризации системы — разрешение конфликтов идентификаторов в БД, немного о CAP theorem и мониторинге с распределёнными БД, о нюансах работы Zabbix в кластерном режиме: резервирование и координирование работы серверов и прокси, о «доменах мониторинга» и новом взгляде на архитектуру системы.
Коротко расскажу о том, как запустить кластер у себя, где взять исходники, какие доп. настройки потребуются для кластера.

HighLoad++ Siberia 2019. Зал «Томск». 24 июня, 17:00. Тезисы и презентация. Следующая конференция HighLoad++ пройдет 6 и 7 апреля 2020 года в Санкт-Петербурге. Подробности и билеты по ссылке.
Михаи Макуров (далее – ММ): – Я работаю в компании-провайдере. Провайдер называется «Интерсвязь», работает в городе Челябинске. У нас примерно 1,5 миллиона человек. И для того, чтобы провайдер работал, есть огромная инфраструктура. У нас примерно 70 тысяч единиц оборудования: коммутаторы, IoT-устройства… – много всего того, что нужно мониторить. Конкретно этот доклад – про использование Zabbix’а, о построении кластера на основе «Заббикса» для инфраструктурного мониторинга.
Я 12 лет в провайдере. Сейчас я не совсем техническими вещами занимаюсь, больше управлением людьми. А это (технические вещи) на самом деле моё хобби. Я эту тему немного разовью.
Проблемы мониторинга
Считаю, что мне повезло. Примерно полтора года назад я оказался в проекте, который звучал так: «Нужно решить некоторые проблемы с нашим мониторингом». Я получил в наследство зону ответственности (мониторинг), которая состояла из кучи серверов, конкретно – из 21 сервера:

Было 4 мощных сервера и 15 прокси – это всё было аппаратным. К этому мониторингу имелись некоторые претензии. Первая – то, что это было много. У нас ни один сервер у провайдера не занимал столько места. Это деньги, электричество… На самом деле это не большая проблема.

Большая проблема заключалась в том, что мониторинг не успевал за тем, сколько мы от него хотели. Для тех, кто активно «Заббиксом» не пользовался – это дашборд, который показывает опоздание по проверкам:

У нас большинство проверок сидело в красной зоне. Они выполнялись более чем на 10 минут медленнее, чем нам хотелось, то есть опаздывали на 10 минут. Это было не очень приятно, но жить ещё более-менее можно было. Самая большая проблема была эта:

Это была система мониторинга исправно работающей сети. Когда выполнялись плановые работы, отваливался сегмент тысяч на пять коммутаторов. Вместе с этими коммутаторами в небытие уходил коммутатор. Когда всё восстанавливалось, часа через два и мониторинг восстанавливался. Это было больно неприятно, и эта фраза должна быть в каждом докладе:

«Надо с этим проектом что-то делать»!
И здесь я две истории расскажу. Тогда мы попробовали пойти одновременно двумя путями. У нас есть группа интеграции – она избрала путь построения модульной системы (был очень классный доклад от «Авито» на «Хайлоад» в ноябре прошлого года в Москве – они примерно про это рассказывали):

Zabbix = люди + API + эффективность
Ребята из маленьких кусочков стали строить систему. А я с несколькими энтузиастами продолжил заниматься «Заббиксом». Были на то причины. Какие причины?
- Во-первых, есть классный API. И когда у тебя есть 60-70 тысяч элементов мониторинга, понятно, что это всё работает только автоматически – руками без ошибок столько не добавить.
- Кадры. Есть дежурные смены мониторинга, которые сидят 24/7. Это не айтишники, это дежурные люди. Мы показывали «Графану», какие-то другие системы – им тяжело. Есть админы, которые привыкли к разнообразию, удобству мониторинга в самом «Заббиксе»: шаблоны, автообнаружение – и всё клёво!
- «Заббикс» может быть эффективным.
База SQL тормозит? Ответ один – Clickhouse
Первая причина была очевидная. Мы тогда работали на MySQL, и мы упирались примерно в 6-7 тысяч метрик в секунду, видели постоянные задержки на дисках.

Сегодня это уже звучало 100 раз: ответ один – Clickhouse:
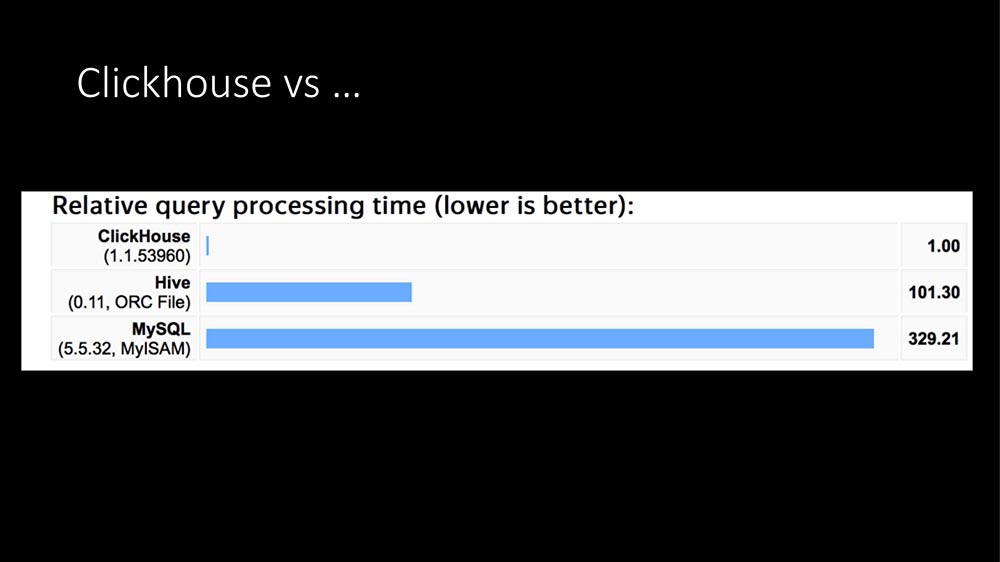
В структуре запросов основную часть запросов (наш профайлинг за несколько часов) составляет запись метрик. Писать метрики в SQL-базу крайне дорого. Вот TimeScaleDB появился… Тогда у нас в эксплуатации «Кликхаус» был примерно год под другие задачи (мы занимаемся big data, у нас большое приложение – в общем, провайдер – это сейчас целый IT-бизнес).
Посмотрев красивые графики из интернета (что «Кликхаус» в сотни раз быстрее, что ему надо очень мало места) и имея текущий опыт, мы написали свой HistoryStorage-модуль для «Заббикса», чтобы он мог сохранять данные «Кликхауса» напрямую (то есть не из экспорта файлов, а прям на лету).

Более того, мы написали модуль для «фронта». Все эти красивые графики в админке «Заббикса» могут строиться из «Кликхауса». Понятно, что API тоже работает.
Эффект примерно такой — SQL-сервера как выделенной сущности не стало совсем, то есть загрузка упала в ноль. Что самое примечательное, у нас был уже выделенный «Кликхаус»-кластер: когда мы туда дали всю нашу нагрузку, она увеличилась с 6 до 10 тысяч метрик. Ребята, которые администрированием занимаются, сказали: «А мы что-то не видим, что пришло. Нету»!
Как мы Clickhouse расширяли
Я скажу даже дальше: для тестов мы пробовали подавать нагрузки до 140-150 тысяч метрик в секунду (больше не смогли из «Заббикса» выжать, позже скажу почему), и этой нагрузки «Кликхаус» тоже не видит. То есть это очень комфортная, классная нагрузка. В общем, есть такой модуль.
Кроме того мы его немного расширили:

В нашей версии можно выключить наносекунды. Вы наверняка знаете: «Заббикс» пишет секунды и наносекунды двумя полями. В «Кликхаусе» поля, в которых вариативность очень большая, занимают много места.
Кстати, про место. Одна метрика в «Кликхаусе» (сейчас у нас примерно 700 миллиардов метрик записано) занимает 2,9 байта. По документации «Заббикса» одна метрика в SQL-базах занимает от 40 до 100 байтов. Выключение наносекунд даёт экономию ещё 40%, то есть примерно 1,5 байта на метрику. То есть «Кликхаус» очень эффективен с точки зрения места.
По просьбе наших ребят, которые занимаются машинным обучением, мы сделали опцию, чтобы можно было писать хост и имя метрики. Так как вариативность данных большая, это занимает не много дополнительного места, несмотря на то, что текстовые данные могут быть значительные (долгими тестами это не проверили ещё).
Плюс, сделали два дополнения, так как мы девелопили «Заббикс» и его приходилось часто дёргать. Очень прикольное дополнение: на старте, поскольку «Кликхаус» позволяет читать миллионы записей, мы можем заполнить кэш истории. Мы на старте задерживаемся на лишние 30-40 секунд, зато получаем сразу запущенный сервис с прогретым кэшем.
В случаях, когда проще с инфраструктуры собрать, есть ещё такая опция: запретить чтение из кэша на какое-то время. Лучше 5 минут быстро поработать не считая триггеры, а потом кэш наполнится – если этого не делать, начинается стагнация хистори-синкеров.
В общем, есть модуль «Кликхауса». Его можно использовать.
Эффективность поллинга
Несмотря на то, что мы решили тогда проблемы с базой, тормоза и проблема с пятнадцатью прокси всё равно осталась. Связаны они были вот с чем:

Это основной pipeline обработки данных в «Заббиксе». Есть этап сбора данных, есть препроцессинг и есть хистори-синкеры, которые делают всю работу (обсчёт триггеров, алертинг, сохранение history). Самое узкое место оказалось в кэш-конфигурации:

Почему тормозит polling? Потому что треды, которые делают запросы, за единичными метриками ходят в очередь в кэш-конфигурации, и его блокируют. Есть другие места, но они не такие узкие. Например, есть сам препроцессинг и есть History Cache. На нашем SQL мы получили такие примерно ограничения:

Возможно, это связано с тем, что в нашем случае база составляет примерно 5 миллионов метрик, которые мы снимаем. Со всем оптимизациями, которые делали, мы смогли получить 70 тысяч метрик в самом узком месте (на Configuration Cache), но только в случае, когда мы их обрабатывали массово.
Что такое массовая обработка? Poller идёт в Configuration Cache и берёт задание не на одну метрику, а на 4 или 8 тысяч. При этом он получает ещё одну замечательную возможность: он может теперь делать поллинг асинхронно, потому что он получил 4 тысячи метрик… Зачем их делать одна за другой делать? Можно сразу все спросить!
Асинхронный поллинг эффективнее, чем прокси!
Для основных типов, которые, используются провайдером – это SNMP и AGENT, мы переписали поллинг на асинхронный режим, и агрегативно это дало примерно прирост скорости от 100 до 200 раз. У нас было 15 прокси, мы их разделили на 150 – их не осталось совсем. В итоге это всё превратилось в две банки, которые только для резерва нужны:

Однопроцессорная банка (один Xeon 1280 стоит). Это I dle time:

Примерно 60% свободно, а вот этот звон от 60% до 40% – запускаемые периодические скрипты на самой машине (external scripts). Их можно оптимизировать, пока проблем не создают.
Scale примерно такой:

Это 62 тысячи хостов, около 5 миллионов метрик. Текущая наша потребность – примерно 20 тысяч метрик в секунду.
Ну что, вроде всё? Проблемы с производительностью решили, History расширили, Polling у нас классный. Проблема решена? Не совсем… Всё было бы слишком просто.
Я немного слукавил на предыдущем графике (не весь показал):

Есть две проблемы. Хочется сказать: «Дураки, дороги». Есть человеческий фактор, есть оборудование.
Одного сервера всё-таки мало. Примерно за год эксплуатации было два случая с аппаратными проблемами – SSD-диск и что-то ещё. Большую часть проблем составляет человеческий фактор, когда люди делают какие-то проверки. У нас в компании «Заббикс» используется как сервис: все подразделения могут там что-то своё писать.
Хотелось бы расширения. Хотелось бы не зависеть от одной банки. Хотелось, чтобы мы могли скейлиться ещё сильнее. И причём хотелось бы скейлиться по принципу Scale-out. Тут даже обсуждать нечего: расти, повышая мощность одной банки, уже 20 лет как не актуально.

Просился кластер…
Где-то в декабре появилась первая версия. Атомарная единица кластера – то, что обрабатывается на отдельном хосте. Был выбран хост.

Дело в том, что в «Заббиксе» есть достаточно сильные связи между item’ами, которые могут быть на одном хосте, т. е. могут быть связаны триггеры, они могут в препроцессинге вместе обрабатываться. А вот между хостами связанность уже не такая высокая, поэтому нормально для того, чтобы эту связанность сделать, использовать между нодами их кластера – много трафика там не будет. Основная задача кластеров – это договориться между собой, кто какими хостами занимается.
Хотелось бы обойти наш максимальный лимит в 60-70 тысяч метрик, потому что аппетит приходит во время еды. У нас есть ребята, которые занимаются QoE… Quality of Experience – анализ того, как интернет работает у абонентов на основе транзитных метрик, т. е. поставляете все TCP-метрики 1,5 миллионам человек, лить в мониторинг – там много данных.
И хотелось надёжности. Хотелось, чтобы, если что-то случилось… Позвонил дежурный смены, сказал – «У нас проблемы с сервером», – выключил его, завтра разберёмся.
Первый кластер
Первая версия была реализована на основе etcd:

Etcd – это распределённое key-value-хранилище, используется во многих прогрессивных проектах (насколько я понимаю, в Kubernetes). Всё было классно. Etcd даёт очень интересные инструменты – например, решает проблему выбора основного сервера. Но такая проблемка…
У нас была классическая трёхземка «Заббикса»: «веба» – база – сам сервер. А мы добавили туда ещё и «Кликхаус», а теперь ещё и etcd добавили. Админы стали чесать за головой: что-то многовато здесь зависимостей – наверное, будет не надёжно. В процессе развития выяснилась ещё одна вещь: в самом «Заббиксе» есть уже встроенный способ межсерверной коммуникации, просто он используется между сервером и прокси, так называемый процесс proxy poller:

Он вполне классно подходит для межсерверной коммуникации с минимальными изменениями. Это позволило etcd не использовать (по крайней мере, временно), очень сильно упростить код, а самое главное, работать на коде, который выверен (кажется, лет 5 или 7 этому коду).
Как серверы координируются в кластере?
Координация сделана по типу вроде IGP-протокола. Для того чтобы серверы могли иметь приоритет (сейчас скажу, зачем это надо) и для того чтобы можно было избавить от конфликтов в SQL-базе при записи логов, каждому серверу присваивается идентификатор (пока вручную) – это число от 0 до 63 (63 – это просто константа, может быть больше):

Сервер с максимальным идентификатором становится «мастером». Когда мы запустили у себя первые тест-кластеры, первое, что сказали наши админы: «Вау! А давайте мы их на разных площадках поставим. Ну, здорово же!» (к этому ещё вернёмся). И когда у кого-либо появятся распределённые кластеры, можно будет управлять тем, как будет перераспределяться топология: куда будет уходить роль «мастера» в случае падения основного «Заббикс»-сервера:

В данном случае вот так:

Степпинг
В оригинальном «Заббиксе» это сделано так: генерацией автоинкрементных индексов занимается сам сервер. Чтобы много instance’ов друг другу не наступали на пятки (чтобы не создавали логи с одинаковыми индексами), используется степпинг: «Заббикс» с идентификатором «1» будет генерировать кратные единице – 1, 11, 21; с идентификатором «7» – 7, 17, 27 (с нюансами).
С модификаторами проехали.

Как взаимодействуют серверы между собой?
Это наследие IGP – «привет»-пакеты (Hello) каждые 5 секунд. Так серверы знают, что у них есть соседи. Так «мастер» знает, что есть соседи рядом, и на основе этого «мастер» решает, каким серверам какие хосты можно раздать.

Соответственно, есть конфигурация. По старой памяти я её называю топологией. Топология – это по сути список серверов и хостов, которые к ним относятся.
Протокол простой – это JSON:

Это тоже наследие коммуникации «Заббикс»-прокси и «Заббикс»-сервера. В общем, нет смысла использовать что-то другое. Единственное, что в случае «Заббикса» там есть 4 байта (ZBXD), но это не суть важно.
В hello-пакете передаётся идентификатор сервера: когда сервер посылает пакет, он говорит свой идентификатор и свою версию топологии – таким образом серверы быстро узнают, что есть новая версия топологии и очень быстро обновляются.
Собственно, сама топология – это просто дерево, список серверов. Для каждого сервера – список хостов, которые он поддерживает:

А дальше возникает интересная проблема.
Есть такая магическая фраза – домены мониторинга
В чём суть? В классическом «Заббиксе» у нас всё было просто – однозначное отношение: этот хост мониторится этим прокси, этот прокси даёт данные серверу. Если прокси не был установлен (или не нужен), то этот сервер мониторил все хосты:

Когда у нас много серверов, что делать? Тем более может быть проблема с тем, что у нас географически распределённые серверы, и сервер в каком-нибудь медленно работающем офисе в Кемерове начнёт пытаться мониторить всю инфраструктуру Новосибирска.

Мы этого не хотим. Мы хотим иметь некий механизм, чтобы не все серверы, а выбранные нами (возможно, по географическому признаку) могли мониторить какой-то конкретный хост. При этом мы хотим управлять этим, и хотим, чтобы это было просто. Для этого была придумана идея доменов мониторинга. По сути это простые группы – просто в записи уже есть группы.
И когда я это делал, мы с ребятами из эксплуатации разговаривали – они сказали: «Группы нас путают очень сильно. Мы всегда начинаем думать про нормальные группы». Поэтому такое название: домены мониторинга.
Хосты однозначно относятся: один хост – один домен:

В домен хост может входить любое количество серверов. Серверы могут входить в любое количество доменов. Это весьма гибкая штука. Чтобы гибкость можно было расширить и совсем сломать мозг, есть ещё домен по умолчанию:

Серверы, которые входят в домен default, мониторят все хосты, у которых не осталось живых серверов, либо которым не присвоен домен мониторинга.
Это как раз позволяет топологически нормально привязывать хосты к каким-то серверам и управлять тем, как распределятся хосты в случае, если один сервер у нас упадёт:

Следующая проблема, с которой мы столкнулись…
Кластер: Think Different
Когда у нас появляется много серверов, появляются новые возможности по построению кластера, по построению топологии. Это такая классика, когда у нас есть какой-то центральный сайт и есть удалённые; или, допустим, прокси, куда делегирована нагрузка:

В случае кластерного «Заббикса» может реализовываться двояко. Можно пойти классическим путём: просто удвоить инфраструктуру. В центре у нас два сервера, которые образуют кластер, могут переставлять хосты или брать нагрузку на себя, если сосед упал. Соответственно, можно поднять дополнительные прокси на тех же серверах – получим двойной резерв:

Можно воспользоваться новыми «фичами» и сделать так:

Главное, не перейти к ситуации, когда географически удалённый сервер мониторит какую-то большую инфраструктуру в другом месте. Это больше вопрос администрирования (я его называю «бизнесовый»), потому что это вопрос настройки.
Кластер: split brain и point of view
С кластером пришла ещё одна интересная ситуация, с которой мы столкнулись:
- split brain;
- point of view (точка съёма).
Они немного пересекаются. Split brain – это когда у вас есть два сервера, которые отвечают за поллинг одной и той же инфраструктуры. Когда у нас развалилась связь, началась какая-то авария – как они будут себя вести? Понятно, что они будут себя вести так, как вы их настроите и об этом тоже нужно заранее подумать (сценарии разные).
Проблема point of view примерно такая: проверки, которые зависят от топологической удалённости серверов, могут давать разные результаты для одного и того же хоста, потому что они далеко. Это касается проверок скорости доступа. Допустим, если вы RTT замеряете, оно разное может быть.
С точки зрения техники сделали такие макросы:

Они работают на уровне элементов данных, на уровне триггеров. Они позволяют идентифицировать, откуда эти данные, и какой из серверов являлся инициатором триггера. А как интерпретировать данные, что делать – это решайте сами. Но когда вы знаете, какой сервер зафиксировал падение доступности до хоста, вы знаете, что делать.
Кластер SQL-базы
Очевидно, если мы разнесли кучу серверов, то мы бы хотели, чтобы у каждого была рядом своя база. Неправильно было бы завязывать на одной общей. К сожалению, сказать, что у меня есть сейчас готовое решение… У меня пока такого опыта нет. Я сейчас расскажу почему.
Во-первых, я предполагаю, что, если кто-то начнёт тестировать и пользоваться кластером – можно использовать стандартные решения. Допустим, Galera для MySQL.
Есть куча решений для асинхронной репликации для PostgreSQL. В случае с «Заббиксом» это работает нормально: индексы пересекаться не будут, а от того, что данные немного опоздают в логи и запишутся чуть позже – это не проблема. «Кликхаус», понятно, может быть кластеризован априори.
Почему нет готового решения?
Из общей структуры запросов есть такая маленькая часть, которая не касается истории:


Из этой маленькой части подавляющее большинство запросов у нас сейчас – это логи. Логи в основном формируют три таблицы:
- Логирование каких-то вещей (Logs), которые случились с инфраструктурой. Это таблицы problems, events и events recovery. Сервер упал, сервер восстановился – когда срабатывают триггеры, это всё пишется.
- Процентов 15 составляет состояние (State). Состояние – это изменение элементов инфраструктуры (сервер или хост упал – триггер сработал – «Заббикс» записывает в базу). По сути он хранит своё состояние в базе. С одной стороны, это здорово; с другой – у меня есть что сказать на эту тему…
- Совсем чуть-чуть запросов касается загрузки и изменения конфигурации (Configuration update).
Вот классический «Заббикс. В него добавили «Кликхаус», вынесли метрики из SQL-базы:

Во-первых, хотелось бы за состоянием ходить в сервер:

Это правильно. Если вы уроните сервер и через два часа откроете веб-админку, он вам покажет, какое состояние мониторинга… Это будет неправдой – он покажет то, что было 2 часа назад! Правильно было бы сказать: «Я не знаю, какое сейчас состояние сети». Если что-то конкретное интересует, можно посмотреть по истории проблем или ивентов, что там реально было.
Второе. Логи просятся вынести их в более дешёвую систему хранения, которая занимает существенно меньшее пространство на диске и меньше тратит ресурсов:

Потом можно подумать, что делать. От SQL-базы хочется на самом деле избавиться. Сначала хотелось бы вынести состояние, логи вне SQL-базы. То ли она будет легко реплицирована (потому что изменений очень-очень мало останется), то ли её можно будет перетащить в «Кликхаус» (вдруг он начнёт поддерживать полноценное изменение и удаление данных). Посмотрим…
Практика. Установка
Кластер, теорию, «воду» я рассказал. Конкретика. Если вы решили поставить кластер у себя, что надо делать?

Нужно поставить второй «Заббикс»-сервер (т. е. именно «сишный» daemon). Для кластера появляется два новых параметра (я про них рассказал): идентификатор сервера (число от 1 до 63, сервер с наивысшим идентификатором становится «мастером») и имя хоста (нужно для самоидентификации сервера, когда он загрузит список серверов из базы).
Для каждого сервера нужно указать ServerIP и IP-порт. Это нужно для того, чтобы серверы могли находить друг друга, и трафик между этими IP-адресами портами должен работать. Каких-то дополнительных портов не требуется, так как у нас работает всё через стандартный proxy poller, то есть стандартный trapper ловит hello-запросы, а proxy poller инициирует трафик.
Дальше небольшие изменения. Там, где раньше у нас было управление прокси, теперь появилась панелька «Управление кластером»:

Там появилось некоторое количество новых объектов:

Самое главное, нужно туда зайти и создать домен default. Я говорю о минимальной конфигурации для теста. Второе – завести оба сервера, записать туда те самые IP-адреса, порты и имена хостов, которые вы задали в конфигурации (они должны совпадать). У сервера есть новое поле «Домен» – выбрать этот default.
В общем-то, всё.
- Запустите один сервер.
- Посмотрите, что он пишет по поводу кластера: «Я один в поле воин, я тут самый главный». Начнёт заниматься мониторингом.
- Подождите какое-то время, запустите второй сервер.
- Они сначала друг друга увидят, потом пройдёт некий hello-time, они скажут: «Мы можем работать вместе»; поделят хосты между собой.
- Наслаждайтесь работой.
Думаю, стоит поравнять серверы, посмотреть, как это работает. В наших тестах время отсутствия мониторинга в случае падения одного из серверов составляет примерно 30-40 секунд. Это можно уменьшить, но тогда страдает коммуникация между серверами, особенно если сеть ненадёжная, начинается небольшой звон.
Не техническая часть
Это всё родилось и планировалось в виде патчей пропихнуть в основную ветку, но по разным причинам не пошло. И с апреля этого года кто-то из комьюнити подсказал: «А давайте это сделаем форком, отдельным проектом!» И пошло-поехало!

И тут – интересная вещь: появилось какое-то количество энтузиастов, которые что-то делают, пилят, настраивают GitLab, CI/CD, приносят классные идеи. Вот, допустим, наносекунды – это из комьюнити пришло.
В общем, пока оно живёт как отдельный проект, обновляется практически автоматически до актуальной версии – на 4.9 находится (4.2 мы не брали). Есть некий Roadmap – сейчас это уже можно скачивать в виде дебиан-пакетов. По-моему, есть сборки для «Убунты»; я не знаю, есть ли RPM’ы.

Скоро будет полноценная поддержка прокси (там есть некоторые заминки) и «тулинг» для текущего просмотра состояния кластера в «Заббикс»-панели. По нашему опыту. Админам важно знать на каком сервере какой хост обрабатывается, чтобы начинать искать проблемы. Система новая – чисто психологический фактор: мы поставили кластер, что-то работает не так… Кто виноват? Кластер!.. Поэтому нужен «тулинг», нужно понимать.
До конца лета хотелось бы вытащить из SQL-базы все информационные потоки, которые там не нужны, не обязаны быть. History Storage.
Ссылки
У меня ещё есть 5 минут. Хотел бы свои запасные темы обсудить.
Во-первых, всё, что я рассказывал, классно ложится в идеологию активного мониторинга, т. е. когда сервер ходит за проверками куда-то.

Активный и пассивный поллинг
Что, если у вас пассивный мониторинг? У нас достаточно много такого! Есть проверки, которые, допустим, долго считать. Или когда какие-то специфические скрипты куда-то ходят, готовят данные и потом их нужно отправить на сервер. Понятно, что такие скрипты не могут знать всей структуры кластера, а делегировать им всю базу никто не будет. Для этого сделан в кластере такой механизм, чтобы переживать такие вещи:

Есть серверы. «Мастер»-сервер решил, какие хосты на каком сервере обрабатываются.
- Так вот в случае, если хост шлёт принудительно данные не на свой сервер, то этот сервер данные принимает, обрабатывает.
- В стандартном «Заббиксе» есть проверка: он убеждается, что эти метрики действительно присутствуют в Configuration Cache, проверяет их тип.
- Если всё окей, он эти данные уже в подготовленном виде пересылает на тот сервер, которым они должны быть получены. Так как все серверы полную информацию о том, где какие хосты обрабатываются, это делается напрямую.
- На финальном сервере-адресате это обрабатывается уже быстро, без дополнительных проверок. Тем не менее к распределению того, куда какие проверки приходят, нужно с умом относиться. Если попытаться лить 200 тысяч метрик на один сервер, он просто не справится – в блокировках погибнет.
Активные прокси
Ремарка: пассивный прокси не поддерживается пока!
Я убрал код. Это связано с тем, что тяжело для людей сделать ещё один механизм, какой из серверов ещё будет за этот прокси отвечать.
Активные прокси сами ходят на серверы. Для этого есть опция Server (стандартный прокси). В изменённом прокси есть опция Servers:

И что делает такой изменённый сервер? Он держит KPI-соединение со всеми серверами, которые для него указаны; спрашивает конфигурацию, шлёт данные на первый доступный сервер из списка. Это позволяет решить проблему. Допустим, если у вас прокси, настроенный на «Заббикс»-сервер, и «Заббикс»-сервер упал – в кластере есть другой, чтобы не оставаться без прокси; тогда прокси просто к другому прицепится.
Вопросы
Вопрос из аудитории (далее – А): – Хотел бы уточнить, как обстоят дела в связи между серверами? По какому протоколу общаются? Есть ли какая-то защищённость? Потому что в интернет выводить коммуникацию между серверами не особо «секьюрно»… Как это дело происходит?
ММ: – Думаю, это претендент на лучший вопрос – в точку! На самом деле, когда мы перешли к стандартной коммуникации, серверы для своей межсерверной коммуникации унаследовали все те фишки протокола коммуникации, которые есть между сервером и прокси. Я уточню: там есть шифрование, сжатие данных. Пожалуйста – так же через вебы всё настраивается, как это стандартно настраивается для сервера и прокси; всё будет работать.
А: – Как у вас «Хаускипер» работает в случае с «Кликхаусом»?
ММ: – В стандартном «Заббиксе» нет интерфейса из «Хаускипера» в History Interface, то есть History Interface не поддерживает ротацию данных (ElasticSearch, допустим, не поддерживает). Может, в 4.2 это есть (я не смотрел), но пока на 4.0.9.
Сделать легко! В новом «Кликхаусе» есть партиционирование. Хочется сделать путём отцепления устаревших партиций. Понятно, что на уровне отдельных item’ов ротации не будет, но в «Заббиксе» есть фишка: можно указать глобальные значения (допустим, всю историю хранить не более 90 дней) – по этом глобальным значениям чистить можно все item’ы, всю историю. И это будет сделано! Есть на «Гитлабе» ещё на эту тему.
Нам хочется архитектурно правильно сделать: то ли History Interface расширить, чтобы это в принципе было… В общем, не хочется оставлять технического долга, но сделано будет. Потому что это надо, тем более «Кликхаус» стал поддерживать.
А: – Как у вас со стороны к этому относятся? Вы, получается, довольно объёмную не провайдерскую работу проворачиваете.
ММ: – Я, наверное, не очень правильно выразился. Это хобби моё! Я на самом деле не технический специалист – я менеджер. В свободное время занимаюсь.
А: – Думал, вы в рамках основной деятельности это делаете…
ММ: – Бизнес даёт мне классную площадку для тестов. На самом деле я очень рекомендую – разгружает мозг. Я бы где-нибудь на менеджерской «штуке» рассказал бы это – когда можно переключиться с людских проблем на эти. Они так классно решаются! Это технические проблемы. Ты спрограммировал, и оно работает так, как ты спрограммировал! Людей, жалко, так нельзя делать.
А: – Вы пишите в «Кликхаус» через какой-то прокси или напрямую?
ММ: – Напрямую. На самом деле унаследован тоже видоизменённый History Interface, который используется для «Эластикса». Используется url, то есть через http-интерфейс «Заббикс» шлёт «Кликхаусу». Что классно, «Заббикс» агрегирует, когда идёт большой поток истории, тысячи метрик в одну пачку, и это очень классно ложится на «Кликхаус».
А: – По сути, он сам за него бачи пишет?
ММ: – Да. Один SQL-запрос, который выполняется url’ом, типично содержит в себе тысячу метрик. Админы «Кликхауса» просто счастливы.
Ведущий: – На этом программа в этом зале окончено. Есть вечерняя программа, которая организована, и есть то, что можете сделать только вы. И я предлагаю, в то время как вы будете общаться друг с другом, подумать о том, что же интересного можете вы… Когда вы рассказываете друг другу про свои случаи, это, скорее всего, то, о чём вы можете сделать доклад. Друг с другом обсуждая, вы можете найти как раз найти какую-то канву – программный комитет примет вашу заявку, рассмотрит и поможет сделать из этого хороший, упакованный рассказ. Может, у тебя есть какой-то рассказ о работе с программным комитетом?
ММ: – На самом деле фидбека много даётся. Мне так повезло: человек из программного комитета живёт в моём Челябинске, и «Хайлоад» – единственная конференция, которая так плотно работает с докладчиками. Я нигде такого больше не встречал. Это очень на пользу идёт! Разные этапы: ребята отсматривают видео, дают комментарии по слайдам – очень в тему бывает (орфография, описки). Очень здорово! Я рекомендую! Попробуйте себя!
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас:Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Комментариев нет:
Отправить комментарий