На пороге создания нового проекта
Давайте притворимся, что бизнесу, который рулит нашей маленькой, но гордой командой разработчиков, потребовалось сделать что-то новое. Мы довольно умны (и набили достаточно шишек), чтобы не изобретать велосипеды, поэтому мы начинаем с глубокого погружения в интернет, в поисках того, что было давно и успешно сделано по аналогичным требованиям нашими коллегами. Внезапно оказывается, что существующие решения описаны поверхностно, расплывчато и противоречиво.

Интернет предоставляет к нашим услугам невообразимое количество текста, в пропорции толерантного Парето (примерно 50 на 50), рассказывающего как про истории успеха, так и о радикальных неудачах. Некоторые выступают за использование фреймфорка Foo и архитектуры Bar, в то время как другие гарантируют, что только Baz поверх Boo (и полный отказ от Foo любой ценой) могут помочь в достижении цели. Чтобы хоть как-то справиться с такими объемами рекомендаций, мы отбрасываем новости из источников, о которых никогда не слышали, и в конечном итоге получаем некоторое количество советов, исходящих от доверенных людей. Чтобы стать таковым, нужно либо написать десяток-другой книг и создать пару курсов, либо просто долго расти и превратиться в монстра «too big to fail». Как, например, Goozone Hawk Co., которые попросту не могут ошибаться.
Это — в чистом виде давление авторитетом, предвзятость оценки на основе титула источника. Кипеж вокруг, который иногда еще называют «бурлением талой воды», мгновенно распространяет как правильные, так и спорные, и просто вредные идеи — одинаково быстро. Мне невдомек, почему вдруг этот седовласый старик с окладистой бородой — вдруг не может ошибиться. С какой вообще стати? Мне хотелось бы иметь мое собственное мнение.
Дайте мне точку опоры и я переверну рычаг
С некоторых пор я совершаю первый подход к каждой новой проблеме — с написания собственного кода. Ну, к почти каждой новой проблеме. Я не собираюсь переписывать операционную систему, сервер баз данных, или диспетчер контейнеров. Но если это все выглядит, как задача на недельку, и крякает, как задача на недельку, я снова и снова буду входить в эту реку.
Что нам нужно реализовать на этот раз? Сложную система мониторинга, чтобы лишний раз доказать нашу декларируемую совместимость с принципом девяти девяток.
Наш миссия — разработка критически важной платформы. Нет, я понимаю, что каждый бизнес считает свою платформу (и миссию) критически важной, но здесь, в Fintech, это по-настоящему так. Вспоминается одно выступление на конференции о высоконагруженной системе (от компании, которая действительно обслуживает догазиллион запросов в секунду), во время которого докладчик с гордостью упомянул, что они некорректно обрабатывают менее, чем один запрос pro mille. И это — довольно крутой результат. Но в нашем случае — допустимое количество некорректно обработанных запросов — ровно ноль.
Кроме того, мы имеем дело со многими сторонними сервисами, что делает нас уязвимыми для сбоев, вызванных непредсказуемыми и, в целом, не очень-то адекватными источниками. Одна «транзакция» может длиться несколько часов, так как она требует одобрения стапятисот внешних «процессуально-исполнительных органов» перед реальным выполнением. Мы своего рода эксперты в переговорах на машинных языках: со всеми этими министерствами правды общается наш код.
Я мог бы продолжить этот список еще на три экрана, не ограничиваясь следующими пунктами:
- возможность необходимости ручного вмешательства в экстренных случаях на каждом этапе;
- параллельность исполнения почти всех процессов;
- обработка кучи высоконагруженных очередей фактических данных из посторонних источников;
- возможность откатить любое действие;;
- необходимость аудита каждого отдельного шага как внутри компании, так всего происходящего в сторонних сервисах (насколько возможно);
- управление всем этим зоопарком, чтобы всегда быть уверенными в парадигме «утром стулья — вечером деньги».
Очевидно, что у нас повсюду есть мониторинг, тут и вон там, и я уверен, что большинство интернет-компаний в других областях будут считать нашу систему отслеживания неполадок — пуленепробиваемой. Но мы не можем просто слепо полагаться на то, что единороги и розовые феи удачи защищают нас от любого зла.
Ладно. Нам нужна точка опоры и запрос, чтобы мы могли перевернуть интернет. Какой же путь выбрать, чтобы сделать нашу платформу еще безопаснее. К сожалению, это проще сказать, чем сделать. И тут я предался своему греху. Я нырнул, чтобы…
Изобрести велосипед
На данный момент

Все сервисы, показанные слева — работают в облаке, все запускают по несколько экземпляров параллельно, некоторые — в кластере, остальные — архитектурные синглетоны. Вообще, этот проект родился из идеи «давайте улучшим мониторинг», но быстро превратился в «мы могли бы построить журнал событий, который отслеживал бы все изменения и обеспечивал откат до боеспособного состояния в случае сбоев».
Парный мониторинг
Помните свою первую сессию парного программирования, и собственное удивление от того, насколько это может быть продуктивнее кататонии перед пустым экраном в отсутствии мыслей, что делать дальше? Это было удивительное чувство, не так ли? Именно это воспоминание подарило мне мысль внедрить парный мониторинг. То есть, такую открытую систему дружеского обмена информацией, когда не только инфраструктура проверяет здоровье контейнеров, а полицейские приложения — состояние остальных приложений и адеватность их операций с точки зрения бизнес-логики. Нет, они должны играть в команде, делясь проблемами друг с другом.
Скажи транзакциям «нет»
Транзакций быть не должно. Мы будем поддерживать только атомарные операции. Транзакции на уровне приложения — абсолютное зло. Каждый откат транзакции на уровне приложения — неизбежно представляет из себя заново написанную, неспецифицированную, глючную и медленную реализацию половины движка СУБД, а мы договорились избегать переизобретения монстров.
Тотальная слежка
Несмотря на существование долгоживущих «транзакционных» операций в нашей среде, мы обнаружили, что можем разделить все на атомарные действия, управляемые конечными автоматами. Вместо того, чтобы запускать транзакцию, включающую изменения нескольких различных объектов, мы вводим другой объект, который играет роль транзакционного конечного автомата. В течение жизненного цикла этого объекта все оригинальные базовые объекты помечаются как находящиеся в транзакции. Как только этот объект достигает конечного состояния, все изменения применяются к дочерним контролируемым объектам — одновременно, создавая несколько строк в журнале событий, по одной на атомарное действие. Таким образом, у нас всегда есть возможность откатить что-либо впоследствии.
Кроме того, да, есть некоторые действия, которые не могут быть откачены по-человечески (например, фактический перевод денег). Мы четко обозначаем их в журнале событий и для каждого из таких действий вводим объект «откат» (ха-ха), который выполняет действие, имитирующее откат в реальной жизни (например, переводит то же самое количество назад для надуманного примера выше).
Дирижер, или хореография?
Эти два термина (Orchestration и Choreography) появились в англоязычном интернете не так давно, и обычно подходы упоминаются как взаимоисключающие. Мы обнаружили, что это совсем не так. Можно было бы инкапсулировать части всей системы в соответствии с SRP в дирижируемых внутри коллективах, которые вместе прекрасно играют по нотам событий, и наоборот.
Мы также должны быть в состоянии расставить границы на воображаемой диаграмме, представляющей нашу архитектуру с высоты птичьего полета. Больше всего это похоже на политическую карту мира. Границы не могут пересекаться. Государства в пределах границ несут ответственность за правила внутри государства. Они буквально имеют свои собственные правительства, законы, все, что угодно. Координация действий внутри одной страны может осуществляться в соответствии с требованиями законов государств; связь между различными государствами осуществляется по дипломатической почте; угу, спасибо, Алан Кей и Джо Армстронг!— передачей сообщений.
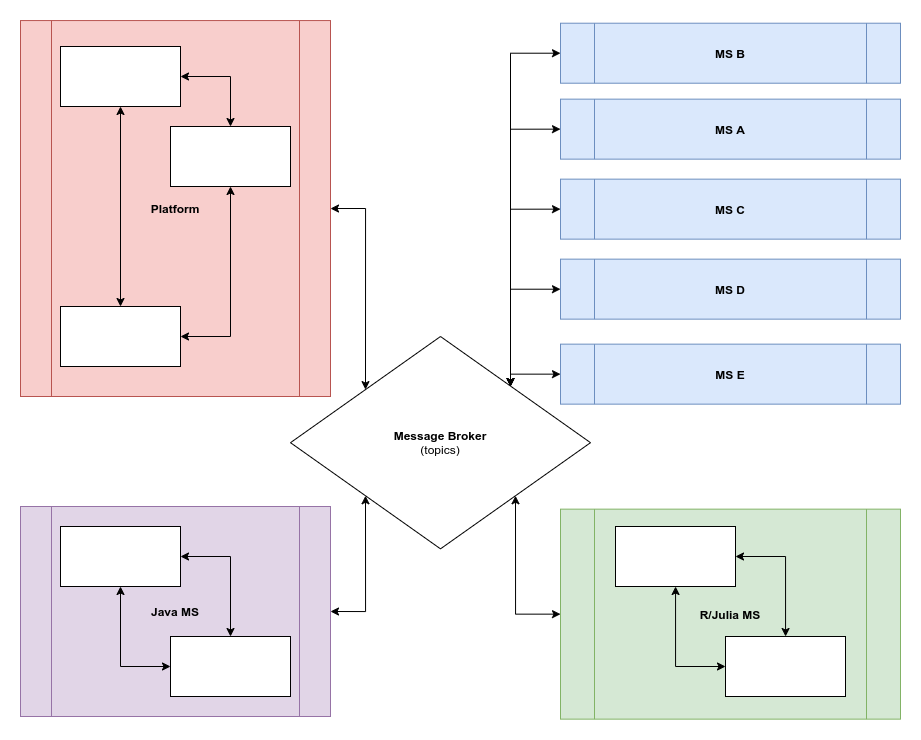
У всех без исключения сообщений есть «темы»; кто угодно, заинтересованный в данной теме, должен явно подписаться на нее (привет, вебсокеты). Если в кластере выполняется несколько экземпляров одной и той же службы, они должны сами решить, как обрабатывать и обмениваться поступающими сообщениями между узлами (самая простая и надежная реализация будет, скорее всего, основана на каком-нибудь аналоге hashring).
Вот тут распишитесь
Все сообщения должны оповестить систему об успешной (или неуспешной) обработке. Получатель подтверждения не обязан быть тем, кто отправлял исходное сообщение. Журнал событий (который подписан на все) — отслеживает все запросы и отвечает за оповещения соответствующих служб в случае, если что-то пошло не так.
Воспроизведение и перемотка
Журналы событий используются для воспроизведения сценариев сбоя (или просто подозрительных). Еще они могут использоваться для пересмотра и анализа сбоев в staging. Полная реализация адекватного журнала событий — довольно сложна, и мы не собираемся реализовывать ее прямо сейчас, но вся архитектура построена с учетом этой способности.
Хаос разработки
Chaos Engineering — тоже довольно молодой термин. Вся система постоянно подвергается перекрестному огню при помощи отправки неожиданных и поврежденных сообщений, подключением и отключением экземпляров служб, имитацией сетевых разделений и сбоев удаленных сервисов. Эта методология позволяет обнаруживать проблемные места и реагировать на сбои сейчас, а не когда он будет вызван клиентским запросом в три часа ночи в субботу.
Ну вот; это составляет начальный перечень требований, который будет постоянно расширяться и обновляться со временем.
Стоя на плечах гигантов
Я должен сказать, что в подавляющем большинстве случаев велосипеды, изобретенные мной на этапе анализа проблемы, рождались угловатыми, хрупкими, и напрочь лишенными седел и спиц. Я выбрасывал их в мусорную корзину с легким сердцем, чтобы в результате обратиться к одному из зрелых, проверенных общественными баталиями решений. Но не в этот раз.
Мы посмотрели на аналогичные попытки, предпринятые Netflix (Orchestrator, Data Capture,) Sharp End (AWS + Chaos Monkey,) OpenPolicyAgent, и многими другими, а также — многими встроенными инструментами инфраструктуры облачного провайдера, но песня осталась прежней.

Все выглядело так, как будто нам действительно было нужно наше собственное, созданное здесь и сейчас, решение.
Пара слов в завершение
Чем больше компания, тем больше неудач она терпит на каждом шагу в единицу времени. Не следует слепо следовать советам и передовым практикам, опубликованным властями. Используйте время, посвященное анализу проблемы, — с умом. Учитесь на собственных ошибках, прежде чем выбрать одно из правильных решений, представленных на рынке. Или, редко, но со смешанным чувством глубокого изумления и удовлетворения, убедитесь сами, что ваш велосипед едет плавно, и на самом деле — быстрее и аккуратнее, чем все, что было создано человечеством раньше. Это чудесный момент, позволяющий наслаждиться этим прекрасным чуввством: да я, оказывается, не так уж и плох в своей профессии!».
Удачного велосипедостроения!
Комментариев нет:
Отправить комментарий