Подробности и билеты по ссылке. HighLoad++ Siberia 2019. Зал «Красноярск». 25 июня, 14:00. Тезисы и презентация.
Разработать промышленную систему управления и распространения данных с нуля — нелегкая задача. Тем более, когда полный бэклог, времени на работу — квартал, а требования к продукту — вечная турбулентность.

Мы расскажем на примере построения системы управления метаданными, как за короткий промежуток времени выстроить промышленную масштабируемую систему, которая включает в себя хранение и распространение данных.
Наш подход использует все преимущества метаданных, динамического кода SQL и кодогенерации на основе Swagger codegen и handlebars. Это решение сокращает время разработки и переконфигурации системы, а добавление новых объектов управления не требует ни единой строки нового кода.
Мы расскажем, как это работает в нашей команде: каких правил придерживаемся, какие инструменты используем, с какими трудностями столкнулись и как их героически преодолели.
Анастасия Цымбалюк (далее – АЦ): – Меня зовут Настя, а это – Стас!
Стас Целовальников (далее – СЦ): – Всем привет!
АЦ: – Сегодня мы расскажем вам про MDA, и как мы с помощью этого подхода сократили время на разработку и явили миру промышленную масштабируемую систему управления метаданными. Ура!
СЦ: – Настя, что такое MDA?
АЦ: – Стас, я думаю, мы к этому сейчас плавно перейдём. Точнее, об этом расскажу чуть-чуть в конце презентации. Давай сначала расскажем о нас:

Себя я могу охарактеризовать как искатель синергии в промышленных IT-решениях.
СЦ: – А меня?
Чем занимается команда SberData?
АЦ: – А ты просто промышленный мастодонт, потому что вывел в пром не одно решение!
СЦ: – На самом деле мы работаем вместе в «Сбербанке» в одной команде и занимаемся управлением метаданными SberData:

АЦ: – SberData, если по-простому – это аналитическая платформа, куда стекаются все цифровые следы каждого клиента. Если вы клиент «Сбербанка», вся информация о вас стекается именно туда. Там хранится множество dataset, но мы понимаем, что объём данных не означает их качества. А данные без контекста иногда бывают вовсе бесполезны, потому что мы не можем их применить, интерпретировать, защитить, обогатить.
Как раз эти задачи решают метаданные. Они показывают нам бизнес-контекст и техническую составляющую данных, т. е. где они появились, как трансформировались, в какой точке находятся сейчас и минимальное описание, разметку. Этого уже достаточно для того, чтобы начать пользоваться данными и им доверять. Как раз эту задачу и решают метаданные.
СЦ: – Другими словами, миссия наше й команды – повышение коэффициента полезного действия информационной аналитической платформы «Сбербанка» за счет того, что информация, о которой, ты только что рассказала, должна быть доставлена нужным людям в нужное время в нужном месте. А помнишь, ты ещё говорила о том, что, если данные – это современная нефть, то метаданные – карта месторождений этой нефти.
АЦ: – Действительно, это одно из моих гениальных высказываний, которым я очень сильно горжусь. Технически эта задача сводилась к тому, что мы должны были создать инструмент управления метаданными внутри нашей платформы и обеспечить его полный жизненный цикл.
Но для того, чтобы погрузиться в проблематику нашей предметной области и понять, в какой точке мы находимся, я предлагаю откатиться на 9 месяцев назад.
Итак, представьте: за окном ноябрь месяц, птицы все улетели на юг, мы грустим… И у нас к тому моменту с командой был проведён успешный пилот, были заказчики – мы все пребывали в зоне комфорта, пока не случилась та самая точка невозврата.
Система управления метаданными моделей
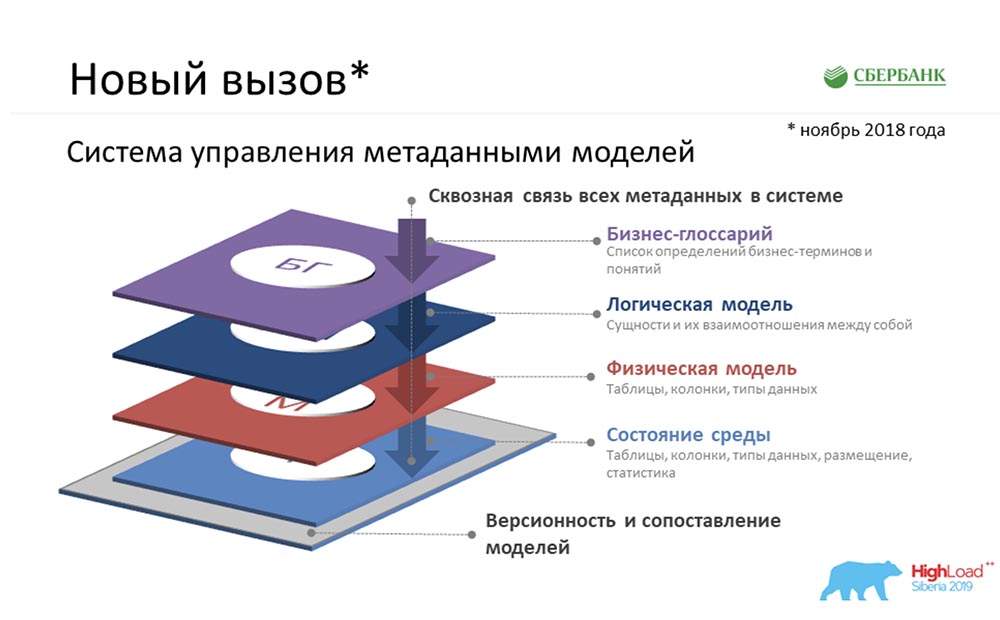
СЦ: – Там у тебя ещё что-то было о том, что мы пребывали в зоне комфорта… Фактически нам была поставлена задача создания Metadata Broker, который должен был дать возможность общения с нашими клиентами, программами, системами. Наши клиенты должны были иметь возможность на уровне бэкенда либо отправить какой-то пакет метаданных, либо получить. И мы, обеспечивая эту функцию, на своём уровне должны были аккумулировать максимально согласованную, актуальную информацию по метаданным на четырёх логических уровнях:
- Уровень бизнес-глоссария.
- Уровень логической модели.
- Уровень физической модели.
- Состояние среды, которое мы получали за счёт реверса промышленных сред.
И всё это должно быть согласованно.
АЦ: – Да, действительно. Но здесь я бы тоже как-то объяснила по-простому, поскольку не исключаю, что предметная область неясна и непонятна…
Бизнес-глоссарий – это о том, что умные люди в костюмах часами придумывают… как назвать какой-то термин, как придумать формулу расчёта. Они долго-долго думают, и в конце у них появляется как раз бизнес-глоссарий.
Логическая модель – это о том, как видит себе мир аналитик, который в состоянии общаться с этими умными людьми в костюмах и галстуках, но в то же время понимает, как бы это можно было приземлить. Далёк от деталей физической реализации.
Физическая модель – это о том, когда наступает очередь суровых программистов, архитекторов, которые реально понимают, как эти объекты приземлить – в какую таблицу положить, какие поля создать, какие индексы навесить…
Состояние среды – это некий слепок. Это как показания с машины. Программист иногда хочет сказать машине одно, а она неправильно понимает. Как раз состояние среды показывает нам реальное положение дел, и мы постоянно всё сравниваем; и понимаем, что есть разница между тем, что сказал программист, и реальным состоянием среды.
Кейс для описания метаданных
СЦ: – Поясним это на конкретном примере.Например, что у нас есть четыре этих обозначенных уровня. Предположим, что есть у нас эти серьёзные люди в галстуках, которые работают на уровне бизнес-глоссария – они вообще не понимают, как и что внутри устроено. Но они понимают, что им нужно делать форму обязательной отчётности, нужно получить, скажем, средний остаток на лицевых счетах:

К этому уровню человек уже должен иметь свой бизнес-глоссарий (терминов обязательной отчётности) или его завести (средний остаток на лицевом счёте). Дальше приходит аналитик, который его прекрасно понимает, может с ним поговорить на одном языке, но при этом может говорить на одном языке и с программистами.
Он говорит: «Слушай, у тебя здесь вся история разбивается на отдельные счета как сущности, и у них есть атрибут – средний остаток».
Дальше приходит архитектор и говорит: «Мы будем делать эту витрину кредитов юридических лиц. Соответственно, мы сделаем физическую таблицу лицевых счетов, мы сделаем физическую таблицу ежедневных остатков на лицевых счетах (потому что они получаются каждый день при закрытии оперативного дня). А раз в месяц по дедлайну будем рассчитывать среднее (таблица ежемесячных остатков), как и просили».
Сказано – сделано. А потом пришёл наш парсер, который сходил на промышленный контур и сказал: «Да, вижу – есть необходимые таблицы…» Что ещё обогатило эту таблицу? Здесь (в качестве примера) – партиции и индексы, хотя, строго говоря, и партиции и индексы могли бы находиться на уровне проектирования физмодели, а здесь могло быть что-то ещё (например, объём данных).
Регистрация и хранение на уровне метаданных
АЦ: – Как это хранится всё у нас? Это суперупрощённая форма того примера, который расписал ранее Стас! Как это всё будет лежать у нас?
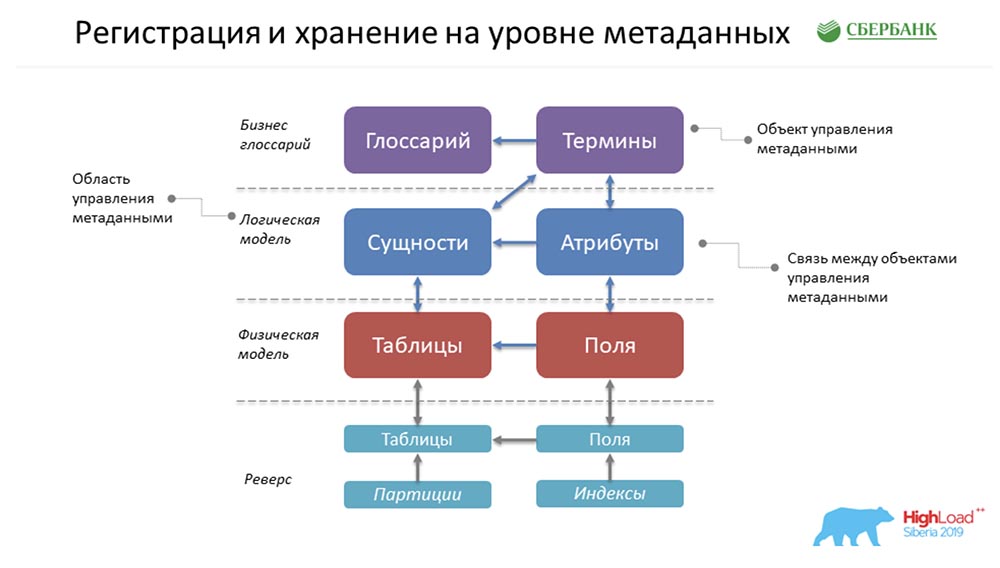
Фактически это будет одна строка в объекте «Глоссарий», одна – в объекте «Термины», одна – в «Сущностях», одна – в «Атрибутах» и так далее. На рисунке выше каждый прямоугольник – это объект в нашей системе управления, который представляет собой ту или иную хранимую там информацию.
Чтобы вас потихоньку начать вводить в терминологию, я прошу отметить следующее… Что такое объект управления метаданными? Физически это представлено в виде таблицы, но на самом деле там хранится определённая информация по терминам, глоссариям, сущностям, атрибутам и т. д. Этот термин, «объект», мы дальше и будем использовать в своей презентации.
СЦ: – Здесь надо сказать, что каждый кубик – это просто таблица в нашей системе, где мы храним метаданные, и это мы называем тем самым объектом управления.
Требования по введению метаданных
Что мы имели на входе? На входе нам пришли достаточно интересные требования. Их было очень много, но здесь мы хотим показать три основных:

Первое требование достаточно классическое. Нам говорят: «Ребята, всё, что к вам однажды зашло, оно должно зайти навсегда». Историзация полная, причём любое изменение в вашей системе метаданных, которые к вам пришли (неважно, пришёл ли пакет из 100 полей (100 изменений), либо одно поле в одной таблице изменилось), требуют обязательной регистрации новой ревизии метаданных. Также требуют вернуть ответ:
- по умолчанию – актуальное состояние;
- по дате;
- по номеру ревизии.
Второе требование было интереснее: нам сказали, что могут с нами работать по объектам, но придётся программировать много на Java, а они этого не хотят. Предложили пригнать вперемешку сразу 100 объектов (или 10), а нам это дело обрабатывать (потому что умеем). Что значит вперемешку? Например, пришло 10 колонок. Они имеют ссылку на идентификатор таблицы, а самой таблицы у нас нет – она в хвосте JSON’а пришла. «Вы придумайте и обработайте – надо, чтобы вы это смогли»!
В порядке увеличения интереса – третье: «Мы хотим иметь возможность не просто пользоваться API, который вы нам сделаете, а хотим сами понимать…» И в произвольном порядке говорить: «Дайте нам объединение с этого объекта на тот через третий объект. И пусть у вас система сама поймёт, как это всё делать, спросит у базы и вернёт результат в JSON’е».
Такую историю мы имели на входе.
Приблизительные расчёты

АЦ: – По нашим приблизительным расчётам, чтобы всю эту концепцию претворить в жизнь, нужно каждый объект управления участвовал в семи интерфейсах: простые (симпловые), на пообъектную запись / чтение и удаление…
Ещё три – на универсальную запись / чтение / удаление, т. е. что мы можем закинуть всё это в любом порядке и как суповой набор передать системе, а она сама разберётся, в каком порядке удалять, ставить, читать.
Ещё одно – на построение иерархии, чтобы мы системе могли указать – «Верни нам с объекта по объект»; и она возвращает дерево вложенных объектов.
Сложность реализации
СЦ: – Помимо технических требований, которые пришли нам на вход в момент старта этой истории, мы имели дополнительные трудности.

Во-первых, это некоторая неопределённость требований. Не всякая команда и не всегда могла чётко сформулировать, что им нужно от сервиса, и зачастую момент истины рождался в момент прототипирования какой-то истории на контуре def. И пока это доходила до прома, могло быть и несколько циклов.
АЦ: – Это и есть та самая турбулентность, которую анонсировали вначале.
СЦ: – Далее…
Был запредельный дедлайн, потому что даже на момент старта от нас зависело более пяти команд. Классика жанра: результат нужен был вчера. Вариант работы – в режиме ошпаренной лошади, чем мы и занимались.
Третье – это большой объём разработки. Настя на своём слайде показала, что, когда мы посмотрели требования, что и как делать, то поняли: 1 объект требует семи API (либо под него, либо участие в семи API). Это означает, что, если у нас патч (6 объектов, модельный, 42 API) выходит за недельку…
Стандартный подход
АЦ: – Да, на самом деле 42 API за неделю – это лишь верхушка айсберга. Мы прекрасно понимаем: чтобы обеспечить работу этих 42 API, нам необходимо:
- во-первых, создать структуру хранения под объект;
- во-вторых, обеспечить логику его обработки;
- в-третьих, написать тот самый API, в котором объект участвует (либо настроен конкретно под него);
- в-четвёртых, было бы неплохо в идеале обложить всё это контурами тестирования, протестировать и сказать, что всё хорошо;
- в-пятых (та самая вишенка на торте), задокументировать всю эту историю.
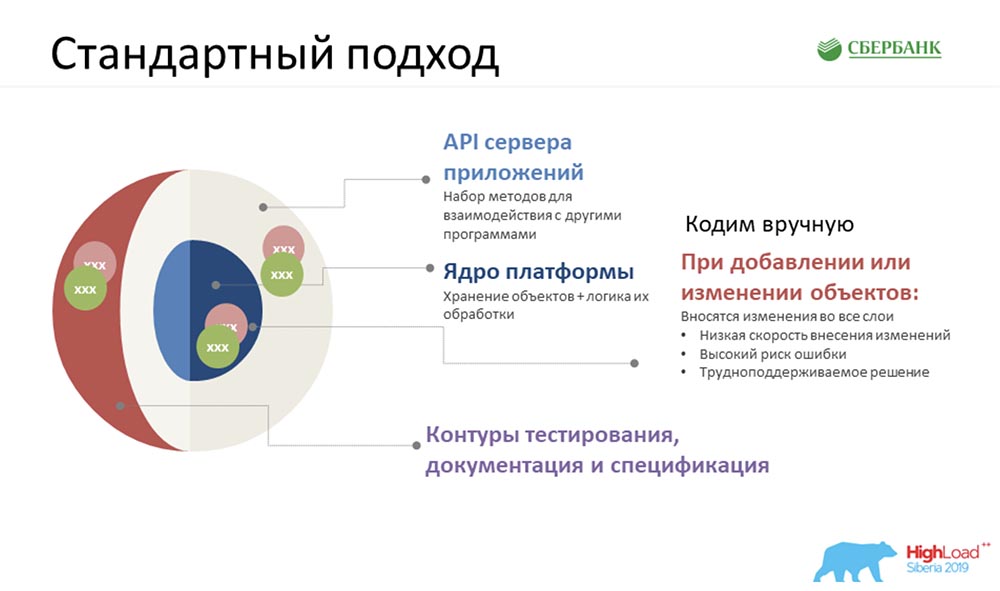
Естественно, первое, что нам пришло в голову (на старте мы вам показывали примерную схему) – мы имели около 35 объектов. С ними нужно было что-то делать, всё это нужно было выводить, а времени было очень мало. И первая идея, которая пришла к нам в голову – это сесть, закатить рукава и начать кодить.
Даже пару дней поработав в таком режиме (нас было три команды), мы достигли такой температуры накала… Все были нервные… И мы поняли, что нам нужно искать другой подход.
Нестандартный подход
Мы начали обращать внимание на то, чем мы занимаемся. Идея этого подхода всегда была у нас перед глазами, потому что мы очень давно занимаемся метаданными. Как-то сразу она нам в голову не пришла…
Как вы догадались, суть этой идеи в том, чтобы использовать метаданные. Она заключается в том, что мы собираем структуру нашего хранилища (это и есть определённые метаданные), один раз создаём шаблон какого-то кода (например, несколько API или процедур обработки логики, скриптов создания структур). Один раз создаём этот шаблон, а потом прогоняем через все метаданные. По тегам в код подставляются свойства (имена объектов, поля, важные характеристики), и на выходе получаем готовый код.

То есть достаточно один раз заморочиться – создать шаблон, а потом всю эту информацию использовать как для существующих, так и для новых объектов. Здесь мы введём ещё одно понятие – #META_META. Объясню зачем, чтобы вас не запутать.
Наша система занимается управлением метаданными, а подход, который мы используем, описывает систему управления метаданными, т. е. две меты. «МетаМета» – мы так назвали у себя, внутри команды. Чтобы и остальных дальше не путать, мы будем использовать именно этот термин.
Механизм обеспечения историзации и ревизии
СЦ: – Ты кратко изложила остальную часть нашего выступления. Расскажем более подробно.
Надо сказать, что, когда мы готовились к выступлению, нас попросили дать техническую информацию, которая могла бы быть интересна коллегам. Мы это сделаем. Далее слайды пойдут больше технические – возможно, кто-то что-то интересное для себя увидит.
Сперва о том, как мы решили вопрос историзации и ревизии. Возможно, это похоже на то, как делают многие. Рассмотрим это на примере метаданных, которые описывают одно поле в таблице проводок (в качестве примера):
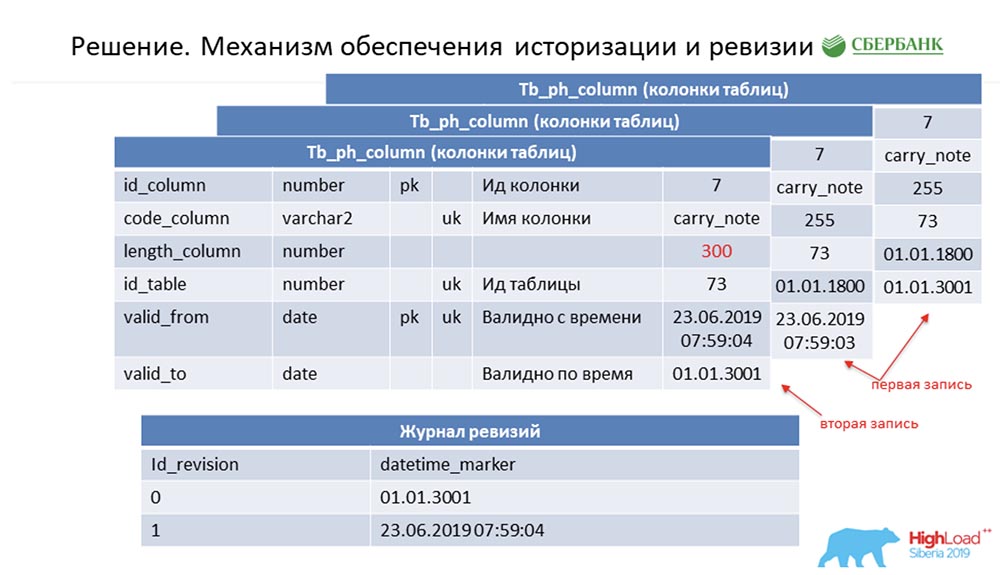
У неё есть id – «7», имя – carry_note, есть ссылка id_table 73, а также поле – 255. Мы вводим в первичный и альтернативный ключ некое поле (типа date) с временной точки, с которой эта запись становится валидной – valid_from. И ещё одно поле – по какую дату эта запись валидна (valid_to). В данном случае они заполнены по умолчанию – видно, что эта запись в принципе валидна всегда. И так происходит до тех пор, пока мы не захотим изменить, скажем, длину поля.
Как только мы хотим это сделать, мы закрываем запись valid_to (фиксируем временную метку, в которую событие произошло). Одновременно с этим делаем новую запись («300»). Несложно заметить, что при таком раскладе, если обратиться к базе данных с какой-то временной точки по «битвину» (between) между valid_from и valid_to, то мы получим одну-единственную, но актуальную на тот момент времени запись. И при этом мы одновременно вели некоторый журнал ревизии:
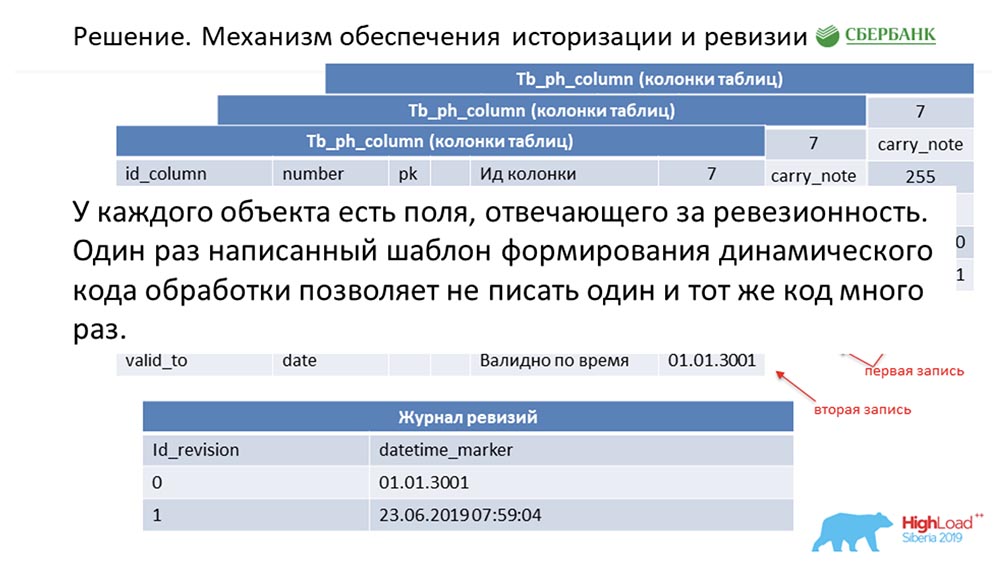
В нём мы фиксировали возрастающие по сиквенсу (sequence) id ревизии, и временную точку, которая соответствует этому id ревизии. Так мы и смогли закрыть первое требование.
АЦ: – В принципе да! Здесь подход один и тот же. Мы понимаем, что у каждого объекта в системе есть эти два обязательных поля, и мы один раз заморочились – скодировали логику обработки этого шаблона, а потом (при формировании динамического кода) просто подставляем имена соответствующих объектов. Так каждый объект в нашей системе становится ревизионным, и это всё может обрабатываться – мы вообще больше не пишем ни единой строки кода.
Пакетное обновление
СЦ: – Второе требование для меня было чуть более интересным. Честно говоря, когда оно пришло на вход, я сначала просто стал в ступор. Но решение пришло!
Я напомню, это тот самый кейс, когда к нам, допустим, пришёл JSON с пакетом на n-ое количество объектов, которые нужно вставить в систему. При этом у нас в начале идут 10 колонок, ссылающихся на несуществующую таблицу, а таблица шла в хвосте JSON. Что делать?

Мы нашли выход в использовании механизма рекурсивных иерархических запросов – это наверняка всем хорошо известная конструкция connect by prior. Сделали это следующим образом: здесь – фрагмент нашего кода на продакшн:

В этом месте (участок кода, обведённый красным овалом) – основная суть, которая даёт идею. И здесь объект линкуется на другой объект, связанный по foreign key, который есть в системе.
Для понимания: если кто-то пишет код на Oracle, там есть таблицы All_columns, All_all_ tables, All_constraint – это и есть словарь, который обрабатывается обрабатывается скриптами (как те, что отражены на слайде выше).
На выходе мы получаем поля, которые дают нам приоритет обработки объектов, и дополнительно дают дескриптор – он по сути является уникальным строковым идентификатором любой записи метаданных. Код, по которому получен дескриптор, тоже указан на слайде выше.
Например, поле – как оно могло бы выглядеть? Это код платформы: oracle КП., production. КП, my_scheme.КП, my_table. КП и т.д., где КП – это код поля. Вот и будет такой дескриптор.
АЦ: – Какая здесь проблематика? У нас есть объекты в системе и нам очень важен порядок их вставки. Например, колонки мы не можем вставить перед таблицами, потому что колонка должна ссылаться на определённую таблицу. Как мы делаем стандартно: сначала вставляем таблицы, в ответ получаем массив id, по этим айдишникам раскидываем колонки и делаем вторую операцию вставки.
В реальности, как показывал Стас, длина этой цепочки доходит до 8-9 объектов. Пользователю, используя стандартный подход, нужно выполнять все эти операции поочерёдно (все эти 9 операций) и чётко осознавать их порядок, чтобы не случилось никакой ошибки.
Насколько я верно интерпретирую Стаса, мы можем передать системе все эти объекты в любом порядке и вообще не заморачиваться о том, как нам нужно производить эту вставку – мы просто кинул в систему суповой набор, а она сама всё распределила, в каком порядке вставлять.
Единственное, у меня возникает вопрос: а если мы вставляем объект в первый раз? Мы таблицу до этого вставляли, не знаем её id. Как нам указать (чисто гипотетический пример), что нужно вставить две таблицы, у каждой из которых есть по колонке? Как нам указать, что в этом JSON’е колонка ссылается на таблицу1, а не на таблицу2?
СЦ: – Дескриптор! Дескриптор, который мы указали на том слайде (предыдущем).
А на этом слайде собственно и дано то самое решение:

Дескрипторы используются в системе как некое мнемоническое поле, которое не существует, но заменяет id. В тот момент, когда вначале система поймёт, что нужно вставить таблицу – вставит, получит id; и уже на этапе генерации SQL-запроса вставки и колонки она будет оперировать id. Пользователь может не париться: «Дай дескриптор и выполни!». Система сделает.
Универсальный запрос по группе связанных объектов
Пожалуй, мой любимый кейс. Это самое любимое техническое требование, которое у нас было. К нам пришли и сказали: «Ребята, сделайте, чтобы система могла всё! С объекта на объект, пожалуйста. Догадайтесь, как это всё джойнить между собой. Верните нам, JSON, пожалуйста. Мы не хотим много программировать, используя ваш сервис»…
Вопрос: «Как?!»
Мы на самом деле пошли тем же путём. Ровно та же самая конструкция:

Она использована для того, чтобы решить и эту задачу. С одной лишь разницей: там был допускной фильтр, который раскручивал это иерархическое дерево только для тех историй, где требовался дескриптор. Условно говоря, он был уникальный для каждого объекта. Здесь же раскручиваются все возможные связи в системе (у нас порядка 50 объектов).
Все возможные связи между объектами лежат заранее подготовленными. Если у нас объект участвует в трёх связях, соответственно, три строчки будет подготовлено для того, чтобы алгоритм мог понять. И как только к нам приходит JSON-запрос, мы идём туда, где у нас заранее в «МетеМете» подготовлена эта история, ищем нужный нам путь. Если не находим – это одна история, если находим – формируем запрос в БД. Выполняется – возвращаем JSON (что и просили).
АЦ: – Как результат, мы можем системе передать, с какого по какой объект мы хотим получить. И если можно очертить чёткую связь между двумя объектами, значит, система сама разберётся, на каком уровне вложенности объект, и вернёт вам дерева:
Это очень гибко! Пользователи у нас, ещё раз повторю, находится в состоянии «турбулентности»: сегодня им нужно одно, завтра – другое. А данное решение позволяет нам очень гибко адаптировать структуру. Это были три ключевых кейса, которые применены у нас на стороне ядра.
СЦ: – Давай подведём некоторый итог. Понятно, что сейчас мы всех фишек не расскажем из-за ограниченности времени. Три кейса, на наш взгляд, мы вынесли и рассказали. У нас получилось, мы смогли всю самую сложную логику, причём ту, которая должна однообразно работать по каждому объекту управления метаданными, впихнуть в код ядра.
Мы не смогли сделать этот код 100% динамическим, а это означает, что с любыми созданными объектами (неважно – уже созданные или которые будут созданы потом; главное, чтобы были созданы по правилам) система работать умеет – ничего не надо дописывать, переписывать. Достаточно просто протестировать. Всю эту историю мы припарковали на три универсальных метода. На мой взгляд, их достаточно для того, чтобы решить практически любую бизнес-задачу:
- во-первых, этот тот самый универсальный «обновлятор» – метод, который умеет делать update/insert/delete (delete – это закрытие записи) по одному или группе объектов, переданных в произвольном порядке.
- второе – это метод, который умеет возвращать универсальную информацию только по одному объекту;
- третье – это тот самый метод, который может возвращать Join-информацию, соединённую по группам объектов.
Вот так у нас получилось, и мы сделали ядро. А дальше мы перейдём к твоей самой любимой части.
Точка входа в Application
АЦ: – Да, это моя любимая часть, потому что это моя зона ответственности – Application Server. Чтобы понять, в какой ситуации я находилась, снова попытаюсь погрузить вас в проблему.
Стас хорошо поработал и передал мне эти три стандартных метода, которые манипулировали этими объектами. Это чисто схематичное описание – в реальности их намного больше:

Вернёмся к самому началу, чтобы вас погрузить… Как у нас будут представлены метаданные в системе?
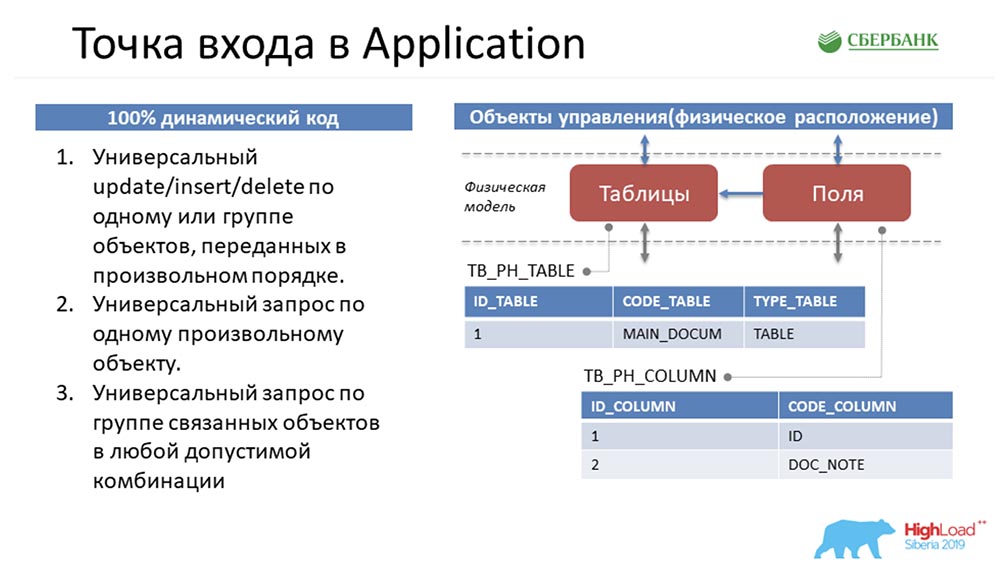
Если мы видим, что в среде есть таблица, в нашу систему она ляжет как одна запись в объекте таблиц и пара записей в объекте полей. По сути мы собрали структуру.
Мы можем заметить, что количество у этих объектов разное. Тогда, чтобы манипулировать этими объектами, привести всё к универсальной структуре, чтобы все три метода поняли, о чём идёт речь, Стас делает ход конём. Он берёт, и все объекты переворачивает, т. е. любой объект в нашей системе управления метаданными он представляет как четыре строки:

Поскольку любой объект в нашей системе управления метаданными физически представляет собой таблицу, то любой объект можно разложить по этим четырём признакам: номер строки, таблица, поле и значение поля. Это всё как раз придумал Стас, а мне это нужно было как-то претворить в жизнь и отдать пользователям.
СЦ: – Извини, а как я могу тебе передавать в каком-то плоском ответе колонки, например, которые ещё не созданы, когда-то будут созданы, и бог знает какими они могут быть?.. Поэтому единственный вариант в условиях динамического кода настроить взаимодействие между ядром и application, передать тебе эту информацию – только такой, какой мы видим. Я считаю, что с моей точки зрения это решение было гениальным, потому что оно исходило как раз от тебя.
АЦ: – Сейчас мы не будем об этом спорить. За две недели до конца дедлайна я осталась с тем, что у меня на руках были эти три метода (слева на предыдущем слайде), которые манипулировали универсальной структурой (справа на том же слайде).
Моей первой мыслью было просто завернуть всё на уровне API и пойти с этим к пользователю, сказав: «Вот, смотрите, какая гениальная вещь! Вы можете делать что угодно! Передавать любые объекты, и даже не существующие. Круто, да»?!

А они говорят: «Но вы понимаете, что у вас сервис совсем не специализирован? Я как пользователь не понимаю, какие объекты я могу передать в систему, как я могу ими манипулировать… Для меня это – чёрный ящик, я вообще боюсь, что покорёжу данные; я могу ошибиться – мне страшно. Сделайте так, чтобы я мог чётко следовать инструкциям и видеть, какие объекты есть в системе и какие способы манипуляции я могу использовать».
Спека. Подход
Тогда нам стало ясно, что было классно составить спеку на наш сервис. Коротко говоря, составить список объектов нашей системы, список инпойнтов, манипуляций и какими объектами они между собой жонглируют. Так сложилось, что в нашей компании мы для этих целей используем Swagger для этих целей как некоторое архитектурное решение.

Посмотрев структуры «Сваггера», я поняла, что нужно где-то взять структуру объектов, которые есть в системе. От ядра я получила только три стандартных метода и перевёртыш в виде таблицы. Больше ничего. Для меня тогда казалось невыполнимой задачей вытащить всю структуру, которая есть в хранилище, из этих четырёх стандартных полей. Я искренне не понимала, где меня взять всё описания объектов, все допустимые значения, всю логику…
СЦ: – Что значит где? У нас с тобой есть «МетаМета», которая обеспечивает работу ядра в режиме Real-time. Ядро в режиме реального времени исполнения генерирует SQL-запрос, который общается с базой. Там всё есть, не только то, что тебе нужно. Там есть ещё и связи между объектами.
АЦ: – По совету Стаса тогда я пошла в «МетаМету» и удивилась, потому что весь необходимый джентльменский набор для генерации стандартной спеки там присутствовал. Тогда появилась идея, что нужно создать шаблон и расписать всё по семи возможным сценариям – 7 стандартных API для каждого объекта.
Спека. OAS + Handlebars
Итак, здесь нетрудно заметить, из чего состоит спека:

Можно зайти на сайт OAS и Handlebars (внизу слайда) и посмотреть, из чего она должна состоять – там набор Endpoints, набор методов, а в конце идут модели. Код повторяется из раза в раз. Для каждого объекта мы должны писать get, put. delete; для группы объектов мы это должны написать и так далее.
Фишка состояла в том, чтобы всю эту историю написать один раз и больше не париться. На слайде представлен пример реального кода. Синие объекты – это теги в Handlebars, это шаблонизатор; довольно-таки гибкий, всем советую – его можно настраивать под себя, писать кастомные обработчики тегов…
На место этих синих тегов, когда этот шаблон пробегается по всем-всем метаданным, подставляются все значимые свойства – имя объекта, его описание, какая-то логика (например, что нам нужно добавить дополнительный параметр, в зависимости от свойства) и так далее. В конце – ссылка на модель, которую он интерпретирует.
Код application. Swagger Codegen + Handlebars
Всё это мы закодировали, записали, составили спеку. Всё было очень классно и хорошо. Мы получили все 7 возможных сценариев для каждого объекта.
Отдали это пользователю. Тот сказал: «Вау! Круто! Теперь мы хотим этим пользоваться»! В чём проблема, опять-таки?
У нас появилась спека, которая подробно описывает каждый метод, что с ним делать, какими объектами манипулировать. И есть три стандартных метода ядра, которые на вход принимают описанную выше перевёрнутую таблицу.
Тогда нужно было просто одно скрестить с другим (сейчас мне это кажется лёгким). То есть, когда пользователь вызывает в интерфейсе какой-то метод, нам нужно было правильно и корректно пробросить его в ядро, перевернув модель (где у нас есть красивые спецификации) в эти четыре стандартных поля. Вот и всё, что нужно было сделать.

Для того чтобы всё это претворить в жизнь, нам потребовались «назначительные» преобразования…
Преобразования
У «Сваггера» изначально есть такой инструмент – Swagger Codegen. Если вы хоть раз заходили в спеку, составляли, то там есть кнопка «Сгенерировать серверную часть». Нажимаете, выбираете язык – вам генерируется готовый проект.
Генерируется замечательно: там есть все описания классов, все описания эндпойнтов… – он работающий. Можете запустить у себя локально – он будет работать. Беда одна: он возвращает заглушки – каждый метод не инкрементирован.
Была идея в том, чтобы дописать логику, исходя из этих семи сценариев в кодогенераторе – «испортить» один из стандартных шаблонов, настроить его под себя. Здесь как раз пример реального кода, который мы используем в шаблонизаторе и список тех действий, которые нам необходимо было выполнить, чтобы настроить этот кодогенератор под себя:

Самое главное, что сделали – подключили необходимые библиотеки, прописали классы общения с ядром, интерпретировали (в зависимости от сценария) вызов одного или нескольких методов на стороне ядра. Также переворачивали модель: из красивой, что указана в спеке – в четыре поля, а потом обратно трансформировали.
Наверное, самый сложный кейс здесь заключался в том, чтобы отдать пользователю дерево, потому что ядро нам в ответ также возвращает четыре строки – поди разбери, на каком уровне иерархии находится объект. Мы воспользовались механизмом внешних связей, который есть в IDE, то есть мы пошли в «МетаМету», посмотрели все пути от одного к другому и по ним динамически генерируем дерево. Пользователь может у нас запросить с любого объекта по любой, какой желает – ему на выходе вернётся красивое дерево, в котором всё уже структурно разложено.
СЦ: – Я на секунду тебя остановлю, поскольку уже начинаю теряться. Спрошу тебя в стиле «Правильно ли я понимаю, что»…
Ты хочешь сказать, что мы вычислили всё самое сложное, самый сложный код, который необходимо было бы написать для какого-то нового объекта. И для того, чтобы сэкономить время, не делать этого, мы сумели всё это запихнуть в ядро и сделать эту историю динамической… Но этот API (как пошутили, «упоротый») настолько «может всё», что его страшно отдавать наружу: неумело обращаясь с ним, можно повредить метаданные. Это с одной стороны.
С другой стороны, мы поняли, что не можем общаться с нашими заказчиками-клиентами, если не дадим им API, который будет однозначно проекцией тех объектов управления метаданными, которые задеплоины в систему (по сути выполнять некий контракт на наш сервис). Казалось бы, всё – мы попали: если объекта нет – его ещё нет, а когда он появляется – появляется расширение контракта, уже новый код.
Мы вроде бы попали избегаемое ручное кодирование, но ты здесь предлагаешь делать этот код по кнопке. Снова нам удаётся уйти от истории, когда что-то надо писать руками. Это так?
АЦ: – Да, это действительно так. Вообще, моя идея была завязать с программированием раз и навсегда, хотя бы с помощью шаблонизаторов. Один раз написать код, а потом отдыхать. И даже если появится новый объект в системе – по кнопке запускаем обновление, всё подтягивается, у нас новая структура, генерируются новые методы, всё хорошо и прекрасно.
Тюнинг MetaMeta
Для того чтобы сделать наш сервис ещё лучше, мы обогатили стандартную «МетаМету». На входе у нас было то, что осталось от ядра. Ещё мы добавили дополнительное описание к объектам, объекты сгруппировали в области. Всё это мы отображаем в спеке, чтобы пользователь понимал, чем он манипулирует и с каким объектом сейчас общается.
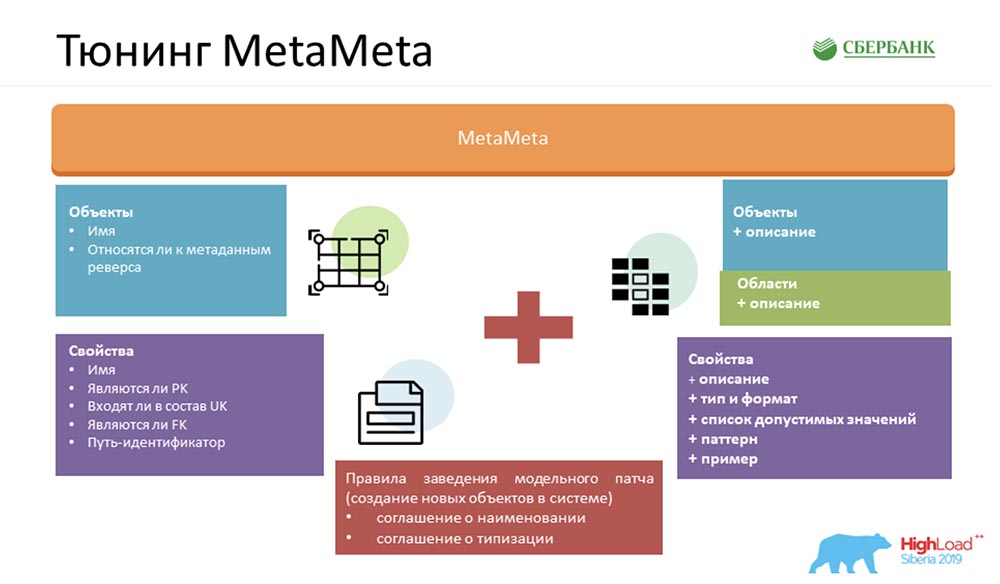
Только мы добавили туда некоторые рюшечки – типы, форматы, списки допустимых значений, паттерны, примеры. Это тоже доставляет удовольствие пользователям – они уже чётко понимают, что можно вставлять, что нельзя. Также мы ещё предоставляем клиентский артефакт пользователю, который позволяет нам отловить ошибки при общении с нашим сервисом (именно по формату, уже на этапе компиляции).
Но самое главное, чтобы вся эта магия работала, нам необходимо было внутри договориться: создать свод определённых правил. Их немного – я насчитала три (на слайде их два, поэтому один придётся запомнить):
- Соглашение о наименовании. Мы определённым образом именуем объекты в системе, чтобы было легче распознавать сценарии их дальнейшего использования.
- Соглашение о типизации. Это чтобы корректно определить типы, форматы, и чтобы они бились между ядром и application-сервером, мы используем систему check`ов, по которым понимаем, к какому формату относится то или иное свойство.
- Корректные внешние ключи. Если объекту указать неверную ссылку на другой объект, то вся эта магия будет работать неправильно.
Результат
СЦ: – Это круто, но очень много теории. Ты можешь привести какой-то практический пример?
АЦ: – Да, я его специально подготовила. До того как уехать на конференцию, в пятницу вечером, буквально за 5 минут до конца рабочего дня, Стас мне сказал: «О, смотри! Я выпустил модельный патч – как классно! Было бы неплохо обновить наш сервис». Патч содержал всего лишь два объекта, но я понимаю, что при старом подходе мне пришлось бы заморочиться и написать либо дописать 7 API.
Тут же мне хватило буквально нажатия одной кнопки, чтобы вся эта магия заработала. Красным я специально обвела то, место, где сейчас произойдёт магия:
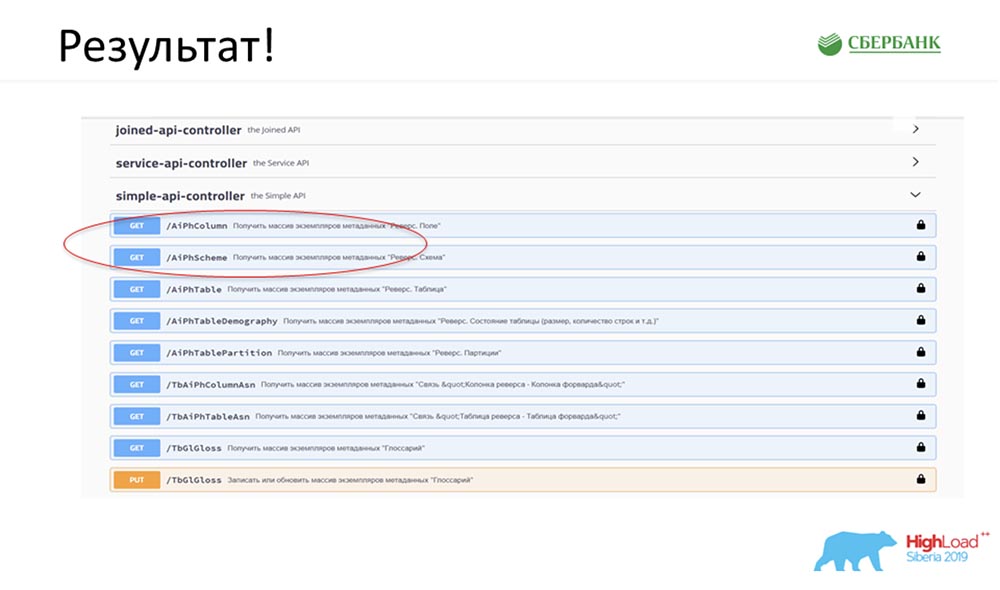
Нажимаю на кнопку… Это конечно, скрины, но в реальности всё так и работает:
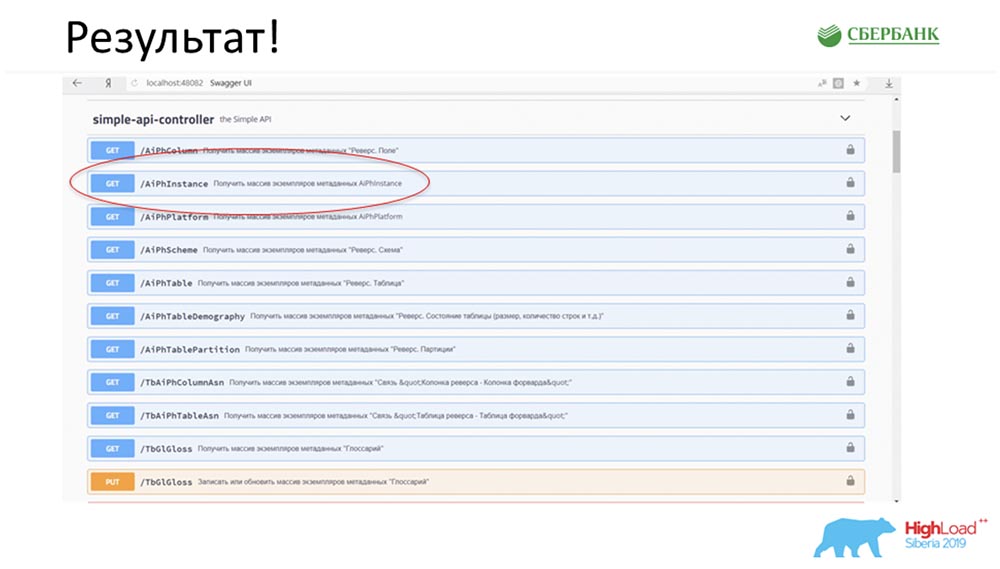
У нас появился новый метод (между двумя), который уже отдаёт данные, по которым мы в иерархии можем запросить всю структуру, все вложенные объекты:
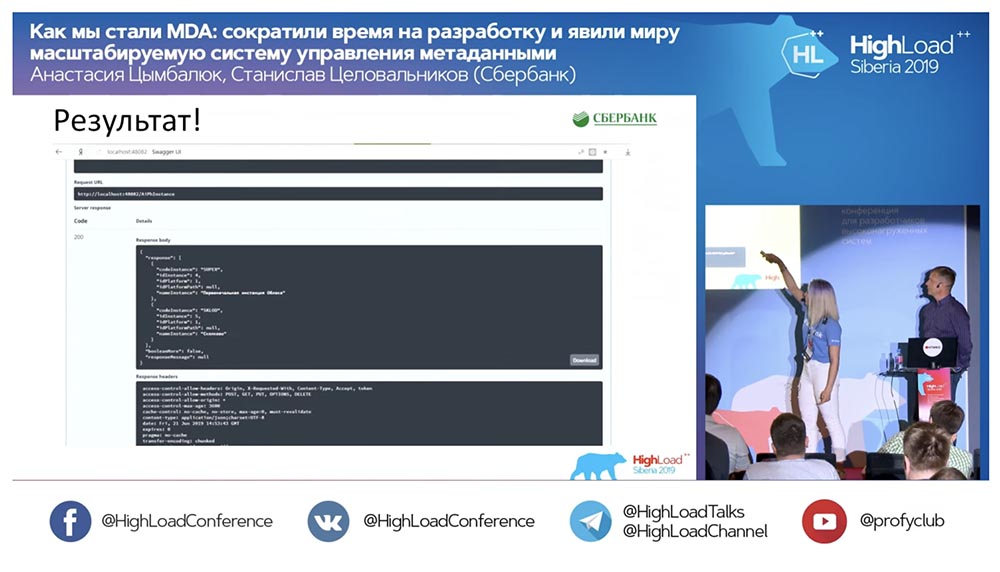
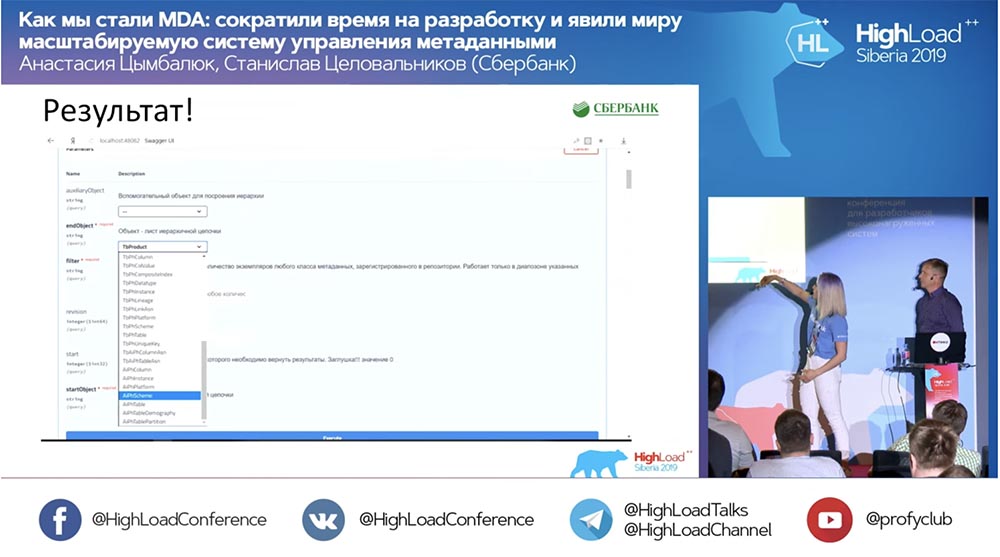
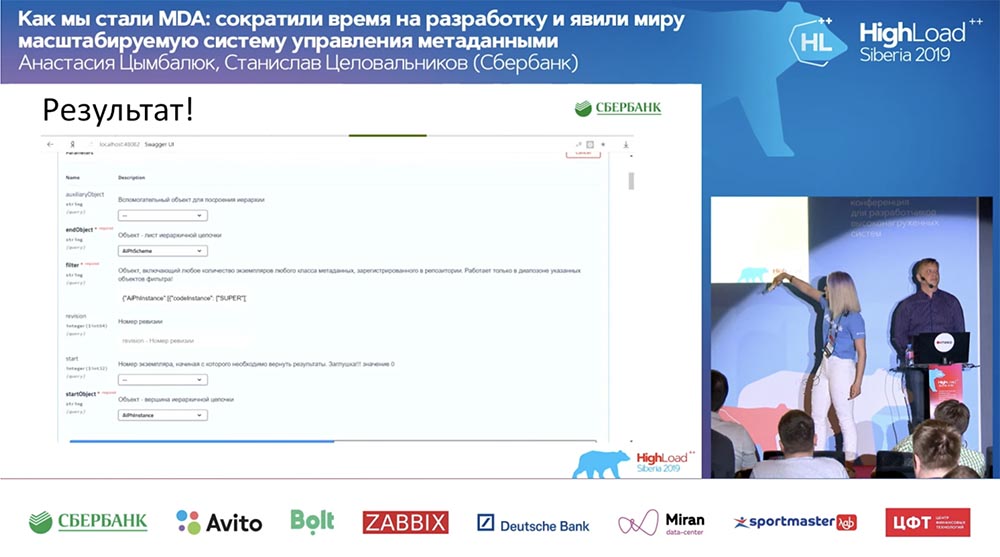
И всё это работает! Я вообще не написала ни одной строки кода.
Итоги
СЦ: – Во-первых, факт в чём? Нам удалось самую сложную логику, которая отнимала бы больше всего времени у наших программистов, упаковать в 100% динамический код ядра, который умеет работать с объектами – теми, что есть и теми, что будут:
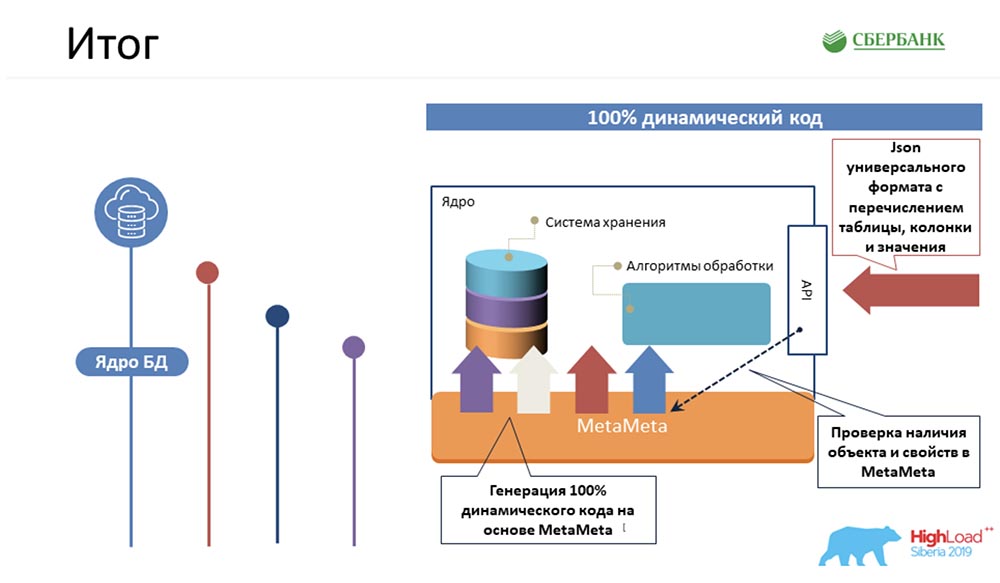
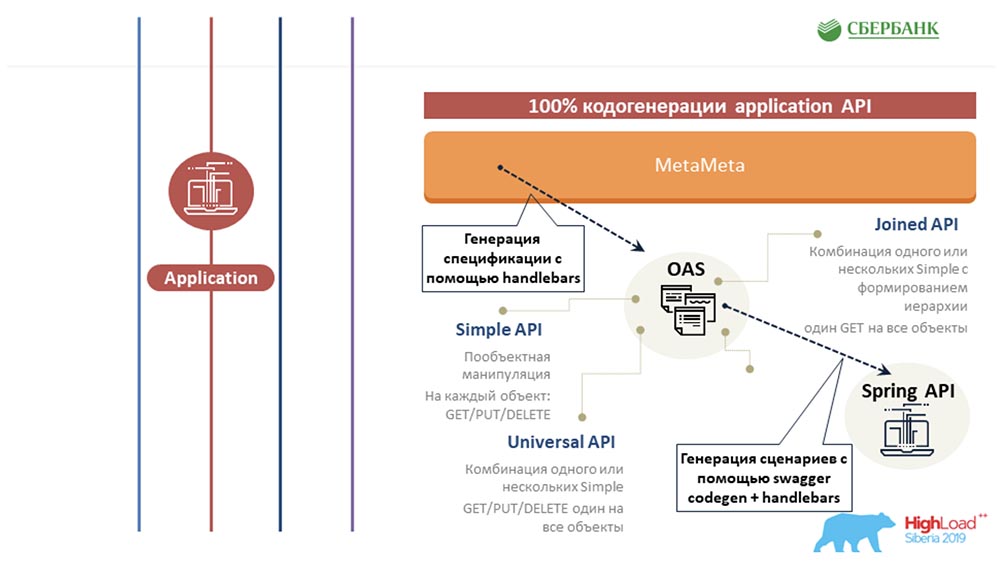
Во-вторых, нам удалось на уровне сервера приложений (там, где это невозможно) тоже уйти от программирования за счёт кодогенерации – та самая кнопка, которую ты демонстрировала:
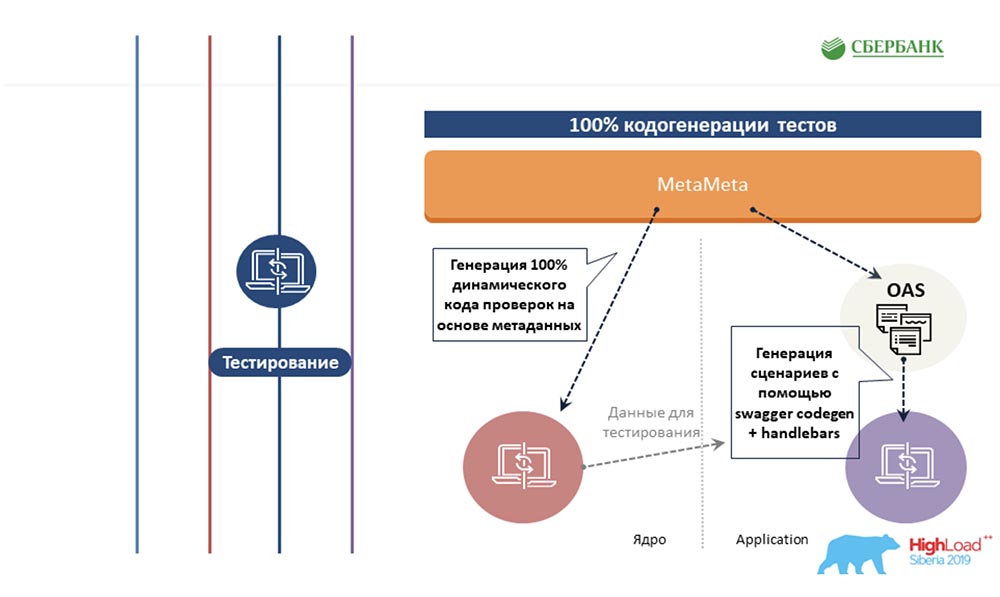
АЦ: – Тот же самый подход, основанный на метаданных, мы постарались распространить на другие области, на область тестирования. Мы так же пишем шаблон один раз для какого-то объекта, вставляем туда теги. И когда этот шаблон пробегается по метаданным, он генерирует готовую простыню со всеми тестовыми сценариями, то есть фактически мы все объекты покрываем тестами.
Далее – вишенка на торте. Я знаю, что мало кто любит документировать то, что делает. Мы решили эту боль тоже на основе метаданных. Один раз мы подготовили шаблон с html-разметкой, разметили его тегами. И когда мы пробегаемся по метаданным, во все эти теги подставляются соответствующие объектам их свойства.

На выходе получается готовая красивая html-страница. Затем публикуем в Confluence, и можем дать нашим пользователям в человеко-читаемом формате, чтобы они посмотрели, что у нас есть в системе, как с этим работать, какое-то минимальное описание, допустимые значения, обязательные свойства, ключи… Они всё это могут видеть и могут довольно-таки просто в этом разобраться.
Как результат, мы имеем четыре основных пойнта, и такой подход называется MDA (Model Driven Architecture). Переводится это почему-то как «архитектура, управляемая моделью», хотя я назвала бы это «методом разработки программного обеспечения».

Суть в чём? Вы создаёте модель, договариваетесь о неких правилах. Затем создаёте один раз шаблоны трансформации этой модели на каком-нибудь доступном вам языке программирования. Все это работает для изменения старых объектов, для добавления новых. Вы пишите код один раз и больше не заморачиваетесь.
СЦ: – Я честно ждал весь доклад, когда ты ответишь на этот вопрос. Давай перейдём к моим любимым слайдам.
Решение. Процесс. Раньше
АЦ: – «Процесс. Раньше» – это наша гордость, потому что раньше мы много программировали, почти ничего не ели – были очень злыми. Приходилось выполнять все эти 5 шагов для каждого объекта:

Это было очень грустно и отнимало у нас очень много времени. Сейчас мы сократили эту пищевую цепочку до трёх звеньев, самое важное из которых – просто правильно создать объект, и больше ничего:
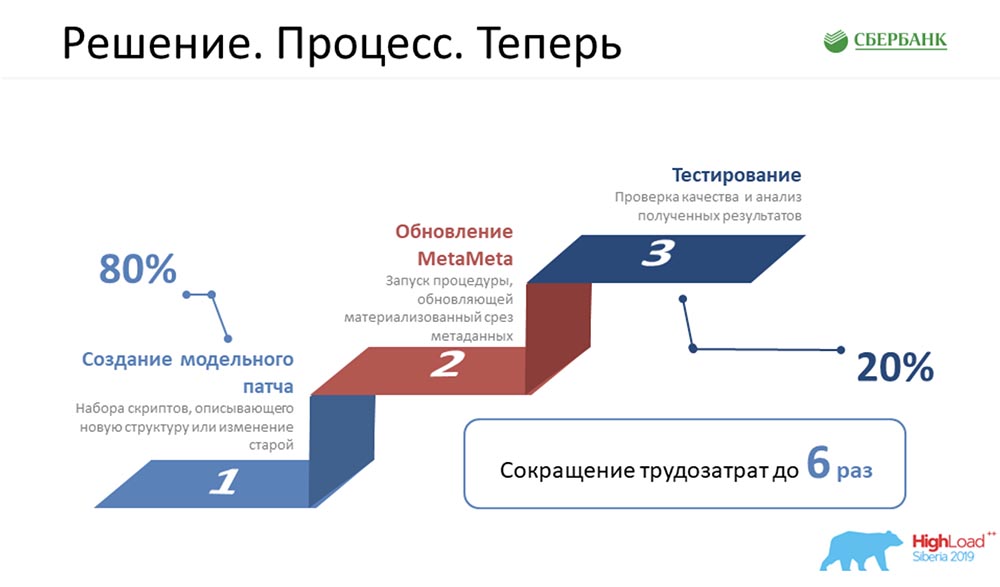
«МетаМета» у нас запускается по кнопке (обновление), затем тестирование. Мы пока смотрим, чтобы у нас ничего не отвалилось, поскольку мы совсем недавно начали применять этот подход. Стараемся весь этот процесс контролировать.
По подсчётам, все наши трудозатраты на разработку всего нашего обеспечения сократились в 6 раз.
СЦ: – От себя хочу искренне сказать, что цифра 6 – не дутая, она даже консервативная. На самом деле КПД ещё выше.
Планы на будущее
Ты просила в конце доклада остановиться на наших планах. В первую очередь видится, что мы должны достичь не просто законченного, а отчуждаемого и коробочного решения. Данные технологии могут быть применены где-то рядом, там, где это уместно. Хотелось бы добиться законченного продукта, который будет развиваться, и который мы сможем предлагать уже от имени «Сбербанка».
Конечно, если говорить о ближайших задачах, они все на слайдах отображены буллетами. Несмотря на ту оптимизацию, которую мы получили, всё равно нагрузка на команду достаточно серьёзная. Я не могу сказать с уверенностью, с какого квартала мы сможем перейти к реализации этих шагов.
Цифра 6 и тот кейс, который Настя привела – они честные. Это действительно было в пятницу, когда нам нужно было получать документы (самолёт, командировочные и прочее). У смежной команды в понедельник были назначены испытания, и нам нужно было выпустить этот патч, не подставить ребят. Сработало! Это реальный кейс.
Я был бы счастлив, если бы кому-нибудь из вас это могло бы пригодиться. Если будут какие-то вопросы – мы доступны. И после доклада тоже некоторое время здесь. Спрашивайте. Будем рады вам помочь!
АЦ: – Действительно, этот подход, я считаю, может начать использовать каждый. Необязательно в нашем виде (мы занимаемся управлением метаданными). Это может быть система управления чем угодно. Всё, что нужно иметь под рукой – реляционный взгляд на вещи, оттуда забрать метаданные, разбираться в каких-то шаблонизаторах и понимать какой-то из языков программирования (как это всё устроено).
Все эти инструменты есть в открытом доступе – можно уже начать гуглить и понимать, как ими пользоваться. Я уверена, что с их использованием ваша жизнь станет проще, лучше, и вообще освободится время для новых, амбициозных, классных задач. Спасибо!
Вопросы
Вопрос из аудитории (далее – А): – Я правильно понимаю, что у вас всё нагромождено из-за того, что вы используете реляционную БД? Мне кажется, если бы вы посмотрели в сторону документоориентированной БД, всё это решение у вас было бы гораздо проще, чем сейчас вижу.
СЦ: – Не совсем так. То, с чего мы начали, когда рассказывали про людей, работающих на уровне глоссария и того паука, который ходит на пром, читает эти истории и проверяет – действительно, та таблица с тем полем, которая отвечает за этот термин глоссария, имеет место на проме. От нашего сервиса говорили: «Ребята, у вас REST API должен быть. Как вы это сделаете – ваши проблемы. Вот список разрешённых технологий – используйте что-то из этого списка (это то, что мы можем в «Сбербанке» использовать)».
Это уровень нашей solution, прикладной архитектуры. Нам, наоборот, было легче сделать это не реляционке. Почему? Приведу пример, один из многих… Например, мне нужно обеспечить, когда я пишу поле, чтобы оно не ссылалось в никуда на таблицу, которая не существует. Я просто делаю foreign key в базе и не парюсь. Ни строчки не пишу – она мне не даст сделать эту запись. И таких примеров много!
Здесь скорее следует говорить о другом. Более сложная история: мы будем выпускать модельный патч с набором данных корректировка / сертификация, и там 6 объектов. И неизбежно, чтобы ты обеспечивал этот джентльменский набор API, нужно месяца три работы (навскидку). У нас на это уйдёт недели полторы. Не применяя эти технологии, просто было невозможно выжить в этих условиях. Мы просто не дали бы такой уровень сервиса!
Это возможно в том случае, если ты так построил производство, что у тебя есть модельный патч (новый объект), кнопка «Сделай всё хорошо» и какой-то софт, который в режиме эмуляции клиента протестирует. Заработало новое, не отвалилось старое – вот этого надо было достичь, а как – это уже выбор команды.

А: – У меня второй вопрос. А какой есть пример использования из жизни? Я понимаю, что теоретически это выглядит так, что можно хоть весь мир описать вашим META_META-объектом… А в жизни как применяете? Тормозить ведь должно, судя по тому, как оно реализовано (друг в друга всё вкладывается)!
СЦ: – Кстати, нет (на удивление)! Ещё одно применение этой истории – это кодогенераторы. Это там, где строятся какие-то витрины, хранилища, и ты ETL, все возможные варианты пытаешься припарковать к заранее описанным девяти шаблонам, девяти шаблонизаторам. С помощью метаданных описываешь эту трансформацию, используя эти шаблоны как заготовки. Дальше эта машина без программирования даёт ETL-код, генерит код на основе метаданных. Считаю, что там тоже такие технологии, подходы будут уместны и правильны.
А: – Я рассчитывал на более конкретный пример.
А: – Скажите, пожалуйста, у вас в требованиях было написано, что вам нужно сложно-структурные запросы делать (Join и тому подобное). На каком языке это реализовано, или как-то логически вы это описываете?
СЦ: – Обращение через REST API, чаще всего это Java, хотя это может быть любой язык. У нас сервис опубликован (dhttps, https спрашивай – тебе JSON вернётся). Те куски кода, который мы показали – это SQL. Для того чтобы понять, в каком порядке это обрабатывать, мы делали некоторую SQL-настройку над словарями СУБД и парковали это в отдельной схеме в виде материализованных представлений. Соответственно, когда выпускается модельный патч, нажимается кнопка «Обновить материализованное представление» (+ поля появляются). А реально наш код – Java и Oracle.
АЦ: – Здесь стоит заметить, что мы решили разделить зоны ответственности. Всю магию мы заведомо перенесли в ядро, а Application просто грамотно интерпретирует эти ответы. То есть сам механизм Join’а происходит в ядре, а Java просто грамотно раскидывает это всё по дереву и выдаёт пользователю конечный результат.
А: – А то, что делает Code Gens – туда вы уже записываете логику сложных запросов? Или это делается на стороне клиента? Надо понять, с какой стороны описывается… Представили, получается, Code Gen, на котором надо в какой-то структуре аккуратно описать: например, я хочу, чтобы у меня API изучал такой-то Join, пройти по списку; потом сказать, есть ли там внутри или нет… – сложные достаточно запросы. На каком этапе это пишется?
СЦ: – Если я правильно понял ваш вопрос, это как раз та история, когда наши клиенты, наши заказчики (это команда внутри ядра, платформы) говорят: «Слушай, не хотим программировать – дайм нам вот это». «Вот это» делалось всё в ядре. Ядро – по сути что? Процентов 80, может, 90 – это генерация динамического кода, того текста, который будет из-под PL/SQL вызвано, но обращено к базе. Там даже по времени дольше генерируется эта строка, потом происходит обращение к базе (например, запрос Join), возвращает, заворачивает это в JSON, выдаёт в перевёрнутом виде. Далее Java всё это трансформирует в контракт, который зависит от структуры.
А: – Показали решение пакетного обновления. А как производится гарантия доставки – пришёл ли целостный пакет, или часть пакета? Они имеют определённый кахерианс? И как сделать так, чтобы ни сервис не упал, ни структуры данных не имели какую-то связанность, чтобы не было каких-то ошибок?
СЦ: – У нас протокол есть – там два режима обновления. В одном из них ты можешь выставить флаг «Примени всё, что сможешь». Есть некий софт, который Excel преобразует в JSON – там может быть 10 тысяч строк. И у тебя, строго говоря, две строки могут быть невалидны (ошибка). И либо ты говоришь: «Примени всё, что сможешь»; либо «Примени только в случае, если вся эта история не будет иметь ни одной ошибки». Там интегральный статус будет rollback, например. Фактически происходит вставка в базу, но commit не вызывается.
В случае если ошибка – он rollback вызывает, он в протоколе; ты в любом случае получаешь протокол. Ты получаешь статус по каждой строке, и у тебя отдельным полем идёт идентификатор – или число (id объекта), или какой-то альтернативный ключ, или и то и другое. Протокол даёт возможность понять, что произошло с моей просьбой.
АЦ: – Пользователь сам указывает, в каком из вариантов ему двигаться. Мы этот параметр передаём на сторону ядра, и ядро уже производит всю магию, выдаёт нам ответ, а мы его интерпретируем.
А: – Почему не использовали какую-либо встроенный компилятор выражений, который помогал бы определить правило? Допустим, у нас есть шаблон, я на каком-то языке (типизированный / не типизированный язык сценария) веду блог; написал: «Хочу список». Передал этот фрагмент, чтобы какой-то обработчик кода всё это прожевал, сложил это в NoSQL-базу, как это предлагали в первом вопросе… Всё-таки непонятно, зачем реляционная база данных и почему и как бороться с избыточностью данных? Присылает вам человек шаблон с миллиардом мусора… Как эти договорённости достигаются, когда человеку надо?

СЦ: – Попробую ответить так, как я понял вопрос. С нами общаются сейчас большей частью программы. Когда настраивается механизм интеграционного взаимодействия, с нами общаются не столько люди, сколько программы. Есть, конечно, кейсы, когда люди присылают а-ля эксельники для первичной проливки: мы из них делаем JSON’ы, прогружаем, но это скорее первичная настройка.
И у нас есть режим, когда ты послал 5000 строк, из них 4900 вернулось со статусом «Я обработала, изменений не нашла, ничего не сделала». Но в протоколе это отражено и ошибки нет. Это с одной стороны избыточность.
У нас вся эта история хранится в приближённой к третьей, нормальной форме, которая как раз не предполагает избыточности, в отличие от каких-то денормализованных структур, которые используются, например, для витрин.
Почему реляционка? На нас работают кодогенераторы, и очень высока чувствительность к качеству метаданных в системе. И когда мы имеем возможность с помощью реляционки настроить foreign key и обеспечить… Запись просто не ляжет – будет ошибка, если в системе что-то не то, если произошёл сбой. И мы хотим, но не ищем себе дополнительной работы…
Нас измеряют не потому, сколько строк кода мы написали: «Вы решили вопрос сервиса и его стабильности или нет?» Можете вообще не писать – главное, чтобы оно работало. В этом смысле нам было просто быстрее и удобнее сделать так.
Я не беру конкретного вендор, но ведь реляционные базы развиваются уже 20 лет! Это же не просто так. Возьмите, например программу Word или Excel в Windows – вы там не программируете код, который с помощью «Ассемблера» обращается и двигает головки винчестера, чтобы записать файл… Так же и здесь! Мы просто использовали те наработки, которые в RDBMS были, и это было удобно.
АЦ: – Чтобы обеспечить все наши требования, для нас важна была именно целостность метаданных. И здесь мы, наверное, ещё хотели донести, что вообще не надо цепляться – реляционку мы используем, не реляционку… Суть доклада в том, что вы тоже можете начать использовать. Необязательно на реляционной базе, потому что наверняка у других тоже есть какие-то метаданные, которые можно собрать: как минимум, какие есть таблицы, поля, и это всё запрограммировать.
А: – Система предполагает какое-то использование. Как вы планируете (или уже сделали) поставку данных в вашу систему? Понятно, что на продуктовую идёт какое-то обновление структуры данных. Как это всё приходит к вам? Автоматически, либо агент ваш стоит, либо нагибаете все команды разработчиков, чтобы вам поступали обновления?
АЦ: – У нас есть два режима работы. Один – это когда сами разработчики или команды вынуждены нам пулять через REST-сервисы метаданные в систему. Второй режим работы – этот тот самый «пылесос»: мы сами заходим в среду и забираем оттуда все возможные метаданные. Мы это делаем раз в сутки, и как раз сверяемся с тем, что нам отправили разработчики.

СЦ: – Из тех четырёх уровней, которые мы рассмотрели, три верхних уровня (глоссарий, логические модели, физмодели) – это та история, которая по умолчанию в режиме Metadata Broker заходит к нам, а мы – пассивный участник. Нас вызывают, нам передают что-то, спрашивают; наша задача – припарковать в согласованном виде. Хотя есть кейсы, когда мы ресурсами команды какие-то истории настраиваем, если сильно заинтересованы в том, чтобы эти метаданные у нас появились.
Как Настя сказала, касательно истории с реверсом (на техническом жаргоне называем «пылесосом»), мы ходим в промсреду и читаем какие-то данные. Там разные кейсы – мы готовы потом обсудить, мы готовы рассказать много интересных историй.
А: – Я из центра финансовых технологий. Увидел там знакомое слово – main DACUM. В нашей платформе есть свои метаданные. Вы как дружите – непосредственно с таблицами «Оракла» или с нашими метаданными в этом случае? Потому что в нашем случае дружить с таблицами «Оракла» – это не совсем показательно.
СЦ: – Есть такая таблица main DACUM, которая содержит проводки. Это не секрет: были и есть продукты, которые работают на этой истории. Это одни из источников информации в хранилище. Есть какая-то система, которая является поставщиком данных. Естественно, она в фокусе нашего внимания с точки зрения метаданных, потому что одна из историй, которую мы должны показать и вообще не коснулись здесь (в силу темы доклада) – это Data lineage. Вы должны показать, откуда происходит история данных этого поля. В этом смысле, если имеется таблица main DACUM, мы о ней знаем.
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас:Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Комментариев нет:
Отправить комментарий