Coderik однажды отметил: "Фильтра Калмана много не бывает". Так же можно сказать и о теореме Байеса, ведь это с одной стороны так просто, но с другой стороны так сложно осмыслить его глубину.

На просторах YouTube есть замечательный канал Student Dave, однако последнее видео опубликовано шесть лет назад. На канале представлены обучающие видео в которых автор рассказывает очень простым языком сложные вещи: теорему Байеса, фильтр Калмана и пр. Свой рассказ студент Дейв дополняет примером расчета в matlab.
Однажды мне очень помог его видео урок под названием “Итеративная байесовская оценка” (на канале ему соответствует плейлист “Iterative bayesian estimation: with MATLAB”). Я захотел чтобы каждый мог познакомится с объяснениями Дейва, но к сожалению проект не поддерживается. Сам Дейв не выходит на связь. Добавить перевод к видео нельзя, так как это должен инициировать сам автор. Обращение в youtube не дало результата, поэтому я решил описать материал в статье на русском языке и опубликовать там, где его больше всего оценят. Материал очень сильно переработан и дополнен, так как он прошёл через мое субъективное восприятие, поэтому выложить его как перевод было бы неуместно. Но саму соль объяснения я взял у Дейва. Его код я переписал на python, так как я сам в нем работаю и считаю хорошей заменой математическим пакетам.
Итак, если вы хотите глубже осмыслить тему теоремы Байеса, добро пожаловать.
Для того чтобы проиллюстрировать мощь теоремы Байеса для непрерывных случайных величин, Дейв предлагает рассмотреть задачу “байесовского ниндзя”. Суть задачи в следующем.

Есть ниндзя-математик, который очень не любит перепелов. Перепел прячется в кустах, а ниндзя сидит на дереве рядом. Ниндзя может одним решительным прыжком на перепела сразить его, но он не знает где точно находится перепел. При этом перепел и издает время от времени звук. По звуку ниндзя может определить местоположение перепела, но очень неточно. Теорема Байеса позволяет ниндзя по серии криков перепела определить местоположение перепела все точнее и точнее. И в какой-то момент количество криков позволит ниндзя нанести сокрушительный удар.
Если вы ознакомитесь с видео на канале, то узнаете, что ниндзя так и не удалось удачно спрыгнуть на перепела, но это уже другая история.
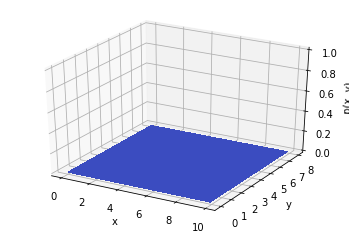
Ниндзя-математик видит кусты как ограниченную область по оси . Истинное положение перепелки пока неизвестно. Вероятность в каждой точке области поиска одна и та же. Априорное распределение равномерное.

В процессе наблюдения (ниндзя славились свое выдержкой) были получены замеров (гипотез) местонахождения.
К тому же ниндзя замерил дисперсию измерения положения перепелки по крику .
Благодаря теореме Байеса есть возможность из равномерного распределения получить нормальное, да и с дисперсией куда меньшей чем дисперсия измерения.
Теорема Байеса
где — уточненное распределение;
— распределение известное до опыта;
— распределение модели измерения (правдоподобие ).
Дисперсия распределения модели измерения известна ниндзя заранее. За математическое ожидание принимается точка пространства, а за случайную величину замер (вероятность гипотезы о том, что в этой точке пространства сидит перепелка при получении замера):
где — функция плотности нормального распределения;
— математическое ожидание;
— стандартное отклонение измерения;
— измеренная величина.
Данную формулу необходимо повторить для серии опытов (), каждый раз подставляя вместо априорного распределение апостериорное, которые было получено при предыдущем опыте.
На анимации ниже видно как меняется распределение от оценки к оценке.
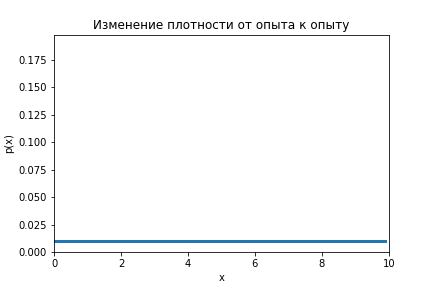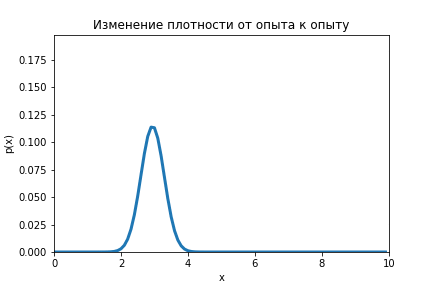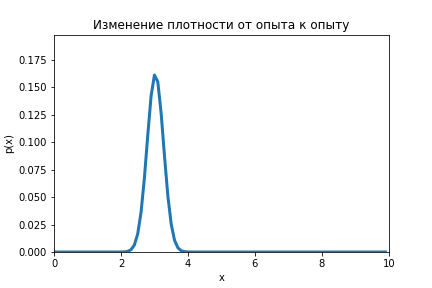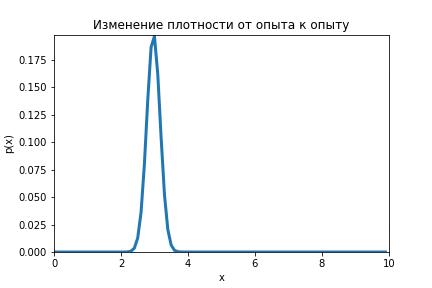
Код по ссылке.
Как только шесть уменьшаться до размера ноги ниндзя, он сможет нанести свой сокрушительный удар с вероятностью успеха в 99,7 %.
Так-то именно двумерный случай рассмотрен Дейвом, в отличие от одномерного случая.
Рассмотрим более реальную задачу. Ведь ниндзя всё таки смотрит на кусты сверху-вниз.
Истинное положение перепелки . Дисперсии (ковариационная матрица) и количество криков те же.
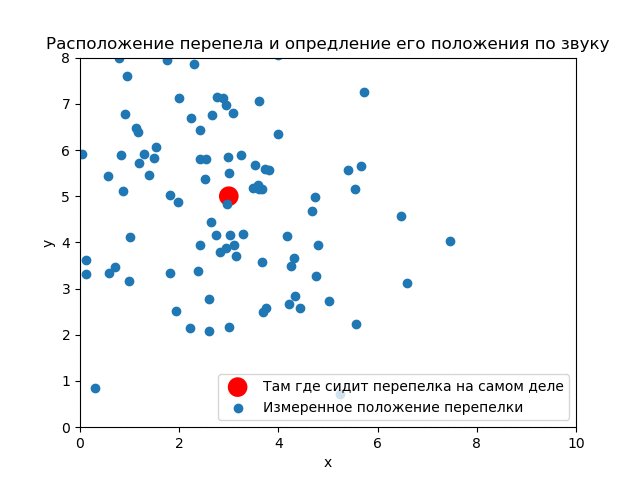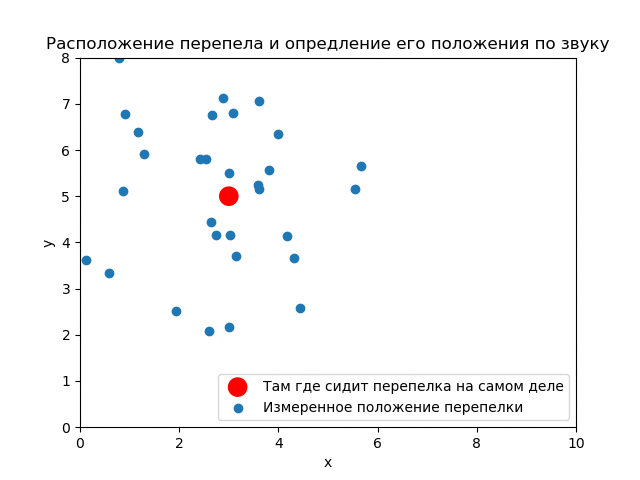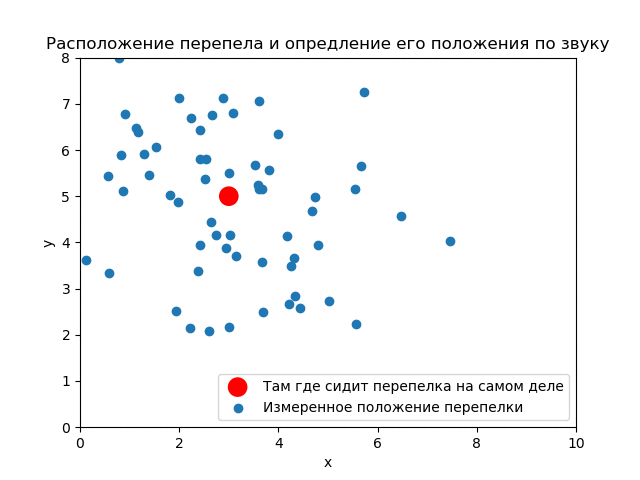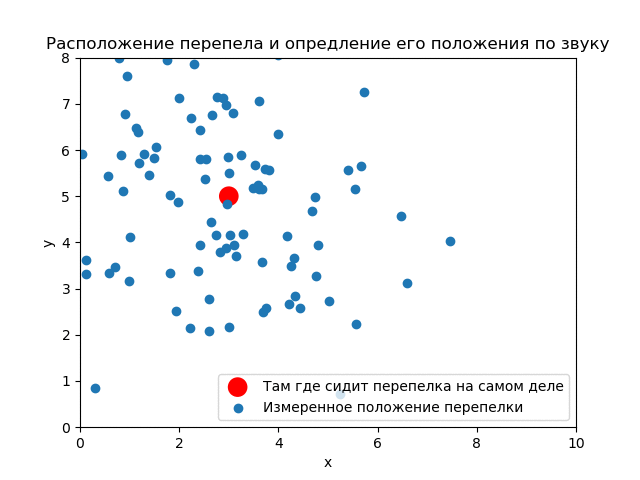
До опыта (априори) вероятность того, что перепелка будет в любом месте кустов одинакова. Априорное распределение равномерное.
Формула Байеса для непрерывных многомерных случайных величин примет вид:
где — вектор координат вида ;
— уточненное распределение;
— распределение известное до опыта;
— распределение модели измерения.
Распределение модели измерения:
где — ковариационная матрица;
— результат замера вида .
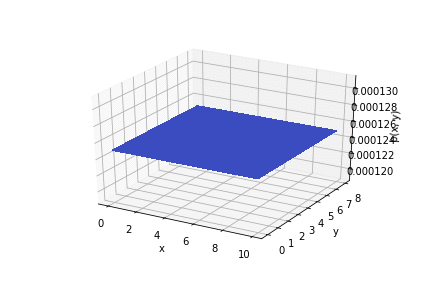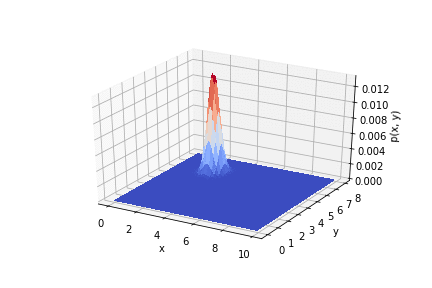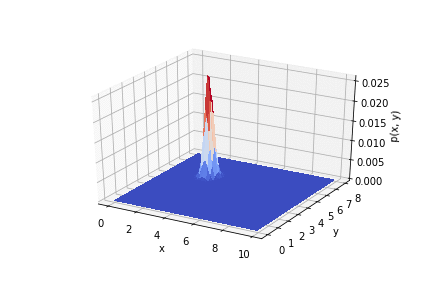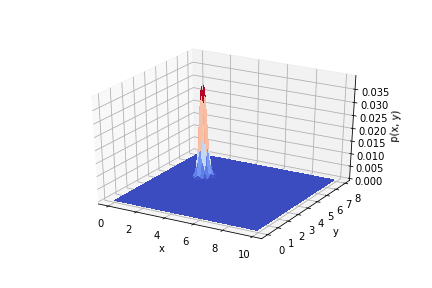
На анимации ниже видно, как меняется распределение от опыта к опыту.
Код по ссылке.
Таким образом видно, как результаты опыта влияют на априорное распределение.
Теорема Байеса очень необычная. Ты вроде её понял, но она не устает удивлять тебя своими применениями.
Заходите на канал Дейва в течении этих недель самоизоляции. Всем добра.
Комментариев нет:
Отправить комментарий