— Сергей Бережной veged уже несколько раз поднимал эту тему и рассказывал про тестирование в Поиске. Вот ссылки на доклады в 2016-м и 2017-м. Многое из того, что он тогда рассказывал, де-факто стало стандартом для большинства компаний. Но несмотря на это, все еще остаются вещи, которые пока нигде особо не применяются. Именно на них я и сосредоточусь.
Чтобы не отставать от хайпа, будем говорить об этом на примере колдунщика карты коронавируса на серпе, то есть в результатах поисковой выдачи.
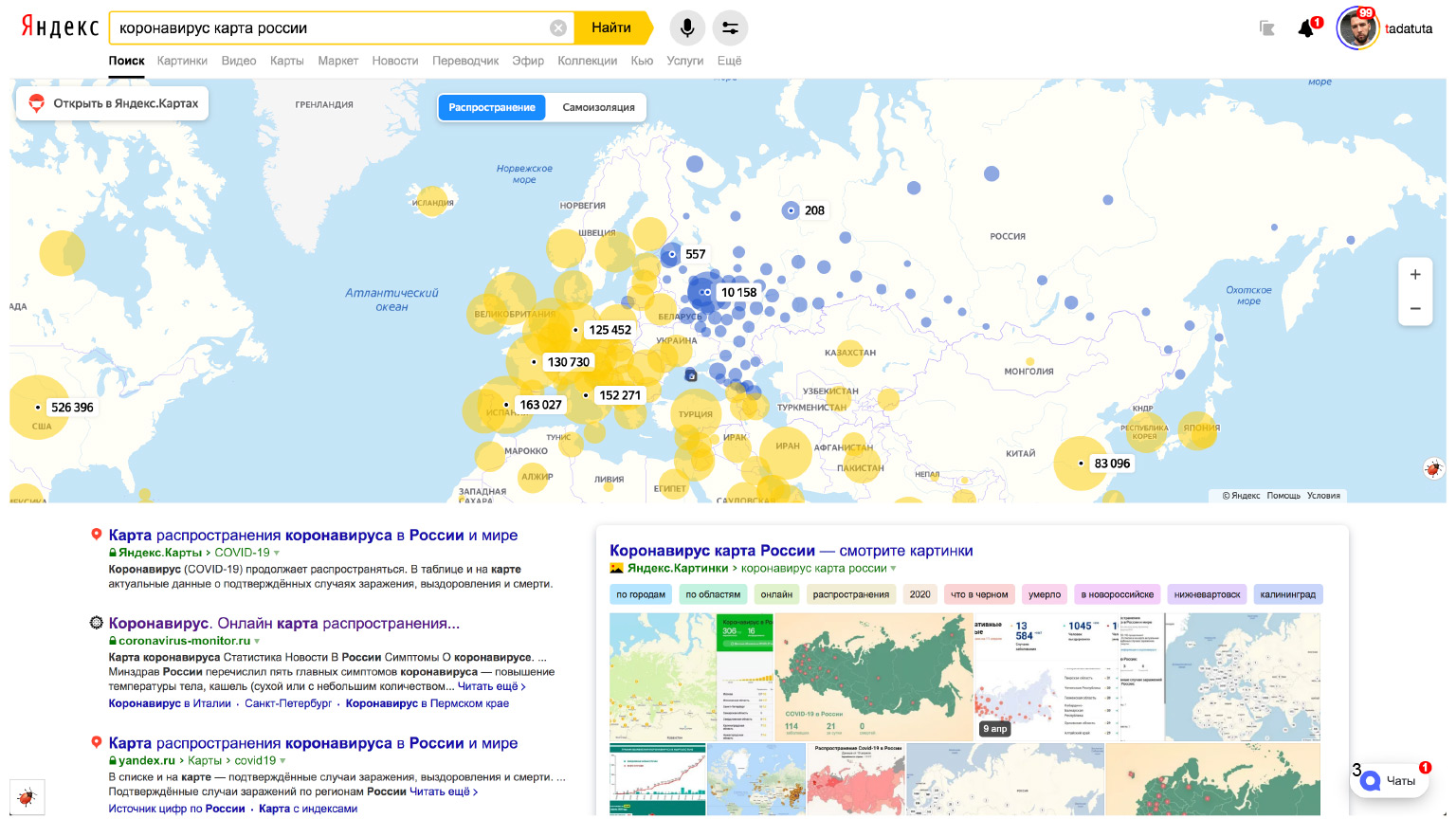
Если ввести запрос [коронавирус карта России], помимо привычных результатов поиска мы увидим сверху такую большую красивую карту.
Давайте проследим, как выглядит flow разработки такой фичи.
Задача появляется в трекере, где описано, как все должно выглядеть. Дальше разработчик пишет код, самостоятельно его тестирует. И если ему кажется, что все хорошо, то он открывает пул-реквест. Затем, пока коллеги ревьюируют его код, роботы начинают искать, как же унизить человека.

Самое унизительное — это падение линтеров. Но в данном случае разработчик молодец. Если заглянуть внутрь, мы видим, что все проверки прошли успешно.

Что проверяют линтеры? В первую очередь, они могут проверять стили. Например, с помощью eslint или stylelint. Есть еще множество разных проверок, которые могут выполняться с помощью линтеров. Это все очевидно, на этом нет смысла останавливаться. Пойдем дальше.

Какие еще бывают проверки? Например, мы можем посмотреть на юнит-тесты. Классическая пирамида тестирования. Мы в самом низу делаем как можно больше простых юнит-тестов. Они самые дешевые, никак не связаны с данными. Они убеждаются, что каждый кирпичик нашей функциональности работает, как ожидалось.

Заглядываем внутрь. Здесь тоже все хорошо. Здесь мы проверяем, что JS-функциональность в порядке.

Но, понятное дело, недостаточно убедиться, что JavaScript хорошо отработал. Важно проверить, что в каждом браузере не разъехалась верстка, что мы нигде не потеряли ничего в стилях и т. д.
Для этого нам помогут функциональные тесты, которые мы пишем с помощью опенсорсного решения, которое случилось в Яндексе, — Hermione. Hermione позволяет явно сказать: перейди на такую-то страницу, найди такой-то компонент, кликни по нему, посмотри, что произошло. Но помимо этого она позволяет сравнивать скриншоты. Здесь мы видим, что такие проверки есть на десктопе, планшетах и телефонах.
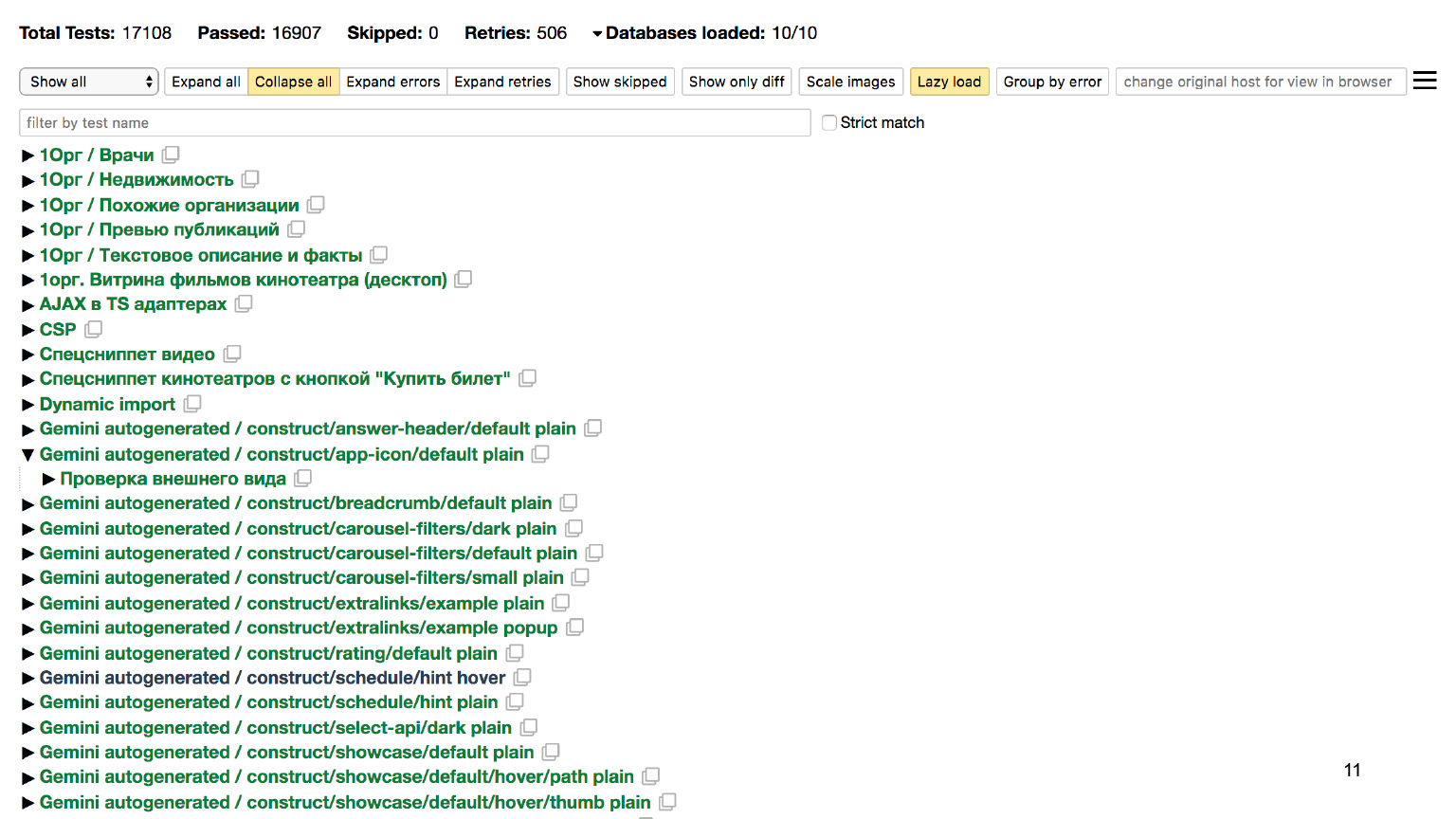
Если пойти глубже и посмотреть на отчет, видно, что только для десктопа мы проверили более 17 тысяч разных сценариев и убедились, что все в порядке.
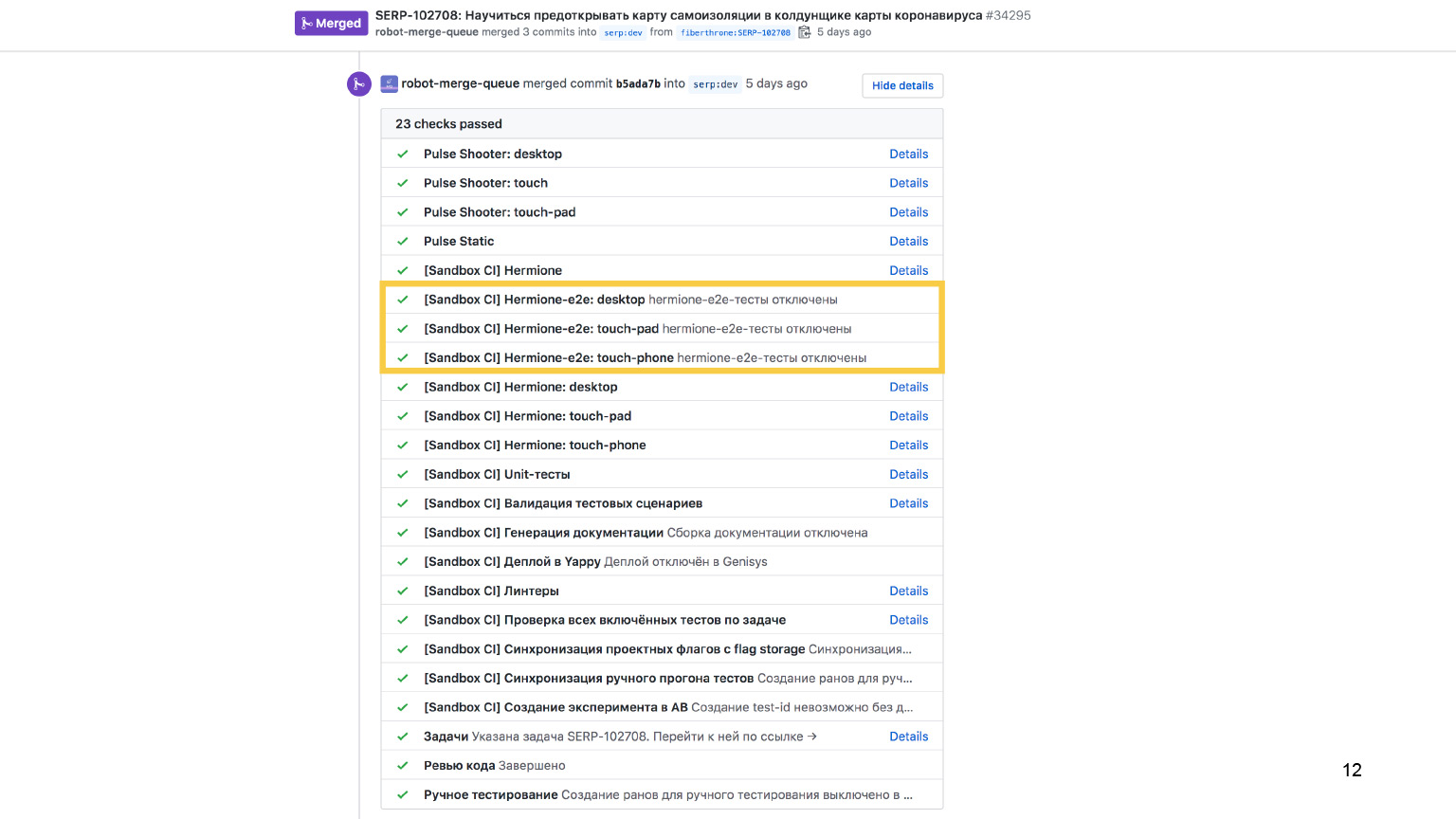
Окей, идем дальше. Помимо проверки юнит-кусочков верстки, мы еще должны на каком-то этапе убедиться, что и связка верстки с данными, с бекэндом, тоже в порядке. Проверки могут быть ровно такие же: мы можем с помощью тестов на Hermione проверить и эту часть. Здесь видно, что для всех трех платформ есть e2e-тесты.
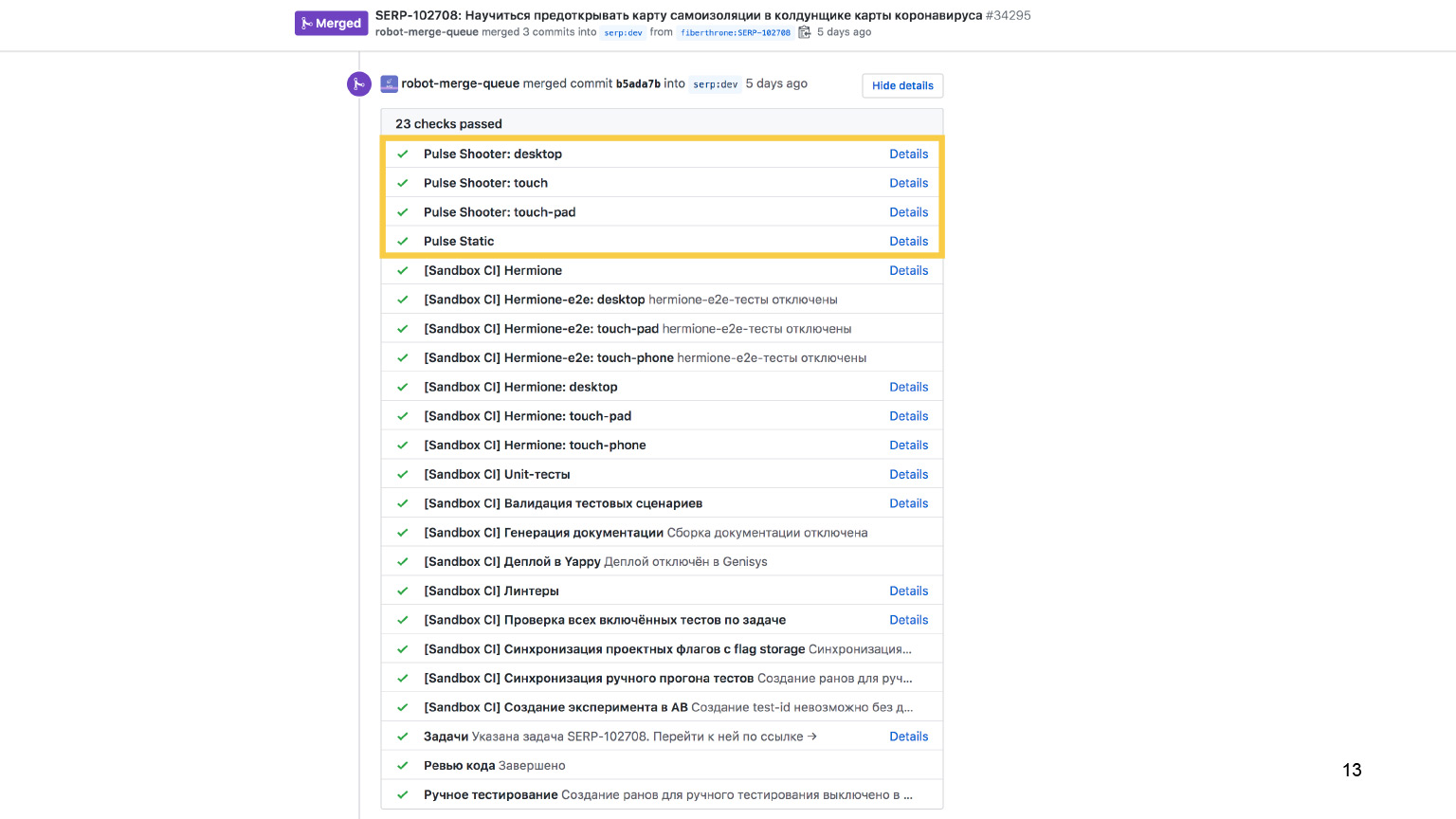
Есть еще целая куча метрик. Из интересного — проверки на скорость. Вообще, скорость — один из достаточно важных показателей качества продукта. Если интерфейс медленный, он отталкивает пользователей ничуть не меньше, чем интерфейс, в котором есть баги.
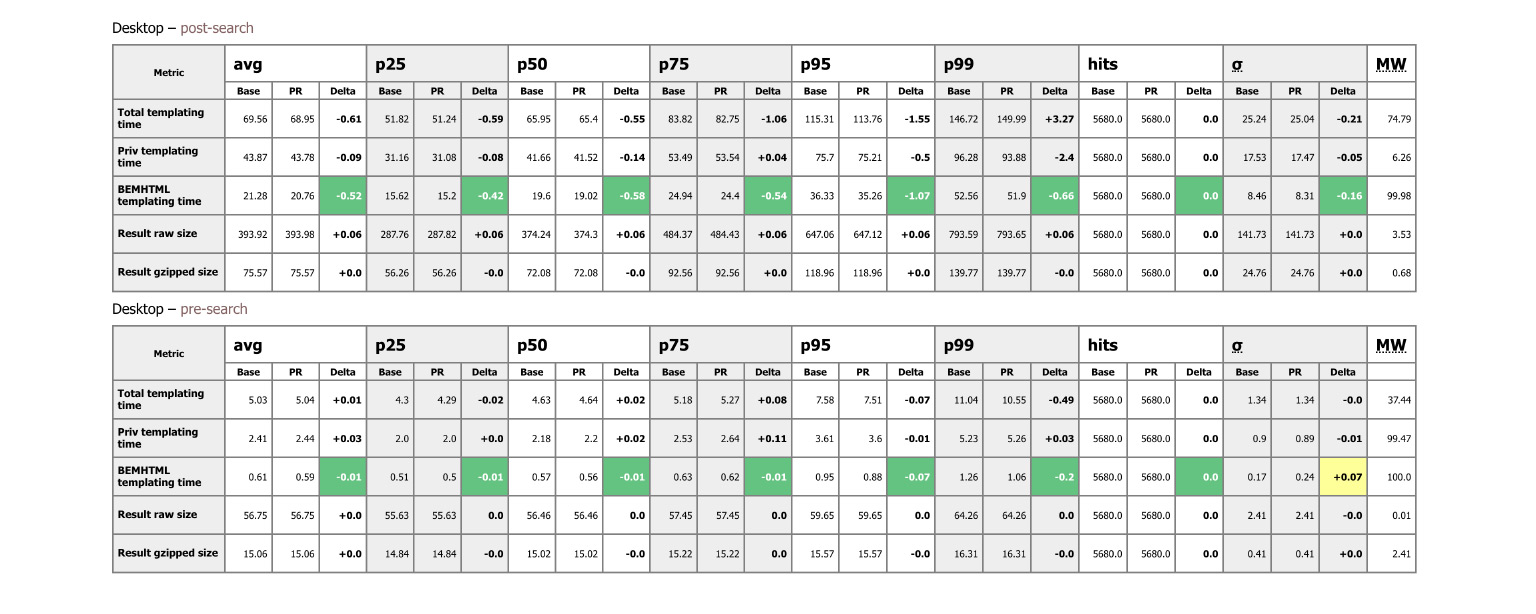
Внося любое изменение в кодовую базу, мы проверяем целую кучу параметров, чтобы убедиться, что интерфейс по-прежнему достаточно быстрый, что мы этими изменениями не замедлились.
Обо всем этом подробно рассказывал Андрей Прокопюк в нескольких докладах: 1, 2. Очень рекомендую их посмотреть, потому что там огромный внутренний мир, история о том, как правильно проверять скорость ваших интерфейсов.

Но мы идем дальше. Пока роботы выполняли свое дело, коллеги успели прочитать и одобрить код. Наверное, можно считать, что теперь-то точно все хорошо? Мы проверили прямо со всех сторон, рассмотрели под всеми углами. Люди тоже перепроверили, что там ничего не было упущено. Наверное, можно катить в продакшен.
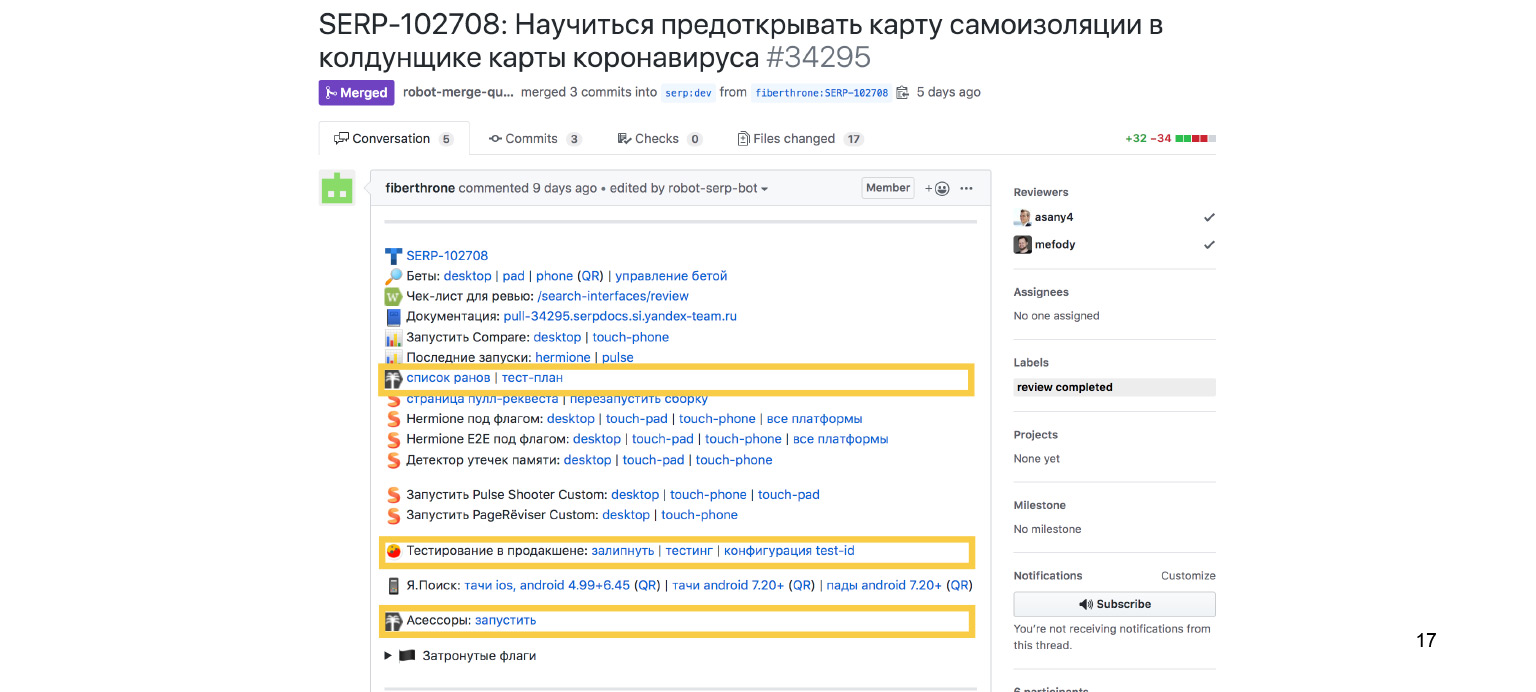
На самом деле, конечно, нет: если мы отскроллим наш пул-реквест наверх, то обнаружим здесь еще несколько интересных пунктов. Если конкретно, нас интересуют вот эти. Они связаны с ручным тестированием. Вы можете спросить: как же так? Почему в докладе обещали рассказать про автоматизацию, перечислили очевидные вещи, а теперь вдруг говорят про необходимость ручного тестирования?
Именно в автоматизации ручного тестирования, как бы странно это ни звучало, вся соль доклада.
Прежде чем погрузиться в это, рассмотрим ответ на вопрос, зачем нам то самое ручное тестирование, когда все покрыто автоматическими проверками? Дело в том, что покрыть абсолютно все аспекты очень сложно. Потому что браузеров очень много, потому что они работают на разных операционных системах. И существует огромное количество самых разных устройств, на которых эти операционные системы с браузерами запускаются.
При этом люди пользуются всеми этими устройствами в достаточно разных условиях. Кто-то спокойно сидит дома на диване и не спеша рассматривает веб-странички. Кто-то на бегу, в метро пытается что-то быстренько сделать. Кто-то за прекрасным огромным дизайнерским дисплеем, кто-то, наоборот, за супермаленьким дешевым монитором и т. д. Еще у всех пользователей совершенно разные навыки. Люди по-разному воспринимают одни и те же интерфейсы. Понятно, что мы никогда не сможем покрыть все это многообразие автоматическими тестами.
Поэтому мы сталкиваемся с вопросом — как же все-таки вручную протестировать гигантский проект, где многие тысячи проверок? И как это сделать во всех этих окружениях при том, что есть жесткое требование — необходимо выкатывать релиз каждый день?
Давайте подумаем, как в принципе прокликать все это огромное количество тест-кейсов и ничего не забыть? Как избавиться от человеческого фактора? Как убедиться, что тестировщик действительно все эти кейсы помнит? Он ведь мог где-то срезать: подумать, что изменение не затрагивает часть функциональности, и просто туда не посмотреть. Как убедиться, что он так не поступит?
Наверняка многие догадались, что для этого нам потребуется Test Management System. У нас есть свое решение, оно называется TestPalm.

Что в ней видно? У нас есть список проектов.
Открываем проект интерфейсов Поиска.
Находим все тест-кейсы, которые затрагивают тот самый колдунщик коронавируса, и смотрим на конкретный кейс.
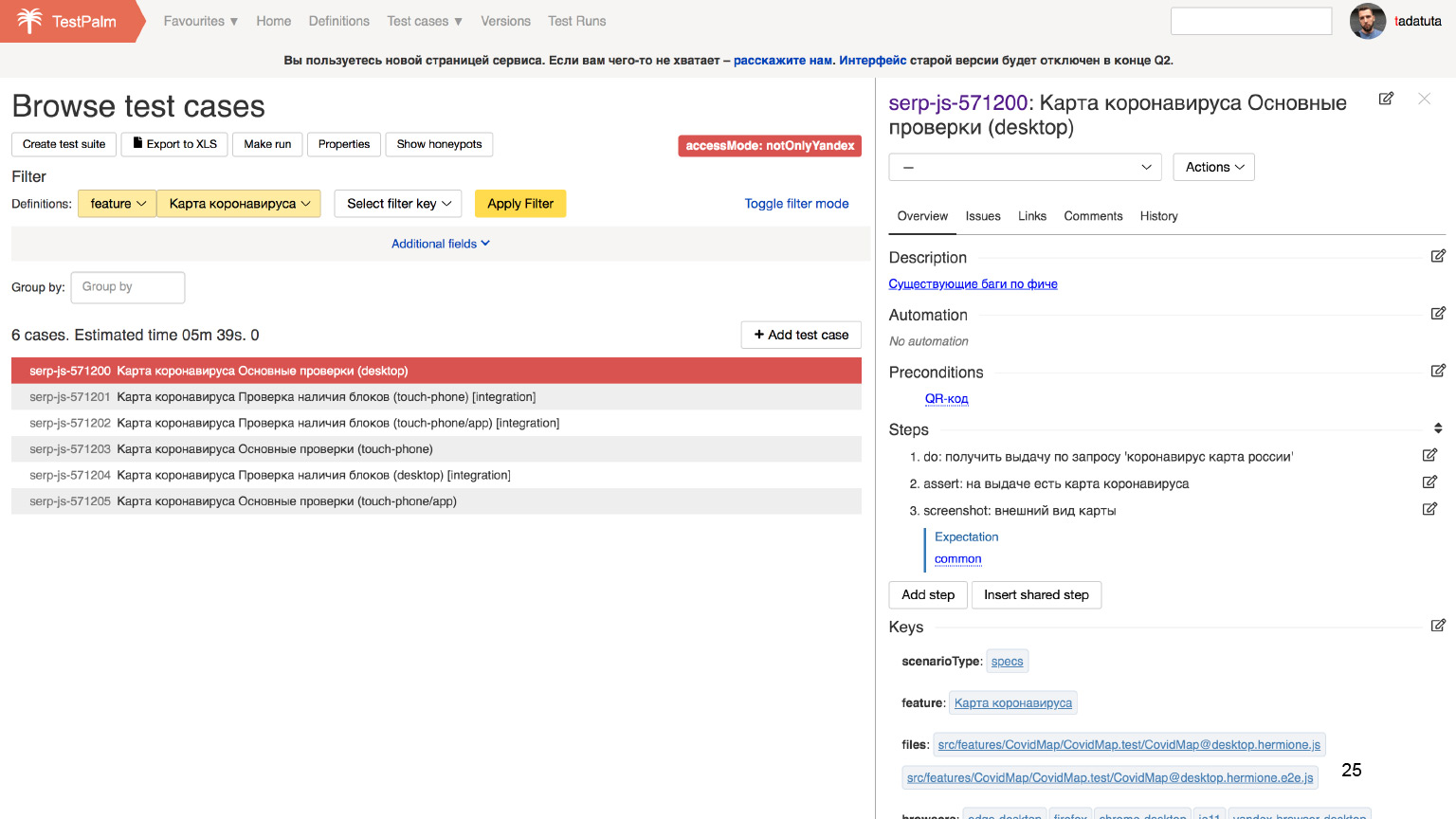
Здесь видны шаги, которые нужно проделать, чтобы убедиться, что этот кейс выполняется.
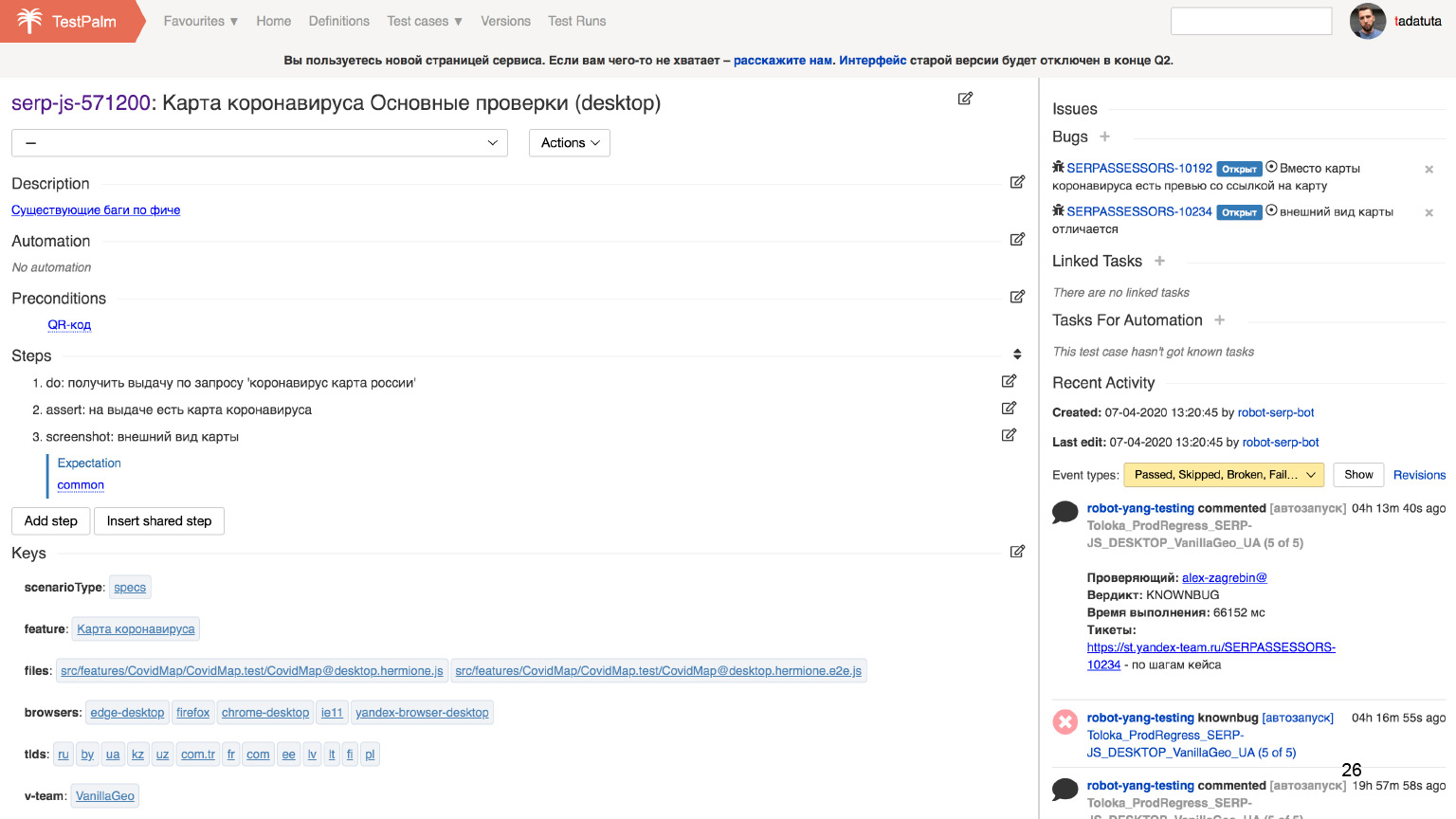
Предположим, мы хотим провести тестирование либо конкретной фичи, либо всех фич. Все, что нам нужно сделать, — открыть эти списки тест-кейсов и выполнять каждый шаг один за другим: поставить галочку, что все хорошо. Либо, если что-то пошло не так, из этой же системы мы сразу можем завести связанный баг, и разработчик сможет его починить.
Казалось бы, в этом смысле проблема решается. Мы избавляемся от человеческого фактора и успеваем все протестировать. Но если мы будем просто хранить тест-кейсы в отдельной системе, то пока код продолжает каждый день меняться, мы рискуем оказаться в ситуации, когда тест-кейсы рассматривают нечто сильно отличающееся от продукта.
Чтобы решить эту проблему, мы пользуемся подходом, про который несколько лет назад рассказывал Серёга, говоря о том, как обеспечить свежесть тестов и гарантировать, что они проверяют именно свежий код.
Делается это просто. Нам всего лишь нужно хранить все эти тесты рядом с кодом. Окей, в случае с тестами всё очевидно и все так делают. Что же делать с тест-кейсами, которые должны храниться в отдельной системе? Ровно то же самое. Выглядит это примерно так.
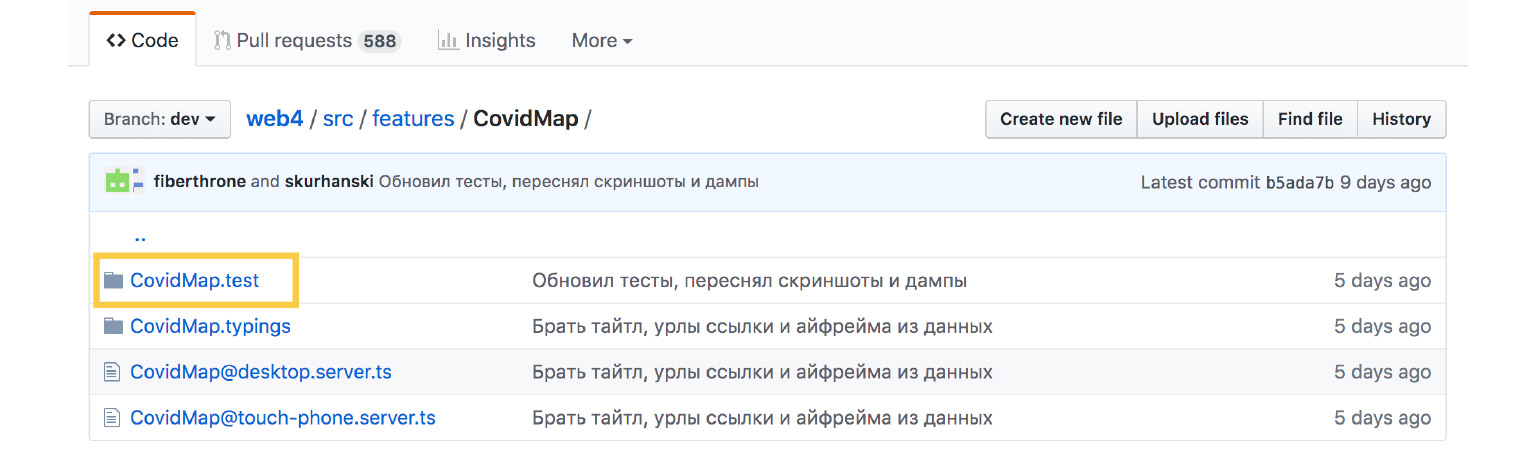
Вот папка с колдунщиком карты коронавируса. Здесь есть папка CovidMap.test.
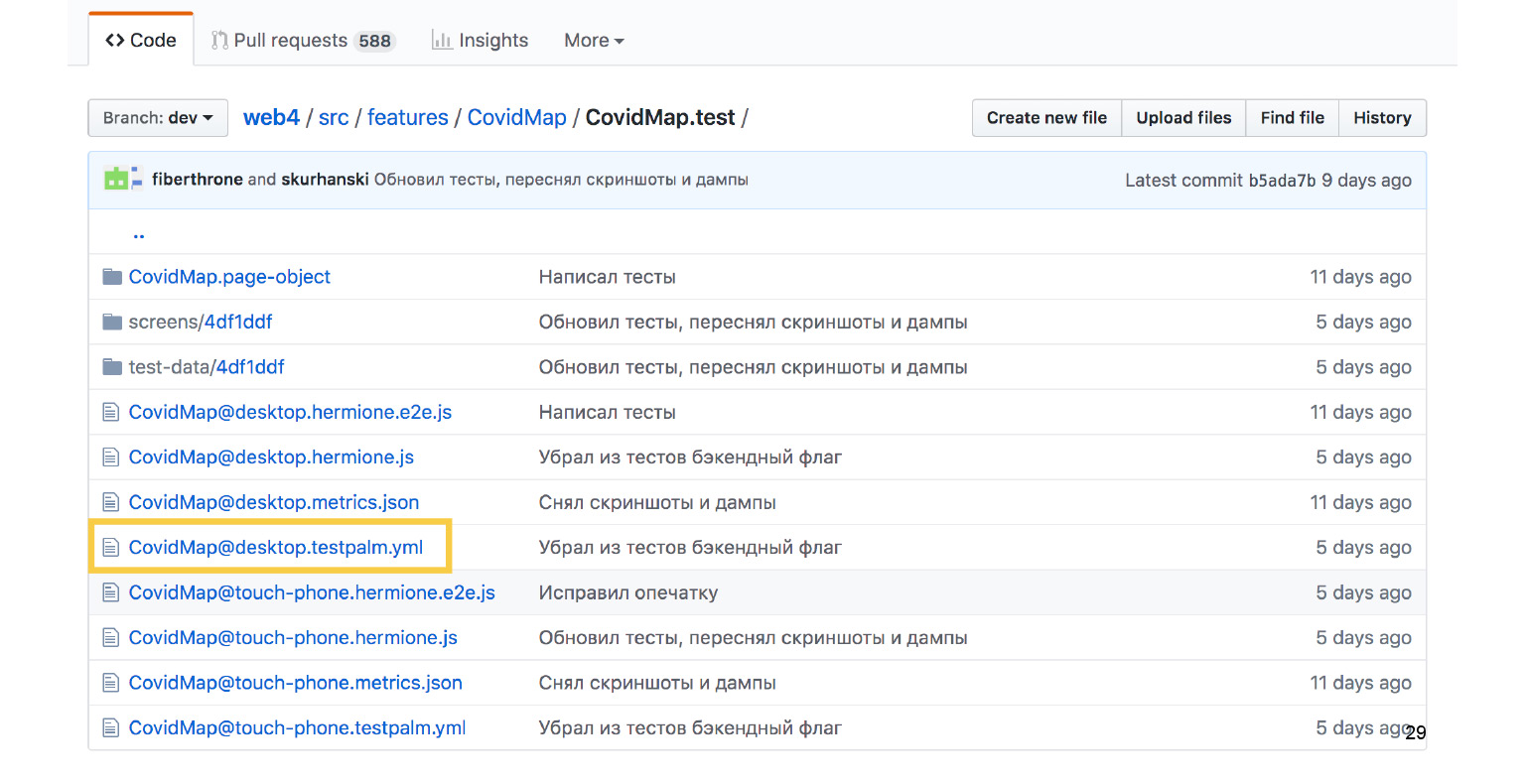
Внизу лежит куча файлов. Нас в первую очередь интересует файлик под названием testpalm.yml.
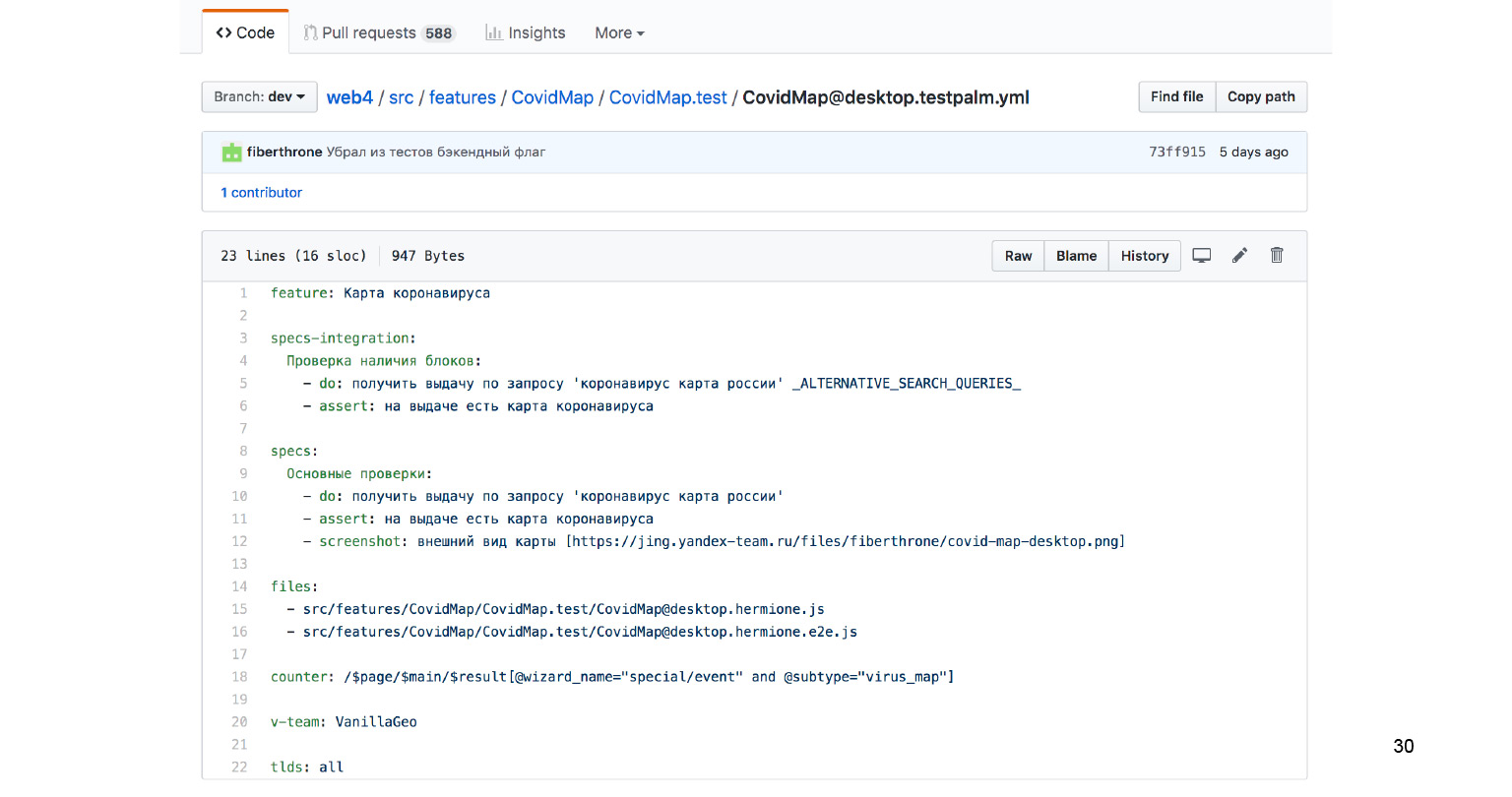
Этот файл описывает в достаточно человекочитаемом формате, что же нужно сделать, чтобы пройти сценарий.
Давайте еще ближе посмотрим на этот текст — он достаточно важный в этом рассказе.
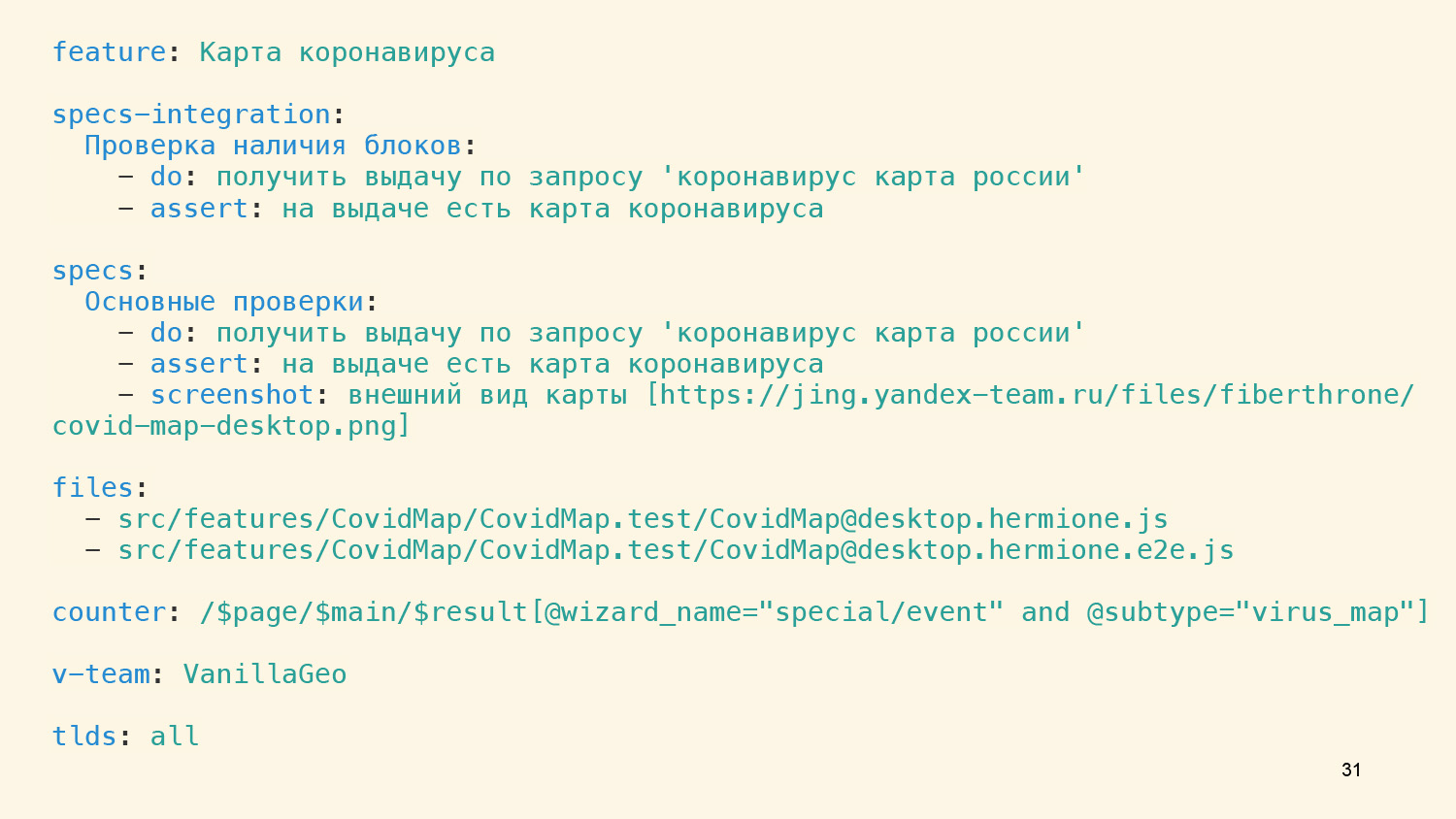
В первую очередь мы здесь говорим, что эта фича называется «Карта коронавируса», и у нас есть два типа проверок — интеграционная и функциональная, атомарная, не завязанная на данные.
В случае с интеграционной мы можем проверить только то, что при вводе определенного запроса фича действительно появилась. Больше ничего проверить не удастся, потому что данные постоянно меняются. Если мы захотим глубже проверять, что все хорошо, то при первом же изменении данных тест протухнет.
Но во втором случае с проверкой на замоканных данных такой проблемы нет. У нас есть возможность проверять скриншот и видеть полное совпадение, что мы и делаем. Там появляется третье поле, указывающее ссылку на нужный скриншот.
Есть еще несколько служебных полей, и в поле files важно, что мы связываем это описанное человеческим языком поведение с файлами автотестов.
Таким образом, дальше мы на этапе валидации тестового сценария и самих файлов тестов можем убедиться, что шаги один в один соответствуют тому, что мы тестируем автоматически. Тогда есть гарантия, что описание остается свежим.
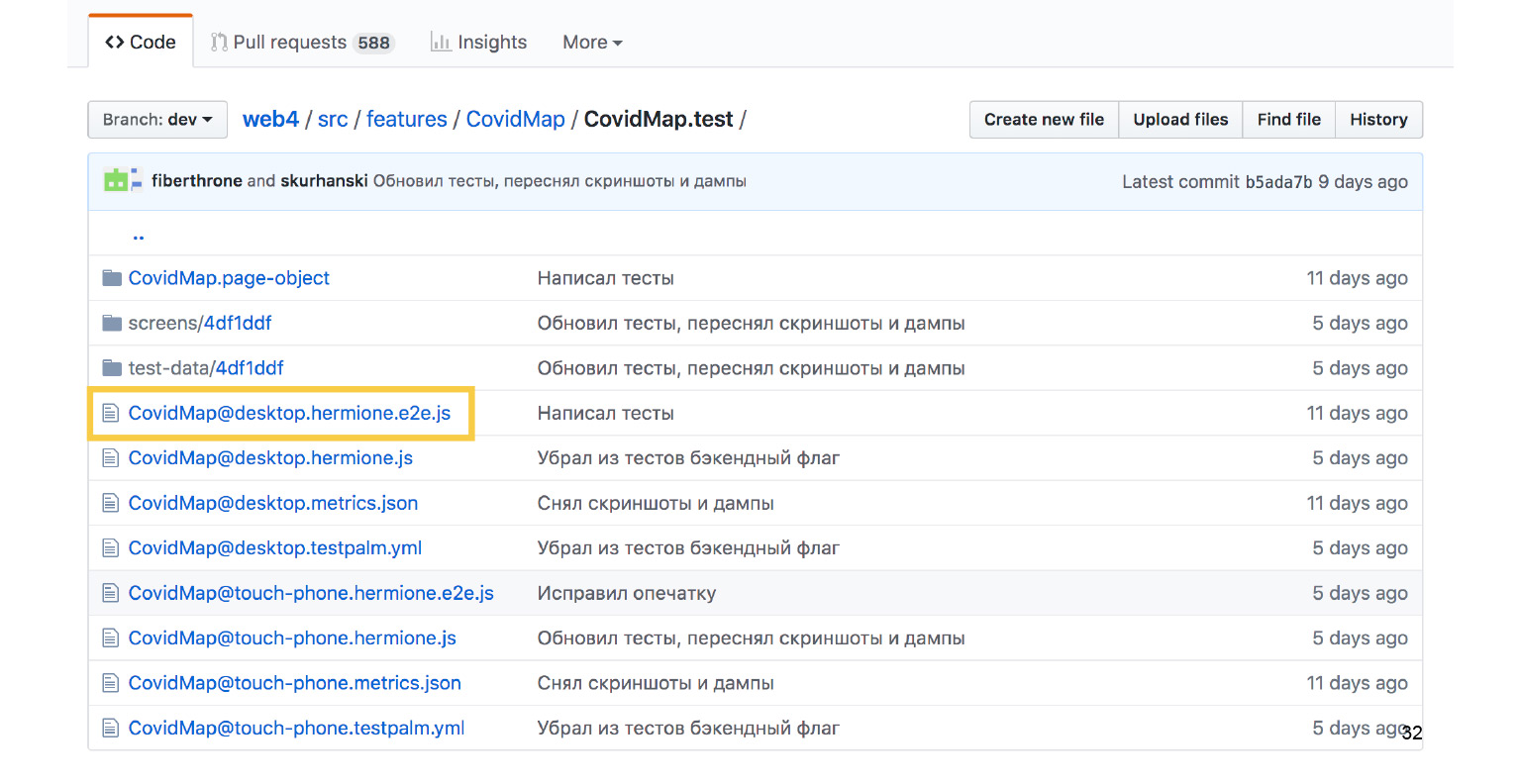
Файлы, на которые мы ссылались из testpalm.yml, находятся здесь же, рядом. Это Hermione.e2e.js с e2e-тестами.

Выглядят они вот так. Действительно, мы для этой же самой фичи проверяем наличие блока.

И точно так же мы храним рядом функциональные тесты на замоканных данных.

Здесь, помимо самого факта открытия колдунщика, мы можем сделать и проверку скриншота.
Хорошо. Теперь давайте вернемся к самому сложному вопросу. Как же все-таки вручную протестировать гигантский проект во всех окружениях и успевать делать полные регрессы каждый день. Если вы еще не догадались, ответ прост.
Нужно нанять очень много тестировщиков! Пара-пара-пам.

И было бы нечестно, если бы я тут просто хвастался, что мы можем позволить себе целую армию тестировщиков и теперь спокойно гоняем тысячи тестов.
Вы, конечно, тоже можете организовать такую схему у себя, вам для этого не понадобится огромное количество специально обученных рекрутеров, которые будут круглосуточно нанимать новых тестировщиков.
Вы, опять же, могли догадаться, что здесь на помощь приходит крауд-тестирование. С помощью Яндекс.Толоки это очень легко организовать у себя. Это не будет стоить каких-то заоблачных денег.
Толока — сервис, который позволяет любому желающему опубликовать свои небольшие задачи. А затем кто угодно может браться за эти задачи, получая за каждое выполнение небольшое вознаграждение. С помощью Толоки можно решать огромное количество самых разных задач — у нас даже есть мобильные толокеры, которые ходят по улице, фотографируют вывески на заведениях и таким образом актуализируют Яндекс.Справочник.
Схема организации крауд-тестирования работает здорово. Возможно, есть и другие подобные сервисы. Если вы их знаете — поделитесь. Мы, конечно, пользуемся собственным.
Окей, если у нас есть тот самый yml с описанием шагов и система управления тестами, то нам остается только экспортировать такие задания в Толоку, а потом забирать результаты обратно и уже дальше интерпретировать их при помощи штатных тестировщиков.

Как это выглядит? Последовательность шагов превращается в последовательность атомарных маленьких задачек в Толоке. Толокер, выполняя каждый шаг, должен ответить, все ли верно или есть проблема. Если проблема есть, он чуть более подробно описывает, что пошло не так. И из этого генерятся тикеты в трекер, которые получает разработчик.
Такой подход как раз позволяет нам проделывать все проверки, потому что толокеров действительно тысячи, потому что кто-то из них готов работать с утра, кто-то вечером, кто-то ночью. Они живут в разных часовых поясах и суммарно обладают всем набором устройств и всевозможных окружений, которые нам и нужны.
Если говорить исключительно про тестирование интерфейсов поисковой выдачи, над ним сейчас работает 9 тысяч отобранных толокеров. Они прошли обучение, наши экзамены и в итоге мы знаем, что они нам обеспечивают проверку 100 тест-кейсов в течение часа, если мы говорим про десктоп. В случае с мобильными устройствами — чуть подольше, примерно 5 часов на 100 тест-кейсов. Примерно с такой скоростью мы движемся, чтобы убедиться, что все хорошо.
Но что делать, если тестировщики в Толоке вдруг будут тыкать, что все хорошо, нормально и даже не всматриваться в задание? Проблема решается достаточно просто. Мы заранее в список задач подмешиваем задание с багами. Это называется honeypot. И тестировщик на такой honeypot тут же наткнется. Он решит, что это очередное задание, кликнет, что там все хорошо. Так мы поймем, что он на самом деле невнимательный, забаним его, и больше он не будет с нами работать.
Помимо проверки тест-кейсов эту же схему можно применить и для других видов задач.
Например, с таким же успехом мы можем проверять актуальность документации. Документация — это же те же самые сценарии, если мы, конечно, не говорим про документацию на API. Но там автоматизация и так есть из коробки: мы можем генерить документацию из кода, и соответственно, она не протухает.
Но если мы говорим про документацию, написанную для пользователей, то это сценарии. Мы точно так же описываем: чтобы получить результат, нужно нажать сюда, перейти сюда, ввести что-то и т. д.
Эти сценарии мы точно так же можем покрыть тест-кейсами, точно так же написать на них автотесты и поверх всего этого запустить крауд-тестирование, в итоге убеждаясь, что документация по-прежнему актуальна. Либо получая тикеты на обновление, если что-то пошло не так.

Давайте подводить итоги. Мы поговорили о том, что важно покрывать автоматическими проверками все, что только можно. Стоит написать как можно больше дешевых юнит-тестов, которые решают большую часть задач.
Но как бы вы ни покрывали все, как бы ни старались написать интеграционные тесты, все равно потребуется ручное тестирование. Минимизировать человеческий фактор, чтобы человек не упустил никаких проверок, помогает система управления тестами. А чтобы тест-кейсы не протухали, важно хранить тестовые сценарии рядом с кодом и валидировать эти сценарии по автотестам. Наконец, мы можем автоматизировать ручное тестирование с помощью крауд-тестирования. Так что тестируйте и запускайте. Спасибо!
Я выступил с этим докладом на последнем Я.Субботнике. Следующий Я.Субботник по разработке интерфейсов пройдёт 4 июля.
Комментариев нет:
Отправить комментарий