Всем привет! Весенний семестр для некоторых студентов 3-го курса ФУПМ МФТИ ознаменовался сдачей проектов по курсу «Методы оптимизации». Каждый должен был выделить интересную для себя тему (или придумать свою) и воплотить её в жизнь в виде кода, научной статьи, численного эксперимента или даже бота в Telegram.
Жёстких ограничений на выбор темы не было, поэтому можно было дать разгуляться фантазии. You Only Live Once! — воскликнул я, и решил использовать эту возможность, чтобы привнести немного огня в бессмертную классику.,
Всем хороша свобода выбора, кроме одного: надо определиться с этим самым выбором. Имелось много тем теоретических проектов, предложенных лектором и семинаристами, но меня они не заинтересовали. Всё-таки хотелось получить на выходе нечто, что можно потрогать руками, а не корпеть над статьями и математическими выкладками.
И тут я вспомнил, что год назад вместе с одногруппниками писал браузерный Арканоид на JavaScript. Почему бы не добавить в эту бородатую игрушку немного рок-н-ролла, а точнее модного нынче computer vision-а? Эта область ML представлялась мне довольно интересной и проект на эту тему стал бы прекрасной мотивацией для изучения.
Так и появилась игра Breakout с управлением жестами через веб-камеру, или выражаясь лаконичнее — Breakout-YOLO, но обо всем по порядку.
Основной геймплей Арканоида заключается в отбивании шарика двигающейся платформой, управляемой мышью/тачпадом или клавиатурой:

Мне же хотелось перенести функцию управления на жесты пользователя. Управление платформой я утвердил следующее: её положение определяется положением некоторого жеста на видео с веб-камеры.
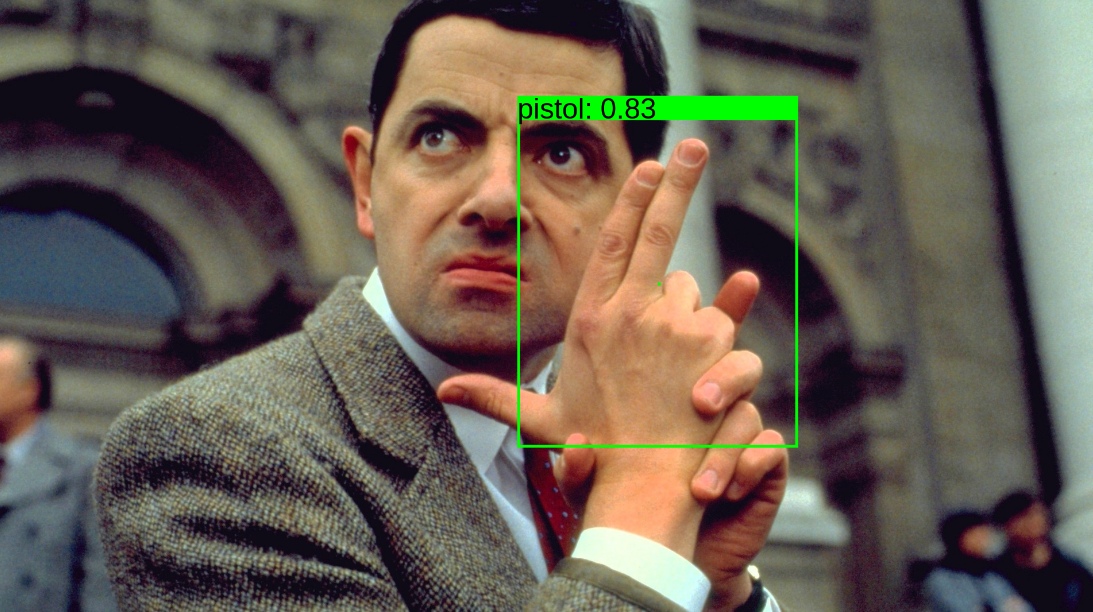
То есть естественным образом возникла задача real-time object-detection — на вход алгоритму поступает кадр из видео, на выходе хотим иметь изображение с объектами, обведёнными в рамку (bounding box) прямо как на картинке ниже:

И все это нужно делать быстро, выдавая хотя бы 20-30 FPS, — ведь никому не интересно играть в слайд-шоу. Не сомневаюсь, что причастные к CV люди по названию статьи догадались какую модель я выбрал, остальных же охотно приглашаю под следующий заголовок.
You Only Look Once
YOLO — это популярная архитектура CNN для решения задачи object-detection:

Основная её идея состоит в том, что нейросеть обрабатывает всё входное изображение лишь единожды. Такой подход дает существенный выигрыш в быстродействии по сравнению с методами, использующими region proposals. В последних же происходит несколько независимых классификаций выделенных областей изображения — это не только медленнее по очевидным причинам, но и не учитывает контекст, что несколько ухудшает точность распознавания.
За подробным описанием архитектуры отсылаю интересующегося читателя к оригинальной статье и её обзору от Deep Systems.
Better, Faster, Stronger
Одной из последних* версий YOLO является YOLOv3. От первоначальной модели эту отличает несколько новых фич: авторы отказались от fully-connected слоя в конце, таким образом остались только свёрточные слои. Для улучшения распознавания объектов разных размеров было добавлено 2 дополнительных выходных слоя, что напоминает концепцию feature pyramid.
Были задействованы anchor box-ы — наборы ограничительных рамок, а точнее их параметров, относительно которых сеть делает предсказания bounding box-ов. Для повышения точности предсказаний их нужно перевычислять отдельно для каждого датасета. Обычно это делают с помощью метода k-средних, кластеризуя множество bounding box-ов из трейна.
Для того, чтобы регуляризовать сеть, к каждому свёрточному слою был прикручен batch normalization. Также был применён multi-scale training — случайное изменение разрешения входящего изображения при обучении.
Детальное описание всех изменений можно найти в статьях про YOLOv2 и YOLOv3 и обзоре.
Я же взял Tiny-YOLOv3 — уменьшенную версию этой модели без последнего слоя:

В ней используется слой пулинга вместо свёрточного слоя с страйдом 2. Всё это делает её быстрее и компактнее (~ 35 Мб), а значит более предпочтительнее для моей задачи.
* на момент выбора модели. С тех пор успела выйти YOLOv4 и нечто, называющее себя YOLOv5.
Перейдём к самой рабоче-крестьянской части проекта.
Выбор жестов и датасета
Для управления игрой были выбраны следующие 4 жеста:

Вопрос: на чем обучать модель?
Первое, что пришло в голову — взять датасет какого-нибудь жестового языка, например американского: ASL Alphabet, Sign Language MNIST и обучится на нем.
Но меня отпугнуло следующее:
- В отсмотренных мною датасетах все фотографии были сделаны на однородном фоне
- Не все выбранные мною жесты были представлены в датасетах
- Я не нашел именно object detection датасета с bounding box-ами, так что в любом случае пришлось бы доразмечать данные
Модели же предстояло работать на разных ноутбуках с разными веб-камерами в условиях если не агрессивного фона и плохого освещения, то как минимум силуэта человека на заднем плане. По этой причине (а также из-за своей неосведомлённости в deep learning) я не мог обоснованно сказать, как YOLO обученная на этих данных поведет себя в бою. К тому же сроки предзащиты проекта поджимали — права на ошибку не было.
Поэтому я посчитал правильным действовать наверняка и решил...

собрать и разметить свой датасет.
Не имей сто рублей, а имей сто друзей
В развивающемся репозитории с различными YOLO моделями мудрецы гласят, что для сколько-нибудь успешного обучения необходимо иметь в трейне не менее 2000 размеченных изображений для каждого класса. Я решил не мелочиться и поставил планку в 3000 изображений для каждого класса, обеспечивая себе пути для отступления и солидную тестовую выборку в случае выполнения поставленной цели.
Как для достижения большего разнообразия в датасете, так и для облегчения собственных страданий пришлось прибегнуть к бесплатному краудсорсингу помощи друзей. Я попросил каждого из этих восьми несчастных записать на веб-камеру 2-ух минутное видео с 4 жестами — по 15 секунд на жест каждой рукой. Сам я сделал 4 таких видео в разной одежде и на разных фонах.
Далее в дело вступал удобнейший GUI для разметки от AlexeyAB. С помощью него я нарезал видео на кадры и, набравшись терпения, сел размечать. Директорию с изображениями я предварительно синхронизировал с гугл-доком при помощи Insync, чтобы не терять время на перенос датасета в облако.
К концу 8-го часа разметки у меня имелось около 8000 изображений с аннотациями в .txt файлах, полное нежелание продолжать процесс и, наверное, парочка новых сидячих болезней. Поэтому, удовлетворившись проделанной работой, я пересчитал anchor box-ы, разделил данные на тест и трейн в жадном соотношении 1:9 и перешел к следующему этапу.
Снаряжаемся видеокарточками
Времени до первого показа проекта оставалось всё меньше и меньше, поэтому я пошёл куда глаза глядят по пути наименьшего сопротивления и решил обучать модель в Darknet — написанном на C и CUDA open-source фреймворке для создания и обучения нейронных сетей.
Вычислительных мощностей мне объективно не хватало — из графических процессоров с поддержкой CUDA под рукой имелась только GeForce GT 740M (Compute Capability = 3.0), которой требовалось 10-12 часов для обучения Tiny-YOLOv3. Поэтому я стал счастливым обладателем подписки на Colab Pro с Tesla P100-PCIE-16GB под капотом, сократившей это время до 3 часов. Стоит отметить, что Colab уже давно и так бесплатно предоставляет всем желающим мощную Tesla T4, правда с ограничениями по времени использования. О них я узнал по всплывшей на экране надписи «You cannot currently connect to a GPU due to usage limits in Colab», заигравшись с обучением YOLO на всяких кошечках-собачках, интереса ради.
Чтобы нащупать trade-off между точностью распознавания и быстродействием, я взял 4 модели: Tiny-YOLOv3 с размерами входного изображения 192x192, 256x256, 416x416 и XNOR Tiny-YOLOv3, в которой свёртки аппроксимируются двоичными операциями, что должно ускорять работу сети. Указанные «Ёлки» обучались в течение 8, 10, 12 и 16 тысяч итераций соответственно.
Метриками качества обученных моделей послужили mean Average Precision с IoU=0.5(далее обозначается как mAP@0,5) и FPS.
Результаты обучения

На графиках выше представлены зависимости значений лосс-функции на трейне и mAP@0.5 на тесте от номера итерации обучения.
Как видите, XNOR модели нездоровилось. Несмотря на финальный mAP@0.5 ≈ 88%, при хорошем освещении она еле-еле распознавала пару жестов с минимальным confidence. FPS ≈ 15 также намекал, что что-то пошло не так. Это не могло не расстраивать, так как я возлагал на XNOR большие надежды. На момент написания этой статьи мне всё ещё не ясно, в чём была проблема, возможно я что-то напутал в .cfg файле.

Остальные же модели обучились приемлемо. Полученные значения FPS справедливы для следующей
ASUS Vivobook S15, i7 1.8GHz, GeForce MX250
В погоне за быстродействием для использования в игре я выбрал 192х192 модель.
Дабы не зависящий от размера входного изображения mAP@0.5 не вводил в заблуждение, надо сказать, что эта метрика в данной ситуации несколько обманчива.
Дело в том, что в собранном датасете жесты на фотографиях расположены примерно на одном расстоянии от камеры, поэтому модели переобучились на это расстояние. Это видно по тому, как 192х192 модель работает при сильном приближении/отдалении от веб-камеры — она не умеет предсказывать очень большие/маленькие bounding box-ы, так как не видела таковых в датасете. Однако такое переобучение соответствует поставленной задаче — распознаванию жестов на установленном расстоянии, удобном пользователю.
Таким образом, важно понимать, что mAP@0.5 здесь тесно связан с конкретной задачей, и на самом деле при уменьшении размера входного изображения модель теряет в точности распознавания очень близких/далеких к камере жестов, что, однако, практически не влияет на точность на тесте.
Немного про архитектуру
Для распознавания жестов в браузере я использовал библиотеку TensorFlow.js. Обученные веса сначала были сконвертированы в Keras, а затем преобразованы в TFJS Graph model.
Так выглядит демо-версия (загрузка может занять некоторое время):

Сама игра написана на Javascript, за основу был взят этот туториал. Её архитектура предельно проста и заключается лишь в перерисовке кадров с помощью setInterval. На некоторых девайсах наблюдался довольно низкий FPS, поэтому я установил модель распознавать жесты каждую 10-ую перерисовку.
Несмотря на это, всё равно могут быть заметны фризы в момент распознавания. Чтобы их избежать я планирую распараллелить распознавание и перерисовку с помощью Web Worker.
А вот теперь поиграем
Весь код с обученными моделями и инструкцией по использованию лежит здесь.
Управление игрой:
- Нажатие на кнопку «Play»/пауза в игре — жест «finger up»
- Перемещение курсора в меню/снятие с паузы — жест «circle»
- Перемещение платформы — жест «fist»
- Выстрел шариком с «липкой» платформы — жест «pistol»
Поиграть можно здесь. Я рекомендую использовать FIrefox, но Chrome/Chromium также поддерживаются.
Так выглядит геймплей:

Внимательный читатель спросит: «А причем тут собственно методы оптимизации?» Да ни при чем! Но такая свобода выбора темы проекта дала стимул плотно начать разбираться в интересном разделе машинного обучения, и это здорово, на мой взгляд.
Sapere aude, хабровчане!
P. S.
Всё это, как видится, лишь история о моём знакомстве с моделью YOLO и о её использовании. Если Вы знаете как надо было сделать, то приглашаю вместе с конструктивной критикой в комментарии, буду рад дельным рекомендациям.
Комментариев нет:
Отправить комментарий