
Terraform — это популярный инструмент компании Hashicorp, для управления вашей облачной инфраструктурой в парадигме Infrastructure as a Code.
Terragrunt — это wrapper для Terraform, которая предоставляет дополнительные инструменты для хранения ваших конфигураций Terraform, работы с несколькими модулями Terraform и управления удаленным состоянием.
Видео:

Ссылки:
Я являюсь AWS Community Hero. Я – сертифицированный Terraform-фанатик, потому что я прошел сертификацию Terraform. Есть такое понятие, как HashiCorp-сертификация.
Я являюсь активным участником open source движения. Я много трачу своего времени, энергии на создание и поддержание Terraform-проектов, community-modules, aws-modules. Может быть, кто-то из вас даже чем-то пользуется из этого.
Я делаю много утилит таких, как, например, Pre-commit-terraform. Это утилита для автоматического форматирования кода документации, форматирования кода и т. д.
Я стараюсь участвовать во всех конференциях. В данном случае у меня появилась возможность выступить на этой конференции, благодаря тому, что завтра будет конференция Delivery Excellence. Вы можете сходить туда и услышать еще кучу всего про Terraform и не только про Terraform.
Если у вас есть Твиттер, GitHub и вы не рекрутер, то Linkedin для вас. Рекрутеры мне ну нужны, потому что все в open source, и мы все находим работу исключительно в open source.

Open source – это бесплатная чаще всего вещь. Мои проекты open source. Они мне дают обычно заказчиков, которые говорят: «Можешь сделать то же самое? Можешь научить нас пользоваться этим?». И это называется консалтинг.
Если есть какая-то команда, которая использует Terraform, и в Terraform используют Terraform workspace, то я говорю: «Давайте я вам workshops проведу и скажу, что это зло?». Это называется workshops.
Если люди пишут код в течение недели-двух и не совсем понимают правильно ли они делают, т. е., может быть, какое-то решение есть получше, тогда они обращаются ко мне, и я примерно час-два в неделю занимаюсь тем, что я их консультирую, смотрю pull request, обсуждаю решения и говорю, как это можно сделать по-другому. Не всегда лучше, иногда просто по-другому.
У меня есть email: anton [собака] antonbabanko.com. Вы всегда можете писать, я, скорее всего отвечу, т. е. я отвечаю, но иногда с задержкой, потому что я сейчас очень много путешествую.
Компания называется Betajob.com. Я в ней единственный сотрудник.

https://github.com/terraform-aws-modules
https://registry.terraform.io/modules/terraform-aws-modules
Terraform AWS модули – это один из основных моих проектов, который я начал в 2017-ом году, потому что мне нравилось делать что-то такое, что нужно большому количеству людей. Например, так или иначе настраивают VPC в Amazon. Я подумал, что надо сделать это как-то правильно. И вместо того, чтобы взять еще один модуль, который кто-то написал, я взял тот, который был самым популярным у меня. Потратил на него несколько сотен часов. И выложил это все в открытый доступ.
Дальше все остальные пошли намного лучше, быстрее. И все оказалось не таким сложным.
Тоже самое касается и поддержания этих сервисов, модулей. Я не трачу на них огромное количество времени. Но все равно достаточное.

https://github.com/sponsors/antonbabenko
Было 7 000 000 загрузок, больше 1 000 pull requests и множество issues было пофиксено. И частично это все благодаря этим 6 аватаркам, которые спонсируют меня на GitHub. Если ваша компания пользуется из этого чем-нибудь, то вы можете присоединиться, и ваш аватар будет тут тоже. Вам все равно, а мне приятно.
Еще один проект, с которым я связан, называется Cloudcraft. Это такая утилита, которая в браузере позволяет все это визуализировать, т. е. нарисовать инфраструктуру, соединить все компоненты. В общем, сделать все классно, как мы можем понять.

Cloudcraft дает возможность это все экспортировать как картинку, посмотреть, сколько это стоит или втянуть в существующую AWS-инфраструктуру.

https://dzone.com/articles/infrastructure-as-code-the-benefits
Я понимаю, что когда это все красиво смотрится, это может впечатлить начальников, менеджеров и дать больше денег, но когда мы возвращаемся к работе, то мы все равно пропагандируем здоровый образ жизни, т. е. инфраструктуру как код. Мы не может ничего сделать с картинкой, т. е. она классно выглядит, ее все пихают во все презентации. Но в реальности инфраструктура должна быть как код, а не инфраструктура как Powerpoint. Или еще хуже, когда инфраструктура как clickops, когда в консоли – клац, клац, готово. И никто не знает, как это работает, зачем это сделано.
И давайте договоримся, что инфраструктура как код – это хорошо, потому что мы ее отслеживаем, мы видим, кто поменял и что поменял. Мы можем четко посмотреть на файлы и понять, какая конфигурация прямо сейчас находится в проекте. К этому надо стремиться. Не всегда это получается. Для этого существуют сервисы cndb, Systems Manager от Amazon. Но это хорошая цель.

О чем мы будем сегодня говорить?
Есть Terraform 0.12 и Terraform 0.11.

Начнем с того, зачем Terraform появился. Я понимаю, что вы многие это уже знаете. Terraform довольно часто упоминается на большом количестве докладов. Тут ничего удивительно нет, потому что Terraform появился неспроста.
Amazon в 2011-ом году сказал: «Вот вам CloudFormation». На нулевой день люди поняли, что это круто. На первый день люди начали писать Spectrum, Fogs и т. д., чтобы собирать эти кусочки JSON, YAML и т. д., т. е. как-то их организовывать. Они придумывали разные DSL и т. д. Вы можете зайти на GitHub и погуглить, например, orchestration-cloudformation. И вы увидите большое разнообразие утилит. Spectrum – это одна из тех, о которой я сегодня здесь слышал от кого-то.
В общем, Google сказал, что все фигня, мы будем, как программисты, людям давать возможность писать на Python, пусть используют Jinja Tempating, будут описывать свою инфраструктуру. Это вполне здравомыслящий подход от Google.
Но Azure тоже сказал, что это все фигня, потому что нет ничего лучше, чем JSON. И ничего, что программисты не понимают, что там происходит. Программисты пользуются этим, плюются. Большинство программистов переходит из Azure ARM в Terraform в одностороннем порядке. Я ни разу не слышал, чтобы кто-то сказал, что Terraform – фигня, я обожаю JSON, я люблю мазахизм.
И по историческим причинам у нас есть Chef, Ansible, Puppet, которые так или иначе умеют всем управлять. У них есть миллион ресурсов, моделей, плейбуков. Там все здорово.
Из этого следует логичный вывод: если можно управлять каким-то одним ресурсом, то можно управлять и public cloud ресурсами Amazon, Google, Azure и т. д. У большинства configuration management утилит уже есть какие-то модули, решения, поэтому все классно. Поэтому сейчас мы видим, что есть куча решений: есть решения, которые сделаны одним провайдером, либо одно решение работает на разных провайдерах.
Terraform в 2014-ом году появился с той идеей, что давайте забудем все то, что есть у остальных, будем смотреть только на то, что сделал хорошего CloudFormation, потому что CloudFormation дал значительный вклады в понимание того, как должна работать архитектура, как ее описывать и что пользователи хотят с ней делать и т. д.

И поэтому появился Terraform, в котором сейчас поддерживается больше, чем 250 провайдеров и используется один и тот же язык для настройки, т. е. используется HashiCorp Configuration Language, где достаточно знать один язык, и можно одинаково работать с ресурсами совершенно на любом провайдере.
И Terraform является первой из существующих программ, утилит, которая позволяет работать с ресурсами на более высоком уровне. В Terraform есть концепция модуля, которая заложена в самую-самую основу. Буквально на второй день использования Terraform, так или иначе возникнет желание этот код использовать. И у Terraform есть такая возможность. У CloudFormation с самого начала этой возможности не было. Конечно, сейчас CloudFormation уже не такой, какой он был в 2013-2014-ом году, но все равно не так все радужно.
Также Terraform не работает со всеми доисторическими mainframes, workers и т. д. Поддерживается то, что существовало, начиная с 2014-го года. Если вы хотите администрировать то, что не администрируется, то вам нужно самому написать API к этому, и написать в Terraform провайдер. И тогда у вас будет Terraform администрировать неадминистрируемое. Это тоже нормальный use cases.

https://www.terraform.io/docs/providers/index.html
Но на самом деле API есть у всего, т. е. от создания email в Google до управления файлами и permeation в Dropbox, и до заказов пиццы. Наверное, многие уже знают, что пиццу тоже можно через Terraform заказывать. Это нормальный use cases.
Но мне больше нравится use cases, где в основу принята концепция взаимодействия. Представьте, что у вас в Minecraft есть земля и есть овца. И если мы бросаем овцу, то овца будет падать-падать. И в конце концов упадет на землю. Если мы уберем землю, то овца упадает и умрет. Поэтому что надо сделать, если мы мыслим как Terraform? Надо сделать так, чтобы овца зависела от земли. И когда мы это описываем внутри hsale, то мы описываем, что есть ресурс овца и ресурс земля. И делаем так, что ресурс овца принимает как аргумент землю. Таким образом мы даем Terraform понять, что сначала сделай землю, а потом брось туда овцу, иначе все пропадет. Это пример того, как можно использовать зависимость в реальном мире.
Это примерно по той же причине, зачем мы придумали объектно-ориентированное программирование. Мы посмотрели вокруг себя и увидели, что у нас много объектов. И решили придумать им какие-нибудь ключевые слова, объекты, наследования и т. д. Тоже самое происходит с Terraform. В Terraform можно описать все, где есть API и есть зависимости.
Если у вас много свободного времени, то можете посмотреть список провайдеров по данной ссылке и представить, какую часть инфраструктуры в своей компании вы можете автоматизировать. На вскидку могу сказать, что весь процесс создания, когда кто-то приходит в компанию, и вы ему создаете email, создаете доступы в GitHub-репозитории, доступы в Jira. Это все в нормальных компаниях автоматизирован с помощью одного pull requests в Terraform. И точно так же происходит при создании.

Если вы начинаете учить Terraform, то я рекомендую всего лишь 3 ресурса:
-
Terraform.io – почитать документацию, потому что документация дает информацию о том, что существует.
-
Learn.hashicorp.com – потом потыкать это здесь.
-
Terraform-best-practices.com – когда вы уже узнали, что есть 100-500 фич разных в Terraform, вы попробовали из них половину, поняли, что что-то тут попахивает и начинаете думать, что есть best practices. Вы пишете в Google «Terraform best practices» и попадаете на мой сайт.
Я этот сайт написал, потому что люди спрашивали меня: «Как это сделать правильно?». Люди спорили – best practices это или нет. И понял, что best practices – это то, что опубликовано на сайте terraform-best-practices. Я так и сделал. Т. е. написал то, что я считаю самым важным. Например, как структурировать код, какие основные фичи в Terraform и вообще при работе с инфраструктурой как код надо учитывать. Я написать еще кучу примеров кода, как это работает для маленьких, для средних, для больших и очень больших компаний в зависимости от количества ресурсов, провайдеров. И я написал это, потому что мне не хочется, чтобы люди делали что-то неправильно.
Теперь, спустя полтора года, люди туда заходят в большом количестве и очень мало людей сопротивляется. Очень мало людей мне говорит: «Ты не прав тут», т. е., пожалуйста, если кто-то не согласен с тем, что там написано, напишите на email или откройте pull request и скажите, что так не работает. Потому что там есть места, которые уже не работают, потому что работали полтора года назад. С тех пор я кое-что там изменил.
Можете изучать эти ресурсы. И важно, чтобы вы понимали, что весь функционал Terraform – это не то, что надо вашей компании. И это, пожалуй, один из важных моментов, который я хочу сегодня донести в докладе. Потому что Terraform очень большой проект, если его весь использовать, то того и гляди вы еще work space начнете использовать.

Что это знает?
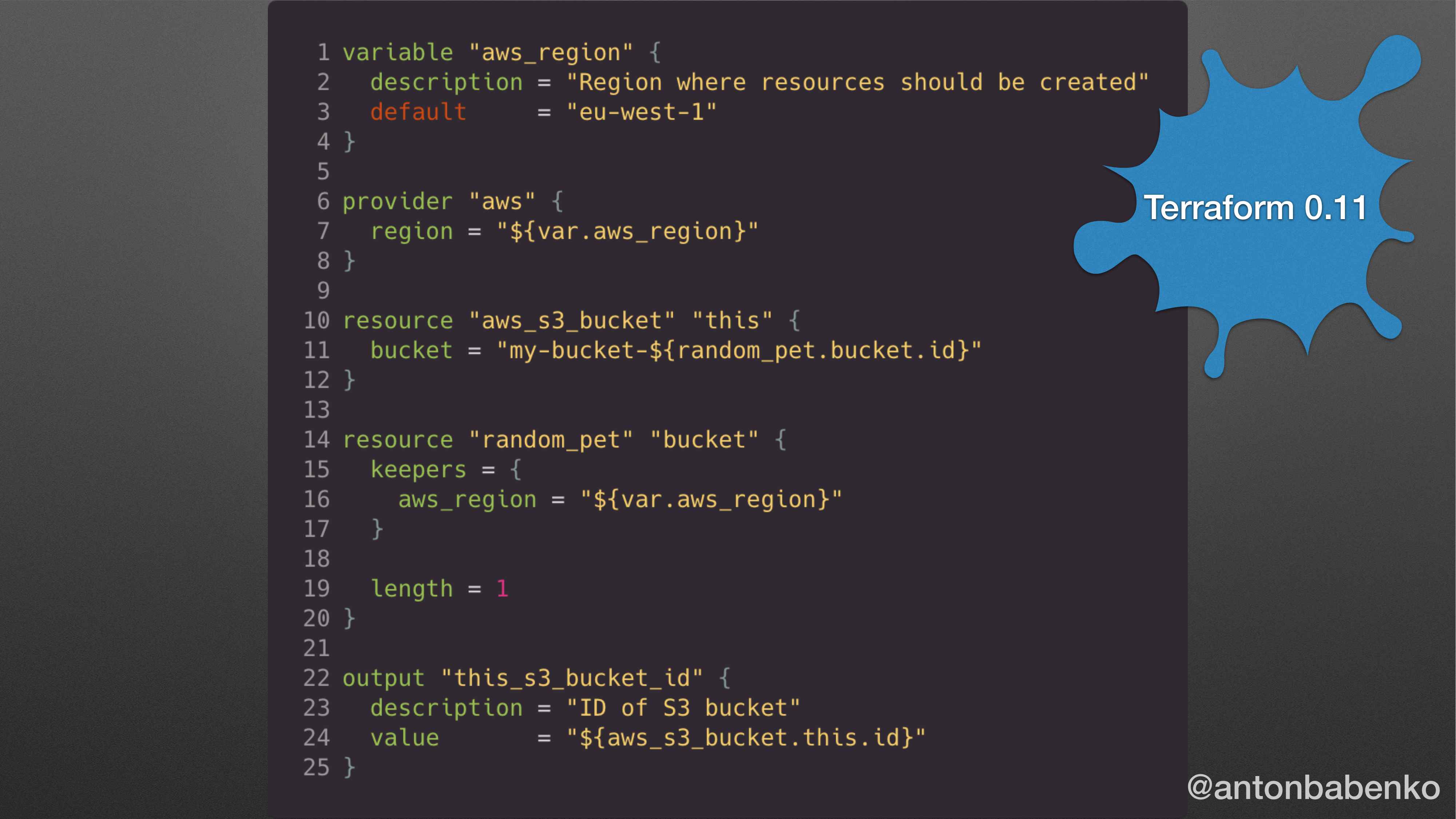
В Terraform 0.11 выглядели вот так конфигурационные файлы, т. е. мы описывали инфраструктуру. В данном случае мы создаем s3_bucket.
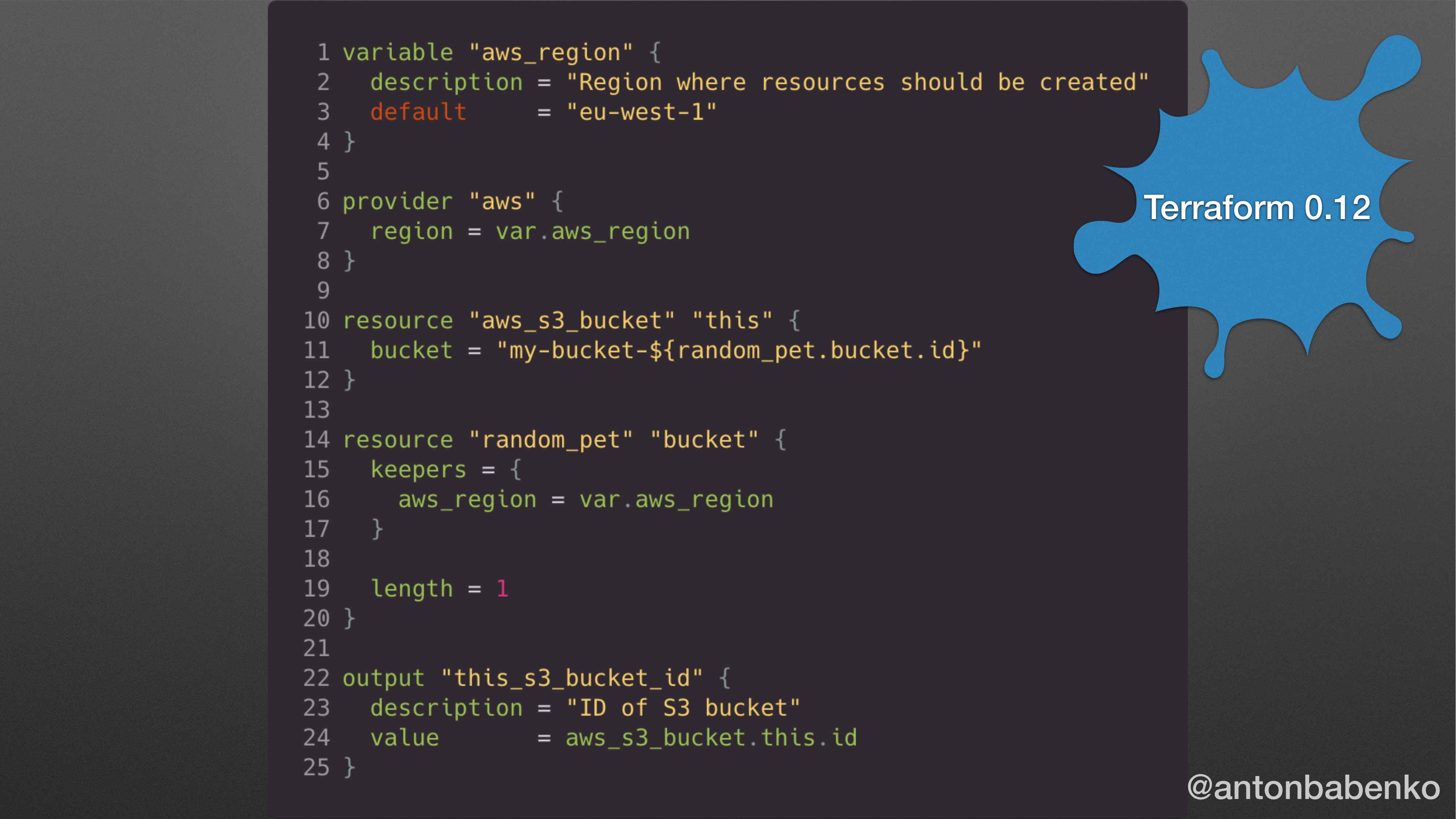
В Terraform 0.12 все вот так вот. Это все, что надо знать. Оно и так будет работать. Но меняется то, что меньше надо символов писать.

https://www.hashicorp.com/blog/announcing-terraform-0-1-2-beta
Там еще есть куча фич. Можно использовать циклы; динамические блоки, где правильно вычисляются условные операторы, где левая и правая часть не вычисляются одновременно.
Если вы использовали Terraform 0.11, то вы, наверное, помнили тот ужас, когда надо было написать выражение, которое и в try, и в false было адекватно правильно написано. И это одна из тех фич, которая мне сделала жизнь сложнее. Correct conditional operators означает, что если выражение истина, то берется левое значение, если не истина, то правое значение. Я поддерживаю большое количество Terraform AWS модулей. И вот эта конкретная штука сделала мою жизнь сложнее.
Почему? Как было раньше? У меня есть 100 -500 ресурсов, которые создаются в зависимости от разных условий. И когда я запускал Terraform plan, Terraform apply в своих тестовых environment, мне не так важно было проверять левую часть отдельно от правой части. Мне главное, чтобы это выражение не содержало ошибок и все. Сейчас мне надо писать test cases для двух разных условий: когда левая часть проверена и правая часть проверена отдельно. Т. е. мне надо писать в два раза больше кода и надо в два раза больше думать. А я люблю, когда Terraform думает за меня. Т. е. я люблю, когда Terraform проверяет значения и выдает какой-то вид ошибки без моего участия, а именно, когда я делаю код review, мне не надо запускать этот код в голове.
Много всего появилось. Все классно. Если вы следили за тем, как появлялся Terraform, т. е. вот этот блокпост на сайте HashiCorp появился примерно за полгода до релиза. И очень много людей думали, что сейчас Terraform 0.12 родится, и мы заживем.
Он родился спустя полгода. За это время было много гневных комментариев от людей в Твиттере, что HashiCorp – плохая компания, потому что она анонсировала, а продукт не готов. Люди были очень расстроены. Это реальность жизни в open source.
https://www.terraform.io/upgrade-guides/0-12.html
Для тех людей, которые хотят обновить с 0.11 на 0.12 вот это самый важный слайд.
Во-первых, есть upgrade guide, где описано, что конкретно поменяется в коде, на что надо обращать внимание, как запускать. Все там классно написано. Если вы прочитаете, то я на 90 % уверен, что миграция у вас пройдет гладко.
Если есть проекты или части проекта, в которых вы не можете использовать Terraform 0.12, но можете использовать 0.11 последней версии, то у вас есть возможность читать Terraform state файлы, созданные версией 0.12. Это основное отличие в самой распространенной ситуации, когда вы обновили что-то, а потом пытаетесь использовать старую версию, а вам говорят, что этот state файл был создан новой версии, пожалуйста, обновите это.
В данном случае это решено специально для того, чтобы была возможность плавно мигрировать части инфраструктуры. Какая-то часть уже на 0.12, а какая-то часть на старой версии, до которой руки не дошли или которую вы собираетесь удалить, поэтому вам не надо ее переписывать.

https://github.com/tfutils/tfenv
Если вы хотите контролировать версии, то есть такая утилита как tfenv. Тут все просто.

https://www.terraform.io/docs/configuration/terraform.html
Есть возможность указания версии провайдеров, о которой не многие знают, хотя она написана в документации. Можно указывать версии того провайдера, в котором работает ваша архитектура. Как часто делают люди? Берут провайдер-блок. Допустим, провайдер AWS. И там написан регион, и там же указана версия провайдера. Можно так делать. Но когда у вас есть один Terraform-блок, то вы выносите в самый верх своей инфраструктуры. И там указываете все свои зависимости. Так намного проще работать.

Если вы обновились, а потом подумали: «Ой, кошмар, что я сделал?», то вот такую команду запустите и она вам вернет предыдущий Terraform state файл поверх того, что у вас сейчас есть. Эта команда спасла не один проект.

Теперь поговорим о том, как структурировать Terraform конфигурации и вообще, как с этим жить.

Когда мы написали все в ресурсах, потом мы осознали, что есть Terraform модули, потому у нас есть куча Terraform моделей. И мы начинаем думать, как их вызывать.

Есть такой способ, как all-in-one, когда мы в tf файлы запихиваем вызовы Terraform-модулей. И преимущество у такого подхода заключается в том, что нам нужно меньше объявлять переменных, меньше outputs. Но когда мы работаем с таким проектом, у нас refresh занимает много времени, plan тоже занимает много времени. И мы работаем с инфраструктурой как с одним большим целом.

Второй способ – это, когда мы делаем 1-in-1. Таким образом у нас намного меньше вызов. И когда мы работаем с каким-то конкретным стеком, мы можем перейти в ту папку и сделать какие-то изменения, и все. Мы работаем в довольно изолированном виде, все намного быстрее.

Представьте свой проект на работе. Как он выглядит: all-in-one или 1-in-1? Многие, когда я задаю этот вопрос, думают, что all-in-one – это кошмар, а 1-in-1 – норма.

На самом деле MFA (Most Frequent Answer) – это посередине.

Потому что, когда начинаем работать над каким-то проектом, у нас есть несколько вариантов. Мы либо идем в Google и спрашиваем: «Google, дай мне какой-нибудь готовый кусок кода, который я сейчас сюда вкину», либо идем на terraform.io, берем оттуда какой-то проект и прикручиваем его к себе – all-in-one. Мы потом берем другие ресурсы, подключаем это все вместе. Запускаем Terraform plan 20 раз. Мы начинаем работать с all-in-one.
Потом мы понимаем, что вот эта целая штука, которая была all-in-one закончена, она тесно между собой связана. Мы это делаем, допустим, как модуль. И дальше уже встраиваем либо в другой проект, либо в другой environment. Т. е. как-то стараемся это переиспользовать.
А структура 1-in-1 является классным примером, когда у нас есть уже готовые куски кода. Например, мы зашли Registry на сайте terraform.io, взяли готовый VPC-модуль. Понятно, что мы его не будем переписывать, дописывать, расширять. Мы будем его просто использовать. И когда у нас есть возможность что-то готовое использовать, намного удобнее работать. Это 1-in-1.
Также, если у нас есть возможность или необходимость разделять это между разными командами или разными программистами внутри одного проекта, когда кто-то из программистов является писателем Terraform-кода, а кто-то не хочет вникать, как он написан, а просто хочет его использовать.
Также, если вы знаете, что такое Terragrunt, то 1-in-1 для этого.

Какой тип окристрации между модулями вы знаете?
Представьте, что у нас есть проект all-in-one. И мы пишем Terraform plan. Ждем 15 минут. Он весь интернет сканирует. Потом мы видим, что там какой-то ресурс должен быть изменен. Мы запускаем Terraform apply, ждем 15 минут, пишем «Yes», все классно.
Потом мы понимаем, что есть такой вариант, как main targets. Мы пишем terraform apply -targets = module.vpc. И вся наша область деятельности ограничена только модулем VPC. Также мы можем написать оболочку, shell-скрипт, makefile, PowerShell и это будет как-то подсказывать Terraform, какие аргументы передавать, либо какие war-файлы загружать, либо какие таргеты использовать. Многое чего можно делать.
Если мы используем 1-in-1, то примером такого mikefile может быть следующее. Мы можем запустить Terraform apply в одной папочке, потом перейти в другую папочку и запустить Terraform apply еще раз. И вот так последовательно это будет запускаться. Т. е. мы заходим в самый верхний уровень, пишем make terraform apply и ждем какое-то время. И все изменения применяются.
Какие еще варианты бывают? Да, мы можем использовать state файл как input для другого скрипта. Это, по сути, реализовано внутри shell-скрипта, который занимается тем, что создает инфраструктуру в одном месте. Потом, когда переходим в другую папку, запускаем Terraform apply, и там используется data-source для того, чтобы прочитать Terraform remote state из известного места. Это тоже способ. Так или иначе это все ограничивается shell-скриптами, makefiles.

А как вам такой вариант? Кто хочет так использовать? Он же работает. Можно до бесконечности все усложнять. Terraform используется для запуска Terraform.
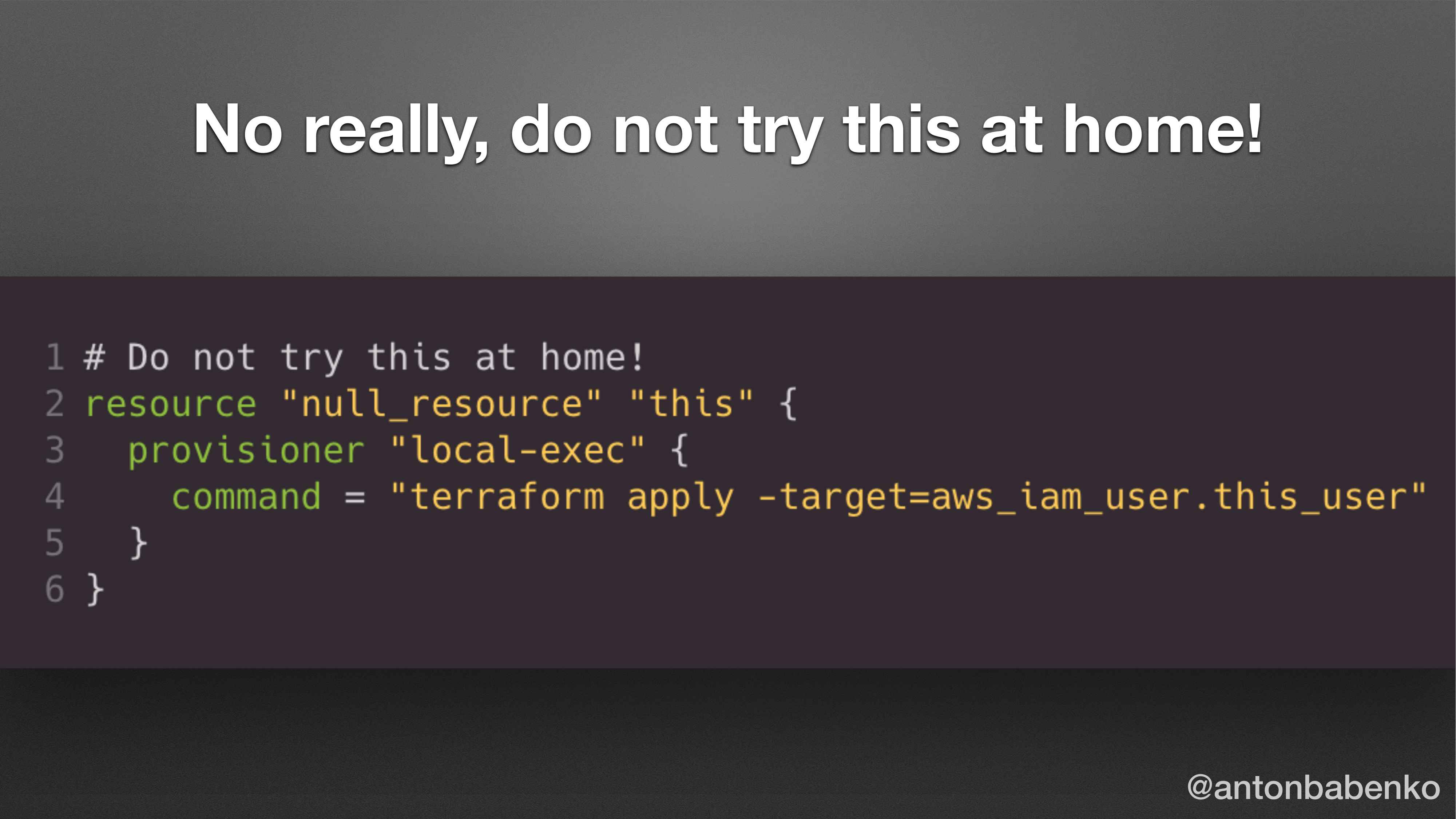
Не надо так делать, конечно. Это плохо. Почему это плохо? Потому что Terraform предназначен для линейной работы. Т. е. мы отредактировали один файл, запустили команду «Terraform apply». Подождали чуть-чуть, увидели результат. Потом зашли и изменили снова этот файл, снова запустили команду.
Все время, когда мы хотим сделать Terraform чуть умнее, чем он был изначально запланирован, этим очень легко выстрелить себе в ногу. Это один из примеров.

Есть такая штука, которая называется Terragrunt. Это чуть получше.

https://github.com/gruntwork-io/terragrunt
https://github.com/antonbabenko/terragrunt-reference-architecture
Основная цель этой утилиты – это помочь пользователям Terraform легче обращаться с Terraform-модулями.
Основной компонент, который используется внутри Terragrunt, это Terraform-модули. Не индивидуальные ресурсы, не настройки, а именно Terraform-модули. Terragrunt апеллирует исключительно Terraform-модулями.
Его можно расширять до посинения, но не надо. Terragrunt работает только как оркестратор именно этих инфраструктурных модулей.
Можете почитать документацию, посмотреть код, нажать «star» на GitHub, там уже больше 3 000 звездочек. Это значит, что людям этот проект нужен. И это здорово.
Единственное, что не здорово, это то, что это отдельный проект. Но об этом чуть попозже.
Если вы почитали документацию и думаете, что это сложно начинается, то вот вам еще одна ссылочка со всеми фичами. Я в этот проект Terragrunt-reference-architecture вкинул все фичи, которые я использую на настоящих проектов. Это настоящий проект, я только поменял название заказчика. Все зависимости, все файлы, все папки там есть. Советую посмотреть, если вы сомневаетесь или пытаетесь начать с нуля и можете наломать своих граблей, а потом расстроиться.
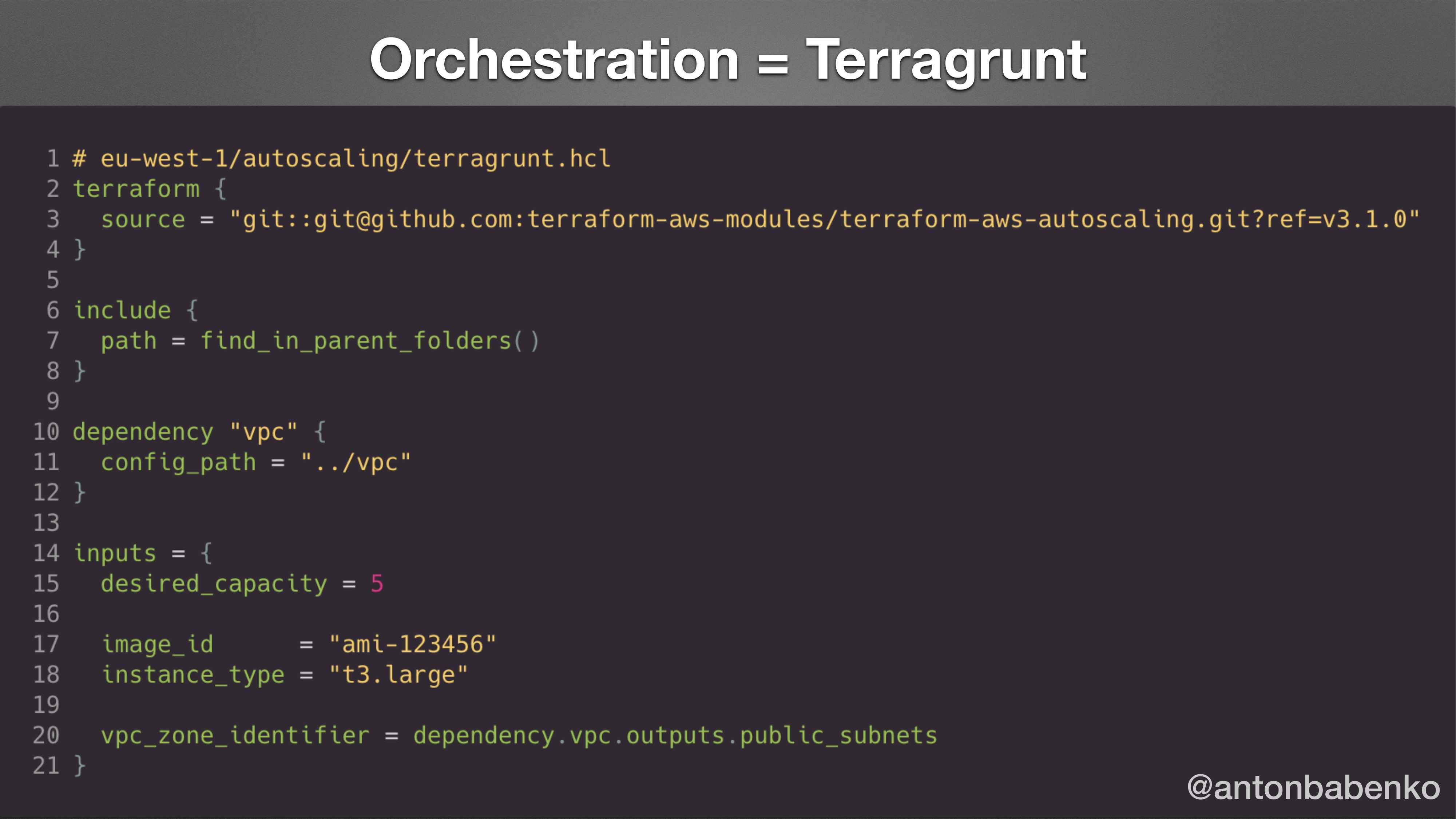
Вот это конфигурационный файл в Terragrunt. Файл с расширением .hcl. Вы можете заметить, что он чем-то похож на Terraform файл, но он со своими расширениями.
Основная строка 3 указывает, какой версии модуль взять. И блок inputs на 14-ой строчке указывает, какие аргументы передать в этот модуль. По сути, это все, что надо знать о Terragrunt.
План действий: вы заходите на registry, находите модуль. Пишите, какой модуль вы хотите использовать в строке 3. Читаете документацию, какие параметры принимает этот модуль. Пишите их в строчке 14. Нажимаете terragrunt apply и все.
Вам не надо знать ни Terraform, ни то, как он взаимодействует с ресурсами. Самое главное вам не надо разбираться, почему в AutoScaling модуле около 200-300 строк, что они там делают.
Вам надо понимать, что есть самый низкий уровень, это когда вы смотрите в исходники Terraform, AWS SDK, либо, когда вы смотрите повыше уровнем.
Если я работаю с людьми, которые не знают специфику Amazon, DevOps, инфраструктуры, то я всегда их отгораживают от Terraform-внутренностей. Максимум, что я рекомендую им смотреть, это: скажи мне какой модуль и какие значения передать.
Но не волнуйтесь: Terragrunt вас не заменит, никто вас не уволит, даже если вы будете это использовать, для вас всегда найдется работа.

Есть много разных фич внутри Terragrunt. Самая важная из них заключается в том, что есть возможность запуска hooks до и после определенных команд. Таким образом можно расширять функционал до бесконечности. Другое дело, когда вы будете слишком много hooks добавлять, вы сами споткнетесь в них и будет уже сложнее работать. Но один-два hooks ничего плохого не сделают.
И также есть возможность указания зависимости. На этом слайде в строчке 10 указано, что для того, чтобы создать autoscaling group, нам надо создать VPC. Где находится код для создания VPC? В строчке 11 указано, что он находится в папке VPC. Для того чтобы создать autoscaling group, нам надо взять список public subnet и передать его в этот список. Это делается на строчке 20 указанием dependency.vpc.outputs.public_subnets.
Наверное, кто-то думает: «А зачем так делать, если можно использовать data-source и data-source’м брать какое-то значение из state файла?». Преимуществом в том, что внутри используется нативный terraform output. Что делает Terragrunt? Он переходит в папку, которая указана тут (.vpc) и там запускает terraform outputs.public_subnets. Получают список subnets и подставляют вместо этого значения dependency.vpc. Таким образом здесь указана мягкая ссылка в значении vpc_zone_identifier. И это значение будет получено без использования data-source и т. д.
Также есть возможность запуска конфигурации на самом верхнем уровне. Если у вас инфраструктура описана как 1-in-1, когда у вас есть куча разных блоков, то вы, конечно, не хотите заходить в каждый блок и писать terragrunt apply, и ждать, пока что-то произойдет, нажимать «Yes» и т. д. Можно зайти в папку уровнем выше и написать terragrunt apply all, тогда он проверит все папки, которые внизу, поймет от какой папки зависит. И спросит: «Действительно ли ты хочешь это сделать?». Нажимаем «Да». И таким образом он создает все, что надо.
Также в Terragrunt есть поддержка pre-commit. И pre-commit hooks позволяют валидировать синтаксис Terragrunt конфигов, а также обновлять документацию.
Есть такой веб-сайт, где написана документация. Можете почитать, если разберетесь. По-моему, она сейчас написана очень плохо. До этого она была в одном файле, в котором можно было искать. Сейчас ее впихнули в красивый веб-сайт, на котором ничего не понятно.

Да, есть и плохое в Terragrunt, например, Terraform Cloud. Что это значит? Terragrunt работает здорово, когда у вас есть доступ к тому месту, где вы его запускаете.
Если вы хотите использовать Terraform Cloud, то Terragrunt тут не поможет вам. Terraform Cloud стоит много денег. И функционал, который он представляет, стоит от 0 до 70 долларов за человека в месяц. По-моему, это много денег.
И даже если прочитать документацию, проникнуться и сказать, что Terraform Cloud – это классно, а потом у вас закончатся деньги, то вы не сможете легко мигрировать в open source. Есть определенный функционал, который доступен в enterprise. Он классный, но его нет в open source версии, поэтому вам надо будет писать большое количество shell-скриптов. И опять-таки workspaces. Они работают по-разному в open source версии и в enterprise, поэтому их лучше вообще не использовать.

Что такое workspaces?

Представьте, что у вас есть одна папка с конфигурацией Terraform, вы запускаете Terraform apply. Создается там инфраструктура, все классно. И тут вы думаете, что я хочу создать эту же инфраструктуру только с чуть-чуть другими значениями. Для этого вы пишите «Terraform workspaces new» и переключаетесь на другой workspace. Потом вы пишите «Terraform plan». И Terraform plan говорит: «Я не знаю ни про какие ресурсы». Т. е. у вас есть ресурсы, которые в дефолт workspace, которые вы уже создали, и какой-то новый workspace. Новый workspace вы только создали, поэтому там ничего нет. В этом возникает 100 проблем.

Первая проблема – это то, что workspaces никак не отражены в коде. Можно написать shell-скрипты, посмотреть в bucket по названию, по имени файла догадаться.
Вторая проблема – для того чтобы правильно работать с инфраструктурой в зависимости от workspaces, в значениях должны писать условие. Например, если Terraform.workspaces = prod, то значение 5, иначе 25. Хорошо, вы так сделали для двух значений. Потом вы осознали, что у вас есть 5 environment и вы, конечно, используете lookup функцию. И берете lookup из ассоциативного массива по ключу, который называется Terraform workspaces. Все классно, вы сами себе усложняете жизнь.
Дальше приходит Вася и спрашивает: «Когда этот workspaces был задеплоен? Этот код в production или QA environment?». И вы: «Не знаю, надо спросить в slack». Начинается кошмар. А потом кто-то спрашивает: «А какая разница между staging и production environment в конфигурации?». На эти вопросы вы не сможете ответить мгновенно.
Смысл работы с инфраструктурой как код в том, что, когда вы открываете файл, то как можно быстрее и в нужном месте вы видите все значения без запуска Terraform в голове. Раньше мы открывали файл Terraform.tfvars, чтобы посмотреть, какие значения там указаны. Мы видим там версии, instances. У нас есть представление.
Когда мы используем workspaces, то мы как бы размазываем информацию по всему. Мы размазываем ее по S3_bucket, в разных state файлах она будет хранится.
И самое главное, мы вводим еще одну ось. У нас есть ось времени и сложности. И мы: «Нам этого мало, мы введем еще одну ось, которая называется workspaces name». И мы уже можем запутаться.
Основная плохая штука в workspaces заключается в том, что workspaces – это просто ненужный функционал. Можете со мной поспорить. Если вы работаете с workspaces и не потратили на работу с workspaces достаточно много времени на написание shell-скриптов, AWS-утилит, которые смотрят, подчищают ресурсы, то вам это все еще предстоит.
Есть один единственный use cases, когда workspaces имеют смысл. Я его специально сюда не написал, но я о нем иногда рассказываю. Я его не написал, потому что люди начнут говорить, что раз я его написал, значит его можно использовать.
Этот use cases имеет смысл, когда у вас есть инфраструктура, которая живет в течение всего pull request. Т. е. у вас открылся pull request, вы переключили на какой-то workspaces, создали временную инфраструктуру, задеплоили туда что-то, отправили эту ссылку в GitHub. Кто-то посмотрел, что там произошло, смержили код. И удалили эту инфраструктуру, и удалили workspaces. Таким образом, эта инфраструктура заведомо создана, чтобы быть удаленной. Для этого надо написать кое-какие утилиты. И тогда есть смысл брать инфраструктуру, которая задеплоена для production environment и просто переключать workspaces.
Я могу еще экстремальный use cases подсказать. Есть такой бэкенд, который нигде не задокументирован. Он называется inmem. Это следующая стадия за workspaces. Т. е. когда мы создаем workspaces и создаем ресурсы, то они хоть как-то где-то отражены. Если вы не хотите париться, что есть такое понятие, как Terraform state, то можете указать Terraform backend configuration type и там inmem (в памяти). Документации на официальном сайте нет, но это работает.

Решением для большинства проблем с workspaces является то, что мы делаем код, с которым работаем, более повторяющимся. И мы используем модули, конфигурация которого хранится в файле или отдельной папке, вместо излишней магии, которая называется workspaces. Таким образом, у нас есть workspaces, которые вы создаете для чего-то временного. Можно создать папку, которая называется Feature 1. В нее положить код, запустить terraform apply. Создать это все, закоммитить это все. И когда у вас эта фича отжила, написать terraform destroy.
Смысл в том, что ваш репозиторий, который содержит всю инфраструктуру, должен отражать полностью все то, что у вас происходит.
Terraform workspaces никак не отражены в коде. И это большая проблема. Я не могу посмотреть в код и сказать, что у нас есть 20 сервисов таких, 10 сервисов таких. Когда вы используете не workspaces, много проблем можно избежать. Используйте модули и будет счастье.

Вот этот слайд, наверное, надо было поставить в самом начале. В данной комнате сидят люди, которые занимаются не только Terraform. Я больше чем уверен, что здесь есть люди, которые занимаются программированием.

Terraform developers сидят в типичной компании. Если вы хотите, чтобы у вас была приличная зарплата, то вы называетесь DevOps-инженерами.
DevOps-инженеры должны использовать все фичи Terraform 0.12, т. е. циклы, динамические блоки, условия, вложенности. Для чего они делают эту всю магию? Для того чтобы показать, как юзерам внутри их компании, пользоваться всем этим.
Артефактом у DevOps-инженеров или Terraform developers является reference architectures, которую они создают. Например, если вы внутри своей компании занимаетесь ICS-сервисами, то есть 100 видов, как задеплоить сервис на Amazon с таким load balancer, с сяким и т. д. Много вариантов. Ваш cloud-архитектор или DevOps-инженер должен понимать, что нам 100 видов не надо, потому что у нас есть один способ, как мы это деплоим. Он пишет этот код, поддерживает его, вкладывает свое время и душу в него, делает его безопасным, думает, как это все будет интегрироваться. И в конце концов артефактом от этого человека будет Terraform-модуль, который он дает своему frontend-разработчику, который вообще не понимает, что такое Terraform. И говорит: «Если тебе надо будет задеплоить сервис, ты вызови этот модуль-блок и передай ему вот эти значения». Все, четкое разделение.

А Terraform юзер, который frontend developer, из 0.12 должен радоваться только тем 5 символам, которые изменились. Раньше он писал в двойных кавычках, доллар, фигурная скобка. А сейчас ему не надо их писать. Все остальные фичи Terraform 0.12 – это радость того Terraform developer, это все ему.
Не надо заставлять людей, что ты будешь full stack developer и поэтому ты должен выучить Terraform. Он хорошо разбирается в своей какой-то области, он знает, как писать frontend application. Ему не надо расширять функционал просто потому, что вы захотели. Для выполнения своей работы ему не надо в это углубляться.

Когда я провожу воркшопы, то я начинаю с простого, потом усложняю и усложняю. И когда где-то посередине люди отсеиваются, потому что все сложно, то это люди, которые frontend developer, backend developer, machine learning эксперты и т. д. А DevOps-инженеры продолжают дальше слушать, им нормально, им все понятно. Вот это как раз та граница.

Modules.tf. Что это такое? Люди это все визуализируют.

И где-то 2 года назад я подумал, что классно они там все навизуализировали, а теперь мне надо из этого сделать код.
Я часто работаю как консультант. И часто возникают такие задачи, когда кто-то что-то нарисовал, а мне потом надо описать это в коде, используя готовые модули.

https://github.com/antonbabenko/modules.tf-lambda
https://github.com/antonbabenko/modules.tf-demo
И я сделал такой генератор инфраструктура как код именно из визуальных диаграмм. На самом деле мне все равно из чего генерировать их, можно из визуальных диаграмм, можно из текстовых файлов, хоть из аудиофайлов, главное, чтобы это была какая-то структурированная штуковина с зависимостями.
Пример кода можете посмотреть – modules.tf.demo.

Берем визуальную штуку, берем готовые строительные компоненты Terraform AWS модуля. И делаем Terragrunt’ом оркестрацию вызовов этих модулей.

В принципе, все просто, да еще и бесплатно. Это open source проект.

https://asciinema.org/a/32rkyxIBJ2K4taqZLSlKYNDDI
На asciinema.org можно посмотреть, как это все работает.

Код, который появляется, подходит для того, чтобы начать работать с проектом. Туда вживлены все Terraform best practices относительно того, как взаимодействуют компоненты между собой, как используются динамические связи внутри Terragrunt.
В конечном результате код, который был сгенерирован, не содержит в себе Terraform файлов, ресурсов. Там используется только Terragrunt вызов такой-то и такой-то и все.
Советую посмотреть, если вам интересно, как можно работать с кодом как пользователь. Если вы хотите посмотреть, как оно работает внутри, как работают модули, как это все пишется, то все это open source, заходите и смотрите, отправляйте pull requests, issues и т. д.

Часто люди говорят, что это все классно, но надо сначала нарисовать, а потом это все появится в коде. Да, это так. Зато это появится в коде, вы можете это запустить. Когда вы это запустите, это появится в Amazon. Когда оно появится в Amazon, оно появится на графике у вас. Все более-менее связано. Я уверен, что многие люди хотят этого. Это довольно насыщенный рынок. Сейчас я знаю около 10 компаний в мире, которые делают похожие штуки, т. е. они все визуализируют, кто-то делает это в close course проектах.
Генерация из Terraform в визуальные диаграммы – это одна из запрашиваемых фич. Технически реализовать это несложно, если вы писали бы все в одном стиле Terraform-код, т. е. выкинули 99 % фич Terraform и все писали без использования циклов, сложных вещей. Тогда это легко было бы визуализировать. Но вы наслушаетесь моих докладов, потом вы используете модули и т. д.

https://github.com/sponsors/antonbabenko
У меня все. Есть несколько ссылок. Меня легко найти везде. Пишите, приходите завтра на конференцию Delivery excellence.
Вопросы
Спасибо за доклад! Было интересно. Небольшой коммент насчет того, что Terraform Cloud – это плохо, дорого. На самой деле там есть бесплатная фича Terraform backend. Там можно бесплатно хранить tfstate, лог файлов. Это даже лучше, чем на S3, потому что там есть Diff, а также удобно работать с командой, либо с CI. Еще есть один способ использовать Terraform pipeline. У вас был слайд all-in-one, 1-in-1. Terraform анонсировал depends_on, т. е. зависимость между модулями. Возможно, скоро Terragrunt будет бесполезен. Что вы думаете по этому поводу?
Да, это все правильно. Понятно, что Terraform Cloud существует, потому что у него есть пользователи. Но я, как представитель open source community, вижу, как 99 % функционала Terraform Cloud люди реализовывают в течение того времени, сколько я этим занимаюсь. Есть такие штуки, как Atlantis, GitHub-actions. Люди используют это очень-очень радостно.
Когда мы используем Terraform Cloud, я переживаю больше не про цену. Я переживаю, что мы насильно привязываем себя к этому функционалу, который нам не нужен. Remote state на сервере Terraform в конечном счете хранится на S3.
Эта штука классная, вопросов нет, но есть очень много решений других. Если вы хотите посмотреть на варианты, которые не Terraform Cloud, то очень рекомендую использовать Atlantis, который позволяет запускать Terraform из pull request. Т. е. открываете pull request, пишите atlantis plan. Terraform запускается не на вашем компьютере, не на каком-то Jenkins. В моем случае запускается на AWS forget instance. И ответ Terraform plan возвращается ко мне в pull request. Я вижу все это в одном месте.
Разработчик Atlassian присоединился к команде Terraform. И он сам советовал в своем блокпосте использовать бэкенд Terraform Cloud. Это бесплатно. Это тоже удобная штука.
Я знаю Люка хорошо.
Писали вы ли своих кастомных провайдеров? Если да, то насколько это сложно сделать?
По трезвому нет. У меня было интересное задание, которое я реализовывал, использовал от MasterCard REST Provider. Это настройка над провайдером, которой подсовываешь swagger файл. И он делает динамически Terraform-провайдер на основании этого swagger файл. Я ему подсовывал swagger файл и те команды, которые описаны внутри swagger файла, они работали. Это был самый простой способ начала писания. А так я иногда там что-то коммичу, но ничего серьезного.
Там есть интересная проблема. Если вы работали с Amazon, то у вас возникали ситуации, когда какая-то issue сидит в провайдере очень долго, и никто не знает, что происходит. Там upload больше сотни, народ пишет: «Что происходит? Когда эта фича будет смержена?». Люди потратили время и написали какой-то код, и провайдер уже почти готов, а Brian ничего не может сделать. Ситуаций очень много, поэтому проблем с провайдерами тоже очень много.
Спасибо за такой оживленный доклад, который расшевелил аудиторию. И хочу задать вопрос относительно рисовалки, которую вы представляли. Она тоже open source?
Cloudcraft?
Да.
Cloudcraft – не open source.
И второй момент. Вы показали, что можно, нарисовав просто структуру, трансформировать в Terraform, а затем в AWS. Такое ощущение, что какой-нибудь менеджер может нарисовать картинку и все это поднять в AWS. Насколько это сложный процесс?
Я, надеюсь, что менеджер этого делать не будет, потому что это дает только начальные данные. По идее, я должен месяц назад был закончить это, но не успел. Т. е. как сделать так, чтобы в визуальном виде запрашивать у людей больше информации? Например, когда рисуешь EC2 instance, ты можешь еще указать 50 параметров: IP-адреса, в какой subnet и т. д. Т. е. какие-то мета-данные ты должен предоставить. И это очень нетривиальная задача. Пока не знаю, но это не open source решение. Есть drowto.io, который open source, который совместимый с Cloudcraft, можно его использовать.
Спасибо за доклад! Вопрос, может быть, немного не по теме. Я хотел бы задать вопрос по поводу Terraform-модулей. Можно ли Terraform модули рассматривать в качестве замены Helm Charts?
Надеюсь, что нет.
И имею в виду в плане развития самих модулей и провайдера.
Провокационный вопрос. Terraform-модули и сам Terraform хорошо работают в создании инфраструктуры. Все, что касается provisioning, запуска сервисов, запуска shell-скриптов – это очень стремная тема для Terraform. Можно много, что делать. Можно Helm Charts создавать и запускать. В общем, есть какие-то решения. Но каждый раз, когда я работаю с Helm из Terraform, у меня какая-то боль возникает. И потом, когда я разговариваю с людьми, они мне говорят, чтобы с ним не работать. А я люблю использовать Terraform намного больше, чем я сейчас рассказал. Т. е. и Helm, и Kubernetes, и все-все применяю, используя Terraform apply. Ты запустил Terraform apply и ушел на год. Это мое видение.
Понятно, что есть необходимость для создания образов. По-прежнему есть Helm, который тоже развивается как сумасшедший. Там есть открытая issue «Helm 3 provider для Terraform», где очень оживленная дискуссия, что вот-вот будет это готово. Но об этом я, по-моему, слышу уже полгода. Там очень много проблем.
Насколько я знаю, есть Kubernetes-провайдер для Terraform. Правда, я не видел, чтобы его активно использовал.
В том то и дело. Оно все есть, но пользуется далеко не все или в каких-то ограниченных use cases. По-моему, эта проблема со всем Kubernetes-движением. Ты можешь использовать одну утилиту сегодня, завтра что-то другое выйдет, либо она отвалится. Terraform сам по себе развивается в ту сторону, чтобы дать людям возможность легко писать провайдеры, дать больше функционала для описания ресурсов. И когда приходят такие большие штуки, как Kubernetes, то они не вписываются в Terraform вообще никак. И поэтому возникает куча проблем.
Спасибо за доклад! У меня практический вопрос. Какой есть лучший способ, как в модуле считать count по output других модулей, если я передаю это list или map?
Т. е. есть модуль, который возвращает какое-то значение?
Например, если у нас есть дефолтный VPC и еще несколько VPC, которые мы создаем на основе какого-то модуля, а потом в другом модуле я хочу применить restrictions security group для всех VPC. Я передаю list.
Каждый раз, когда я слышу какие-то вопросы, я с ходу думаю, что в Terraform можно так, можно так сделать, а потом думаю, что это не будет работать, потому что значения еще не вычислены. И сразу у меня в голове возникает решение, как это сделать в Terragrunt. Т. е. в Terragrunt ты работаешь только с одним модулем. И он принимает аргументы. Одним из аргументов является output’ом из другого модуля. И в Terragrant ты, допустим, сделал бы две папки. И сначала одна запустилась, а потом из другой папки ты использовал зависимости для того, чтобы передать число туда.
Когда ты хочешь использовать только Terraform, то там очень много проблем, которые до сих пор не решены проблемы с вычисляемыми значениями, поэтому просто в Terraform такое решить сложно.
Один способ, как я иногда это решаю. Я пишу terraform apply -target и указываю один модуль, а потом пишу terragrunt apply и все остальное. Но это я пишу только тогда, когда не могу использовать Terragrunt. Т. е. надо использовать –target и надеяться, что оно не рассыплется. Оно рассыплется, скорее всего, в другом месте, но, по крайней мере, это сработает.
Антон, спасибо за доклад! У меня есть вопрос по поводу all-in-one и 1-in-1. Допустим, есть платформа. Платформа состоит из компонентов. Компоненты состоят из ресурсов AWS. Мы, например, создаем модули для ресурсов AWS, версионируем их. Дальше используем подход all-in-one и описываем компонент с помощью версионируемых модулей. И получается модуль для компонента. Дальше мы через Terragrunt, используя один файл, мы деплоим целый компонент. Почему это нелогично? Потому что я понял из твоего разговора, что логичный переход – это с all-in-one на 1-in-1.
Нет, там был слайд MFA somewhere in between. Это означает, что это ситуация, когда тебе надо использовать и то и другое. Один из use cases – это когда тебе надо управлять большим количеством маленьких вещей. Например, у тебя есть 100-500 AM user’ов и ты не хочешь под каждого из них создавать отдельный модуль. Ты пишешь один мастер-модуль и передаешь туда список этих юзеров. В таком случае у тебя all-in-one внутри используется. Эта ситуация разделения all-in-one, 1-in-1 достаточно относительная.
И я больше хотел показать, что есть такие способы. Есть один способ, есть второй способ. И ты знаешь преимущество и одного, и второго способа. И тогда можно придумать третий способ, который где-то посередине. В живых проектах полностью all-in-one я не встречал. Если до фанатизма все разделять, то получается непрактично. И получается много кода, который можно сгруппировать.
Комментариев нет:
Отправить комментарий