
Однажды я решил засучить рукава и найти ответы на следующие вопросы:
- Что именно потребляет так много памяти?
- Можно ли как-то этого избежать?
Здесь я хочу рассказать о том, как искал ответы на эти вопросы. Я планирую пользоваться этим материалом как справочником в тех случаях, когда мне придётся заниматься профилированием Python-кода.
Я приступил к анализу Pylint, начав с точки входа в программу (
pylint/__main__.py), и добрался до «фундаментального» цикла for, наличие которого можно ожидать в программе, которая проверяет множество файлов:
def _check_files(self, get_ast, file_descrs):
# в файле pylint/lint/pylinter.py
with self._astroid_module_checker() as check_astroid_module:
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
Для начала я просто поместил в этот цикл инструкцию
print(«HI») чтобы убедиться в том, что это и правда тот цикл, который запускается тогда, когда я выполняю команду pylint my_code. Этот эксперимент прошёл без проблем.
Далее, я решил узнать о том, что именно хранится в памяти в ходе работы Pylint. Поэтому я, пользуясь heapy, сделал простой «дамп кучи», надеясь проанализировать этот дамп на предмет наличия в нём чего-нибудь необычного:
from guppy import hpy
hp = hpy()
i = 0
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
print("HEAP")
print(hp.heap())
if i == 100:
raise ValueError("Done")
Профиль кучи, в итоге, оказался почти полностью состоящим из кадров стека вызовов (
types.FrameType). Я, по некоторым причинам, ожидал чего-то подобного. Такое количество подобных объектов в дампе навело меня на мысль о том, что их, похоже, больше, чем должно было бы быть.
Partition of a set of 2751394 objects. Total size = 436618350 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 429084 16 220007072 50 220007072 50 types.FrameType
1 535810 19 30005360 7 250012432 57 types.TracebackType
2 516282 19 29719488 7 279731920 64 tuple
3 101904 4 29004928 7 308736848 71 set
4 185568 7 21556360 5 330293208 76 dict (no owner)
5 206170 7 16304240 4 346597448 79 list
6 117531 4 9998322 2 356595770 82 str
7 38582 1 9661040 2 366256810 84 dict of astroid.node_classes.Name
8 76755 3 6754440 2 373011250 85 tokenize.TokenInfo
Именно в этот момент я нашёл инструмент Profile Browser, который позволяет удобно работать с подобными данными.
{kind=link}
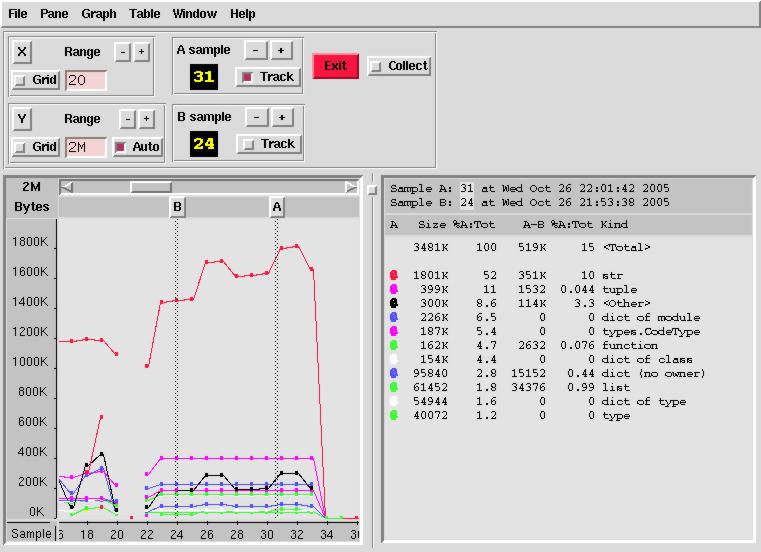
Я настроил механизм создания дампа так, чтобы данные записывались бы в файл каждые 10 итераций цикла. Потом я построил диаграмму, отражающую поведение программы во время работы.
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
hp.heap().stat.dump("/tmp/linting.stats")
if i == 100:
hp.pb("/tmp/linting.stats")
raise ValueError("Done")
У меня получилось то, что показано ниже. Эта диаграмма подтверждает то, что объекты
type.FrameType и type.TracebackType (трассировочная информация) потребляли много памяти в ходе исследуемого запуска Pylint.

Анализ данных
Следующим этапом исследования был анализ объектов types.FrameType. Так как механизмы управления памятью в Python основаны на подсчёте количества ссылок на объекты, данные хранятся в памяти до тех пор, пока что-то на них ссылается. Я решил узнать о том, что именно «держит» данные в памяти.
Тут я воспользовался отличной библиотекой objgraph, которая, пользуясь возможностями менеджера памяти Python, даёт сведения о том, какие именно объекты находятся в памяти, и позволяет узнать о том, что именно ссылается на эти объекты.
На самом деле, это просто замечательно, что у нас есть возможность проводить подобные исследования программ. А именно, если имеется ссылка на объект, можно найти всё то, что ссылается на этот объект (в случае с C-расширениями всё не так уж и гладко, но, в целом, objgraph даёт достаточно точные сведения). Перед нами — отличный инструмент для отладки кода, дающий доступ к массе сведений о внутренних механизмах CPython. Для меня это — очередной повод считать Python языком, с которым приятно работать.
Поначалу я споткнулся на поиске объектов, так как команда objgraph.by_type('types.TracebackType') не находила вообще ничего. И это — несмотря на то, что я знал о том, что имеется огромное количество подобных объектов. Оказалось же, что в качестве имени типа надо использовать строку traceback. Причина этого мне не вполне ясна, однако что есть — то есть. Правильная команда, в итоге, выглядит так:
random.choice(objgraph.by_type('traceback'))
Эта конструкция случайным образом выбирает объекты
traceback. А с помощью objgraph.show_backrefs можно построить диаграмму того, что ссылается на эти объекты.
В итоге я, вместо простого вызова исключения, решил исследовать то, что происходит в цикле for (import pdb; pdb.set_trace()) через 100 итераций. Я начал изучать случайным образом выбираемые объекты traceback.
def exclude(obj):
return 'Pdb' in str(type(obj))
def f(depth=7):
objgraph.show_backrefs([random.choice(objgraph.by_type('traceback'))],
max_depth=depth,
filter=lambda elt: not exclude(elt))
Изначально я видел лишь цепочки из объектов
traceback, поэтому я решил забраться на глубину в 100 объектов…

Анализ объектов traceback
Как оказалось, одни объекты traceback ссылаются на другие такие же объекты. Ну что ж — хорошо. И таких цепочек было очень много.
Я какое-то время, без особого успеха для дела, их изучал, а потом перешёл к исследованию объектов второго интересовавшего меня типа — FrameType (frame). Они тоже выглядели подозрительно. Я, анализируя их, пришёл к диаграммам, напоминающим следующую.

Анализ объектов frame
Оказывается, что объекты traceback удерживают объекты frame (поэтому имеется схожее количество таких объектов). Всё это, конечно, выглядит до крайности запутанным, но объекты frame, по крайней мере, указывают на конкретные строки кода. Всё это привело меня к тому, что я осознал одну до смешного простую вещь: я никогда не утруждал себя тем, чтобы взглянуть на данные, использующие настолько большие объёмы памяти. Мне, определённо, следовало бы взглянуть на сами объекты traceback.
Шёл я к этой цели, похоже, самым извилистым из всех возможных путей. А именно, узнавал адреса в дампе, созданном objgraph, потом смотрел на адреса в памяти, потом искал в интернете по словам «как получить Python-объект, зная его адрес». После всех этих экспериментов я вышел на следующую схему действий:
ipdb> import ctypes
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object)
py_object(<traceback object at 0x7f187d22b880>)
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object).value
<traceback object at 0x7f187d22b880>
ipdb> my_tb = ctypes.cast(0x7f187d22b880, ctypes.py_object).value
ipdb> traceback.print_tb(my_tb, limit=20)
Фактически, можно просто сказать Python следующее: «Взгляни-ка на эту память. Тут, определённо, имеется хотя бы обычный объект Python».
Позже я понял, что ссылки на интересующие меня объекты у меня уже были благодаря objgraph. То есть — я мог просто воспользоваться ими.
Возникало такое ощущение, что библиотека astroid, AST-парсер, используемый в Pylint, повсюду создаёт объекты traceback через код обработки исключений. Я так полагаю, что когда где-то используют нечто такое, что можно назвать «интересным приёмом», то попутно забывают о том, как то же самое можно сделать проще. Поэтому я на это особо не жалуюсь.
В объектах traceback имеется много данных, имеющих отношение к astroid. В моём исследовании наметился некоторый прогресс! Библиотека astroid вполне похожа на программу, способную держать в памяти огромные объёмы данных, так как она занимается парсингом файлов.
Я порылся в коде и нашёл следующие строки в файле astroid/manager.py:
except Exception as ex:
raise exceptions.AstroidImportError(
"Loading {modname} failed with:\n{error}",
modname=modname,
path=found_spec.location,
) from ex
«Вот оно, — подумал я, — это именно то, что я ищу!». Это — последовательность исключений, которая приводит к появлению длиннейших цепочек объектов
traceback. А тут ведь, кроме прочего, выполняется парсинг файлов, поэтому здесь могут встречаться и рекурсивные механизмы. А нечто, напоминающее конструкцию raise thing from other_thing, связывает всё это воедино.
Я убрал from ex и… ничего не произошло. Объём памяти, потребляемый программой, остался практически на прежнем уровне, объекты traceback тоже никуда не делись.
Мне было известно то, что исключения хранят свои локальные привязки в объектах traceback, поэтому можно добраться и до ex. В результате память от них очистить не удаётся.
Я занялся масштабным рефакторингом кода, пытаясь, в основном, избавиться от блока except, или хотя бы от ссылки на ex. Но, опять же, ничего не добился.
Я, хоть тресни, не смог «натравить» сборщик мусора на объекты traceback, даже учитывая то, что на эти объекты не было никаких ссылок. Я полагал, что причина происходящего в том, что где-то есть ещё какая-то ссылка.
На самом деле, я взял тогда ложный след. Я не знал о том, является ли именно это причиной утечки памяти, так как в один прекрасный момент я начал понимать то, что у меня нет никаких свидетельств, подтверждающих мою «теорию цепочек исключений». У меня была лишь куча догадок и миллионы объектов traceback.
Тогда я начал наугад просматривать эти объекты в поисках каких-то дополнительных подсказок. Я пытался вручную «взбираться» по цепочке ссылок, но в итоге находил лишь пустоту.
Потом до меня дошло: все эти объекты traceback расположены «один над другим», но должен быть такой объект, который находится «выше» всех остальных. Такой, на который не ссылается ни один из других таких объектов.
Ссылки были сделаны через свойство tb_next, последовательность таких ссылок представляла собой простую цепочку. Поэтому я решил взглянуть на объекты traceback, находящиеся в конце соответствующих цепочек:
bottom_tbs = [tb for tb in objgraph.by_type('traceback') if tb.tb_next is None]
Есть нечто волшебное в том, чтобы пробиться с помощью однострочника через полмиллиона объектов и найти то, что нужно.
В общем-то, я нашёл то, что искал. Нашёл причину, по которой Python вынужден был держать в памяти все эти объекты.

Поиск источника проблемы
Всё дело было в файловом кеше!
Речь идёт о том, что библиотека astroid кеширует результаты загрузки модулей. Если коду нужен будет модуль, который уже использовался, библиотека просто предоставит ему уже имеющийся у неё результат загрузки этого модуля. Это приводит и к воспроизведению ошибок путём хранения выброшенных исключений.
В этот момент я принял смелое решение, рассуждая так: «Имеет смысл кешировать нечто, не содержащее ошибок. Но, по-моему, нет смысла хранить объекты traceback, генерируемые нашим кодом».
Я решил избавиться от исключения, сохранить собственный класс Error и просто перестраивать исключения тогда, когда это было нужно. Подробности можно найти в этом PR, но он, правда, получился не особенно интересным.
В результате мне удалось снизить потребление памяти при работе с нашей кодовой базой с 500 Мб до 100 Мб.
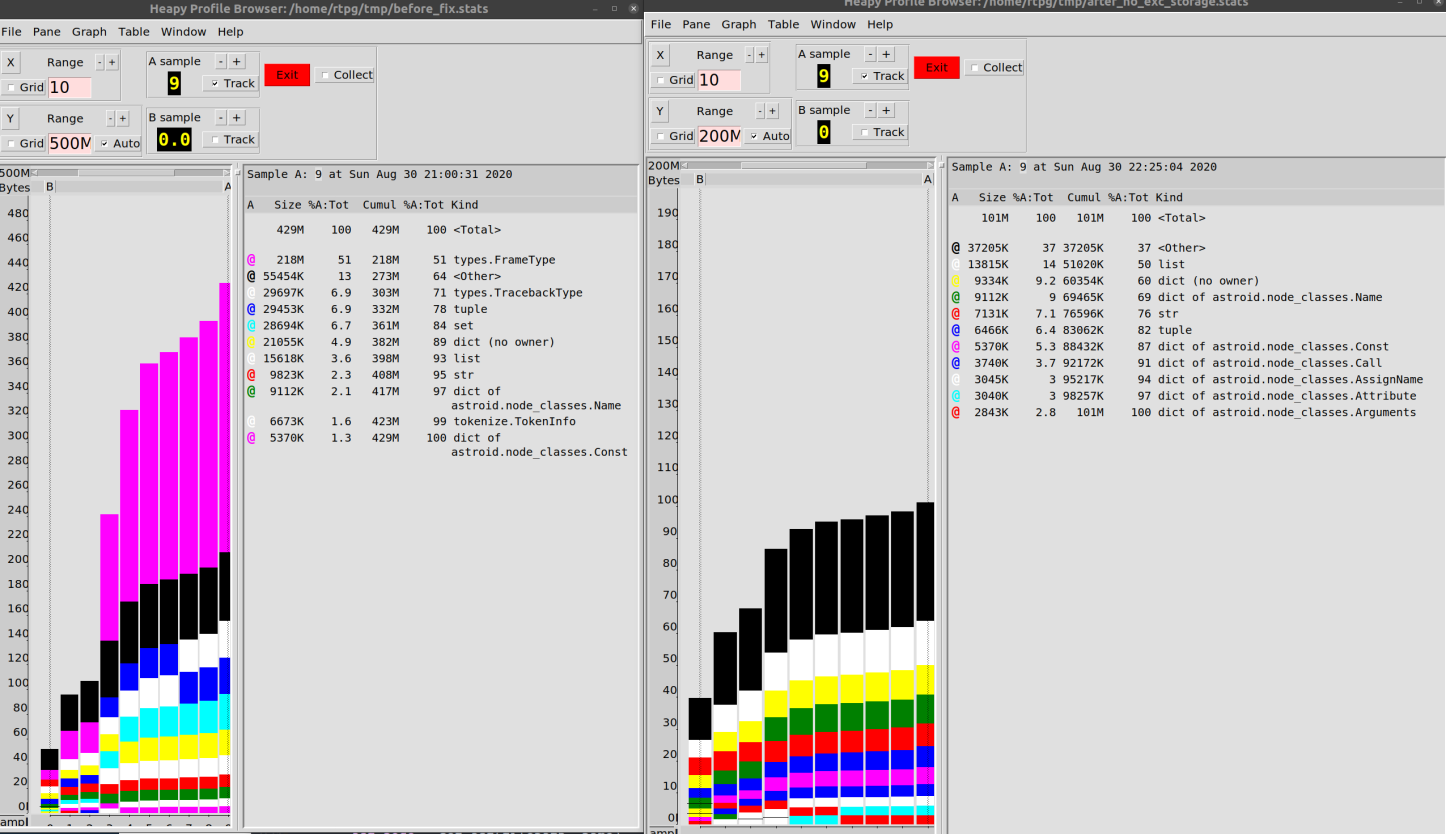
Я бы сказал, что улучшение на 80% — это не так уж и плохо
Если говорить о том PR, то я не уверен в том, что он будет включён в проект. Изменения, которые он в себе несёт, имеют отношение не только к производительности. Я полагаю, что реализованная в нём схема работы может, в некоторых ситуациях, уменьшить ценность данных о трассировке стека. Это, учитывая все детали, довольно грубое изменение, даже принимая во внимание то, что это решение успешно проходит все тесты.
В результате я сделал для себя следующие выводы:
- Python даёт нам замечательные возможности по анализу памяти. Мне следует чаще прибегать к этим возможностям при отладке кода.
- Теории надо подкреплять реальными доказательствами, а не догадками.
- Стоит, исследуя что-либо, записывать «текущие цели». Это позволит не потерять связь с исходной проблемой в процессе отладки. Поступи я именно так, я сэкономил бы себе несколько часов и не отклонился бы от цели, не отвлёкся бы на то, что не было связано с моей проблемой.
- Крайне полезно сохранять фрагменты кода, появляющиеся и исчезающие в процессе работы (или, ещё лучше, коммитить их в Git). Может возникнуть искушение просто удалять подобные вещи, но позже может понадобиться узнать о том, как достигнуты некие результаты. Особенно это важно в делах, связанных с производительностью.
Я, пока это писал, понял, что уже забыл многое из того, что позволило мне прийти к определённым выводам. Поэтому я, в итоге, ещё раз проверил некоторые фрагменты кода. Потом я запустил измерения на другой кодовой базе и выяснил, что странности с потреблением памяти характерны лишь для одного проекта. Я потратил массу времени на поиск и устранение этой неприятности, но весьма вероятно то, что это — лишь особенность поведения используемых нами инструментов, которая проявляется только у небольшого количества тех, кто применяет эти инструменты.
Говорить что-то определённое о производительности очень сложно даже после проведения подобных измерений.
Я постараюсь перенести опыт, полученный в ходе описанных мной экспериментов, и на другие проекты. Я полагаю, что в опенсорсных Python-проектах имеется множество таких проблем с производительностью, справиться с которыми достаточно просто. Дело в том, что сообщество Python-разработчиков обычно уделяет этому вопросу сравнительно мало внимания (это — если не говорить о проектах, представляющих собой расширения для Python, написанные на C).
Приходилось ли вам оптимизировать производительность Python-кода?


Комментариев нет:
Отправить комментарий