Момент посадки на Марс ровера NASA Perseverance (Настойчивость) стал историческим событием. Человечество впервые увидело нечто подобное. Многие люди с замиранием сердца наблюдали за происходящим. «Настойчивость» многие годы будет служить для нас источником вдохновения.
Каждое изображение, поступающее с Марса после успешной посадки ровера, содержало в себе какой-то сюрприз. Одним из таких сюрпризов стало сообщение, зашифрованное в раскраске парашюта марсохода.
Интернет-ищейки заявили о том, что им удалось расшифровать скрытое сообщение, нанесённое на купол парашюта, который помог роверу безопасно приземлиться на поверхность Красной планеты. Как оказалось, фраза «Dare Mighty Things» («Решайтесь на великие поступки») — девиз лаборатории реактивного движения NASA (Jet Propulsion Laboratory) — была закодирована на парашюте с использованием красных и белых полос, представляющих двоичный компьютерный код. Этот код, что неудивительно, можно, используя некоторые вычисления, перевести в кодировку ASCII и, в итоге, понять то, что в нём скрыто.

Ровер сделал этот снимок парашюта в процессе посадки на поверхность Марса
Пользователи Reddit и Twitter обратили внимание на то, что красно-белый узор похож на нечто, способное нести в себе какой-то смысл. Они расшифровали послание, решив, что красные фрагменты представляют единицы, а белые — нули.
Эта история разлетелась по всему миру, благодаря ей кодировка ASCII, о которой говорят не особенно часто, оказалась у всех на слуху.
В этом материале мы поговорим об ASCII, немного коснёмся истории этой кодировки, разберём пример её применения в программном коде. Прочитав эту статью, вы поймёте, что очень сложно не полюбить ASCII, кое-что о ней узнав.
Протокол ASCII
ASCII — это кодировка. Это не протокол. Протоколы могут быть построены на основе ASCII.
На самом деле, так оно и есть, но во множестве документов, которые можно встретить в интернете, ASCII называют не только «кодировкой», но и «протоколом». Поэтому я заранее хочу обратить на это ваше внимание, так как могу называть ASCII и так и так.
ASCII можно назвать самым простым коммуникационным протоколом для передачи текста. При его использовании передаются только обычные и управляющие ASCII-символы. Он предусматривает минимальный контроль ошибок или полное его отсутствие.
Может, в это сложно поверить, но ASCII — это весьма мощная технология. Это — единственный формат данных, который может декодировать любая из существующих компьютерных систем.
Немногие знают о том, что кодировка ASCII появилась в 1960-х годах, когда Лабораториям Белла (Bell Labs) понадобился стандартный способ для передачи текста. Сотрудники Bell Labs реорганизовали телеграфные коды, разобрали их и, совместно с Американской ассоциацией стандартов (American Standards Association, ASA), сформировали ASCII (American Standard Code for Information Interchange, Американский стандартный код для обмена информацией). 1960-е — это время бурного развития компьютерных технологий. Создатели вычислительных машин использовали ASCII. В результате эта кодировка и стала общепризнанным стандартом передачи информации.
XML (eXtensible Markup Language, Расширяемый язык разметки) — это язык, используемый для организации хранения компьютерных данных и для их передачи из одного места в другое. Он построен исключительно с применением ASCII-кодов. Каждый XML-элемент начинается и оканчивается угловой скобкой, которая является ASCII-символом. Даже числовые данные в XML кодируются с помощью ASCII. Например, сведения о давлении чернил кодируются с помощью элементов InkPressure, представляющих собой длинные последовательности ASCII-кодов:
<InkPressure>2.3145</InkPressure>
Почему вокруг так много всего связано с ASCII? Дело в том, что это отражает то, как люди общаются друг с другом. Для общения мы используем буквы, цифры и специальные символы. В мире, например, очень много всего такого, что надо как-то маркировать. Речь идёт о товарных этикетках, о коробках, об автомобильных покрышках, и много о чём ещё. Компьютеры должны считывать маркировку, что они и делают, используя сканеры штрих-кодов. Потом, если речь идёт о штрих-кодах, их надо преобразовать в ASCII-символы, с которыми уже выполняются дальнейшие действия.
Типичный пример использования ASCII — это составление команд и запросов, которые можно отправлять промышленным устройствам, которые, реагируя на них, выполняют какие-то действия, или отправляют в ответ сведения о собственном состоянии.
Что такое протокол?
Представим, что вы попали на аудиенцию к королеве. При этом кто-то из дворцовых служащих сообщает вам о том, каких правил принято придерживаться во время этого мероприятия. Эти правила и называют протоколом. Понятие «протокол» часто используется в компьютерном мире. Вы вводите веб-адрес в адресную строку браузера, нажимаете Enter, это приводит к выполнению множества операций, браузер и сервер обмениваются данными, после чего запрошенная страница выводится на экране. В ходе обмена данными между сервером и браузером используется определённый набор протоколов.
Понятие «сетевой протокол» скрывает в себе множество смысловых уровней. Обычно «протокол» — это механизм, используемый для передачи пакетов с данными между компьютерами. Но тут мы не будем обращать внимание на транспортную составляющую обмена данными. Мы сосредоточимся на исследовании тех данных, которые передаются по сетям. В частности — изучим сообщения, которые программы отправляют другим программам.
Биты, байты и представление информации
Итак, мы уже немного поговорили об ASCII, а ниже я продемонстрирую примеры работы с ASCII в коде. Но прежде чем я это сделаю, предлагаю немного отклониться от нашей основной темы и поговорить о том, как в цифровом мире кодируется и хранится информация.
«Цифровое представление информации» — это когда всё что угодно представляют исключительно с помощью чисел. Обычная последовательность работы при таком подходе выглядит так:
- Нечто (звук, изображение, текст, набор команд…) преобразуют в цифровую форму с использованием некоего механизма.
- Полученные цифровые данные можно сохранить на соответствующем носителе и прочитать с него, их можно как-то обработать, их можно куда-то передать.
- Из цифровых данных можно воссоздать нечто, более или менее близкое к оригиналу, на основе которого они созданы.
Двоичные, восьмеричные, десятичные, шестнадцатеричные числа
Существует множество способов представления чисел. Например, возьмём двоичное число 10011111.
Оно равнозначно следующим числам:
- 237 в восьмеричной системе счисления;
- 157 в десятичной системе счисления;
- 9F в шестнадцатеричной системе счисления.
Все эти числа представляют одно и то же значение. При этом его шестнадцатеричная запись гораздо короче и понятнее двоичной. Именно поэтому в инструкциях ко многим промышленным устройствам можно видеть различные команды, представленные в шестнадцатеричном виде.
Для того чтобы передавать данные по компьютерным сетям эти данные надо представлять в виде байтов. Байт — это группа из 8 битов. С помощью одного байта можно закодировать десятичное число в диапазоне от 0 до 255.
[STX][status][type][length][user data…][checksum][ETX]
Эта конструкция используется для представления неких данных. Ведь, как известно, компьютер не может хранить «буквы», «цифры», «изображения» или что угодно другое. Компьютер может работать лишь с битами. А бит может пребывать лишь в одном из двух значений: «да» или «нет», «истина» или «ложь», «0» или «1». Называть их можно по-разному, но всё сводится к тому, что их всего два.
Для того чтобы использовать биты для представления чего-то, отличного от «нулей» и «единиц», нужны некие правила. Нужна возможность преобразовывать последовательности битов в нечто вроде букв, цифр, изображений. Делается это с применением некоей схемы кодирования, которую обычно называют просто «кодировкой».
Тут мы говорим о схеме кодирования ASCII. В этой кодировке определено 128 символов (для кодирования 1 символа используется 7 битов). Ниже приведён её фрагмент.
Фактически, при использовании ASCII работа ведётся не с «символами» или с «текстами». Всё сводится к манипулированию битами, «видимыми» через несколько слоёв абстракции.
Помимо ASCII существуют и другие способы кодирования символов, другие способы преобразования последовательностей битов в текстовые данные. Например, это набор символов Unicode. Если имеется соответствие между битами, из которых составлена строка, и кодами Unicode-символов — битовое представление строки можно преобразовать в нечто осмысленное. Если такого соответствия нет — подобное преобразование выполнить не получится.
Для преобразования двоичных данных в числа, которые соответствуют номерам из набора символов Unicode (и для преобразования кодов символов в двоичные данные), могут применяться различные кодировки. В частности, это кодировка UTF-8. Она совместима с ASCII, для представления ASCII-символов в ней применяются 1-байтные коды. Для представления символов из набора Unicode в ней может применяться до 4 байтов на 1 символ.
Если две компьютерные системы обмениваются друг с другом данными, им нужно договориться о том, какую именно кодировку они используют. Например, текстовые данные, представленные на этой странице, закодированы с использованием UTF-8, о чём сервер, передавший страницу, сообщает браузеру, который её принял и вывел на экран.
STX / ETX (протокол ASCII)
Помните вышеприведённую конструкцию? Повторим её ещё раз:
[STX][status][type][length][user data…][checksum][ETX]
Сокращения STX и ETX обычно используются для обозначения управляющих символов ASCII. У них нет графического представления, они не могут быть выведены на экран, поэтому там, где они используются, обычно применяют их сокращённые наименования. На практике они заменяются на соответствующие ASCII-символы. А именно, STX заменяется на ASCII-символ с кодом 0x02, а ETX — на символ с кодом 0x03.
В записи кодов управляющих символов использована конструкция 0x. Она указывает на применение шестнадцатеричных кодов. Например, 0x01 — это, в десятичном представлении, 1, а в двоичном — 00000001. 0x10 — это 16 в десятичном представлении и 00010000 в двоичном.
С помощью управляющих символов STX (Start of TeXt, начало текста) и ETX (End of TeXt, конец текста) можно сформировать простой пакет, в который упаковываются пользовательские данные. В таком пакете, помимо признаков начала и конца текста, присутствует контрольная сумма (checksum), которая позволяет организовать надёжную передачу данных. Возможно, вы видели подобные конструкции в коде, предназначенном для обмена данными с некими устройствами по сети или через порт RS232.
Пример кода: отправка ASCII-команд через TCP/IP
Исходя из предположения о том, что у нас уже имеется установленное сетевое соединение, нам, для организации обмена данными между программами, нужно всего лишь отправить по этому соединению соответствующую строку. При этом, например, символ STX будет представлен в виде '\x02', а передача H — в виде '\x02H\x04'.
ASCII-команды можно отправлять с использованием различных каналов связи. В моём примере будет использован TCP-канал. Пример написан на C# (мы рассмотрим и JavaScript-пример, рассчитанный на платформу Node.js). Этот код будет понятен и тем, кто знает Java.
▍Обзор проекта
Итак, мы будем разрабатывать простое клиент-серверное TCP-приложение.
Клиент может быть чем угодно — устройством, Linux-процессом, консольным приложением .NET Core (в нашем случае используется именно такой клиент).
То же самое касается и сервера. Сервером может быть некое промышленное устройство, или, скажем, марсоход. Помните, как я говорил о том, что ASCII — это единственный формат, понятный всем существующим земным компьютерам? Это относится и к компьютерам, находящимся на Марсе. Наш сервер, правда, не имеет отношения к Марсу. Он будет представлен ещё одним консольным приложением .NET Core.
Вот пример выходных данных, генерируемых в ходе работы нашей клиент-серверной системы.
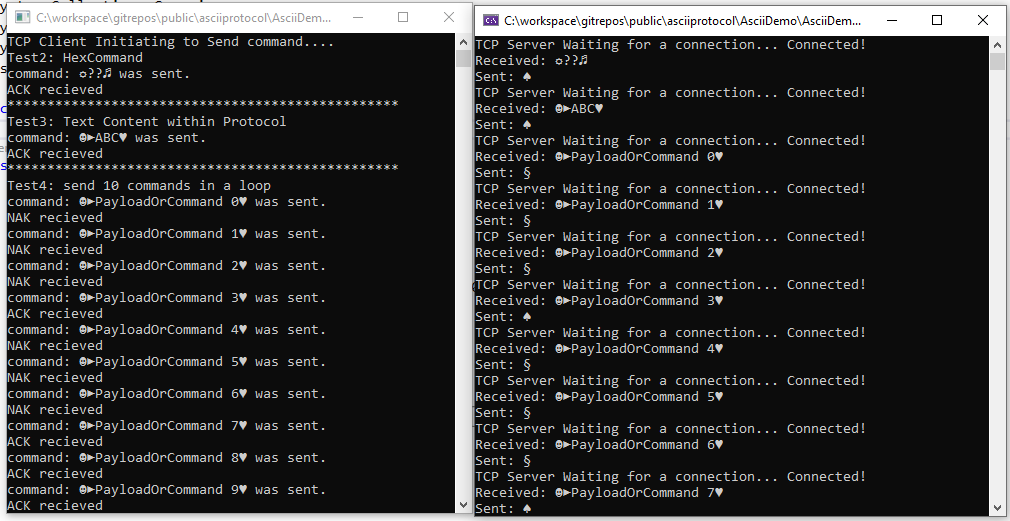
Пример работы клиент-серверной системы
▍И что всё это значит?
Если вы задались вопросом, который вынесен в заголовок этого раздела — знайте, что меня это порадовало. Сейчас я всё это объясню, прибегнув к фрагментам кода моего приложения. Его полную версию, с которой вы можете поэкспериментировать самостоятельно, можно найти в этом репозитории на GitHub.
Для начала взглянем на структуру проекта. Здесь у меня имеются два .NET Core-приложения. Одно из них — это TCP-клиент, а второе — TCP-сервер. Тут, кроме того, используются некоторые стандартные библиотеки.

Структура проекта
▍TCP-клиент
AsciiDemo.TestApp — это наш TCP-клиент. Вот его код (файл Program.cs):
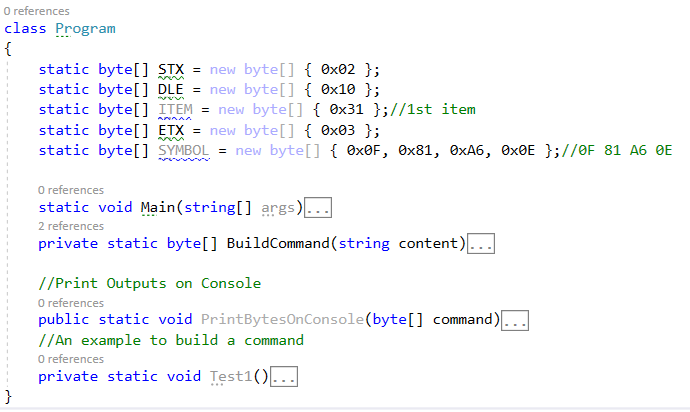
Код класса Program
Метод Main является точкой входа в приложение.

Код метода Main
Этот код устроен очень просто, но если у вас есть по нему вопросы — можете задать их мне. Здесь мы сначала подготавливаем некоторые команды, используя кодировку ASCII, затем преобразуем их в байты и отправляем по сети TCP-серверу. Тут же мы выводим сообщения в консоль.
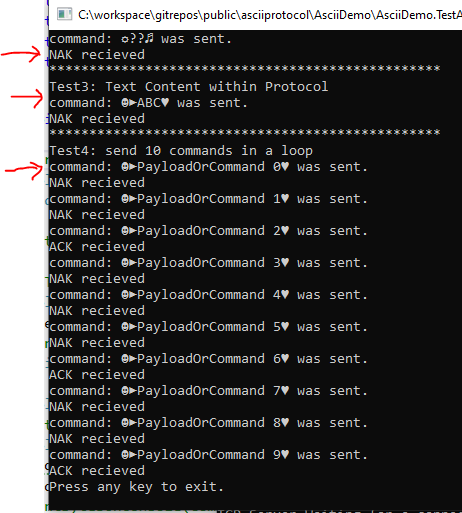
Сеанс связи с точки зрения клиента
Обратите внимание на то, что мы получаем от сервера подтверждения (ACK/NAK) о получении данных (об этом мы поговорим ниже). В результате оказывается, что наш TCP-клиент может не только отправлять команды серверу, но и получать от сервера ответы.
В консоли можно видеть некоторые необычные символы. Это — визуальные представления управляющих символов, о которых мы говорили выше.
Вот код метода BuildCommand, который используется для составления команд с использованием ASCII.
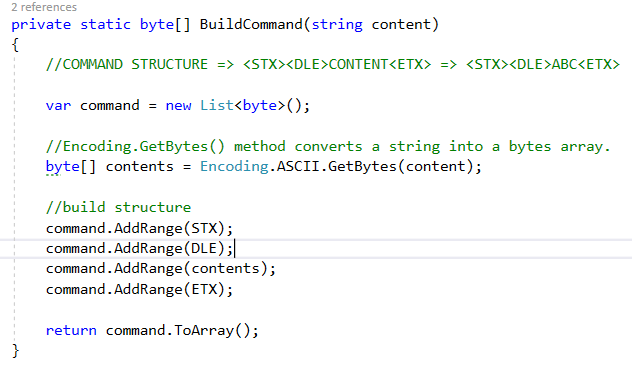
Код метода BuildCommand
Я не рассматривают тут код метода TCP-клиента SendCommand, так как в нём нет ничего особенного. Это — обычный сетевой C#-код, подобный тому, который используется на сервере. Вы, в любом случае, можете сами посмотреть этот код, обратившись к репозиторию проекта.
▍TCP-сервер
AsciiDemo.TCPListenerApp — это простейший TCP-сервер. Он прослушивает заданный порт, ожидая поступления команд. После получения команды он просто выводит её в консоль (если подобные команды используются для управления неким устройством — оно может, например, выключиться, или прочесть показания некоего датчика), а затем отправляет ответ. В данном случае выполняется отправка ответов ACK или NAK, имитирующих, соответственно, успешное или неудачное выполнение команды. Если нужно — можно организовать любую другую реакцию сервера на подобные команды.
Вот как выглядит то, что выводит в консоль сервер.
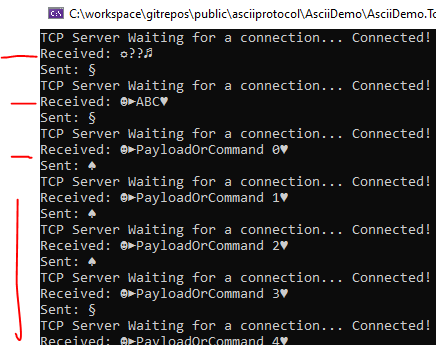
Сеанс связи с точки зрения сервера
Как видно, каждый раз, получая команду от клиента, сервер выводит её в консоль, а после этого отправляет клиенту ACK или NAK. То, что происходит в это время на клиенте, мы уже видели.
Вот код метода Main TCP-сервера:
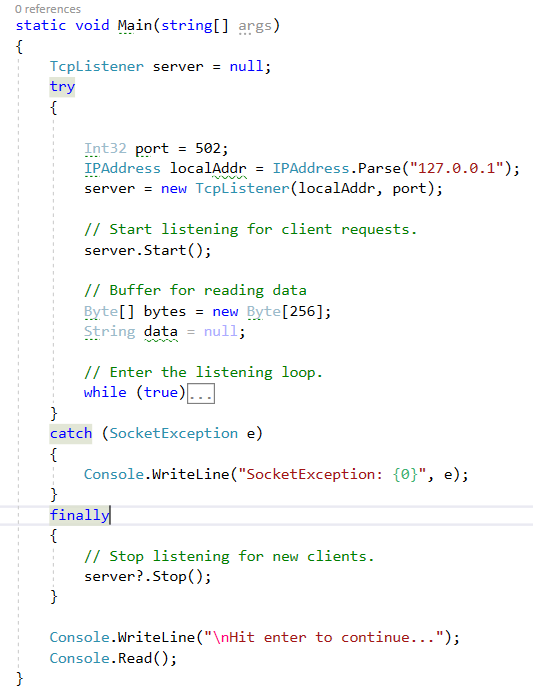
Код метода Main
Тут всё устроено очень просто. Сначала мы запускаем сервер на заданном IP-адресе и порте, а потом сервер, в соответствующем цикле, ждёт поступления данных. Вот код этого цикла.

Цикл, используемый в работе сервера
В этом цикле, при наличии соединения, выполняется чтение байтов данных с помощью NetworkStream.
Байты мы преобразуем в ASCII-символы, выводим их в консоль, а после этого отправляем клиенту байты, соответствующие кодам управляющих символов ACK или NAK.

Получение данных от клиента и отправка ему ответа
▍Node.js-реализация клиента
Как уже было сказано, подобный функционал можно реализовать и с использованием других языков программирования. Вот, например, вариант реализации простого TCP-клиента для платформы Node.js.
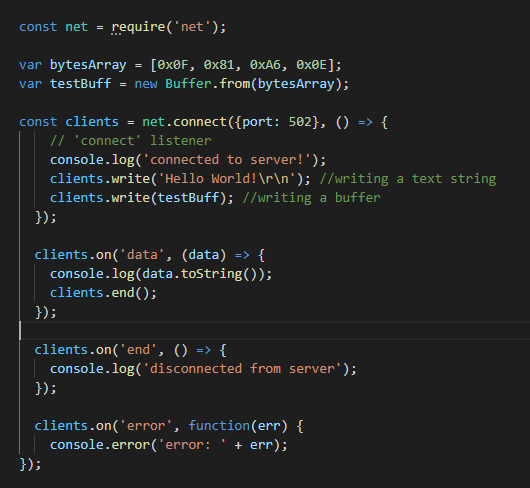
TCP-клиент для Node.js
Попробуем организовать взаимодействие Node.js-клиента с нашим .NET Core-сервером.
Вот что выведет в консоль клиент.
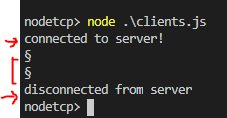
Сеанс связи с точки зрения Node.js-клиента
Клиент подключается к серверу, отправляет ему две команды и выводит ACK/NAK-ответы сервера.
А вот как подобный сеанс связи выглядит с точки зрения .NET Core-сервера.
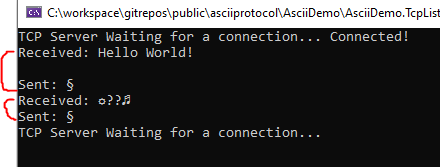
Сеанс связи с точки зрения .NET Core-сервера
Сервер получает команды от клиента и отправляет ему ответы.
Итоги
Полагаю, что ASCII — это просто потрясающе. Это простая и мощная кодировка, на основе которой несложно создавать коммуникационные протоколы. И она будет актуальна до тех пор, пока люди общаются, используя буквы и цифры.
Использование ASCII при составлении команд и запросов восходит к временам ранних мейнфреймов IBM, при работе с которыми применялись терминалы. Оператор вводил на терминале команды и нажимал на клавишу Return для отправки их компьютеру. Все взаимодействия с этими компьютерами, так как работали с ними люди, были основаны на стандартном ASCII.
Везде, где используется некая маркировка чего-либо, применяется ASCII. Например, каждый сканер штрих-кодов, в сущности, работает с последовательностями ASCII-символов. Эти символы где-то хранятся, их нужно распечатывать, иногда их надо преобразовывать в числовые данные.
Даже сегодня, когда в нашем распоряжении имеются современные протоколы для промышленных устройств, ASCII не теряет актуальности. И так будет ещё очень и очень долго.
Приходилось ли вам создавать собственные реализации протоколов, основанных на ASCII и применяемых для обмена данными с некими устройствами?

Комментариев нет:
Отправить комментарий