Предыстория/Мотивация
Все началось с хобби в начале 2020 года — с очередной попытки написания эмулятора игрового сервера Lineage 2 "по новому". Перед этим шагом было несколько попыток распиливания монолита существующих решений на рынке по новым практикам разработки, но затея оказалась тщетной, ибо те монолиты, которые и по сей день существуют и участвуют в так называемом "продакшен-пиратстве", имеют сильную связанность компонентов и решения поставленных задач, сопоставимые с началом 2000х годов, когда сфера только начинала развиваться. А самое главное, что монолит не заточен на построение распределенной архитектуры и, как следствие, обладает низкой эффективностью.

Было принято решение взять часть бизнес-логики (основной составляющей обработки действий игрока) из допотопных проектов эмуляторов и создать современный/масштабируемый эмулятор игрового сервера Lineage 2 Prelude Of War.
Исследование
Что на рынке
Возьмем, к примеру, EVE Online — проект который смог. Архитектура серверной части позволяет при относительно средних вычислительных мощностях, обеспечивать:
- низкую задержку игрок-сервер;
- стабильный онлайн до 20тыс. игроков.
Что там внутри:
- Stackless Python & Infiniband;
- публичные узлы подключения игроков (Proxy);
- внутренние узлы-контроллеры солнечных систем (SOL);
- контроллеры твердотельных накопителей для операций ввода/вывода (Blade);
- SQL Server Cluster.
А общая концепция архитектуры проекта заключается в stateless контроллерах игрового мира и хранением всего состояния игрового мира в базе данных с высокой доступностью за счет дисков.
Чтож, отлично, некий план стека технологий вырисовывался, но, нет… Не все так просто. Поддержка физических машин для такой архитектуры — слишком дорогое удовольствие, и на рынке Lineage 2 оно никому не нужно.
Главное, что можно выделить из архитектуры EVE Online:
- распределенное состояние игровых объектов;
- распределенный контроль игровых регионов (солнечных систем).
Продолжим.
Дальнейшим примером выступает официальный сервер PTS Lineage 2, написанный на C++.
Что внутри:
- сервисная архитектура;
- сервис взаимодействия с базой данных;
- сервис аутентификации;
- 2 сервиса-контроллера игровой логики игроков и NPC;
- SQL Server.
Минусы:
- не поддерживает масштабируемость сервисов;
- ограничение игроков в 5 тыс. на одной инсталляции;
- full stateful.
Можно сразу отсечь этот вариант, но в нем можно проследить некую логику разработчиков с попыткой заложить на будущее поддержку масштабирования, при котором выделяются четкие уровни ответственности каждого сервиса. Увы, по сей день нет никаких новостей по этому поводу от компании NCSoft, которой принадлежат права на разработку игры, а на минуточку, игра разрабатывается с 2002 года.
Из этого решения можно выделить также некоторые важные моменты на перспективу:
- сервисная архитектура;
- разделение ответственности.
Spring cloud стек
Казалось бы, при чем тут "кровавый" Энтерпрайз к многопользовательской игровой архитектуре, спросит читатель. Все достаточно просто — нас абсолютно не интересуют веб-решения, построенные с помощью этой технологии, важная составляющая — микросервисная архитектура и подходы, которые используются в эталонных приложениях.

Стандартная архитектура на этом стеке представляет собой набор инфраструктурных сервисов, взаимодействующих между собой с помощью REST API или Event Queue (брокеры).
Главными компонентами выступают:
- discovery-service — сервис-регистратор, обнаружения и хранения мета-информации каждого инфраструктурного микросервиса;
- config-server — сервис централизованной конфигурации инфраструктурных микросервисов;
- api-gateway — маршрутизация запросов от клиента во внутреннюю кухню по метаинформации из discovery-service.
Красиво, удобно, новомодно, а главное — заставляет описывать каждый микросервис, как stateless приложение.
И из этого решения можно выделить важные архитектурные преимущества:
- api-шлюз для взаимодействия между микросервисами и клиентами;
- discovery-service, как неотъемлемая часть архитектуры.
Базовое представление архитектуры
Ознакомившись с решениями на данном этапе исследования, можно уже выделить представление.
Какой стек будет использоваться:
- spring boot — удобный микрофреймворк построения приложения с инъекцией зависимостей/из коробки поддержкой конфигурации приложения;
- project reactor — проект, посвященных реактивным потокам данных;
- reactor netty — реактивная обертка над сетевым фреймворком netty;
- r2dbc — реактивная реализация драйвера взаимодействия с базой данных.
Почерпнуть полезной информации по netty можно тут.
Служебные подсистемы:
- PostgreSQL (базовое состояние);
- KeyDB (промежуточное состояние системных компонентов).
Перед составом сервисов небольшая вводная в игровой клиент Lineage2.
Сетевая логика клиента
Чтобы пролить больше света на архитектуру решения, нужно сначала понять как работает игровой клиент с сервером и региональной составляющей мира.
Клиент работает сразу с двумя серверами:
- сервер авторизационных данных игрока — через него происходит первый этап подключения и проверка логина: пароля игрока, а также дальнейший вход в лобби;
- сервер игровой бизнес логики — второй этап подключения клиента, после пройденных проверок на сервере авторизации (предигровое лобби выбора персонажей, вход в игровой мир)
Протокол, по которому клиент взаимодействует с серверами — TCP.
Каждый пакет состоит из размера пакета (2 байта), типа пакета (1 байт) и блока параметров(переменная длина). В дополнение к этому, в пакетах сервера авторизации, в конце добавляется контрольная сумма и дополняется нулями так, чтобы размер пакета был кратен 8-ми байтам. Контрольная сумма может быть рассчитана следующей функцией:
public int checksum(ByteBuf buf) {
int checksum = 0;
while (buf.isReadable(8)) {
checksum ^= buf.readInt();
}
return checksum;
}Протокол lineage использует 6 разных типов данных:
- char – может принимать значение от -128 до 127. Имеет длину 1 байт
- short – может принимать значение от -32768 до 32767. Имеет длину 2 байта
- int – может принимать значение от -2147483648 до 2147483647. Имеет длину 4 байта
- int64 (long) – может принимать значение от -9223372036854775808 до 9223372036854775807. Имеет длину 8 байт.
- float – может принимать значение от 2.22507e-308 до 1.79769e+308. Имеет длину 8 байт
- string – текстовая строка в юникоде(UTF8). Каждая буква представлена двумя байтами, первый байтом код буквы, а второй – номер кодовой таблицы. Индикатором конца строки служит символ с кодом 0.
Пакеты сервера авторизации шифруются по алгоритму Blowfish. Пакет Init содержит динамический Blowfish ключ случайно генерируемый для каждого клиента. Этот пакет сначала шифруется по алгоритму XOR (ключ генерируется случайным образом и помещается в конце пакета), а потом шифруется по алгоритму Blowfish, статическим ключом. По умолчанию статический ключ — 6B 60 CB 5B 82 CE 90 B1 CC 2B 6C 55 6C 6C 6C 6C. Все последующие пакеты будут шифроваться динамическим Blowfish ключом. Пакет LoginRequest дополнительно шифруется по алгоритму RSA. Ключ состоит из следующих частей: B = 1024, E = 65537, N = передается в пакете Init. Вместе эти 3 части составляют целый RSA ключ.
Байты N в пакете зашифрованы функцией:
public byte[] scrambledRSA(KeyPair keyPair) {
byte[] scrambledModulus = ((RSAPublicKey) keyPair.getPublic()).getModulus().toByteArray();
if (scrambledModulus.length == 0x81 && scrambledModulus[0] == 0) {
scrambledModulus = Arrays.copyOfRange(scrambledModulus, 1, 0x81);
}
// step 1 : 0x4d-0x50 <-> 0x00-0x04
for (int i = 0; i < 4; i++) {
byte temp = scrambledModulus[i];
scrambledModulus[i] = scrambledModulus[0x4d + i];
scrambledModulus[0x4d + i] = temp;
}
// step 2 : xor first 0x40 bytes with last 0x40 bytes
for (int i = 0; i < 0x40; i++) {
scrambledModulus[i] = (byte) (scrambledModulus[i] ^ scrambledModulus[0x40 + i]);
}
// step 3 : xor bytes 0x0d-0x10 with bytes 0x34-0x38
for (int i = 0; i < 4; i++) {
scrambledModulus[0x0d + i] = (byte) (scrambledModulus[0x0d + i] ^ scrambledModulus[0x34 + i]);
}
// step 4 : xor last 0x40 bytes with first 0x40 bytes
for (int i = 0; i < 0x40; i++) {
scrambledModulus[0x40 + i] = (byte) (scrambledModulus[0x40 + i] ^ scrambledModulus[i]);
}
return scrambledModulus;
}Для расшифровки можно воспользоваться следующей функцией:
private byte[] decryptXorModulus(byte[] xor) {
// step 1 xor last 0x40 bytes with first 0x40 bytes
for (int i = 0; i < 0x40; i++) {
xor[0x40 + i] = (byte) (xor[0x40 + i] ^ xor[i]);
}
// step 2 xor bytes 0x0d-0x10 with bytes 0x34-0x38
for (int i = 0; i < 4; i++) {
xor[0x0d + i] = (byte) (xor[0x0d + i] ^ xor[0x34 + i]);
}
// step 3 xor first 0x40 bytes with last 0x40 bytes
for (int i = 0; i < 0x40; i++) {
xor[i] = (byte) (xor[i] ^ xor[0x40 + i]);
}
// step 4 : 0x00-0x04 <-> 0x4d-0x50
for (int i = 0; i < 4; i++) {
final byte temp = xor[i];
xor[i] = xor[0x4d + i];
xor[0x4d + i] = temp;
}
if (xor.length == 0x81 && xor[0] == 0) {
xor = Arrays.copyOfRange(xor, 1, 0x81);
}
return xor;
}
public PublicKey parseScrambledModulus(byte[] scrambledModulus) {
scrambledModulus = decryptXorModulus(scrambledModulus);
final KeyFactory keyFactory = KeyFactory.getInstance("RSA");
final BigInteger modulus = new BigInteger(1, scrambledModulus);
final RSAPublicKeySpec rsaPublicKeySpec = new RSAPublicKeySpec(modulus, RSAKeyGenParameterSpec.F4);
try {
return keyFactory.generatePublic(rsaPublicKeySpec);
} catch (InvalidKeySpecException e) {
throw new RuntimeException(e);
}
}Функции шифрования и дешифрации игрового трафика:
public void decryptData(ByteBuf byteBuf) {
int read = 0;
while (byteBuf.isReadable()) {
final int sub = byteBuf.readByte() & 0xFF;
byteBuf.setByte(byteBuf.readerIndex() - 1, sub ^ inKey[(byteBuf.readerIndex() - 1) & 15] ^ read);
read = sub;
}
shiftKey(inKey, byteBuf.writerIndex());
}
public void encryptData(ByteBuf byteBuf) {
if (!cryptEnable) {
cryptEnable = true;
return;
}
byteBuf.resetReaderIndex();
int read = 0;
while (byteBuf.isReadable()) {
final int sub = byteBuf.readByte() & 0xFF;
read = sub ^ outKey[(byteBuf.readerIndex() - 1) & 15] ^ read;
byteBuf.setByte(byteBuf.readerIndex() - 1, read);
}
shiftKey(outKey, byteBuf.writerIndex());
byteBuf.resetReaderIndex();
}
public void shiftKey(byte[] key, int size) {
int old = key[8] & 0xff;
old |= (key[9] << 8) & 0xff00;
old |= (key[10] << 0x10) & 0xff0000;
old |= (key[11] << 0x18) & 0xff000000;
old += size;
key[8] = (byte) (old & 0xff);
key[9] = (byte) ((old >> 0x08) & 0xff);
key[10] = (byte) ((old >> 0x10) & 0xff);
key[11] = (byte) ((old >> 0x18) & 0xff);
}**С каждым кодированным/декодированным пакетом ключ изменяется на длину пакета, поэтому нужно использовать два отдельных экземпляра ключа – один для шифрования исходящих пакетов, второй для расшифровки входящих. Все пакеты шифруются начиная с 3-го байта, т.е. размер пакета никогда не шифруется.
Из выше перечисленного выделяются три уровня ответственности решения:
- сервер работы в базой данных;
- сервер авторизации игроков;
- сервер бизнес-логики игроков (окрестратор).
Игровой мир/карта/система регионов
Если покопаться внутри клиента, то можно обнаружить файлы карты игрового мира с кодами регионов {x}_{y}.unr (расширение unreal level map) и как следствие должна быть региональная сетка игрового мира. В версии клиента, который я использую, мир состоит из 28 регионов в ширину (x) и 26 регионов в высоту (y). Каждый регион имеет блоки размером 256х256 координат. Каждый блок разделен на 8х8 ячеек.
Общая высота мира (y) — 851968 координат.
Общая ширина мира (х) — 917504 координат.
Из полученных данных нехитрым математическими преобразованиями можем нарисовать региональную сетку на карте игрового клиента.

int REGION_WH = 222; // предрасчитаная ширина региона для изображения (легитимно только для моего варианта собранной карты из клиента)
private void renderGrid(BufferedImage img, Graphics2D g, FontMetrics fontMetrics) {
// draw grid
for (int x = 19, y; x-- > 0; ) {
for (y = 17; y-- > 0; ) {
final String name = (x + 10) + "_" + (y + 10);
final int strx = ((x * REGION_WH) + (REGION_WH / 2)) - (fontMetrics.stringWidth(name) / 2);
final int stry = (y * REGION_WH) + (REGION_WH / 2) + (fontMetrics.getHeight() / 2);
g.drawString(name, strx, stry);
g.drawLine(0, (y * REGION_WH) + REGION_WH, img.getWidth(), (y * REGION_WH) + REGION_WH);
g.drawLine((x * REGION_WH) + REGION_WH, 0, (x * REGION_WH) + REGION_WH, img.getHeight());
}
}
}Центральные регионы игрового мира X=19 Y=18, с которых начинается отсчет координат, а также стоит учитывать что ось Y инвертированная по отношению к изображению, поэтому координаты отрицательными значениями идут выше отметки (0, 0), а положительные — соответственно ниже.
Существует также внутренняя кухня для регионов, где рассчитываются ячейки.
Итак, из грид сетки можно увидеть, что мир построен из каждого отдельного куска карты. Отсюда рождается идея контроллеров части регионов карты (региональных ячеек) по оси Х и, собственно, находящихся в них объектов. Т.е. фактически это будет кластер, с центральным оркестратором распределения игровых объектов по его же шардам.
То самое
Из чего должно состоять решение:
- discovery-gateway-service — сервис, который содержит информацию обо всех инфраструктурных сервисах приложения. Каждый микросервис регистрируется на сервере discovery, и discovery знает все инфраструктурные сервисы, работающие на каждом порту и IP-адресе, и, выполняет функции балансировки/маршрутизации пакетов между ними;
- data-service — сервис, который отвечает за работу с базой PG и предоставляет свое АПИ инфраструктурным сервисам. Идея сервиса такова, что каждый другой сервис не должен взаимодействовать с базой напрямую, т.е. разделение ответственности, но может обратиться или записать некоторые свои данные используя Net обертку;
- auth-service — сервис, обеспечивающий механизм входной точки доступа игрового клиента (центрального шлюза) аутентификации игровых аккаунтов и распределения игроков по выбранным серверам в списке серверов (зоны);
- game-gateway-orcehstrator — сервис, обеспечивающий механизм входной точки доступа игрового клиента (центрального шлюза) авторизированных игровых аккаунтов после Auth Service и распределения игроков по Game Shard. Дополнительно хранит механизм кодеков/декодеров шифрования клиента с привязкой сессионных ключей каждого живого аккаунта, т.е. основная функция прием шифрованных запросов от игрового клиента, дешифровка и ретрансляция запросов на дочернюю игровую ноду привязанную к игроку по региональной сетке (Game Shard);
- game-shard — сервис, обеспечивающий основную бизнес логику обработки входящих пакетов от Game Orchestrator, взаимодействие с остальными инфраструктурными сервисами, обработкой действий игрока и отправки результата по сессионным идентификаторам обратно в Game Orchestrator;
- npc-shard — аналогично Game Shard, только в случаи для NPC (Non Player Character).
Любой сервис может масштабироваться.
Протокол общения сервисов — TCP.
Стоит добавить, что общение сервисов между собой не блокирующее, т.е. сервис на определенное действие не ждет ответа. Можно разделить такую логику на два обработчика — producer и consumer данных. В момент получения результата с течением времени, механика продолжит выполнение того или иного действия.
Пример:
- Shard запрашивает данные игрока у data-service, отправляя пакет с информацией ReqCharInfo (produce). При этом работа потока не блокируется для ожидания результата.
- Data-service принимает пакет ReqCharInfo (consume), выполняет некоторую логику забора данных из базы данных или кешей, отправляет обработанную информацию обратно в Shard пакетом RespCharInfo (produce).
- Shard принимает некоторым обработчиком данные игрока (consume) и выполняет следующий кусок логики манипуляции с данными.
Распределённое состояние
Фактически, что нам известно из многопользовательской игры — существует два состояния игрового объекта:
- базовое
- промежуточное
Базовое состояние — первичные данные, такие как уровень/наименование/тип/идентификатор etc., из которых составляется базовое представление объекта при инициализации в игровом мире.
Промежуточное состояние — динамические данных объекта, изменяемые посредством игровых механик, взаимодействия игрок-объект/объект-объект, в реальном времени.
С базовым состоянием все достаточно просто — его можно хранить в любой реляционной базе данных, а с промежуточным уже начинаются проблемы на стадии планирования.
Промежуточное состояние должно хранится в памяти приложения для быстрых расчетов и доступа, но в распределенной архитектуре это состояние должно хранится в централизованном хранилище, достаточно быстрым для темпа выбранной игры. Т.е. на каждого игрока в среднем рейт нормальной игры (атака, передвижение, манипуляции с предметами, системные задачи обработки) начинается с отметки в 100 rps. И по логике, распределение игроков в мире осуществляется так:
- 15% торговля
- 85% внутриигровая активность (осады, события, пвп контент и пр.)
Возьмем к примеру средне статистический онлайн с официального сервера в воскресенье
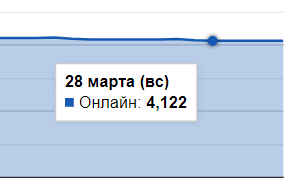
4122 игрока подключены к серверу. Рассчитаем нагрузку 4122 х 0.85 х (50 — 150 rps) = от 175 krps до 525 krps read/write. Не хило.
Какую систему использовать для хранения?
Требования:
- отказоустойчивость
- масштабирование
- хранение и обработка большого количества данных игровых объектов
- низкий latency и потребление ресурсов
Было перепробовано множество подсистем хранения промежуточного состояния, укажу наиболее перспективные из них:
- Redis/KeyDB
- Hazelcast
- Apache Cassandra (как отдельно так и в режиме embed шарда)
- Apache Ignite (как отдельно так и в режиме embed шарда)
Они все прекрасно работают с небольшими пакетами данных, и заявленные графики производительности на сайтах этих систем исключительная правда для небольших моделей.
А модели игровых объектов промежуточного состояния достаточно жирные — в среднем 100 — 200 полей различных типов данных.
У всех наблюдаются одни и те же проблемы, точнее это даже не проблемы самих систем, а проблемы построения функционала получения/записи данных:
- блокирующие вызовы операций чтения/записи;
- сериализация/десериализация данных.
И, как следствие — потребление большого количества ресурсов.
P.s. исследование продолжалось в течении почти года.
Уже на данном этапе понятно, что из проекта ничего не выйдет. Погодите ка, что это? Off-Heap память? Серьезно?
В связи с неудовлетворительными показателями испробованных систем, было принято решение взять за основу off-heap таблицы хранения данных с прямым доступом в память процесса. Но это дает дополнительную реализацию функционала репликации. За основу off-heap системы хранения структуры <K,V> был взят алгоритм LSM-дерева поскольку обеспечивает быструю доступность данных по индексам при большой частоте записи и использует механизм слияния одного слоя памяти в другой (heap -> off-heap) с кастомной сериализацией объектов, основанной на ручной записи в буфер данных (Externalizable). Так же стоит дополнить, что в некоторых кейсах десериализации, объекты в их полном представлении не нужны, а нужна лишь часть данных. Поэтому была написана обертка, которая умеет работать с конфигурируемым View уровнем с перечислением необходимых полей. По факту это прямое чтение данных по смещению в байтовом массиве.
Главное преимущество еще одного костыля кастомной системы — прямой неблокирующий доступ/запись данных в памяти 1 сервиса. А как же stateless — по факту да, пришлось пренебречь этой концепцией и хранить промежуточное состояние в памяти одного сервиса и реплицировать данные внутри кластера. Единственно что оставили — распределенные счетчики и задачи, которые хранятся в KeyDB и обрабатываются фреймворком redisson.
Xeon E5-2689 8 x 2.6, DDR 3 ECC 1866
Смешанный режим, 10 миллионов объектов, длина ключа 8 байт, длина значения 3567 байт
sync mode
avg write: 3128 ns
avg read: 2741 ns
write all: 25617 ms — 400k rps
read all: 21430 ms — 476k rps
async mode
avg write: 2689 ns
avg read: 2145 ns
write all: 16573 ms — 603k rps
read all: 11620 ms — 860k rps
CPU factor: 30% wo socket io
При желании можно разогнать показатели еще больше.
Представление кластера (оркестратор — шард)
Как описывалось выше, оркестратор, фактически master уровень кластера, распределяет регионы для шарда (slave). Мы знаем, что игровой мир можно разделить на n-частей по оси X и эти самые части игрового мира отдаются под контроль шарда.
Как это выглядит визуально.

А что там по отказоустойчивости?
- Оркестратор может быть масштабируемым с хранением состояния кластера в KeyDB.
- По отключению шарда от кластера и его восстановлению, осуществляется балансировка регионов, как по живым шардам, так и по вновь подключенным.
Алгоритм балансировки кластера основан на Consistent Hashing, но со своими нюансами:
- балансировка затрагивает абсолютно все состояние кластера, а не его отдельный элемент
- балансировка осуществляться влево, вправо и в две стороны по горизонтальному представлению кластера
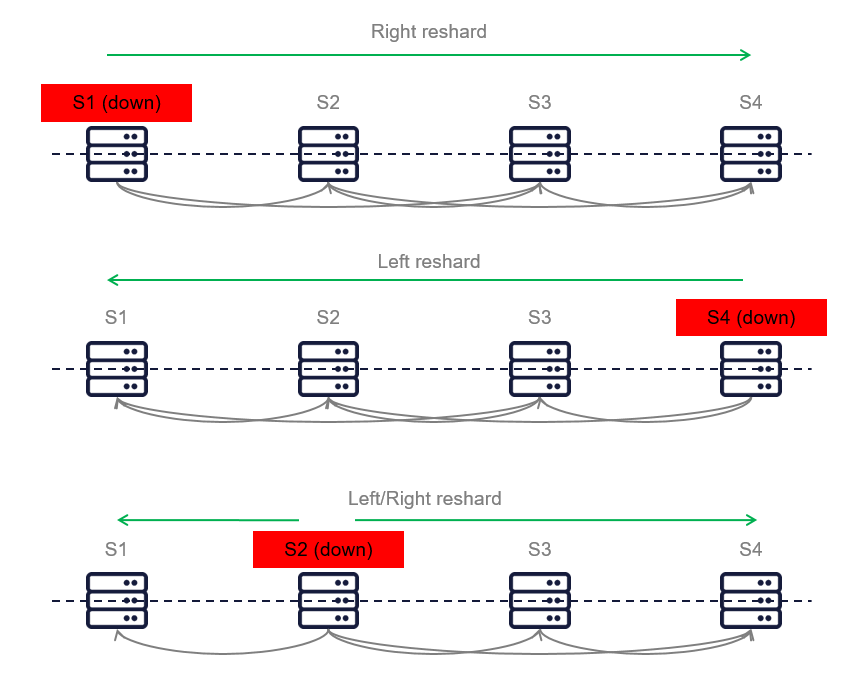
Конечная архитектура
Базовое представление
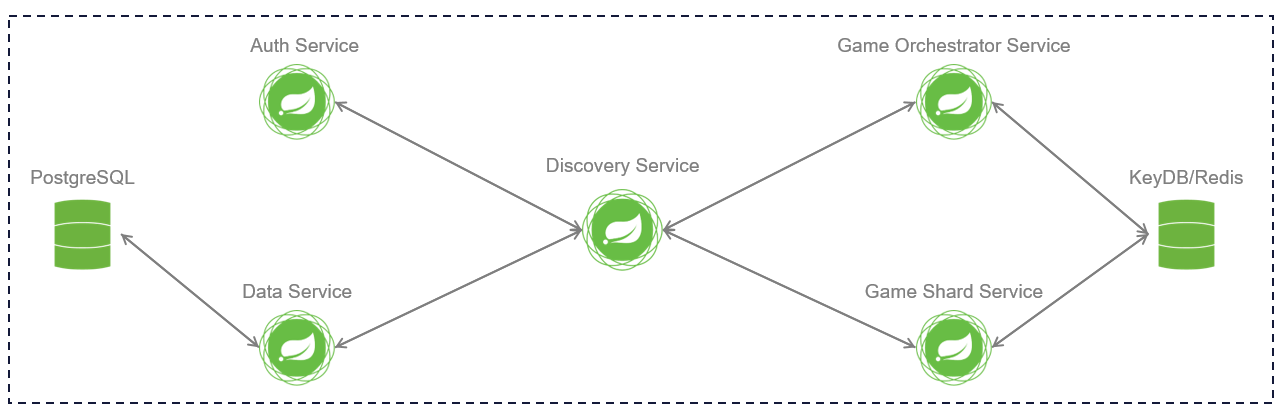
Показана схема взаимодействия инфраструктурных сервисов внутри кластера.
Дополнительно был реализован функционал discovery zones — где шлюзом между ними выступает auth-service (2 зоны — 2 разных сервера) и игровой клиент дает возможность выбирать на этапе авторизации, на какой сервер игрок хочет зайти.
Представление зон обнаружения

Представление взаимодействия игрового клиента с инфраструктурой
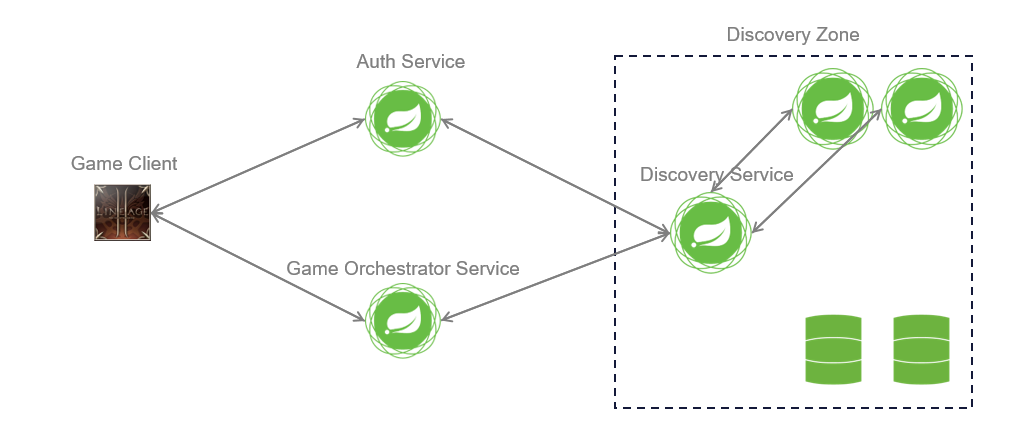
Представление репликации данных
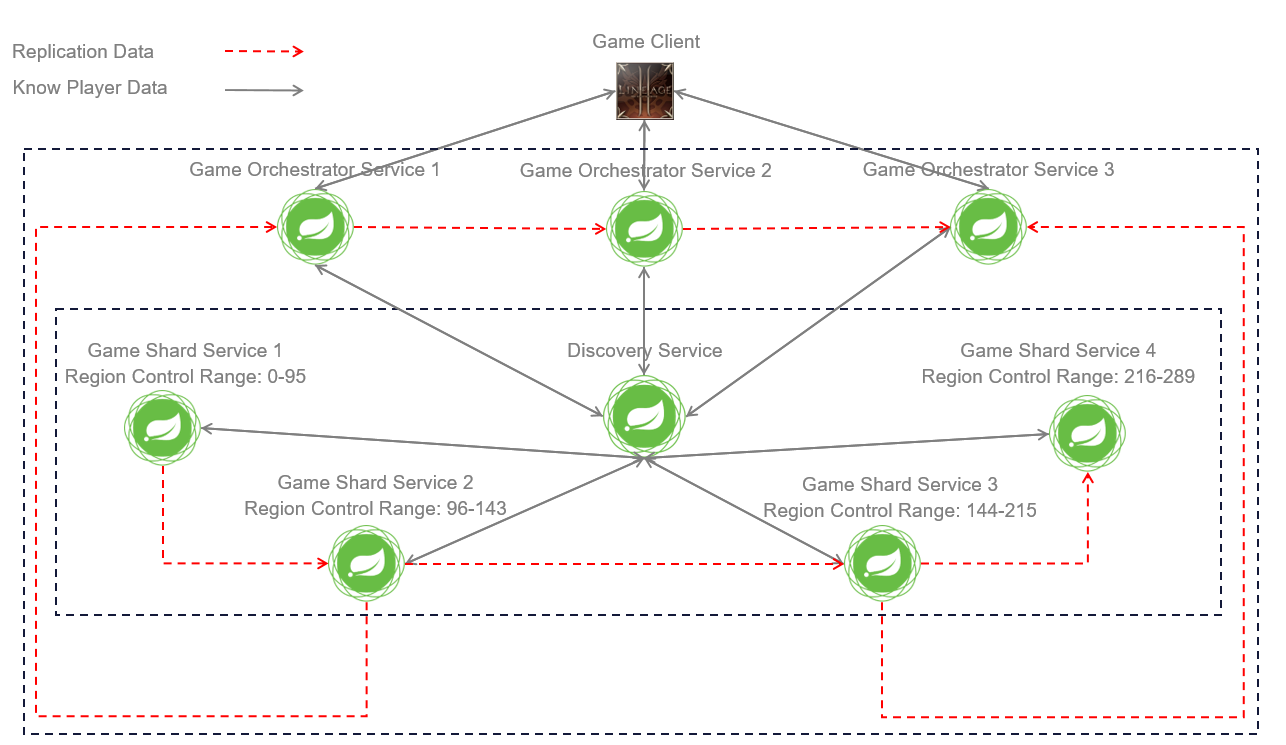
Может показаться, что в этой схеме, узким местом является Discovery Service. Нет, он также масштабируемый с инициализацией подключений от других сервисов. Единственная проблема — нужно перезапускать всю инфраструктуру для расширения инстансов сервиса.
Заключение
Абсолютно любую MMO игру можно адаптировать под архитектуру, описанную в статье, поскольку у любой игры есть региональное распределение.
В рамках анализа было представлено обобщение архитектур, используемых в играх MMO, и рассмотрены методы для распределения игрового мира на несколько сервисов/машин.
Основными аспектами решения являются:
- масштабируемость любого сервиса;
- балансировка нагрузки алгоритмом RR, который обеспечивает discovery-gateway-service при общении сервис-сервис;
- для orchestrator действуют правила RR распределения соединений как и для всех остальных сервисов;
- availability & partition tolerance;
- consistency — скорее нет, чем да, поскольку нужно дополнительно еще продумать распределенные блокировки;
- разделение ответственности компонентов системы;
- региональное распределение/контроль игрового мира, как распределение нагрузки игрового мира на решение.
Результаты получились отличными, на примере живого игрока (клиента) — нет никаких визуальных аффектов трансфера из одного шарда в другой при пересечении границы подконтрольных регионов. Шарду достаточно отправить пакет с идентификатором игрока для инициализации процедуры переключения управляющего контекста на другой шард. А обеспечивается эта функциональность репликацией дельты промежуточного состояния игрока в память других шардов кластера.
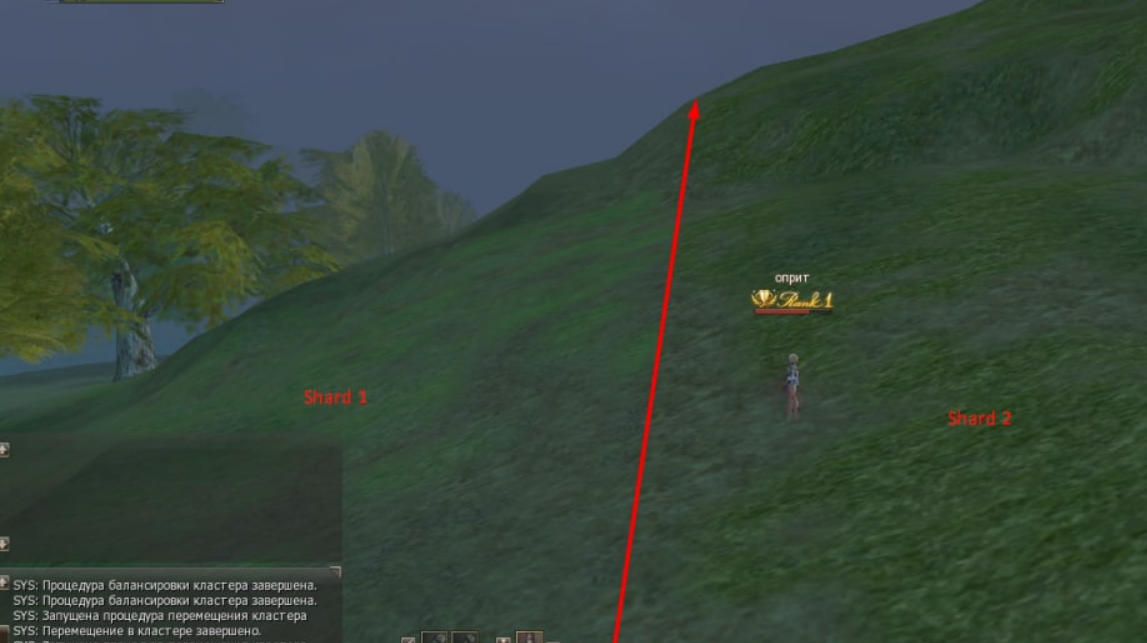
Надеюсь кому-нибудь это будет полезно.
Комментариев нет:
Отправить комментарий