Тропические леса и фикусы-душители
В тропических лесах, где всегда тепло, влажно и много зелени живет одно интересное растение. С необычным названием — фикус-душитель. Почему он получил такое имя? Как из фильма ужасов.
Дело в том, что в таких комфортных тропических условиях у растений возникает жесткая конкуренция. Солнечный свет закрыт кронами мощных, вековых деревьев. Их крепкие корни выкачивают все полезные ресурсы из почвы — воду, минералы. В таких условиях пробиться новому ростку крайне сложно. Но фикусы-душители нашли выход. Их семена изначально попадают на кроны деревьев, где много света. Там пускают свои побеги. Поначалу они растут медленно. Но по мере роста их корни спускаются вниз до самой земли, обвивают ствол дерева-носителя. И как только они добираются до земли — скорость роста удваивается. Все! Дни дерева-носителя сочтены. Теперь ствол не может расти в ширь, так как он обвит фикусом и тот его сдавливает в своих горячих обьятиях.

Крона дерева не может получать достаточно света, потому что фикус забирает его себе. Его листья выше. Корни фикуса высасывают из почвы воду и питательные вещества, так что дереву носителю достается все меньше. В какой-то момент дерево-носитель погибает, но фикусу оно уже не нужно. Его стебли образуют прочную основу, которая повторяет силуэт своей жертвы. Обычно старое дерево полностью сгнивает в таком заключении и от него не остается и следа.Однако внешний образ по прежнему остается — его в точности повторяет сам фикус:

Рефакторинг сервиса приложения доставки продуктов
Часто бывает необходимо разбить таблицу на две, либо вынести часть методов сервиса в отдельный сервис. Хорошо, если вы можете остановить ваше приложение. Пользователи в это время ничего не делают — ждут обновления. Вы разделяете скриптами данные по таблицам и опять запускаете приложение — теперь пользователи могут снова работать. Но иногда такой сценарий невозможен.
Допустим у нас есть приложение, которое позволяет заказывать продукты из магазинов. Оплатить их. В том числе и бонусами. Очевидно, сами бонусы начисляются какой-то не тривиальной логикой: число покупок, возраст, лояльность и прочее.
Допустим имеются следующие действия, которые у нас хранятся в одной таблице:
-
Открыть заказ. В таком случае оформляется сам факт посещения заказа и общая сумма. Пока он открыт в него можно добавлять товары. Затем заказ собирают, отправляют в доставку и в итоге заказ переходит в закрытый статус.
-
Можно оформить возврат товара. Если вам не понравился кефир - вы оформляете возврат и вам возвращают его цену.
-
Можно списать бонусы со счета. В таком случае часть стоимости оплачивается этими бонусами.
-
Начисляются бонусы. Каким-либо алгоритмом — нам не важно каким конкретно.
-
Также заказ может быть зарегистрирован в некотором приложении-партнере (ExternalOrder)
Все перечисленная информация по заказам и пользователям хранится в таблице (пусть она будет называться OrderHistory):
|
id |
operation_type |
status |
datetime |
user_id |
order_id |
loyality_id |
money |
|---|---|---|---|---|---|---|---|
|
234 |
Order |
Open |
2021-06-02 12:34 |
33231 |
24568 |
null |
1024.00 |
|
233 |
Order |
Open |
2021-06-02 11:22 |
124008 |
236231 |
null |
560.00 |
|
232 |
Refund |
null |
2021-05-30 07:55 |
3456245 |
null |
null |
-2231.20 |
|
231 |
Order |
Closed |
2021-05-30 14:24 |
636327 |
33231 |
null |
4230.10 |
|
230 |
BonusAccrual |
null |
2021-05-30 09:37 |
568458 |
null |
33231 |
500.00 |
|
229 |
Order |
Closed |
2021-06-01 11:45 |
568458 |
242334 |
null |
544.00 |
|
228 |
BonusWriteOff |
null |
2021-05-30 22:15 |
6678678 |
8798237 |
null |
35.00 |
|
227 |
Order |
Closed |
2021-05-30 16:22 |
6678678 |
8798237 |
null |
640.40 |
|
226 |
Order |
Closed |
2021-06-01 17:41 |
456781 |
2323423 |
null |
5640.00 |
|
225 |
ExternalOrder |
Closed |
2021-06-01 23:13 |
368358 |
98788 |
null |
226.00 |
Логика такой организации данных вполне справедлива на раннем этапе разработки системы. Ведь наверняка пользователь может посмотреть историю своих действий. Где он одним списком видит что он заказывал, как начислялись и списывались бонусы. В таком случае мы просто выводим записи, относящиеся к нему за указанный диапазон. Организовать в виде одной таблицы — банальная экономия на создании дополнительных таблиц, их поддержании. Однако, по мере роста бизнес-логики и добавления новых типов операций число столбцов с null значениями начало расти. Записей в таблице — сотни миллионов. Причем распределены они очень неравномерно. В основном это операции открытия и закрытия заказов. Но вот операции начисления бонусов составляют 0.1% от общего числа, однако эти записи используются при расчете новых бонусов, что происходит регулярно. В итоге логика расчета бонусов работает медленнее, чем если бы эти записи хранились в отдельной таблице. Ну и расширять таблицу новыми столбцами не хотелось бы в дальнейшем. Кроме того заказы в закрытом статусе с датой создания более 2 месяцев для бизнес-логики интереса не представляют. Они нужны только для отчетов — не более.
И вот возникает идея. Разделить таблицу на две, три или даже больше.
Проблема в том, что эта таблица — одна из наиболее активно используемых в системе (как раз по причине совмещения в себе данных для разных частей логики). И простой при ее рефакторинге крайне нежелателен.
Изменение структуры хранения в три этапа
Предположим, что наше legacy монолитное приложение хоть и плохое, но не совсем. Как минимум зарезервировано. То есть работает как минимум два экземпляра. Так, что при падении одного из них - второй продолжит обслуживать пользователей:
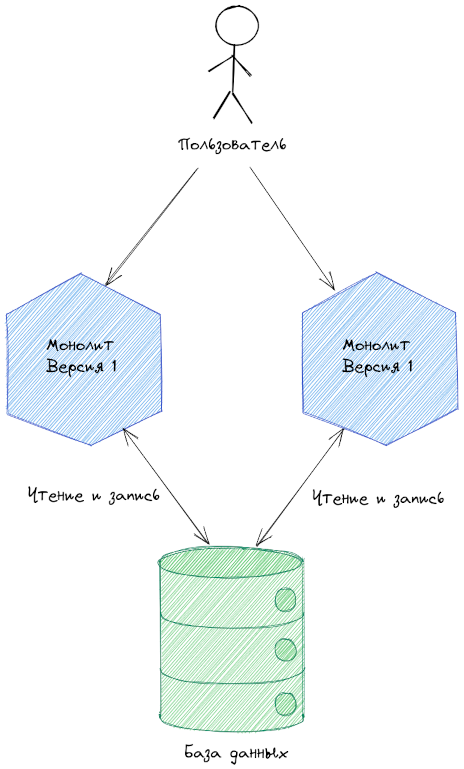
Между пользователем и монолитом есть прокси, которая в целях упрощения схемы можно не отображать. Просто учтем, что запрос может случайным образом выполнятся на любом экземпляре.
Оба экземпляра работают с одной базой данных. Реализуя паттерн Shared Database.
Первый шаг к рефакторингу — выпуск новой версии монолита. Которая по-прежнему работает со старой таблицей, как и предыдущая версия. Но и пишет данные в новую таблицу или таблицы. На схеме для наглядности показана отдельная база данных.
Отдельная новая база данных вполне может появиться. Однако не всегда. Ввиду сложностей обеспечения транзакционности между двумя БД. Все в конечном счете зависит от реализации и от ограничений бизнес-логики.
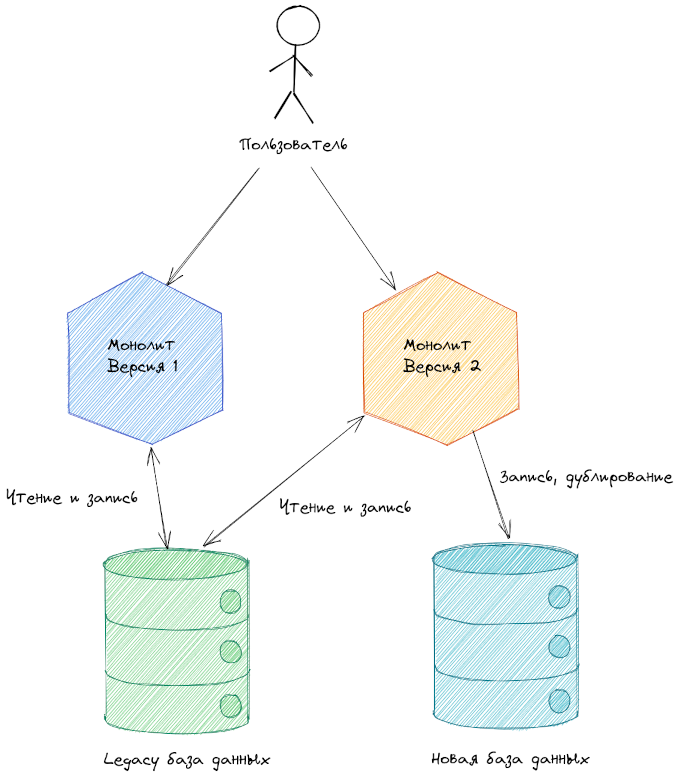
Применительно к нашему примеру мы могли бы получить следующую структуру для новых таблиц.
BonusOperations:
|
id |
operation_type |
datetime |
user_id |
order_id |
loyality_id |
money |
|---|---|---|---|---|---|---|
|
230 |
BonusAccrual |
2021-05-30 09:37 |
568458 |
null |
33231 |
500.00 |
|
228 |
BonusWriteOff |
2021-05-30 22:15 |
6678678 |
8798237 |
null |
35.00 |
Отдельную таблицу для данных из внешних систем - ExternalOrders:
|
id |
status |
datetime |
user_id |
order_id |
money |
|---|---|---|---|---|---|
|
225 |
Closed |
2021-06-01 23:13 |
368358 |
98788 |
226.00 |
Для операций с заказами моложе, чем 2 недели (предположим, что ограничение бизнес-логики было как раз определено на это уровне. Ведь если заказ был произведен более двух недель назад его нельзя отменить, изменить и прочее) новая таблица OrderHistory с уменьшеным числом столбцов.
Для оставшихся типов записей - OrderHistoryArchive (старше 2х недель). Где теперь также можно удалить несколько лишних столбцов.
Выделение таких архивных данных часто бывает удобным. Если оперативная часть очень требовательна к производительности — она вполне может себе размещается на быстрых SSD дисках. В то время как архивные данные могут использоваться один раз в месяц для отчета. И их больше в разы. Поэтому размещая их на дешевых дисках — мы экономим иногда вполне приличную сумму.
По схеме выше мы видим, что версия начала дублировать всю информацию в новую структуру данных. Но пока использует в своей бизнес-логике данные из старой структуры. Запрос обработанный версией 2 записывается именно в том формате, в котором его ожидает версия 1. Запрос обработанный версией 1 сохранит данные, которые также используются в работе версии 2.
Монолит версии 1 и монолит версии 2 вполне могут работать совместно. Лишь для тех запросов, которые обрабатывались монолитом версии 1 в новой базе данных будут пробелы. Эти пробелы, а также недостающие данные можно будет в дальнейшем скопировать отдельным скриптом или утилитой.
Спустя какое-то время работы версии 2 мы получим заполненную новую базу данных. Если все хорошо, то мы готовы к следующей стадии — переводу основной бизнес-логики на новую базу данных.
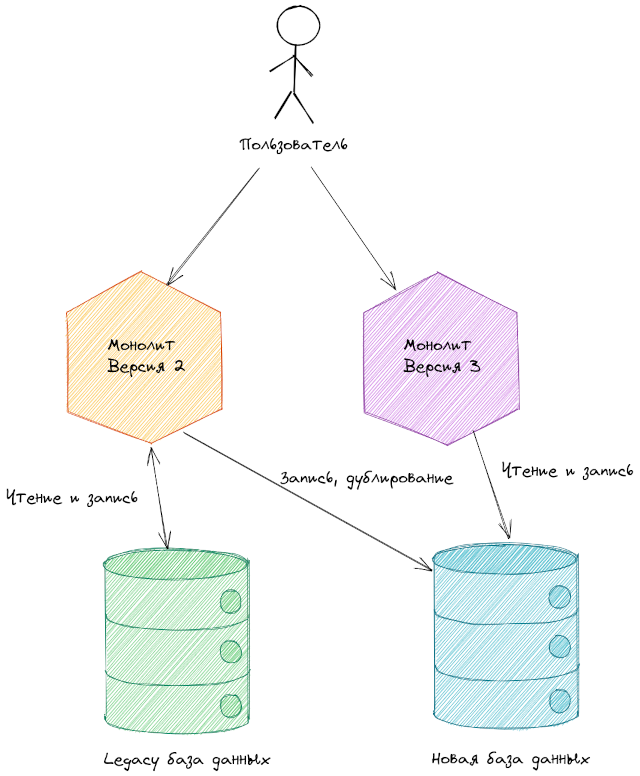
В случае успеха просто удаляем старые таблицы, так как все данные уже сохранены в новой структуре.

Итого. Внешне система никогда не менялась. Однако внутренняя организация радикально преобразилась. Возможно под капотом теперь работает новая система. Которая лишена недостатков предыдущей. Не напоминает фикусов-душителей? Что-то похожее есть. Поэтому именно такое название паттерн и получил — Strangler.
Очевидно, что аналогичным образом можно подходить к рефакторнгу не только структуру данных, но и кода. Например, разделять монолит на микросервисы.
Выводы
-
Паттерн Strangler позволяет совершенствовать системы с высокими требованиями к SLA.
-
Для обновления системы без простоя нужно сделать как минимум 3 последовательных развертования на продакшен. Это одна из причин, почему системы требовательные к показателям общего простоя заметно дороже.
-
Для быстрой разработки нового функционала и рефакторинга нужно уметь быстро производить развертывание системы в продакшен. Поэтому одним из первых шагов при рефакторинге таких легаси систем — уменьшение времени развертывания системы. Если мы вернемся к тому же фикусу-душителю — он остался бы обычным сорняком, если бы не рос гораздо быстрее дерева-носителя.
Все вышеперечисленное имеет смысл только в том случае, если действительно имеется необходимость. И если мы имеем возможность обновить систему ночь или в часы наименьшей нагрузки, конечно таким подарком судьбы нужно воспользоваться.
Комментариев нет:
Отправить комментарий