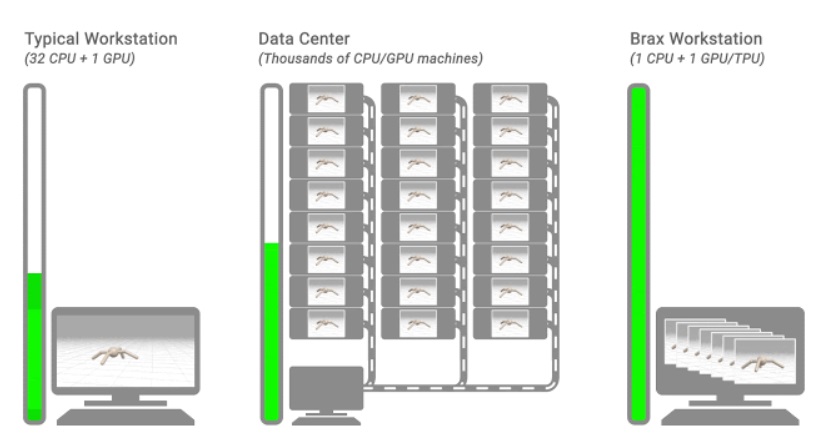
В обучении с подкреплением (Reinforcement Learning) одним из ограничивающих факторов является быстродействие физических симуляторов, на основе которых происходит обучение нейросети. Из-за специфики расчетов, лишь малую часть из них можно вынести в GPU, а большая часть вычислений в физических движках делается на CPU. Для примера, один GPU может обучать нейросеть десятками тысяч параллельных "потоков" в секунду. Но один CPU с запущенным на нем физическим симулятором, может выдавать лишь 60-200 кадров в секунду.
Для борьбы с этим ограничением, обычно запускается большой кластер из сотен или тысяч CPU с запущенными на них параллельными физическими симуляторами. А результаты их расчета передаются в единственную GPU, обучающую нейросеть.
Исследователи из Google AI разработали новый физический движок Brax, который эффективно работает на одном GPU и способен выдавать до 10 миллионов шагов симуляции в секунду, выполняя при этом до 10 тысяч запущенных параллельных симуляторов физики.
Это позволяет эффективно обучать нейросети на одном или нескольких локальных GPU, что раньше требовало внешнего сетевого кластера из десятков тысяч CPU.
Обучение с подкреплением пытается имитировать жизнь и самообучение биологических организмов. Для этого необходим какой-то реалистичный физический симулятор, в котором этот организм будет "жить". Если он (организм) делает что-то правильно, то получает награду и закрепляет полученные навыки. А если неправильно, то "погибает".

К сожалению, написать симулятор, реалистично имитирующий физическую реальность, очень непростая задача. Хотя для этого достаточно простых законов Ньютона, но из-за того что вычисления делаются дискретно и последовательно, возникает ряд проблем. Например, после очередного шага симуляции - интегрирования всех действующих на объект сил, включая гравитацию, инерцию и т.д., объект после обновления его координат может оказаться полностью или частично внутри другого объекта. Ниже уровня пола или внутри стены.
")
Необходимо как-то сдвинуть его обратно, не нарушив результат действующих на объект сил. Которые математически, по строгим формулам, привели к тому, что он проник внутрь другого объекта, а значит простое искусственное перемещение объекта обратно уже искажает их результат и делает такую симуляцию не совсем достоверной. Либо надо как-то применять ряд эвристик для избегания такого случая.
Расчет контактов и силы трения между объектами в физических движках - это сплошные боль и разочарование, полные компромиссов. А ведь без расчета реалистичной силы трения, например между ногами и землей, не будет возможности достоверно симулировать перемещение (бег, ходьба, удары по мячу) организма в симуляторе.
Уменьшать шаг симуляции не представляется возможным, так как расчеты получаются слишком медленными. Существующие физические движки (MuJoCo, Bullet, Chrono, PhysX, Havok) выходят из этого положения, используя очень упрощенное представление 3д объектов в виде простых примитивов - кубов, сфер и эллипсоидов, и максимально увеличивая шаг расчетов. А также используя ряд эвристик для расчета столкновений между объектами. Для обучения с подкреплением такой упрощенный симулятор годится, потому что схематичное изображение фигурки человека вполне позволяет отрабатывать основные алгоритмы.
К сожалению, этого все еще недостаточно, и даже на современном CPU процессоре физические движки выдают от силы 60-200 FPS, в зависимости от точности симуляции (т.е. величины шага симуляции) и количества объектов в сцене. Специфика физических расчетов такова, что перенести на GPU можно лишь малую незначительную часть, а основные расчеты приходится делать последовательно на основном CPU.
Поэтому для обучения нейросетей в симуляторах часто запускают внешние сетевые кластеры из сотен, тысяч и даже десятков тысяч CPU процессоров, на каждом из которых запущена своя копия физического симулятора. Потом результаты этих расчетов передают на один или несколько GPU, которые собственно и обучают нейросетевого агента.
Уже давно предпринимаются попытки заменить программные симуляторы на нейросетевые. Чтобы нейросеть предсказывала физику. А так как она это может делать параллельными батчами (пакетами) размером в тысячи и десятки тысяч элементов, то это аналогично запуску тысяч параллельных симуляторов. Нейросетью уже пытались как напрямую предсказывать физику, т.е. координаты где окажется каждый объект в сцене, так и разрабатывали довольно сложные алгоритмы, где нейросеть работает с сжатым представление сцены, содержащим только наиболее важную информацию (координаты, направления) для решения задачи.
К сожалению, нейросетевые симуляторы все еще плохо работают. Их долго обучать под конкретное окружение и они неважно обрабатывают граничные случаи.
Поэтому классические физические 3d движки, делающие расчет на основе физических формул, все еще остаются основным и, что печально, тормозным инструментом.
Разработчики из Google AI попытались пересмотреть как спроектированы современные физические движки. И сделали следующие выводы, где потенциально их можно ускорить:
-
Использование кластеров с CPU для симуляции физики занимает очень много времени для взаимодействия по сети, нейросеть может получить результаты в лучшем случае через 10 миллисекунд после их появления. Если же запускать симулятор на том же устройстве, где происходит обучение, то задержка может составлять порядка 1 наносекунды.
-
Также много времени занимает сериализация данных для передачи по сети, даже с таким довольно эффективным форматом как Protobuf.
-
Вычисления, которые делает каждая копия симулятора, очень похожи, но не являются полностью одинаковыми, что не позволяет их эффективно распараллелить на одной машине.
Исходя из того, что физические вычисления на всех копиях симуляторов очень похожи, в новом физическом движке Brax разработчики попытались устранить основную причину, не позволявшую эффективно объединять расчеты в параллельные батчи для GPU. Чтобы использовать матричные операции, по аналогии с обучением нейросетей. А именно: ветвление в алгоритмах физических движков из-за оператора IF. Например, если мяч отскакивает от стены, то внутри физического движка запускается отдельный блок кода, выявленный оператором IF.
Для этого в Brax применили комбинацию из нескольких подходов:
-
Заменили операторы IF в коде на непрерывные функции, такие как аппроксимация столкновения шара со стеной с помощью signed distance function. Такая функция возвращает отрицательное значение, когда объект проникает внутрь стены. Использование в формулах signed distance функций вместо обычных абсолютных координат (на основе которых потом с помощью IF определялось столкновение), позволило создать одинаково выглядящий код без ветвлений, который можно матричным способом запустить в батче на GPU. Именно этот подход дал наибольший прирост производительности.
-
Где это возможно, заменили ветвления в коде на динамическую компиляцию, то есть компилируемый во время выполнения код (just-in-time compilation). Многие ветвления в коде физических движков основаны на статических свойствах окружения, например на самой принципиальной возможности двух объектов столкнуться.
-
Запуск расчета обеих частей ветвления, а после выбор только нужного результата. Это похоже на контейнерные вычисления, которые делает любой современный процессор. Но так как приходится выполнять излишний код, это добавляет лишние операции по сравнению с двумя пунктами выше.
После того, как код приобрел унифицированный вид (без ветвлений), это упростило его вид, и позволило запустить упрощенными батчами на одном GPU. С учетом избавления от сетевых задержек от внешнего кластера параллельных CPU, это ускорило итоговое обучение reinforcement learning нейросетей в симуляторе в 100-1000 раз.
Графики ниже показывают возможности движка Brax по симуляции физики.
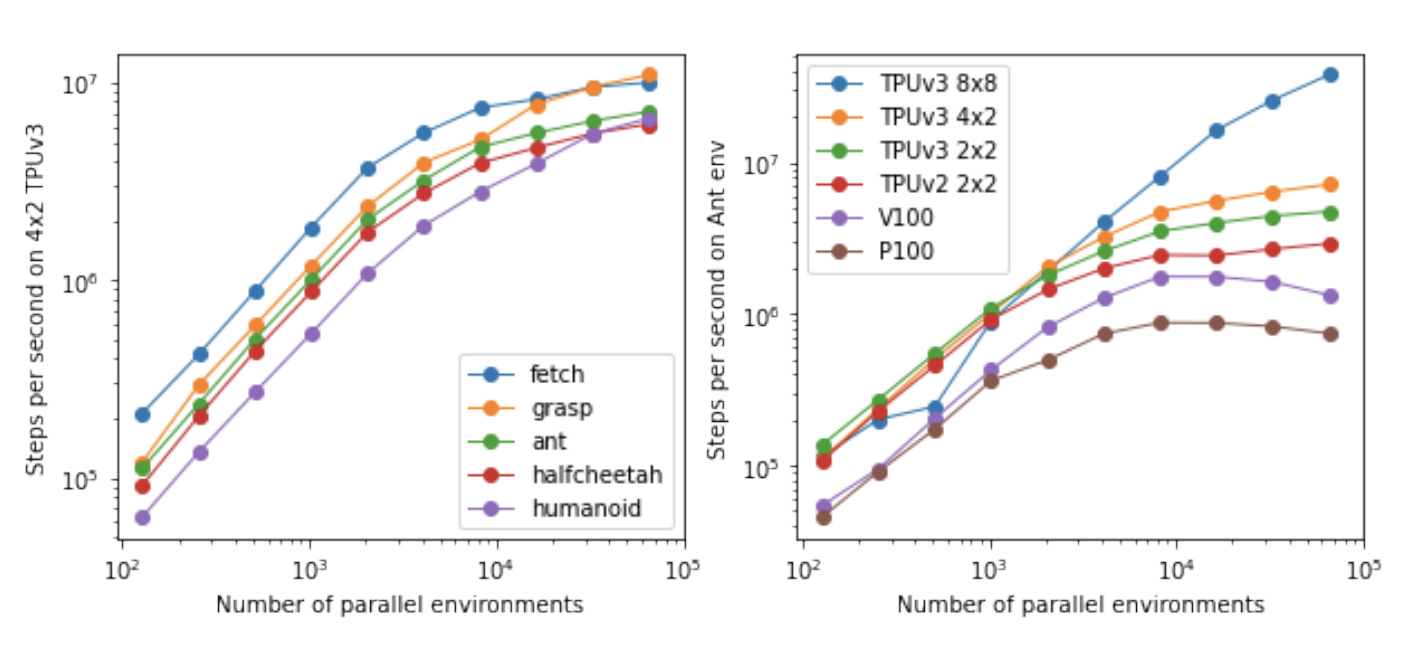
Из текста оригинальной статьи не совсем ясно, что означает вертикальная ось, но похоже, это суммарная производительность всех параллельных симуляторов. То есть, порядка 10 миллионов шагов симуляции делают все 100 тысяч параллельных симуляторов в сумме (хотя там же отмечается, что система упирается в ограничение по памяти на 10 тысячах параллельных симуляторов). В любом случае, этот график показывает, что производительность Brax растет практически линейно от числа запускаемых параллельных симуляторов.
Причем для гугла в первую очередь имеют значения их родные TPU (TPUv3 8x8 на графике означают 64 чипа TPUv3, соединенных высокоскоростным соединением). Но также видно, что Brax способен выдавать на одиночных GPU видеокартах уровня V100 и P100, используемых, в частности, в бесплатном сервисе Google Colab, на простых окружениях (таких как Ant - бегающий по земле четырехлапый паук) около миллиона шагов симуляции при 10 тысячах параллельных симуляторах.
К сожалению, не совсем ясно, эквивалентны ли эти шаги симуляции кадрам в секунду FPS, или это голые шаги симуляции как в обычных физических движках. Потому что каждому кадру в секунду у обычных движков соответствует от 4 до 50-100 внутренних шагов симуляции (фиксированных либо адаптивных), где суммируется результат от таких небольших подшагов.
В любом случае, это большое достижение, позволяющее проводить эксперименты с обучением с подкреплением на домашних компьютерах.
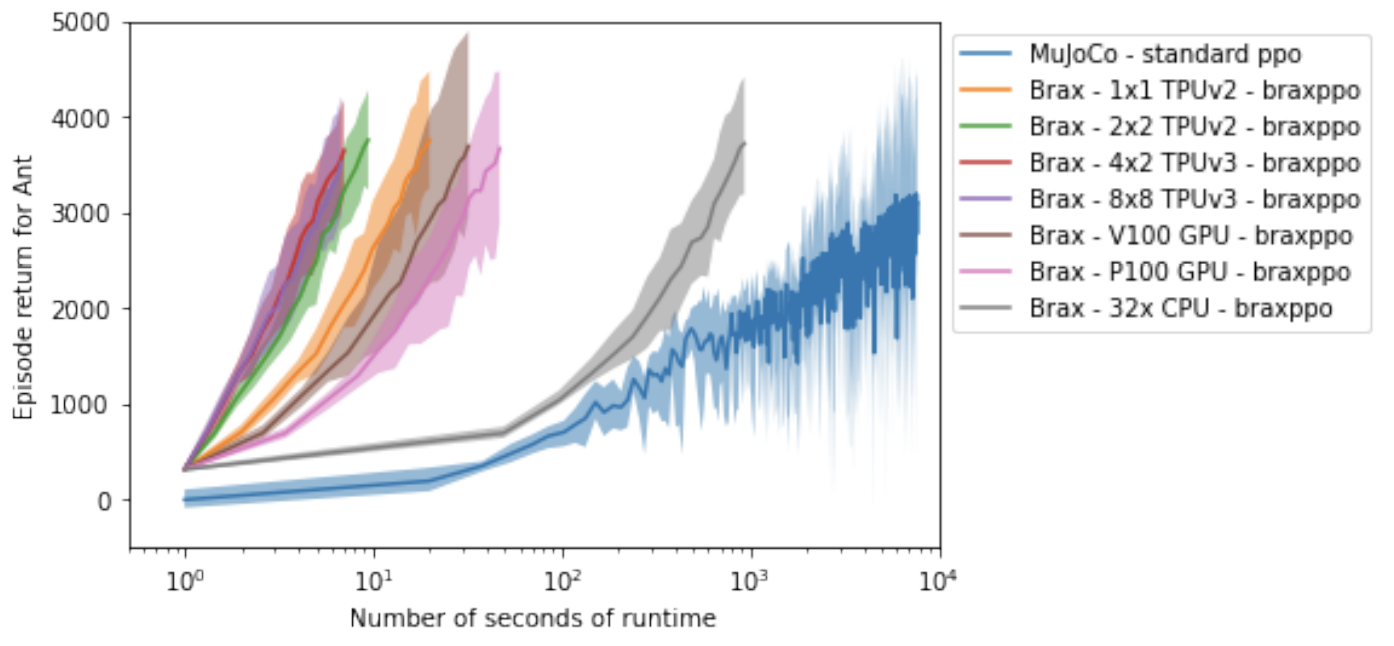
В оригинальной статье также приводится график общего времени обучения для Ant окружения по сравнению с классическим физическим движком MuJoCo, традиционно используемым для этого класса задач.
Более того, авторы сравнили точность Brax с основными существующими физическими движками: две версии MuJoCo, отличающиеся алгоритмами, PhisX и Havox - быстрыми движками, применяемыми в играх и использующими частично GPU.
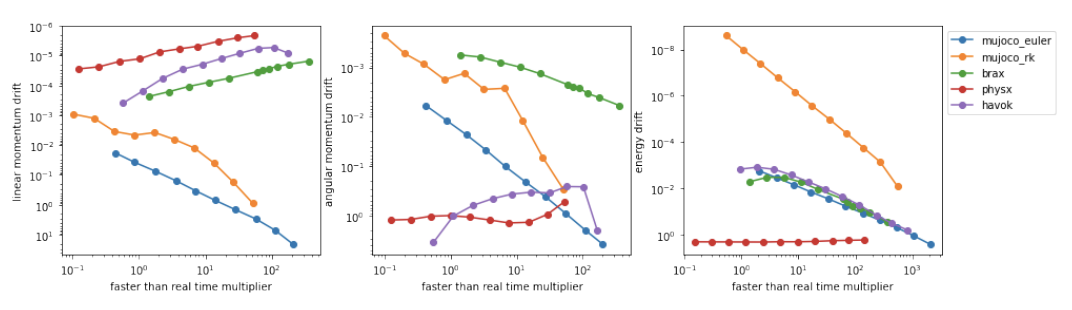
Этот график показывает (ссылка на PDF с объяснением методики измерений), какой у движка получается дрейф линейного момента, углового момента и энергии, по мере увеличения шага симуляции. Чем меньше этот дрейф, то есть чем выше кривая на графике, и чем линейнее этот график (то есть не зависит от увеличения шага симуляции), тем лучше. Как видно, новый движок Brax работает на уровне лучших существующих физических движков.
В принципе, Brax можно использовать и для других целей, а не только для Reinforcement Learning. Как добавлять объекты в сцену и запускать симуляцию, есть неплохое пошаговое обучение на официальной странице Brax на github в виде Colab ноутбука: basics.ipynb.
Также в комплекте Brax есть готовые OpenAI окружения, которые легко запустить для экспериментов. Это окружения Ant, Reacher, HalfCheetah, и в том числе популярное окружение Humanoid (бегающий человечек). А также несколько специфических окружений для робототехники.

Ссылки:
-
Официальная страница Brax: https://github.com/google/brax
-
Статья на сайте препринтов: https://arxiv.org/abs/2106.13281
Комментариев нет:
Отправить комментарий