Мы искали сервис, в котором можно оценить качество городской среды, чтобы выбирать комфортные места для прогулок. Поиск не увенчался успехом, поэтому на примере Питера мы сделали свою карту гулябельности.
Что такое гулябельность и в чем проблемы ее оценки?
Существует термин walkability, который в русской версии Википедии переводится как Пешеходная доступность. Пешеходная доступность, на наш взгляд, не самый удачный термин, так как доступность сама по себе – это скорее про изохроны. Walkability же – это про то, насколько пространство приспособлено для прогулок. Поэтому в разговорной речи иногда используют дословный перевод walkability – гулябельность.
Про гулябельность часто говорят в контексте качества и комфортности городской среды и городских пространств. Эти термины объединяет то, что их можно выразить некоторым показателем, который будет говорить: в одном месте людям хорошо, а в другом плохо. И тема эта довольно популярная: свежая статья Алексея Радченко про комфортные города, много статей от Городских проектов, карта эмоций города Imprecity, американский сервис по оценке гулябельности, сервисы пешеходной навигации от Urbica и Yahoo.
Вычисление этого показателя – комплексная задача, зависящая от множества критериев, для определения которых разрабатывают свои методики и стандарты. Среди них можно выделить несколько интересных примеров.
Пример 1. Книга датского архитектора Яна Гейла «Города для людей», в которой было сформулировано 12 базовых критериев качества пространства, разбитых на три базовые группы – безопасность, комфорт и удовольствие.
Проблема: часть критериев на практике не поддаются автоматизации, такие как «возможность сидеть» (сложно получить данные о каждой скамейке), погода (сложность определения солнечных и теневых зон) и т.д. Для них, по сути, необходимо выходить из дома и оценивать городские пространства на месте.
Пример 2. Методика расчета предлагает также Нью-Йоркский институт ITDF, который ставит в центре внимания тему пешеходной доступности.
Проблема: пространство города представлено как дискретное, из-за чего места, расположенные рядом, могут сильно отличаться друг от друга.
Пример 3. Проект индекса качества городской среды, разработанный Минстроем и ДОМ.РФ совместно с КБ Стрелка, которые произвели расчеты для 1114 городов России. Их индекс рассчитывается на основе 36 индикаторов.
Проблема: расчеты ведутся на уровне города, исходные данные редко предоставляются открыто, а для уровня кварталов и улиц данные практически отсутствуют.
Наша идея
Мы учли перечисленные недостатки и решили реализовать собственный подход к расчётам. Наша основная идея в том, чтобы:
-
автоматизировать расчёты показателя качества городской среды
-
моделировать пространство как непрерывное
-
производить расчеты на крупном масштабе (улицы, кварталы)
-
использовать открытые данные
За основу мы взяли разделение критериев качества городской среды по Яну Гейлу, но на текущий момент ограничились только некоторым показателями комфортности.
")
Из наиболее значимых критериев мы выбрали:
-
визуальные – плотность и высотность застройки (попадает под критерий масштаба) и озеленение;
-
уровень шума.
Центральной фигурой расчётов стало положение наблюдателя и его область видимости (двумерной), а также объекты городской среды, которые попадают в поле зрения наблюдателя – растительность и здания. При оценке уровня шума мы учитывали только влияние транспорта.
Чтобы покрыть весь город необходимым значением индекса, нужно задать множество положений наблюдателя (набор регулярных точек-положений) и на их основе рассчитать полигоны области видимости. Объекты городской среды, попадающие в эти области, должны быть использованы для расчета количественных показателей качества.
Данные
Все необходимые векторные объекты (растительность, здания, дороги, водные объекты, мосты, районы города) мы взяли из открытых данных OSM с помощью утилиты фильтрации данных overpass turbo.
Растительность
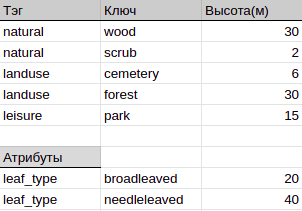
В слой растительности мы включили несколько типов объектов, в которых зачастую имеются древесные насаждения:
Каждому типу назначили высоту, необходимую для расчетов областей видимости. Так как найти данные для этой задачи довольно сложно, мы ее взяли среднюю на наш взгляд:
Здания
В слое зданий мы столкнулись с проблемой дефицита информации об их высоте.
")
Поэтому мы взяли необходимые данные из Росреестра при помощи утилиты, которая также используется в проекте карты возраста домов, и, проведя геокодирование, дополнили слой зданий сведениями об этажности. Чтобы привести высоту к одной метрике с растительностью, мы приняли фиксированную высоту этажа в три метра (округление типовой высоты этажей в жилых зданиях по СНиП 31-01-2003).
")
Методика
Для создания областей видимости есть готовый ГИС-инструментарий. В QGIS это плагин Visibility analysis, принимающий на вход цифровую модель местности (ЦММ) – рельеф плюс любые объекты на поверхности, и возвращающий для каждой точки растр видимости.
В Grass GIS это r.viewshed. Мы остановились на нем из-за сложностей, возникших при попытке создания цепочки алгоритмов в QGIS (промежуточные результаты не закрывались утилитой GDAL, в связи с чем превышалось количество допустимых соединений). В r.viewshed также можно настроить дополнительные параметры, которые есть у всех подобных инструментов: максимальный радиус видимости, который мы эмпирически выставили на 110 метров, высота наблюдателя (используем 1.6 метров = средний рост человека минус 10 см до уровня глаз) и пр.
Влияние атмосферной рефракции и поправки на кривизну Земли мы не рассматривали из-за небольшого радиуса видимости и относительно ровного рельефа территории, на которой находится Санкт-Петербург. Равнинный характер местности также служит причиной того, что мы не будем использовать рельеф, а ограничимся высотами зданий и растительности при построении ЦММ.
После выбора основного инструмента надо определиться с генерацией данных, которые он требует на входе:
Для начала создаем сетку регулярных точек:
-
генерируем гексагональную сетку со стороной полигона в 50 м, а затем строим точки – центроиды каждой ячейки;
-
исключаем точки, которые попадают на крыши зданий, так как нас интересует только outdoor.

Далее строим ЦММ. Для этого нужно:
-
растеризовать полигоны зданий и растительности (используя библиотеку GDAL), присвоив каждой ячейке растра значение их высоты;
-
суммировать значение ячеек растровым калькулятором, чтобы получить итоговую модель.
Особенности построения:
-
нужно, чтобы слои растительности и зданий не пересекались, иначе их высоты будут складываться;
-
при попадании регулярных точек в полигоны растительности наблюдатель окажется на деревьях, что недопустимо. Поэтому мы создаём буферы вокруг этих точек размером со среднее расстояние между деревьями в парках (7 м), а затем вырезаем эти буферы из объектов растительности.
")
Следующий этап – скрипт на Python, который будет считает области видимости. Размещаем все необходимые для расчетов векторные слои в базе данных PostgreSQL с установленным расширением PostGIS. Далее:
-
итерационно проходим по координатам созданных регулярных точек;
-
применяем алгоритм r.viewshed для создания растра видимости;
-
векторизуем растр инструментом Grass r.to.vect для быстрого экспорта данных;
-
используем утилиту командной строки библиотеки GDAL ogr2ogr, чтобы извлечь только геометрии полигонов видимости, которые скрипт будет заносить в итоговую таблицу PostGIS вместе с геометрией регулярных точек.

Построение ЦММ и генерация сетки регулярных точек на каждый район автоматизируется за счёт:
-
функций PostGIS (прежде всего, ST_HexagonGrid);
-
алгоритмов GRASS (предобработка слоев) и утилит командной строки GDAL (растрирование и наложение слоев).
В итоге достаточно запустить скрипт и передать ему идентификатор района/ов, а остальную работу он выполнит сам.
Количественные характеристики критериев комфортности
Как говорилось выше, мы берём в расчет визуальные критерии (плотность застройки, высотность окружающих объектов, озеленение), а также шумовое загрязнение для расчета комфортности городской среды. Необходимо определить количественные характеристики для этих критериев.
Визуальные критерии
Для плотности застройки используем площадь области видимости. Соответственно, чем меньше площадь, тем выше плотность и тем более комфортно человеку (конечно, до разумных пределов).
Для высотности используем медианная высоту растительности и зданий. Чем выше окружающая среда, тем человек чувствует себя более маленьким на их фоне (эффект масштаба), поэтому и снижается комфортность.
Для растительности используем расстояние до ближайшего полигона растительности от положения наблюдателя для критерия озеленения. Чем меньше, тем лучше. При этом, если ни один полигон не попадает в область видимости, то параметру присваивается значение -1 (потому что теоретически точка может находится прямо на границе полигона, и такое часто происходило на практике).
Для вычислений количественных характеристик можно написать SQL функции, которые будут итерационно определять отношение областей видимости к объектам городской среды.
Уровень шума
Чтобы оценить влияние шума, мы использовали алгоритм noisemap (спасибо Urbica за это). Программа на основе данных OSM строит три зоны: 45 дБ, 55 дБ и 65 дБ вокруг каждого объекта, а затем объединяет их по значению в крупные полигоны. В проекте уже содержатся сведения об уровнях шумового загрязнения для множества объектов.
Для решения поставленной задачи мы дополнили эти сведения приблизительными значениями для проездов (highway=service), и соединений дорог (highway=*_link). Также пришлось модифицировать программу под решаемую нами задачу. Мы добавили:
-
возможность использования входных данных, полученных из QuickOSM;
-
настраиваемый параметр учета высоты источников шума;
-
параметр, позволяющий рассчитывать полигоны с любым уровнем шума и в любом количестве;
-
нарезку полигонов шума по плотной квадратной сетке для оптимизации дальнейших вычислений (до этого на выходе получались полигоны размером с город);
-
оверлей difference, чтобы итоговые полигоны не пересекались друг с другом.
После генерации данных полигонов остается написать еще одну SQL функцию, которая будет проверять, полигон с каким значением шума содержит заданную точку, и записывать это значение в атрибуты.
Расчет комфортности
Визуальная оценка
Перед тем, как вычислить интегральный показатель комфортности, мы отобразили в Mapbox Studio все визуальные критерии. Полученная карта подходит для визуальной оценки трех критериев, но при увеличении их количества использовать её нельзя.

Обобщенный показатель
На завершающем этапе выполняем расчёт обобщённого показателя комфортности на основе полученных значений частных показателей качества. Для этого все количественные характеристики нужно привести к единому виду, то есть нормализовать, чтобы они входили в интервал [0,1], обратно пропорционально исходному диапазону значений. Мы использовали нормализацию от нуля до единицы:
-
Для плотности застройки [0, ∏Rmax^2], где Rmax – максимальный радиус видимости.
-
Для критерия озеленения [0, Rmax], при этом следует учитывать, что значение -1 станет нулем.
-
Для критерия высотности [15, 60] (подобрано эмпирически), всё, что меньше или больше автоматически становится единицей или нулем соответственно.
-
Для шумового загрязнения это [0, 80], как получается на выходе программы noisemap.
Мы пошли по простому пути и использовали одинаковые веса для всех частных показателей комфортности.

Последний штрих
Чтобы обеспечить непрерывное покрытие, проводим линейную интерполяцию полученного показателя между рассчитанными точками и получаем непрерывный грид. Далее грид можно реклассифицировать (инструментом r.reclass) и векторизовать (r.to.vect). В результате формируется векторный слой с полигонами, каждый из которых содержит значение индекса комфортности.
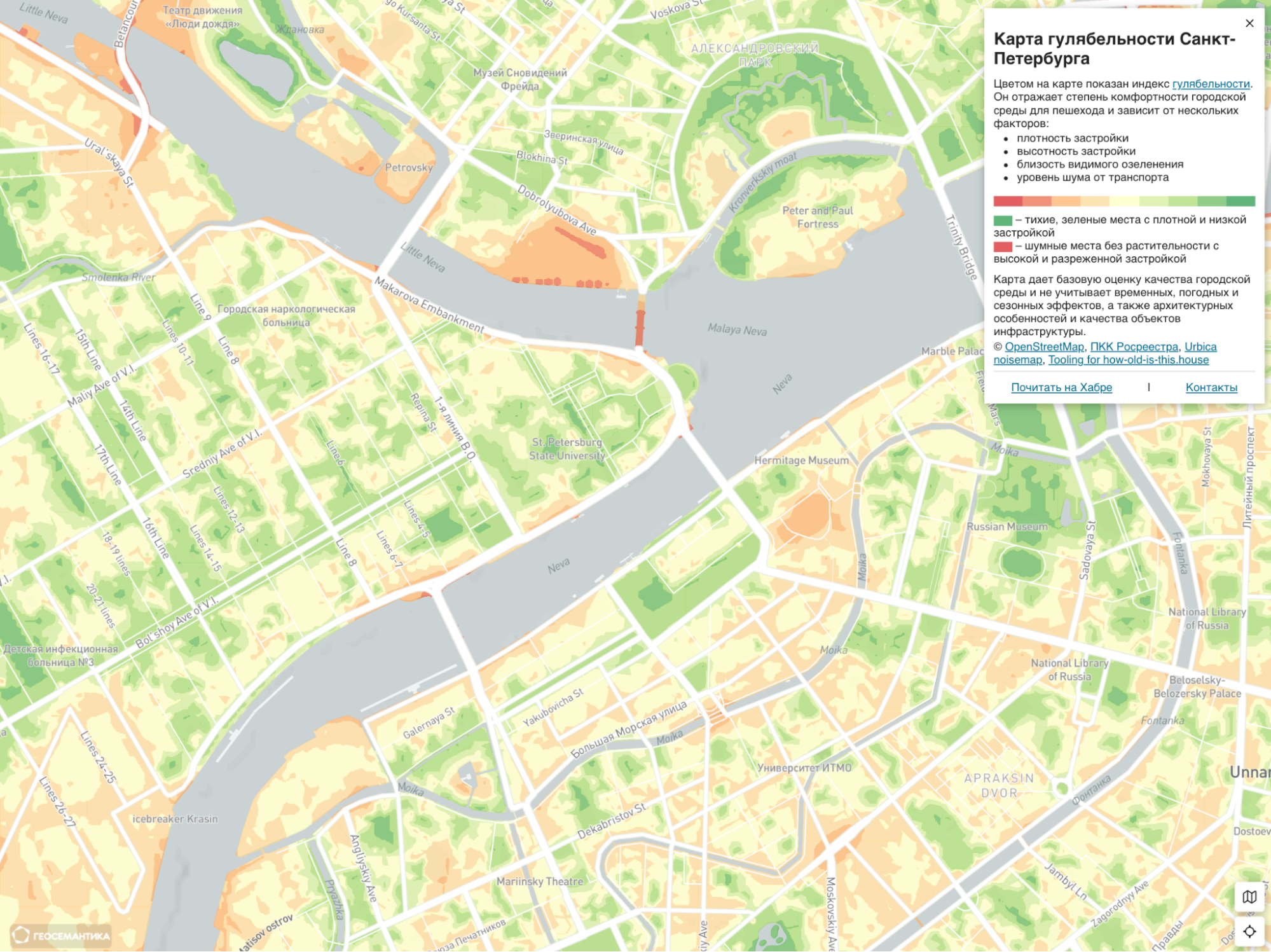
Улучшение результатов
Озеленение
При работе с данными OSM мы обнаружили существенную нехватку полигонов растительности. Это хорошо видно при изучении космических снимков. Поэтому для улучшения результатов мы добавили собственные полигоны в редакторе геоданных OSM iD. Так как пропущенных полигонов оказалось слишком много, пришлось искать другие источники. К примеру, мы использовали геоданные зеленых насаждений, представленные на сайте региональной геоинформационной системы Санкт-Петербурга — RGIS.
Также был использована платформа Geoalert, основанная на методах машинного обучения для автоматизированного выделения контуров объектов на снимках.
Уплотнение сетки регулярных точек
Мы изучили изменения в распространении индекса комфортности при изменении величины гексагонов, на основе которых строятся регулярные точки. При уменьшении значения результаты становились более полными.
На рисунках слева показана карта, в которой не учтены наши изменения, а справа – карта с учётом добавленных всеми вышеописанными способами полигонов растительности и уплотнённой сетки регулярных точек (до 25 м).


Публикация в вебе
Полученный слой мы разместили на https://walkability.ru. Помимо него, в системе доступны слои, на основе которых были получены частные критерии:
")
")

Known issues
Мы осознаем, что в описанной методике мы основывались на ряде допущений, некоторые факторы мы не учитываем в принципе, открытые данные также зачастую неполные, и необходимо привлекать дополнительные источники.
Барьеры
Заборы
Мы не учитываем заборы, которые способны радикально изменить размеры и форму областей видимости, а также снизить влияние объектов интереса на восприятие наблюдателя. Всё дело в том, что ширина непрозрачных заграждений зачастую доходит до 10-20 см (а то и меньше) и поэтому необходимо использовать ЦММ высокого пространственного разрешения. Вычисления займут огромное количество времени, да и высота таких заграждений также имеет большое значение, а найти эти данные на текущий момент затруднительно.
Экраны
Не учтены шумоподавляющие экраны возле дорог. Причина примерно такая же, что и с заборами. Кроме того, данных о наличии экранов довольно мало. Для расчета же полигонов шума достаточно сложно учесть влияние экранов, но об этом можно подумать в будущем.
Низкая растительность
Мы также не учли влияние травы и низкорослых кустарников на восприятие наблюдателя. Хоть оно и небольшое по сравнению с влиянием остальных объектов растительности, но эффект всё же имеется.
Другие источники шума
Исходные данные
Мы использовали только автомобильные и железные дороги при построении полигонов шума. Естественно, существует еще много объектов, которые следовало бы учесть здесь. К примеру, заводы, строительные площадки, станции метро и т.д. Присваивание каждому типу объектов один и тот же уровень шума снизит объективность результатов.
Высота источника шума
На текущий момент учет высоты источников шума происходит косвенно (на основании данных о последовательности отображения дорог), однако реальных данных об этой высоте практически нет. Из-за этого есть довольно сильные искажения в районе ЗСД.
Что дальше
Чтобы сделать сервис еще лучше нам важно собрать ваши мнения о том, соответствует ли рассчитанный индекс восприятию комфортности. Для этого, пожалуйста, пройдите короткий опрос.
Если вам понравился проект – следите за обновлениями в соцсетях: инстаграм, телеграм.
Благодарности
Сервис создан на основе диссертационных исследований Александра Семенова из Федерального Исследовательского Центра РАН. Также благодарим за помощь и консультации Александру Ненько из QULLAB, Ольгу Краснову из MLA, Юлию Малкову из TOBE architects и Никиту Славина из Кон-Тики.
Комментариев нет:
Отправить комментарий