
Всем привет! Добро пожаловать на презентацию об immutable infrastructure – достигая недостижимого идеала. Перед тем как мы начнем, хотел бы сделать небольшое вступление.

Сама по себе immutable infrastructure – это тот подход, в который я очень сильно верю. И мы успешно применяли его в нашей консалтинговой практике в компании FivexL. И, к сожалению, на территории русскоязычных пространств я не видел дискуссии об immutable infrastructure. Я не видел, чтобы люди ее много обсуждали и пользовались этим подходом. Очень много было людей, которые делали синхронизацию конфигурации, например, с помощью Ansible. Ansible очень популярен.
И поэтому в качестве небольшого троллинга я сделал презентацию в декабре прошлого года, которая называлась «Почему я не рекомендую учить Ansible?». И через этот кликбейт-заголовок я надеялся привлечь и инициировать дискуссию о immutable infrastructure.

Но я все же понял, что выбор заголовка был не самым удачным. Люди пришли послушать про Ansible, и, к сожалению, у меня не получилось донести ту информацию об immutable infrastructure, которую мне хотелось донести. Поэтому мы заходим на следующий круг с этой презентацией.
Очень много изменилось с того момента, как я делал презентацию о том, почему я не советую людям учить Ansible. Прошло почти полгода. Появились новые инструменты, новые подходы, поэтому сегодня мы будем смотреть примерно на тот же вопрос, а именно, почему стоит делать неизменную инфраструктуру, почему это хорошо, но зайдем с другой стороны. Надеюсь, что в этот раз получится лучше.

Immutable infrastructure – это не сама цель. Это не то, ради чего мы делаем то, что мы делаем.

Что же тогда является самой целью? Мы будем заходить на immutable infrastructure с точки зрения динамических нехрупких систем и того, как такие системы строятся.

Давайте рассмотрим, какие есть типичные нужды бизнеса.
- У бизнеса есть проблема, что они не могут работать с той нагрузкой, которая приходит на их сервисы. И они не могут масштабироваться.
- Они не могут доставлять новые изменения от своих разработчиков достаточно быстро, чтобы реагировать на изменения рынка.
- Их системы могут быть чересчур сложны в обращении или их тяжело менять.
- У них есть проблемы с восстановлением, что делать, если где-то дата-центр ляжет. Или сами системы могут быть хрупкими.
- Плюс всегда есть сомнения по поводу безопасности и compliance с разными государственными стандартами.

Что в свою очередь хотят девелоперы?
Девелоперы хотят просто deploy. Они хотят:
- Heroku,
- Netlify,
- Serverless.
Они не хотят думать про все эти проблемы инфраструктуры. Они хотят брать свой код и максимально простым образом доставлять его заказчикам и чтобы инфраструктура каким-то магическим образом подстраивалась под него и под запросы, которые приходят извне.

Таким образом мы можем выделять какие-то критерии, по которым можем писать динамические нехрупкие системы.
Такими системами в этой презентации я буду называть:
- Возможность масштабирования.
- Выносливость системы к воздействиям на нее.
- Возможность системы к самолечению, т.е. если один из узлов системы вылетел, то система должна иметь возможность подлечиться и поднять новый узел.
- И возможность воспроизвести эту систему, т.е. если у нас весь дата-центр лег, возможность её пересоздать при необходимости.

И я вижу, что есть несколько компонентов, которые нам нужны для того, чтобы выстраивать такие системы:
- Это неизменная инфраструктура как код. И об этом мы сегодня будем много разговаривать.
- Это service discovery. Мы чуть-чуть его потрогаем, но это тема для отдельной презентации.
- Это динамическая конфигурация и менеджмент секретов.
- Это Zero Trust. Под Zero Trust я понимаю парадигму построения сетей, когда каждая нагрузка в сети идентифицируется не через IP-адрес, и безопасность выстраивается не через firewalls, а через identity. Т.е. когда у вас каждая нагрузка идентифицирует себя с сертификатом. Есть центральная Authority на сертификаты. И основываясь на сертификатах, на поведении нагрузки контрольная система, которая роутит трафик: разрешает или не разрешает этот трафик. Мы уходим от статических firewalls к более динамическим системам.

И перед тем как мы начнем, я представлюсь. Меня зовут Андрей Девяткин. Я консультант, специализирующийся на cloud engineering. Работаю много с облаками AWS и с инструментами HashiCorp. В этом году стал AWS Community Builder и HashiCorp Ambassador. Также являюсь сооснователем консалтингового агентства FiveXL. И записываю подкаст с друзьями, который называется DevSecOps Talks.

Давайте поймем, как у нас получается статическая и хрупкая инфраструктура, от которой мы хотим уйти.

Очень типичная история. Кажется, что это уже пройденный этап, но снова и снова к нам приходят заказчики со следующими ситуациями. Представьте, что есть маленькая компания либо стартап. Подняли немножко денег, наняли одного-двух разработчиков. Сделали MVP, надо это где-то захостить.
Они идут в Amazon. Там у них происходит ClickOps. Это означает, что они с панельки накликали себе серверов. Ходят на эти сервера по SSH, по SСP туда копируют код. Подняли nginx, делают letsencrypt. Вуаля, у них есть сервис, который доступен всему миру и как-то зарабатывает деньги. На каких-то небольших масштабах это может работать. Но все завязано на IP-адресах, все очень статично.

Вы могли обратить внимание, что один сервер назывался NewProd. Что же случилось со старым?

http://kief.com/configuration-drift.html
А с ним случилось следующее. Как известно, когда сервера управляются руками, когда туда постоянно ходят люди и что-то там меняют, там начинает накапливаться конфигурационный дрифт.
Конфигурационный дрифт – это отклонения сервера от того состояния, в котором мы хотели бы его видеть.

https://martinfowler.com/bliki/SnowflakeServer.html
Эти изменения накапливаются, накапливаются, накапливаются. И в конце концов мы получаем сервер-снежинку, который стал настолько уникальным, что отличается от всех остальных серверов и никто не знает, как он таким получился. И никто не знает, как его пересоздать.
Я уверен, что у многих из вас были ситуации в вашей карьере, когда вам приходилось пойти на такой legacy-сервер, который каким-то образом существует, и вам надо на нем что-то поменять. В эти моменты страшно, потому что, если что-то пойдет не так, то нет четкого пути назад. Т. е. нет четкого понимания, как откатиться назад, если что-то пошло не так.

Вернемся к нашему стартапу. У них происходит рост. У них получается больше трафика. Соответственно, они хотят больше мощностей. Они берут nginx с сервера, где он был в продакшене. Двигают его на отдельный сервер. Я на картинке использую значок LB, но в нашем случае пусть это будет отдельный сервер, на котором сидит nginx с тем же letsencrypt. И в его статическую конфигурацию забиты IP-адреса двух серверов, которые сидят за ним.
Они каким-то образом убеждаются, что сервера сконфигурированы одинаково и продолжают копировать код. И все, в принципе, работает. Некоторые компании даже остаются в таком состоянии, потому что им больше не надо.
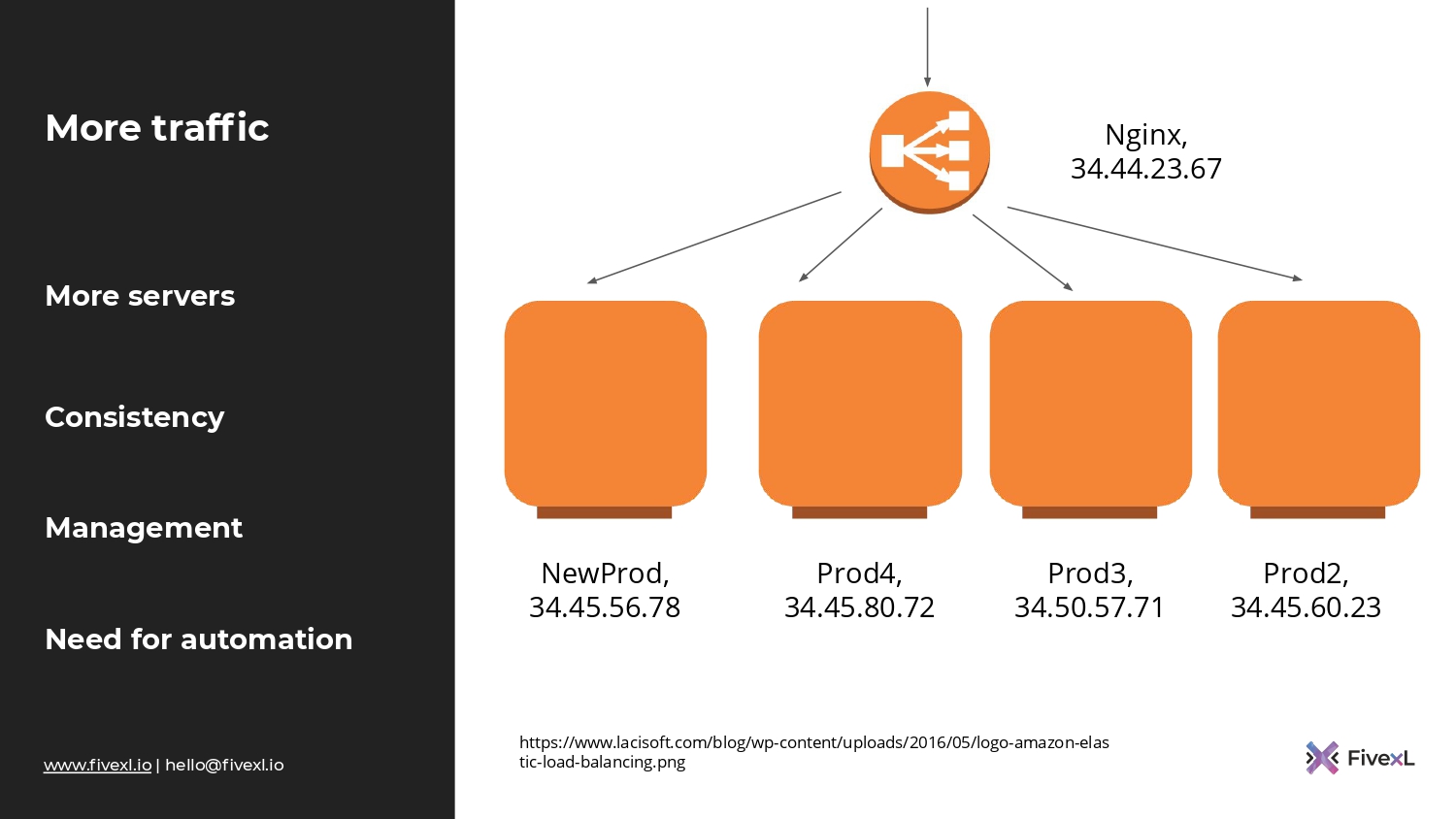
Но наш стартап продолжает расти. У них все больше серверов. И уже начинаются проблемы с тем, чтобы поддерживать консистентность серверов, накатывать на них изменения и менеджить весь этот парк. 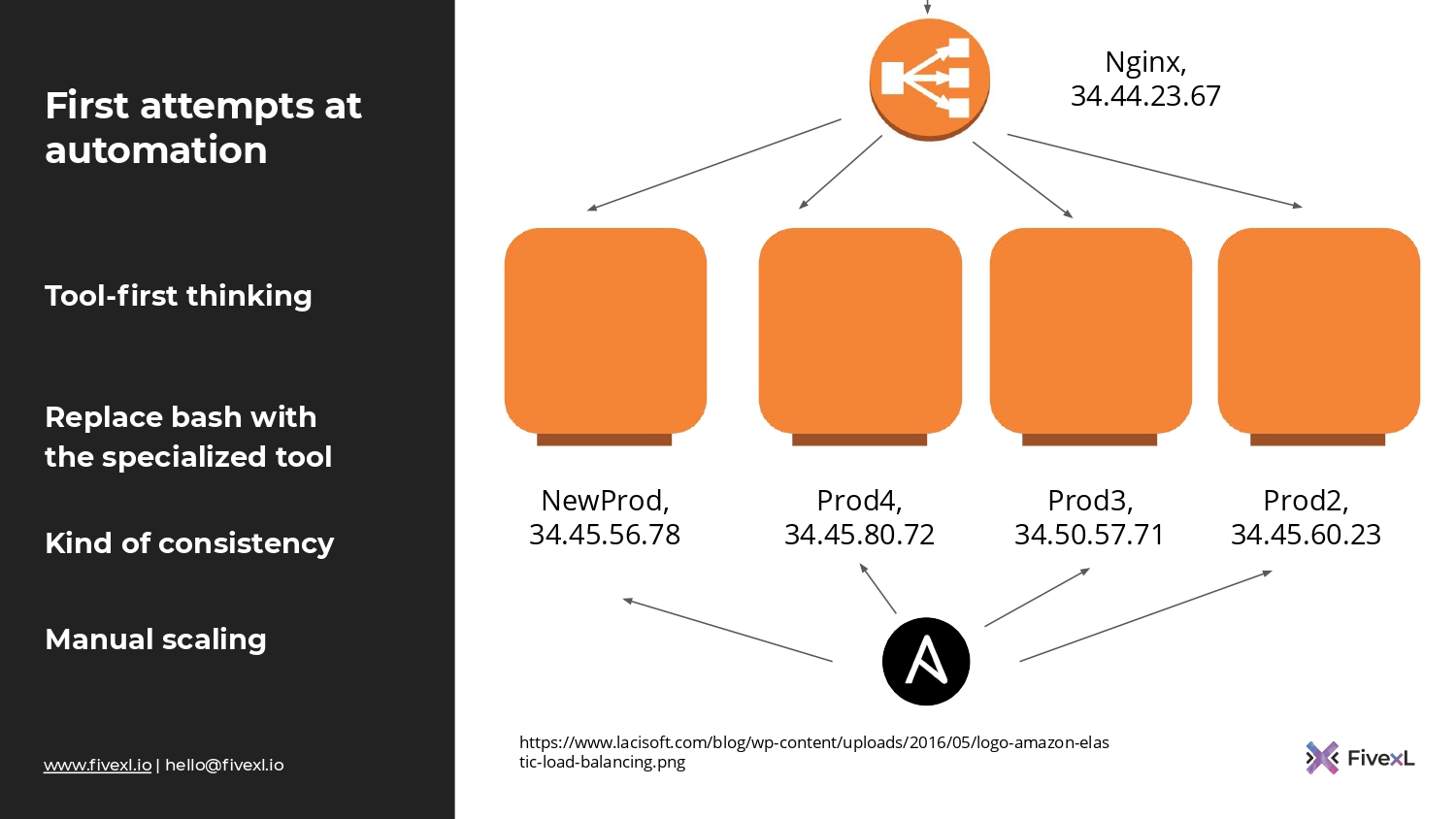
Они начинают чувствовать необходимость в автоматизации. И все так же ресурсы команды ограничены, т. е. там один-два, может быть, три девелопера. И они хватают то, про что они слышали. Если они в русскоязычном пространстве, то не услышать про Ansible очень тяжело. Скорее всего, они его возьмут и будут раскатывать изменения с помощью Ansible. Станет чуть-чуть получше. А, может быть, это будет какой-нибудь bash-скрипт, который у них по очереди ходит на сервера.
Но система все такая же статическая. Там тот же статический nginx, статические IP-адреса. И большая часть процессов происходит вручную. Если что-то упадет, то понадобится ручная интервенция для того, чтобы поддержать систему в том состоянии, в котором мы хотим ее видеть.

Наиболее продвинутые запускают все в докере, не копируют код и запускают Docker Compose.
На что мы еще обратили внимание? Зачастую команда из двух-трех девелоперов в этот момент упирается в то, что им нужно переходить на оркестратор для того, чтобы облегчить свою жизнь. Но этого скачка не происходит. Это именно тот момент, в котором, как мне кажется, людям нужен человек, который будет заниматься инфраструктурой, в которой будет автоматизация. Это я говорю, исходя из нашей практики. Я не претендую на правоту. Это то, что мы видим очень часто.

И тут мы можем видеть, что на картинке prod4 не получает трафика. Как же так? Что с ним случилось?

А с ним случилось вот, что. В какой-то момент на prod4 случился инцидент. Там поднакопилось конфигурационного дрифта. И он стал вести себя не так, как остальные 3 сервера. И ребятам пришлось пойти туда руками, что-то поправить. Он в какой-то момент вернулся в нормальное состояние, они вернули на него трафик. А потом они запустили свой инструмент, он что-то поменял и снова перестал работать.
И теперь они боятся что-то там менять. Они пока его все еще держат, они не прибили эту виртуалку. Они надеются ее вернуть в строй. Но в то же время они боятся запускать свой инструмент автоматизации, чтобы доставить туда новые изменения и могут это делать руками. И потихоньку из-за изменений руками происходит спираль автоматизации, которая идет вниз-вниз-вниз. И мы приходим к серверу-снежинке.

И это именно та проблема, которая есть в инструментах синхронизации конфигурации. Она некритичная. С этим люди живут. Но это что-то такое, о чем стоит задуматься.
Когда мы используем инструменты синхронизации конфигурации, мы поднимаем сервер и потом используем наш инструмент будь то, Chef, Puppet, Ansible и т. д. для того, чтобы накатить изменения. И потом повторно запускаем-запускаем-запускаем. Когда у нас изменяется наша спецификация, мы таким образом доставляем новые изменения.
Как вы можете видеть на картинке, желтым показана та область, которая управляются tool-ом, а за пределом, т. к. мы не можем все сервера поддерживать инструментом, у нас есть возможность для накопления конфигурационного дрифта. В какой-то момент система может быть подвергнута downtime из-за того, что конфигурационных дрифт нарушит работу или вступит в конфликт с изменениями, которые мы пытаемся накатить.

Может ли мы сделать что-то лучше?

В принципе, можем.
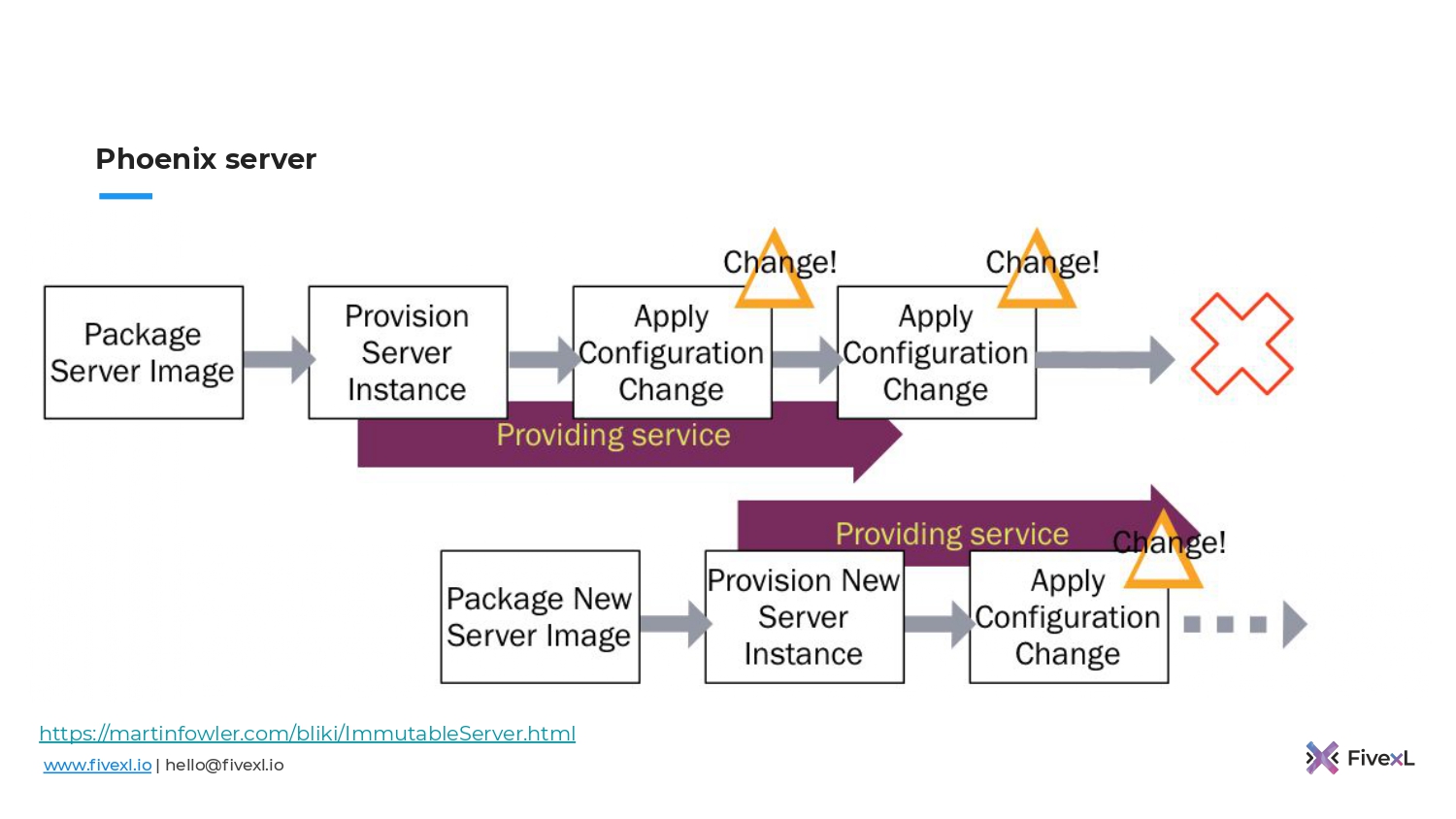
10 лет назад прогрессивное человечество подумало о том, чтобы делать то, что делали, но раз в неделю, в две недели или в месяц прибивать виртуалку. Поднимать новую и накатывать изменения тем же инструментом, которым пользовались. Таким образом мы отказываемся от конфигурационного дрифта, который там накапливался. Мы его обнуляем. Это неплохой вариант.

Многие из вас сейчас могут задуматься: «Если я сейчас начну убивать свои сервера и прокатывать их Ansible, буду ли я делать immutable infrastructure как код? Достаточно ли этого?». Вы будете достаточно близки к этому.

Сложно быть догматичным и делать все по книжке, т. к. жизнь не всегда прямая, у нас всегда будут какие-то лимиты, которые не будут позволять сделать именно так, как в книге.
Даже добавляя такой простой шаг в жизненный цикл ваших серверов, вы можете получить достаточно большой процент бенефитов от этого подхода immutable infrastructure. Но не все.
Давайте поговорим про то, что мы не получаем. Прогрессивное человечество подумало еще дальше.
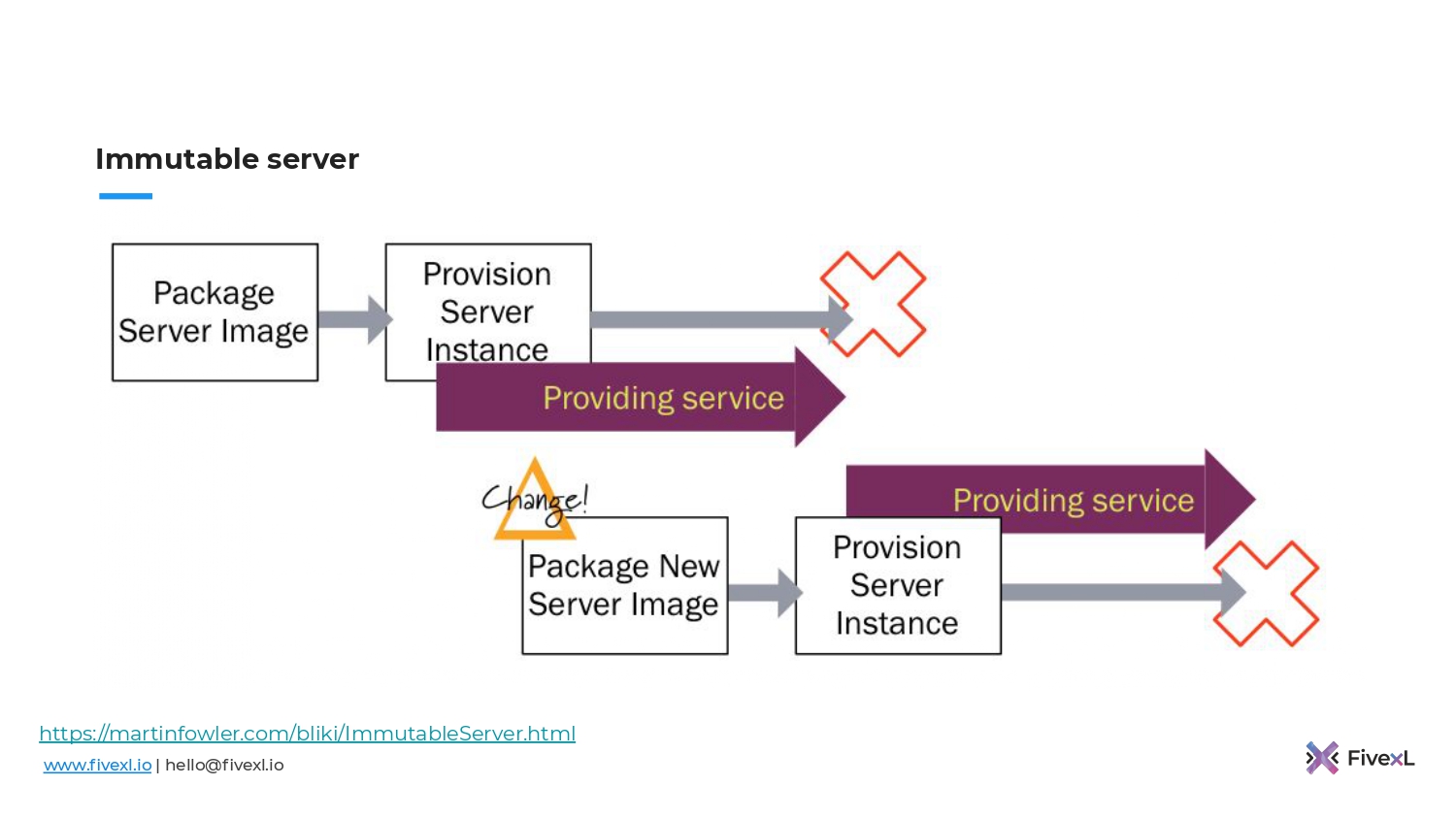
https://martinfowler.com/bliki/ImmutableServer.html
Оно подумало: «А что, если мы возьмем все эти изменения, которые накатывали на сервер и будем запекать в образ?». Когда образ поднимается с сервера, то там его уже не надо конфигурировать. Он сразу готов к эксплуатации. Не надо ждать. А если нам нужны новые изменения, мы подготовим новый образ, запустим, а старый убьем.
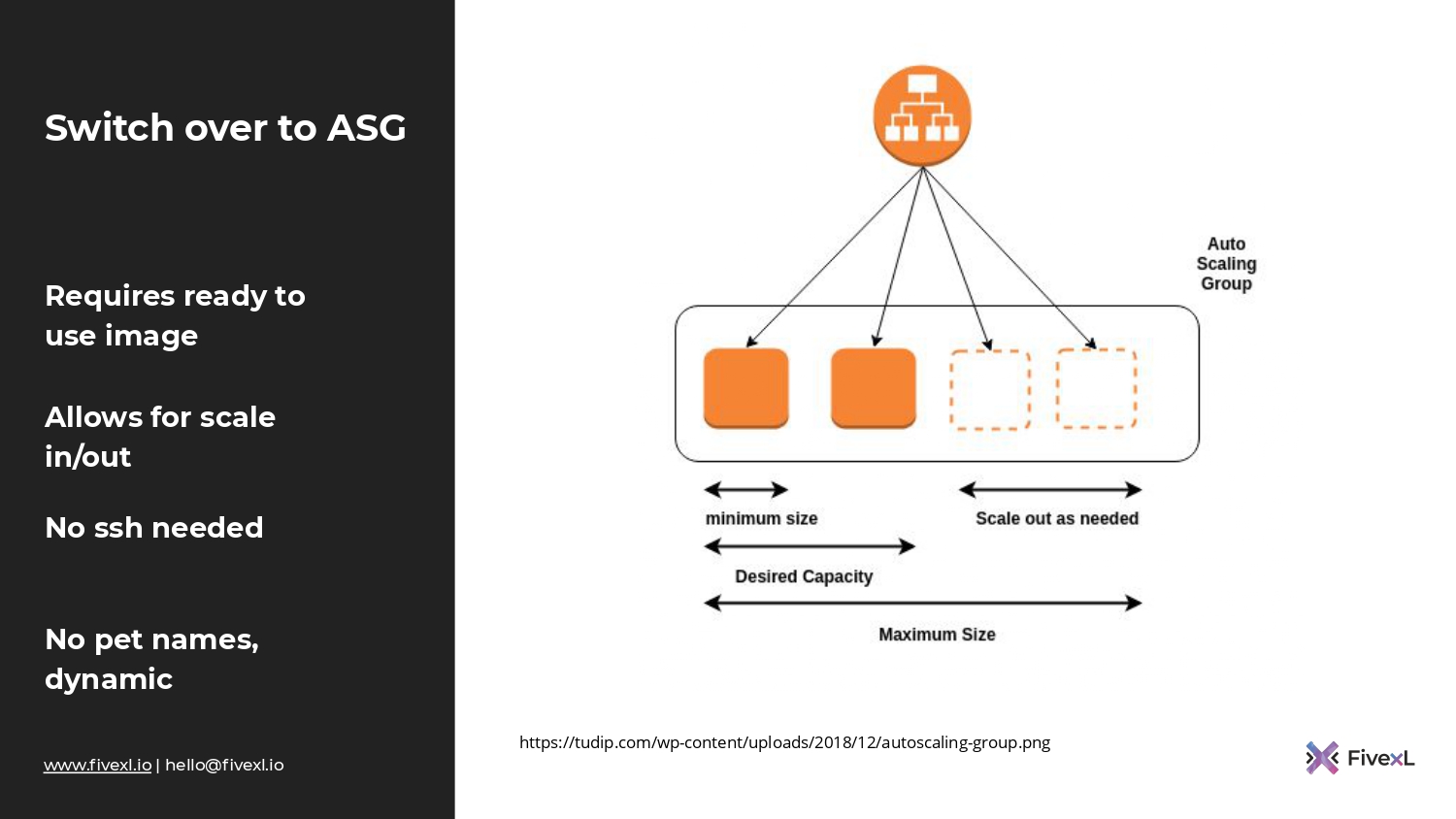
И плюс, у нас появляется важная возможность – autoscaling. Когда сервер поднимается, он уже готов к обслуживанию. Как только на нем проходят health checks, мы можем направлять туда трафик.
И, например, в AWS есть такой примитив, как auto scaling group, которой можно сказать: «Вот мой образ виртуальной машины. Когда поднимется нагрузка, добавь побольше. Когда нагрузки нет — убери». И это возможно, потому что наши образы готовы к старту. В них уже есть все то, что необходимо.
Когда мы делаем синхронизацию конфигурации, у нас сервер поднимается и потом нам надо еще на него конфигурацию накатить. В случае с immutable infrastructure у нас все готово к старту. И поэтому у нас нет нужды открывать, например, SSH-порт на эти сервера, потому что они уже готовы, туда не надо ходить. Там не нужно называть их каким-то образом, потому что они у нас будут постоянно меняться. Auto scaling group будет постоянно убивать, добавлять.
У нас один из серверов выпал, потому что, может быть, деградировало железо под этой виртуальной машиной. Auto scaling group добавила новую. Соответственно, мы отказываемся от таких вещей, как статические IP-адреса. Auto scaling group может пойти в Load Balancer и зарегистрировать в нем новые адреса автоматически. Т.е. у нас уже намного меньше ручной работы. И это то, где мы хотим быть.
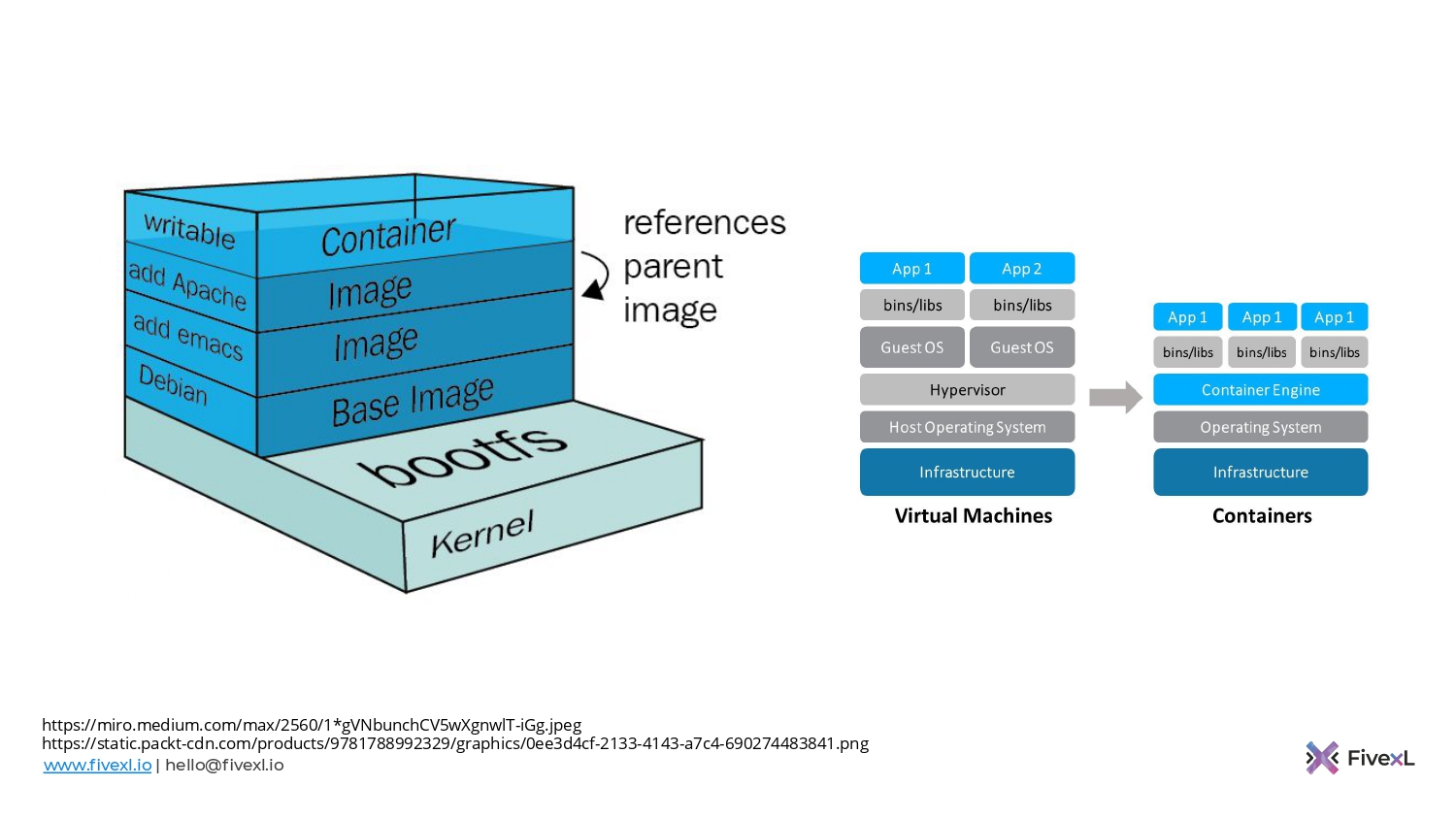
Плюс те команды, которые доставляют изменения в контейнеры, тоже получают определенные бенефиты от immutable infrastructure, потому что сам по себе образ контейнера неизменный. Мы его собрали один раз, и он таким остается. Единственный вариант его изменить – это собрать новый образ.
Контейнер, который вы запускаете, он mutable. В нем будут какие-то изменения, в нем может накопиться конфигурационный дрифт. Но когда вы удаляете контейнер, то вы обнуляете весь конфигурационный дрифт, который в нем накопился. И это здорово, потому что конфигурационный дрифт не попадает на хостовую машину, на которой вы эти контейнеры запускаете. Соответственно, машина сама остается чище.

И тут я обычно начинаю рассказывать о том, что есть такой замечательный инструмент, как Packer. Я мог бы рассказать, что им можно готовить образы виртуальных машин, запускать их on premise на VMWare и раскатывать через PXE или сразу же AMI готовить на Amazon, но не буду.

Давайте пойдем по другому пути. И подумаем, как мы можем скомбинировать неизменные сервера и контейнеры, а также, как мы можем получить максимум бенефитов от этих двух подходов.

Мы можем воспользоваться системами, которые построены для того, чтобы запускать контейнеры.

Давайте рассмотрим AWS BottleRocket. Это open source операционная система, разработанная Amazon. Вышла в том году. В этом году вышел релиз 1.0, т.е. они таким образом пытаются просигнализировать, что она production ready.
Давайте рассмотрим аспекты этой системы и посмотрим, чем она отличается от типичной Linux-системы.
- Вы конфигурируете ContainerOS, в частности BottleRocket через API, т.е. вам не надо писать ни shell-скриптов, ни ходить по SSH. У вас есть API, который вы можете дергать, передать по настройке, и операционная система сама себя настроит. Либо вы можете передать toml-файл на старте как cloud-init, и операционная система себя сама настроит.
- Операционная система обновляет себя через partition flips. У вас всегда есть 2 partitions. Один активный, другой пассивный. Операционная система обновляет пассивный, пытается переключиться туда. Если это получается, переключение происходит. Потом тот, что был активным, становится пассивным. Он обновляется. При этом partitions – immutable. Они приезжают как immutable-образа. Это то, что мы хотим.
- Также операционная система может обновлять сама себя. Там есть такая возможность.
- Security в самом центре разработки системы.
- И вот эти все обвязки, которые оркестрируют поведение операционной системы, которую мы только что обсудили, написаны на Rust. Rust – это buffer safe язык. И как в большинство security проблемы проходят из-за buffer underrun.

https://github.com/bottlerocket-os/bottlerocket
Что туда входит? У меня слева здесь есть полный список того, что туда входит. Это Kernel, Glibc, Buildroot. Нам нужен Toolchain, загрузчик, Unit-система, сетевая система, container runtime (в нашем случае containerd используется). По умолчанию BottleRocket поставляется в Kubernetes и ECS. Соответственно, если у вас Kubernetes, то у вас будет стоять Kubelet, а также aws-iam-authenticator. А если у вас ECS, то у вас будет стоять ecs-агент.
Справа описываются свойства безопасности. Как мы уже говорили, автоматические апдейты безопасности, Immutable rootfs система, Stateless tmpfs for /etc. Нет никаких интерпретаторов. Все исполняемые файлы, которые используются, уже закалены, т.е. hardening и SELinux включен. Т.е. очень много работы сделано за нас.

И вы можете сказать: «Это только в облаках. Как же мне быть on-prem?». Буквально на прошлой неделе вышел Amazon ECS Anywhere, который был предварительно объявлен в декабре. Теперь вы можете запускать ESC на on-prem серверах и использовать ECS-консоль. И это работает. Вы можете также устанавливать BottleRocket у себя, и это будет работать с ECS.
Я хотел сделать эксперимент и запустить локально на ноутбуке BottleRocket и подцепить его к ECS, но не успел, поэтому эта информация не точная. Но теоретически это должно работать.
Можем ли мы сделать еще лучше?

Можем. Есть достаточно много хайпа вокруг MicroVM, unikernels. Нам уже их 10 лет обещают. И говорят, что будет очень здорово. Если вы не знакомы с концептом, unikernels или MicroVM – это специальные операционные системы, которые бегут в один процесс. И там ядро, и все исполняемые файлы вместе с вашей программой компилируются в один бинарник и запускаются. Т.е. там очень похожая ситуация с ContainerOS. Там нет никаких интерпретаторов, никаких shells. Но там нет и контейнеров как таковых. Там только ваше приложение и вся та обвязка, и минимальное ядро, которое нужно, чтобы его запустить.

Но мне всегда казалось, что люди, скорее всего, будут использовать on-prem в своих дата-центрах, потому что там у них есть доступ к Hypervisor. Потому что unikernels зачастую запускают поверх Hypervisor. Как я это буду делать в Amazon? Amazon в систему своей виртуализации не пустит.

https://nanovms.gitbook.io/ops/aws
Но буквально месяц или полтора назад общались с разработчиками инструмента, который называется Ops. И ребята, которые его разрабатывают, придумали, как unikernels запускать почти что везде. Можно локально запускать, можно запускать через KVM, можно запускать на Amazon.
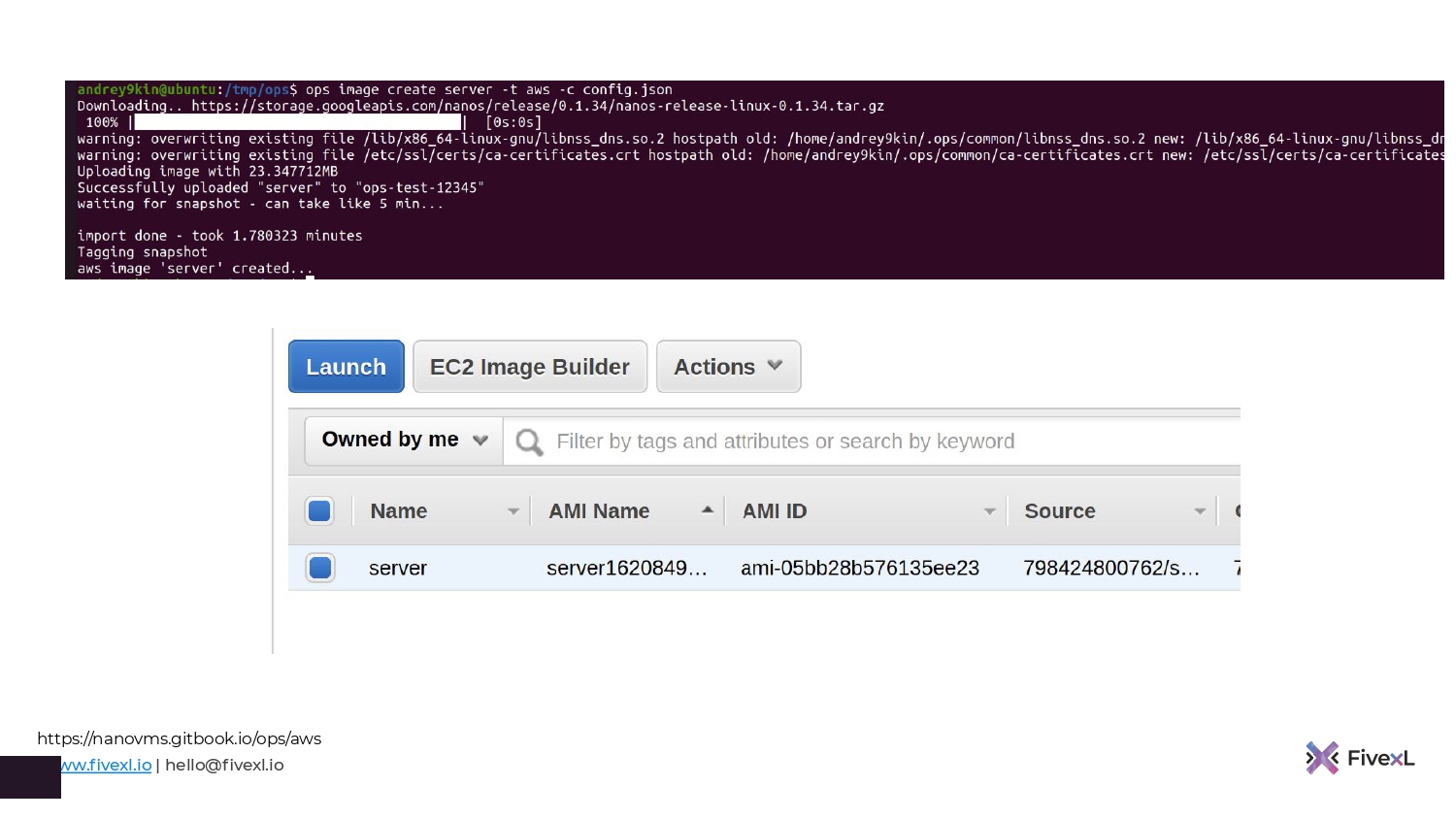
Вот мой персональный пример. Т. е. я говорю: «Ops image create server». Go программа уже скомпилирована. Я говорю: «Тип – Amazon». И потом я указываю config Json, в котором просто говорю через какой S3 Bucket загрузить мой unikernels на Amazon.
Что происходит? Когда эта команда выполняется, они берут мой бинарник, закатывают это вместе в один бинарник со своим unikernel. И у меня появляется в консоли AMI. Они придумали такой подход. Это можно запустить как AMI. И это очень просто.

Я считаю, что это очень классно, потому что это дает нам все те же примитивы, которые мы знаем. Auto scaling groups уже лет 10 в Amazon существуют. Это хорошо отработанный механизм. Мы запускаем приложение напрямую с помощью auto scaling group. Нам не надо заниматься менеджментом виртуальной машины. Нам не надо ставить туда обновления, не надо заморачиваться с контейнерами, не надо заморачиваться с оркестратором. Т. е. вот эти все уровни абстракции мы срезаем. И сама система становится очень простой. У нас есть auto scaling groups, которые напрямую запускают наше приложение, в которые бегут unikernels.
Понятно, что у unikernels есть свои ограничения. Не все можно запустить в unikernels в силу того, что это только один процесс. Если ваше приложение скейлится за счет мультипроцессинга, т. е. форкаются дополнительные процессы, то оно так не заработает. Но multithreading работает отлично. И у вас нет никакого конфигурационного дрифта. Это все immutable. И у нас получается динамическая immutable система, которая может полностью масштабироваться, а также может залечивать повреждения. Если какая из этих микровиртуальных машин вылетает, нам auto scaling group поднимет новую.
Кроме того, потребление ресурсов намного меньше. Когда мы запускаем большую виртуалку, то там много дополнительных процессов, которые едят ресурсы. А зачастую Go-приложения мы можем запускать на tier nano. И если вы используете споты, то будет интересно посмотреть, как будет цена на споты меняться, когда люди начнут все больше и больше использовать unikernels. И мне кажется, что это выстрелит.
Но сейчас то, что я говорю, это чистой воды спекуляция. 10 лет назад, когда я читал спецификации по Docker, это меняло всю игру. И когда читал первые материалы по Docker, то думал, что это вау. Люди вокруг Docker ничего не изобрели, они просто взяли контейнер и построили tooling вокруг него, который позволял обычным людям, которые ничего не понимают в linux-контейнерах, ими пользоваться.
И по ощущениям сейчас происходит то же самое с таким инструментом, как Ops, например. Он делает tooling, который позволяет unikernels использовать обычным девелоперам, которые, может быть, не понимают Linux Kernel настолько хорошо, насколько требовалось лет 5 назад, чтобы работать с unikernels. И, возможно, мы стоим на пороге следующей эволюции. Может быть, выстрелит, может быть, нет. Посмотрим.

Unikernels – это штука крутая, но мы все запускаем Kubernetes. Давайте поговорим немножко про него.

Возьмем те концепции, про которые мы говорили, т. е. концепции синхронизации конфигурации, immutable конфигурации и применим к Kubernetes.
Если верить Kelsey Hightower, то он говорит, что Kubernetes – это новый user space, т. е. это новый Linux, по сути. Раньше мы ставили пакеты, а теперь мы ставим контейнеры.
Если мы раньше ставили пакеты с помощью инструмента синхронизации конфигурации и эволюционировали в immutable infrastructure, то у меня складывается впечатление, что с Kubernetes мы сделали шаг назад. Потому что сейчас GitOps – это самый распространенный способ доставки приложений в Kubernetes. GitOps – это, по сути, синхронизация конфигурации. У нас есть репозиторий, из которого мы синхронизируем конфигурацию в Kubernetes.
Конечно, это не полностью безнадежная ситуация, как это было с Linux, потому что у Kubernetes есть reconstruction loop и какие-то вещи он сам может восстанавливать, т. е. если где-то что-то отклонится, он сам сможет вернуть. Если у вас подов меньше стало, он их постарается поднять. Но мы все равно не защищены от того, что люди изменяют и добавляют руками, если только эти элементы не синхронизируются GitOps. Но за пределами GitOps все еще есть возможность накопления конфигурационного дрифта.

Люди пытаются GitOps пушить и дальше. Есть такие инструменты, как Crossplane, когда вы с помощью GitOps-подхода, с помощью Kubernetes reconstruction loop, с помощью CRD, например, создаете S3 Bucket и другие ресурсы Kubernetes.
В чем тут проблема? В Kubernetes вы зачастую не платите за API-вызовы, но в Amazon вы платите. И можете накапливать cost, о которой вы сразу же не думаете.
У нас есть разрушенный круг обратной связи к разработчикам, потому что в традиционных pipeline разработчик может увидеть, где находится изменение. Я основываюсь на том, что в традиционном pipeline мы запускаем pipeline на каждое изменение. И каждое изменение накатывается до production.
В случае GitOps мы сделали комит в GitOps-репозитории, потом оттуда это изменение каким-то образом в какой-то момент синхронизируется в Kubernetes. И разработчику может быть не так просто отследить то, что происходит.

Как я уже говорил, конфигурационный дрифт и branching. Branching становится еще большей проблемой в GitOps-репозиториях. И, например, Thoughtworks в Technology Radar говорят, что, возможно, стоит немножко вам подумать насчет GitOps. Они говорят, что в этом подходе они ничего плохого не видят, но есть ситуации, когда люди начинают делать долгосрочные branches и потом у них возникают конфликты между branches, а это может плохо закончиться. Имейте это в виду и старайтесь избегать таких ситуаций 
Как я говорил до этого, я пробовал сделать проекцию того пути, который мы прошли с виртуалками на Kubernetes. Мы начали с синхронизации конфигурации, пришли к immutable infrastructure и, возможно, нам надо будет придумать, как мы будем делать immutable конфигурацию, если мы все еще будем делать Kubernetes через 5 лет. Скорее всего, будем, но многие сейчас уже начинают просыпаться и понимать, что Kubernetes – это достаточно глубокое болото, в котором можно застрять, потому что настраивать там надо много.
И если у нас будет возможность как код делать immutable Kubernetes-кластера и пересоздавать их 
Возможно, лучшее, что на сегодня есть и то, что мы рекомендуем заказчикам — это deploy в контейнерах. А также использовать Fargate, если есть деньги. Fargate – это контейнеры в вакууме на Amazon. Не нужно думать о хостах.
Но у Fargate есть ряд ограничений. И цена – одна из них. Если какое-то из этих ограничений не подходит, то можно запустить Container Instances и использовать оперативную систему как BottleRocket. Есть и другие. Есть Red Hat Atomic, например. Т.е. есть такие системы, которые можно попробовать. Позвоните своему вендору и спросите: «Не делает ли он такую?», если вам не подходит BottleRocket по какой-то причине. Я даже видел, что его некоторые энтузиасты на Azure запускают.
И таким образом мы получаем полностью динамическую систему, которая достаточно устойчива, которая реагирует на изменения в запросах, на изменения в трафике. Если что-то отваливается, то поднимается новая нагрузка. И мы можем такое делать, потому что все наши нагрузки доставляются как immutable, т. е. у нас immutable сервера и контейнеры.

Давайте подведем итог.
Мы говорили о том, что есть типичные нужды бизнеса, т. е. это:
- Необходимость в масштабировании.
- Необходимость в быстрой доставке приложений.
- Необходимость менеджмента больших систем, которое может быть достаточно затруднено из-за размера этих систем и их хрупкости.
- Плюс есть постоянные ситуации с безопасностью и compliance.
Я считаю, что использование динамических и нехрупких систем позволит нам добиться того, чего хочет бизнес и таким образом разгрузить нас самих. Например, сейчас середина дня и мне не надо сидеть на пейджере. Точнее пейджер есть, но он никогда не звонит, потому что все работает, и система может с 99% проблем справиться сама. И я могу спокойно тратить это время либо на то, чтобы поговорить с вами, либо делать продуктивную работу для бизнеса, а не бегать и ставить патчи по хостам.

В инфраструктуре как код есть определенные вызовы, с которыми она призвана бороться. Это:
- Конфигурационный дрифт,
- Сервера-снежинки,
- Хрупкая инфраструктура,
- Страх автоматизации.
С помощью инфраструктуры как код мы со всеми этими вызовами боремся.
Инфраструктура как код позволяет менять нам нашу инфраструктуру, делать это легко, убирать драмы из изменений в инфраструктуре, чтобы мы могли это делать как постоянный процесс, чтобы наши системы постоянно развивались и не были статическими, чтобы пользователи могли легко получать те ресурсы, которые им нужны. А также чтобы мы могли улучшать и улучшать эту систему и не было проблем с имплементаций этих изменений. Если легко изменить систему, то легко доставлять новые улучшения туда.

И люди, которые начинали делать инфраструктуру как код через синхронизацию конфигурации, сделали хороший первый шаг. Это определенно лучше, чем делать это руками.
Но там все равно оставалась возможность конфигурационного дрифта. Масштабирование было медленным, потому что нам приходилось накатывать изменения после того, как новый сервер поднимется. Соответственно, надо было подождать какое-то время. Может быть, 5-10 минут. Но не факт, что он поднимется сам полностью.
Все еще очень часто применяется в железных серверах. Как оказалось, используется в Kubernetes. И может быть необходимым злом для того, чтобы сделать следующий шаг, которым, как я считаю, является неизменная инфраструктура.

Она зачастую требует больше сил, чтобы заимплементировать. Придется изучить какие-то новые парадигмы, новые инструменты. Но это здорово для security и это позволяет нам выстраивать легко повторяемые системы, которые устойчивы к изменениям, негативным воздействиям. И если негативные воздействия настолько сильны, что вызывают выход из строя узлов, то эти системы могут восстанавливаться сами.
Таким образом это освобождает нас от работы, которую можем отдать роботам и позволяет нам сфокусироваться на более креативной работе, которая помогает бизнесу развиваться и идти вперед.

Завтра может быть у нас будет immutable Kubernetes? Может быть, выстрелят Unikernels/MicroVM? Или, может быть, Serverless захватит все? А, может быть, будет комбинация из этих трех или что-то такое, что здесь не перечислено? Я не знаю, что будет дальше. Это сложно предугадать. Но если мы используем историческую перспективу, как мы двигались от синхронизации конфигурации к immutable infrastructure, то, возможно, мы сможем сделать более взвешенные выборы инструментов, которые прослужат нам дольше и приведут нас в правильном направлении.

На этом у меня все. Было здорово с вами со всеми пообщаться виртуально. Я готов ответить на вопросы.
Вопросы
Андрей, спасибо за доклад! Мне очень понравился твой доклад про Ansible, который на самом деле был не про Ansible.
Одно дело, когда мы просто разворачиваем серверы с копиями какой-нибудь статики на React. Мы можем их в auto scaling group запихнуть и множить. Если у нас приложение чуть более сложное, если у него есть какой-то state, и будь то твои unikernels или Kubernetes, то все равно у unikernels есть какая-то оркестрации, у Kubernetes есть etcd. Мы можем даже уничтожать старые кластера Kubernetes и создавать новые. Но мы никуда не уходим от проблемы распределенных систем. У нас конфигурация одного сервера зависит от других серверов. Допустим, серверы etcd должны знать друг о друге, чтобы сформировать кластер. Распределенная система фундаментально не надежна. Как тогда строить immutable infrastructure? Что делать с мастер-данными, чтобы это все работало, когда мы можем всегда какую-то связь потерять, и какой-то сервер будет иметь сетевую недоступность?
Я слышу 2 вопроса. Я слышу, что есть о state, т. е. куда девается state, да? И есть вопрос о том, как серверам находить себя и других, если они работают в кластере. Поднялся, например, новый kub node, как ему найти, где сервера находится, куда ему заджониться, т. е. в какой кластер? И, возможно, чтобы заджониться, ему нужен секрет. Приложения могут состоять из нескольких сервисов, у нас может быть микросервисная архитектура, и приложение хочет коммуницировать с другими. И ему нужно знать, как это решается.
Если помните, то в самом начале презентации я говорил, что такие динамичные системы строятся из нескольких компонентов. Immutable infrastructure является одним из них, но она не отвечает на все вопросы. У нас также есть проблема с Service discovery. Это, насколько я понимаю, то, что ты имел в виду. Есть проблема с доставкой секретов. Мы зачастую не можем или не хотим запекать секреты либо в Docker Image, либо в виртуальной машине. И также есть проблема с безопасностью.
Мне один товарищ говорит: «Мне все нравится, что ты рассказываешь, но у нас везде security, везде firewall и все построено на IP-адресах». Эти все проблемы сплетаются друг с другом.
Если мы возьмем историческую перспективу, то можно посмотреть, что делала, например, компания HashiCorp. Я общался с основателями и спрашивал: «Ребята, почему вы делаете open source и вы успешны? Но есть много компаний, которые пытались сделать open source, но провались в этой затеи». И эти ребята сказали: «Мы понимаем, что наши клиенты – это 500 самых больших компаний в мире. Мы работаем на них». Соответственно, они сразу ориентировались на людей, которые работают в on-prem. Все эти вызовы они отлично понимали, потому что в облаках многие из этих проблем уже решены. Есть легкие решения.
Что они сделали? Они выпустили свой продукт Consul, который был как раз для того, чтобы делать Service discovery. В Kubernetes эти проблемы решаются своими способами. В Kubernetes у вас может быть Service Mesh, который позволяет находить другие сервисы и как-то через DNS это решать. В Amazon есть свои способы решения, например, через cloud map.
Но Consul был одним из первых инструментов, который решал проблему Service discovery. И он продолжал развиваться и решать дополнительные проблемы.
И дальше они добавили распределение конфигурации через него. Т.е. сервис поднимается, на нем Consul-агент. Consul-агент добавляется в кластер. Есть способ автоматического подсоединения, как они находили. Там есть механизмы Discovery серверов. Он спрашивал для себя необходимую конфигурацию и понеслось. И через Consul он мог найти всех тех, с кем нужно было общаться.
Следующим шагом они добавили туда Service Mesh для безопасной связи и для распределенного общения. Т.е. решение есть. И мой доклад просто на них не фокусировался.
Мой подход с базами данных – это покупать, пока это возможно. В Amazon есть ребята, которые занимаются базами данных. Они выстраивают хорошие и сильные решения. И пока я могу, пока это работает, пока мне не нужно делать микроскопического тюнинга, что решение Amazon не работает, я буду стараться жить как можно дольше на таком решении. Мы, как специалисты по облачной инженерии, решаем проблемы бизнеса, выстраивая ее из кусочков. Т.е. какие-то кусочки мне даст cloud provider, какие-то кусочки напишет программист. А мы всю эту систему стараемся сложить и сделать так, чтобы эта система соответствовала тем бизнес требованиям, которые решают бизнес-проблемы. И зачастую, если есть возможность купить вместо того, чтобы строить это самому, это более выгодно. Если денег у бизнеса еще мало, то там начинаются приседания с базами данными в docker-контейнере и другими решениями. Это все очень зависит от контекста.
Надеюсь, что я ответил на вопрос.
Нет, но есть над чем задуматься.
Хочу сказать большое спасибо, потому что эта презентация отозвалась в моем сердце! Я как раз специализируюсь на SRE и на Kubernetes. Вы правильно сказали о процессе развития компании. Единственное, не соглашусь с Kubernetes, потому что уровень абстракции постоянно растет, и дальше мы будем в OpenShift. А после OpenShift, где-то года через 3 мы уйдем в MicroOS. У меня вопросы следующие. Когда мы перейдем в MicroOS, то тут есть две очень жесткие проблемы. Первая проблема – это безопасность. Но это не та безопасность, про которую вы говорили с IP-адресами, а безопасность самого ядра, потому что у нас голое ядро и приложение. И второе – это удобство.
Как я и сказал, сейчас идет хайп на повышение уровня абстракции. И мы очень много ресурсов тратим на эту абстракцию. Поэтому мы потом пойдем к MicroOS. И два вопроса: это безопасность MicroOS и удобство их управлением, чтобы было так же удобно, как с тем же Kubernetes.
Я не знаю, как на эти вопросы коротко ответить. Это очень развернутые вопросы.
Комментариев нет:
Отправить комментарий