
Всем привет, меня зовут Илья, я работаю в компании DINS на должности инженера отдела мониторинга. В этой статье расскажу о нашей боли при работе с ElasticSearch. Мне не удалось найти решение этой проблемы где-либо ещё, поэтому, думаю, этот туториал будет интересен всем, кто использует ElasticSearch.
Кросс-кластерный поиск призван обеспечить более стабильную доставку логов за счёт того, что все датаноды находятся в той же локации. Также он призван обеспечить стабильный поиск. Что бы ни случилось с кластером в локациях, остальные кластеры не должны страдать. Но на деле всё оказалось не так.
Cross Cluster Search: о чём это?
Немного о ElasticSearch, кто вкурсе могут смело проматывать этот абзац. Эта функция должна улучшать стабильность всей системы поиска. Для примера, у нас есть сервера в разных локациях, которые перерабатывают большую кипу данных. И есть один небольшой сервер, о котором знают пользователи и к которому они делают запросы. Эти запросы перенаправляются уже на все кластера и забирают оттуда необходимые данные.
Например:
у нас есть 3 проекта в Америке, Китае и Европе. В каждой локации собирается очень много логов в секунду, поэтому переправлять их в какое-то одно место не представляется возможным, у нас будут задержки и система будет деградировать.
В качестве решения мы создаём в каждой локации свой небольшой кластер.
Получается в Америке 3 мастера и 3 датаноды, в Китае только 1 нода, которая выполняет все роли, а в Европе 4 датаноды при этом 3 из них выполняют ещё роль мастера.
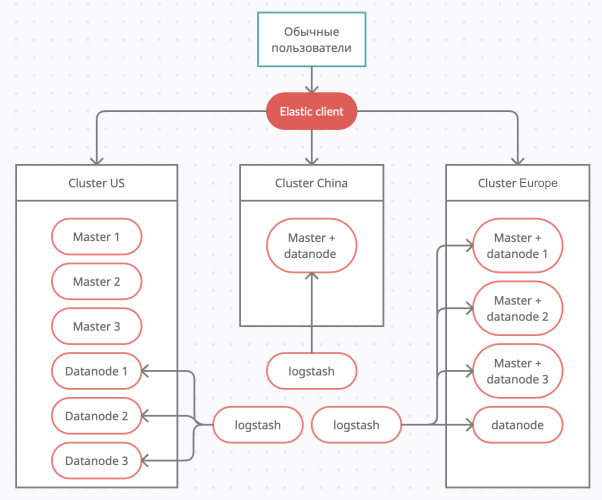
Далее мы будем разбирать пример на основе этого набора кластеров.
Но так как все наши менеджеры находятся в России, то размещаем один клиентский сервер ElasticSearch в Москве, для пользователей с западной части и в Новосибирске, для пользователей с восточной части страны. Такие сервера решают сразу несколько проблем:
- Трафик будет проходить через ближайший сервер, тем самым ускоряя время получения ответа и пользователю не надо задумываться в каком именно кластере лежат его данные.
- ElasticSearch клиент может сохранять результаты запросов, тем самым ещё больше ускорять предоставление данных.
Надеюсь мне удалось объяснить, если нет, то за подробностями сюда.
Разработчики рекомендуют
Самая простая реализация кросс-кластерного поиска — это Sniff. Настройка очень проста, в /_cluster/settings заливаем json с указанием нескольких серверов кластера, после ElasticSearch сам опрашивает кластер по ссылке ‘/_nodes/_all/http’, находит ноды с данными и создает к ним сокет соединения. Всё сразу работает из коробки, что очень удивительно.
Пример загрузки json в ElasticSearch:
curl -XPUT "http://elastic_client:9200/_cluster/settings" -H"Content-Type: application/json" -d '
{
"persistent" : {
"cluster" : {
"remote" : {
"cluster_US" : {
"mode" : "sniff",
"seeds": [
"1.1.1.4:9300",
"1.1.1.5:9300",
"1.1.1.6:9300"
]
},
"cluster_CHINA" : {
"mode" : "sniff",
"seeds": [
"1.1.2.1:9300"
]
},
"cluster_EUROPE" : {
"mode" : "sniff",
"seeds": [
"1.1.3.1:9300",
"1.1.3.2:9300",
"1.1.3.3:9300"
]
}
}
}
}
}’Немного нашей боли
Жизнь боль, не забывай страдать!
Всё бы хорошо, только при такой настройке, стоило серверу перестать отвечать (проблемы с сетью, повышенная нагрузка etc.), Kibana выдавала нам ошибку timeout. Ведь для отображения логов нужна информация со всех кластеров.
Не забываем, что истина в вине доке!
Идём в документацию по настройке sniff в кросс-кластерном поиске и видим:
skip_unavailable
Whether the remote cluster is skipped in case it is searched through a cross-cluster search request but none of its nodes are available.
И казалось бы, вот оно чудо! Разработчики-то умные, не то, что я, и… И я поспешил!
Да, эта функция действительно работает только в том случае, если упал только один сервер из всего кластера. Судя по логике разработчиков, клиент в случае возникновения проблем должен переключится на соседний сервер в кластере. Они не учли, что может быть недоступен весь кластер.
В этом случае при любом поиске в который включен проблемный кластер мы получаем ошибку timeout в не зависимости от результатов поиска в других кластерах.
Простое — не всегда лучшее!
К сожалению, решить проблемы падения кластеров со sniff силами Elasticsearch не удалось. Стали смотреть в сторону proxy, будем сами решать, какая нода лежит, а какая работает и куда отправлять запросы.
В результате у нас получился примерно следующий конфиг для Elastic:
curl -XPUT "http://elastic_client:9200/_cluster/settings" -H"Content-Type: application/json" -d '
{
"persistent" : {
"cluster" : {
"remote" : {
"cluster_US" : {
"mode" : "proxy",
"proxy_address" : "127.0.0.1:9001"
},
"cluster_CHINA" : {
"mode" : "proxy",
"proxy_address" : "127.0.0.1:9002"
},
"cluster_EUROPE" : {
"mode" : "proxy",
"proxy_address" : "127.0.0.1:9003"
}
}
}
}
}’Также локально ставим Haproxy с конфигом:
frontend cluster_US_input
bind *:9001
default_backend cluster_US
backend cluster_US
balance roundrobin
server node1 1.1.1.1:9300 check
server node2 1.1.1.2:9300 check
server node3 1.1.1.3:9300 check
server backup 127.0.0.1:9300 check backup
frontend cluster_CHINA_input
bind *:9002
default_backend cluster_CHINA
backend cluster_CHINA
balance roundrobin
server node1 2.2.2.1:9300 check
server backup 127.0.0.1:9300 check backup
frontend cluster_EUROPE_input
bind *:9003
default_backend cluster_EUROPE
backend cluster_EUROPE
balance roundrobin
server node1 3.3.3.1:9300 check
server node2 3.3.3.2:9300 check
server node3 3.3.3.3:9300 check
server backup 127.0.0.1:9300 check backup
Теперь Haproxy сам проверяет доступность ElasticSearch и при возникновении проблем не отправляет подключения на сломанную ноду. В качестве резервного сервера мы используем локальный ElasticSearch, с которого отправляется кросс-кластерный поиск. Но проблема осталась, потому что сокет соединения — это долгие соединения, они не сразу обрываются после того, как сервер стал недоступен. В результате мы получили тот же timeout, только теперь с добавлением прокси.
Немного покумекав с товарищами, решил принудительно разрывать соединения с сервером, который перестал отвечать.
Также стоит заметить, что долгие соединения нехорошо балансировать с помощью roundrobin, лучше отправлять новые подключения на сервера с наименьшим количеством соединений, поэтому был выбран leastconn.
Закопавшись в документацию, я родил такой конфиг:
frontend cluster_US_input
bind *:9001
default_backend cluster_US
backend cluster_US
balance leastconn
server node1 1.1.1.1:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server node2 1.1.1.2:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server node3 1.1.1.3:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server backup 127.0.0.1:9300 check backup on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
frontend cluster_CHINA_input
bind *:9002
default_backend cluster_CHINA
backend cluster_CHINA
balance leastconn
server node1 2.2.2.1:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server backup 127.0.0.1:9300 check backup on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
frontend cluster_EUROPE_input
bind *:9003
default_backend cluster_EUROPE
backend cluster_EUROPE
balance leastconn
server node1 3.3.3.1:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server node2 3.3.3.2:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server node3 3.3.3.3:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server backup 127.0.0.1:9300 check backup on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessionsСильно внимательные наверное заметили, что для бэкапного сервера также добавлен параметр «on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions», казалось бы, зачем это?
Это на случай горизонтального расширения, если захочется использоваться не один, а 2 или больше бэкапных серверов. В Haproxy они работают по очереди, если не указана опция «allbackups».
А Elastic не так легко обмануть
В итоге у нас получилось нечто хорошее.
- При падении ноды haproxy быстро разрывает все соединения с ней и переключает на живые ноды.
- Если весь кластер вышел из строя, весь трафик переключается на локальный Elastic, который скажет, что такого индекса нет.
- При возобновлении работы какой либо из нод кластера все соединения к бэкапному серверу рвуться и кластер начинает работать.
Вроде всё хорошо, но возникла одна проблема: при первом подключении ElasticSearch запоминает, как называется кластер, и его параметры. Так как бэкапный сервер не входит в состав удалённого кластера, при переключении трафика на него возникает ошибка:
{
"error": {
"root_cause": [
{
"type": "illegal_state_exception",
"reason": "Unable to open any proxy connections to remote cluster [cluster_CHINA]"
}
],
"type": "illegal_state_exception",
"reason": "Unable to open any proxy connections to remote cluster [cluster_CHINA]"
},
"status": 500
}При этом ошибка совсем не гуглилась (сейчас правда гуглится мой пост на форуме ElasticSearch).
Пришлось думать, как обмануть ElasticSearch, чтобы он решил, что всё ок.
Оказывается, в режиме proxy параметр «skip_unavailable» всё же может пропускать целые кластера. В итоге у нас получился вот такой json:
curl -XPUT "http://elastic_client:9200/_cluster/settings" -H"Content-Type: application/json" -d '
{
"persistent" : {
"cluster" : {
"remote" : {
"cluster_US" : {
"mode" : "proxy",
"skip_unavailable" : "true",
"proxy_address" : "127.0.0.1:9001"
},
"cluster_CHINA" : {
"mode" : "proxy",
"skip_unavailable" : "true",
"proxy_address" : "127.0.0.1:9002"
},
"cluster_EUROPE" : {
"mode" : "proxy",
"skip_unavailable" : "true",
"proxy_address" : "127.0.0.1:9003"
}
}
}
}
}’Прям совсем ленивые могут выполнить настройки с помощью Kibana пункт «Remote cluster».
Итак, нам удалось обмануть довольно сложный продукт ElasticSearch и сказать, что все удалённые кластера работают, вне зависимости от их реального статуса.
А может, я изобрел очередной велосипед, и уже есть лучший вариант решения этой проблемы? Буду рад предложениям. Встречались ли у вас подобные проблемы и как вы их решали?
Для ленивых присутствуют конечные конфиги:
json:
curl -XPUT "http://elastic_client:9200/_cluster/settings" -H"Content-Type: application/json" -d '
{
"persistent" : {
"cluster" : {
"remote" : {
"cluster_US" : {
"mode" : "proxy",
"skip_unavailable" : "true",
"proxy_address" : "127.0.0.1:9001"
},
"cluster_CHINA" : {
"mode" : "proxy",
"skip_unavailable" : "true",
"proxy_address" : "127.0.0.1:9002"
},
"cluster_EUROPE" : {
"mode" : "proxy",
"skip_unavailable" : "true",
"proxy_address" : "127.0.0.1:9003"
}
}
}
}
}’haproxy:
frontend cluster_US_input
bind *:9001
default_backend cluster_US
backend cluster_US
balance leastconn
server node1 1.1.1.1:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server node2 1.1.1.2:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server node3 1.1.1.3:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server backup 127.0.0.1:9300 check backup on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
frontend cluster_CHINA_input
bind *:9002
default_backend cluster_CHINA
backend cluster_CHINA
balance leastconn
server node1 2.2.2.1:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server backup 127.0.0.1:9300 check backup on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
frontend cluster_EUROPE_input
bind *:9003
default_backend cluster_EUROPE
backend cluster_EUROPE
balance leastconn
server node1 3.3.3.1:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server node2 3.3.3.2:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server node3 3.3.3.3:9300 check on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
server backup 127.0.0.1:9300 check backup on-marked-up shutdown-backup-sessions on-marked-down shutdown-sessions
Комментариев нет:
Отправить комментарий