
Ежедневно люди загружают на Facebook сотни миллионов видеороликов. Чтобы каждое доставляемое видео было наилучшего качества — с максимальным разрешением и минимальной буферизацией — нужно оптимизировать не только то, когда и как видеокодеки сжимают и распаковывают видео для просмотра, но и то, какие кодеки используются для тех или иных видео. Огромный объем видеоконтента на Facebook также означает, что нужно найти эффективные способы его обработки, не требующие больших затрат вычислительной мощности и ресурсов.
Для этого мы используем различные кодеки, а также адаптивный битрейт (ABR), который улучшает качество просмотра и уменьшает буферизацию — он выбирает наилучшее качество в зависимости от пропускной способности сети зрителя. Но хотя более современные кодеки (например, VP9) обеспечивают лучшую производительность сжатия по сравнению со старыми кодеками вроде H264, они также задействуют больше вычислительной мощности. С вычислительной точки зрения применение самых современных кодеков к каждому видео, загружаемому в Facebook, было бы непомерно неэффективным. А это значит, что нужен способ приоритизировать видеоролики, которые должны быть закодированы с использованием более современных кодеков.
Сегодня Facebook решает эту задачу, сочетая модель выгод и стоимости с моделью машинного обучения (ML) — это позволяет определять приоритетность продвинутого кодирования. Предсказывая, какие видео будут просматриваться чаще всего, и кодируя их в первую очередь, мы можем уменьшить буферизацию, улучшить общее качество изображения и позволить людям, которые ограничены своими интернет-тарифами, смотреть больше видео.
Но это не означает просто отдать приоритет контенту самых популярных авторов или тех, у кого больше всего друзей. Нужно учесть несколько факторов, чтобы обеспечить наилучшее качество видео для пользователей и в то же время гарантировать, что Facebook будут справедливо кодировать контент всех пользователей.
Как мы кодировали видео на Facebook
Традиционно, как только видео загружается на Facebook, запускается процесс для поддержки ABR и ролик быстро перекодируется в различные разрешения (360p, 480p, 720p, 1080p). Затем система кодирования видео пытается еще больше улучшить впечатления от просмотра, используя более продвинутые кодеки, например VP9, или более дорогие «рецепты» (термин, обозначающий тонкую настройку параметров транскодирования), например очень медленный профиль H264, для максимального сжатия видеофайла. У разных технологий транскодирования (использующих различные типы кодеков или параметры кодеков) есть трейдоффы между эффективностью сжатия, качеством изображения и требуемой вычислительной мощностью.
Нас давно занимал вопрос, как распределить порядок задач так, чтобы достичь максимально возможного результата для всех пользователей в целом. У Facebook есть специализированный вычислительный пул для кодирования и диспетчер. Он принимает запросы на выполнение задач кодирования, имеющих приоритет, и помещает их в очередь, где задачи с более высоким приоритетом обрабатываются в первую очередь. Соответственно, от системы кодирования видео требуется правильно назначить приоритет каждой задаче. Это делалось посредством списка простых, жестко закодированных правил. Задачам мог быть присвоен приоритет на основе факторов, например, является ли видео лицензионным музыкальным роликом, коммерческое ли оно, сколько друзей или подписчиков у владельца видео.
Но у такого подхода были и недостатки. С появлением новых видеокодеков увеличивалось количество правил — их нужно было поддерживать и настраивать. Поскольку у различных кодеков и рецептов разные требования к вычислительным ресурсам, качество изображения и трейдоффы, невозможно полностью оптимизировать опыт конечного пользователя с помощью грубого набора правил.
И, пожалуй, самое главное: модель потребления видео в Facebook чрезвычайно перекошена — у пользователей, загружающих видео на Facebook может быть большой разброс друзей или подписчиков. Сравните страницу Disney и блогера с 200 подписчиками. Если блогер и Disney загрузят видео одновременно, скорее всего, у видео Disney будет больше просмотров. Однако любое видео может стать вирусным, даже если у загрузившего его пользователя небольшая аудитория. Задача состоит в том, чтобы поддерживать всех создателей контента, а не только тысячников и миллионников, но в то же время учитывать, что наличие большой аудитории обычно означает больше просмотров и затраченного времени.
Введение в модель выгод и стоимости
Новая модель по-прежнему сначала быстро кодирует ABR-набором H264, гарантируя, что все загруженные видео будут закодированы в хорошем качестве как можно скорее. А вот то, как рассчитывается приоритет задач кодирования после публикации видео, изменилось.
Модель выгод и стоимости выросла из нескольких фундаментальных наблюдений:
-
Видео потребляет вычислительные ресурсы при кодировании только раз. Затем результат можно доставлять пользователям столько раз, сколько потребуется, не задействуя дополнительных вычислительных ресурсов.
-
Относительно небольшой процент (примерно одна треть) всех видео на Facebook генерирует большую часть общего времени просмотра.
-
У дата-центров Facebook ограниченное количество энергии для питания вычислительных ресурсов.
-
Можно сказать, что мы получаем максимальную отдачу (с точки зрения максимизации качества видео для каждого пользователя в рамках имеющихся ограничений по мощности), если применяем более требовательные к вычислительной мощности «рецепты» и продвинутые кодеки к тем видео, которые смотрят больше всего.
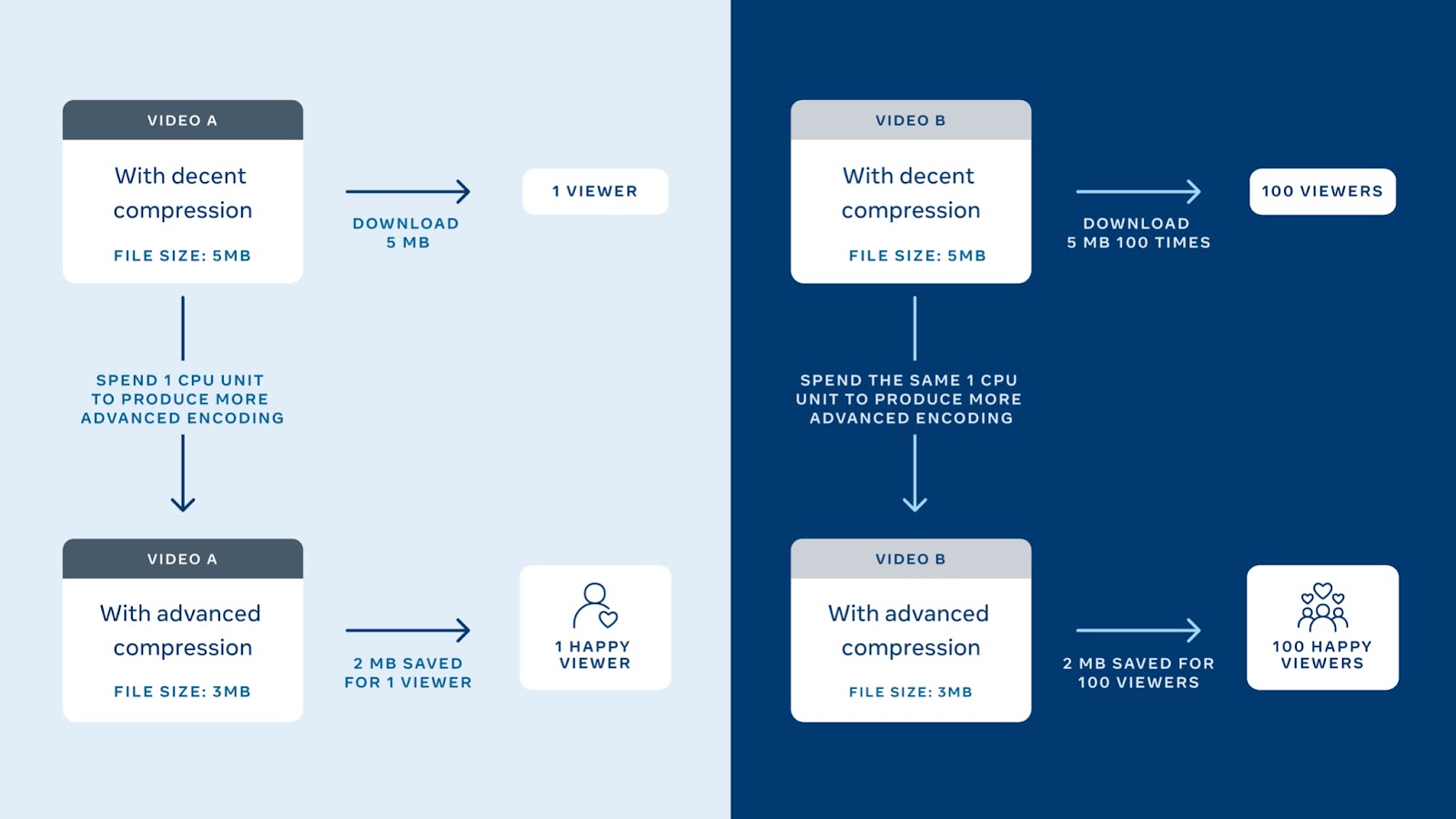
Исходя из этих наблюдений, мы вывели следующие определения для выгод, стоимости и приоритета:
-
Выгода (benefit) = (относительная эффективность сжатия семейства кодирования при фиксированном качестве) * (эффективное прогнозируемое время просмотра)
-
Стоимость (cost) = нормализованная стоимость вычисления недостающих кодировок в семействе
-
Приоритет = Выгода/Стоимость
Относительная эффективность сжатия семейства кодирования при фиксированном качестве: мы измеряем выгоду с точки зрения эффективности сжатия семейства кодирования. Под «семейством кодирования» понимается набор закодированных файлов, которые могут быть переданы вместе. Например, когда что-то закодировано в H264 в разрешениях 360p, 480p, 720p и 1080p, все это вместе составляет одно семейство. А когда те же самые 360p, 480p, 720p и 1080p закодированы VP9 — другое. Одной из проблем здесь является сравнение эффективности сжатия между различными семействами при одинаковом качестве картинки.
Чтобы все это понять, рассмотрим разработанную нами метрику «Минуты видео высокого качества на гигабайтный пакет данных» (MVHQ). MVHQ напрямую связывает эффективность сжатия с вопросом, который интересует пользователей интернета: сколько минут высококачественного видео можно транслировать, имея 1 ГБ данных?
Математически MVHQ можно выразить как:
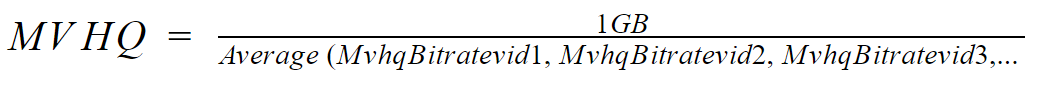
Допустим, у нас есть видео, где MVHQ при использовании быстрого пресета кодирования H264 составляет 153 минуты, при использовании медленного пресета кодирования H264 — 170 минут и 200 минут при использовании VP9. Это означает, что передача видео с использованием VP9 может увеличить время просмотра при использовании 1 ГБ данных на 47 минут (200-153) при высоком пороге качества изображения по сравнению с быстрым пресетом H264. При расчете преимущества конкретного видео мы используем быстрый H264 в качестве базового уровня. Мы присваиваем 1,0 для быстрого H264, 1,1 (170/153) для медленного H264 и 1,3 (200/153) для VP9.
Фактический MVHQ можно посчитать только после кодирования, однако нам нужно значение до этого, поэтому мы используем исторические данные, чтобы оценить MVHQ для каждого из семейств кодирования данного видео.
Эффективное прогнозируемое время просмотра: как будет описано ниже, у нас есть сложная модель ML, которая предсказывает, как долго видео будут смотреть в ближайшем будущем все его зрители. Получив прогнозируемое время просмотра, мы оцениваем, насколько эффективно семейство кодирования может быть применено к видео. Тут учитывается тот факт, что не у всех пользователей Facebook есть устройства, поддерживающие новые кодеки.
Например, около 20 процентов просмотров видео приходится на устройства, которые не могут воспроизводить видео, закодированное с помощью VP9. Тогда, если прогнозируемое время просмотра видео составляет 100 часов, то эффективное прогнозируемое время просмотра при использовании широко распространенного кодека H264 составляет 100 часов, а эффективное прогнозируемое время просмотра при использовании VP9 — 80 часов.
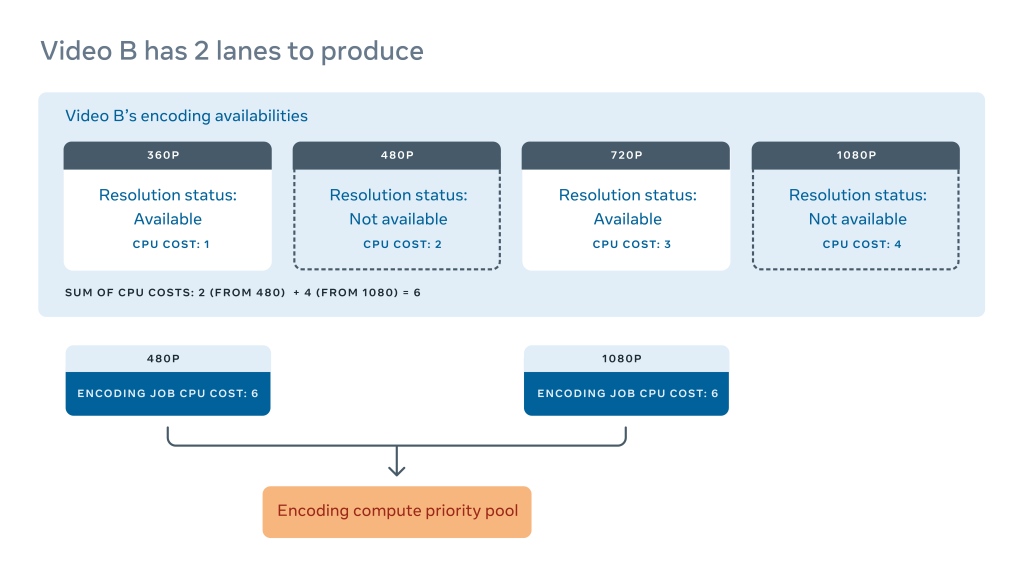
Нормализованная стоимость вычислений недостающих кодировок в семействе: это количество логических вычислительных циклов, необходимых для обеспечения доступности семейства кодирования. Семейство кодирования требует минимального набора разрешений, которые должны быть доступны, прежде чем мы сможем доставить видео. Например, для конкретного видео семейство VP9 может потребовать не менее четырех разрешений. Но некоторые процессы кодирования занимают больше времени, чем другие, поэтому не все разрешения для видео могут стать доступны одновременно.
Допустим, в видео A отсутствуют все четыре разрешения в семействе VP9. Мы можем суммировать предполагаемое использование CPU для всех четырех разрешений и назначить одинаковую нормализованную стоимость для всех четырех задач.
Если у нас нет только двух разрешений из четырех, как показано на рисунке Видео B, стоимость вычисления будет равна сумме затрат на создание оставшихся двух кодировок. Одна и та же стоимость применяется к обоим задачам. Приоритет — это выгода, деленная на стоимость, поэтому приоритет задачи становится более срочными по мере того, как становится доступным больше разрешений. Разрешения кодирования не приносят никакой пользы до тех пор, пока видео нельзя станет доставить пользователю, поэтому важно завершить задачу как можно быстрее. Например, одно видео со всеми разрешениями VP9 имеет больше ценности, чем 10 видео с неполными (и, следовательно, недоставляемыми) разрешениями VP9.

Предсказываем время просмотра с помощью ML
Когда уже принята новая модель выгод и стоимости для определения «как кодировать определенные видео», следующая часть пазла — определить, какие видеозаписи приоритизировать для кодирования. И тут мы стали использовать машинное обучение для прогнозирования, какие видео будут самыми просматриваемыми (и, следовательно, должны быть приоритизированы для продвинутого кодирования).
Наша модель смотрит на ряд факторов для предсказания, сколько времени воспроизведения придется на видео в течение следующего часа. Для этого она смотрит на число друзей или подписчиков загрузившего видео, на среднее время просмотра их предыдущих видеозаписей, а также на метаданные самого видео, включая его продолжительность, разрешение по вертикали и горизонтали, статус приватности, тип поста (прямой эфир, сториз и т.д.), как давно оно было загружено и насколько уже было популярно в прошлом.
Но при использовании всех этих данных для принятия решений сталкиваешься с несколькими неизбежными сложностями:
У времени просмотра высокая вариативность, и для него характерно распределение «длинного хвоста». Даже если прогнозировать только следующий час, время просмотра видеозаписи может разниться от нуля до более чем 50 000 часов — в зависимости от содержания, загрузившего и настроек приватности. Модель должна уметь определять не только «станет ли видео популярным», но и «насколько популярным».
Лучший индикатор времени воспроизведения в следующий час — это траектория времени воспроизведения в прошлом. Популярность видеозаписей в целом очень волатильна по своей природе. Разные видео от одного и того же человека порой очень сильно различаются по времени просмотра в зависимости от реакции сообщества на контент. После экспериментов с разными подходами мы обнаружили, что траектория уже известного времени воспроизведения лучше всего предсказывает будущее воспроизведение. Это приводит к двум техническим сложностям при проектировании архитектуры модели и балансировании данных для обучения:
-
У новых видеозаписей еще нет траектории просмотров. Чем дольше видео находится на Facebook, тем больше мы можем понять по его времени просмотра в прошлом. Это значит, что большинство возможностей прогнозирования неприменимы к новым видеозаписям. Мы хотим, чтобы наша модель показывала достаточно хорошие результаты при отсутствии данных: чем раньше система сможет идентифицировать видео, которое станет популярным, тем больше у нас возможностей доставить высококачественный контент.
-
В данных для обучения доминируют популярные видео. Но не факт, что паттерны самих популярных видеозаписей применимы ко всем остальным.
Свойства времени просмотра различаются в зависимости от типа видео. Сторис короче, и их суммарное время просмотра в среднем меньше, чем у других видео. Прямые эфиры получают основное время просмотров непосредственно во время стрима и в последующие несколько часов. А вот у video on demand может быть очень разный жизненный цикл, и они могут набрать время просмотров намного позже изначальной загрузки, если люди начинают ими делиться.
Улучшения по метрикам ML не обязательно напрямую соотносятся с улучшением продукта. Традиционные функции потерь, используемые в регрессионных моделях (вроде RMSE, MAPE и функции потерь Хьюбера) хороши для оптимизации офлайновых моделей. Но сокращение ошибок моделей не всегда напрямую означает, что продукт стал лучше (улучшился пользовательский опыт, больше времени просмотра покрыто или лучше утилизированы компьютерные ресурсы).
Создание ML-модели для кодирования видео
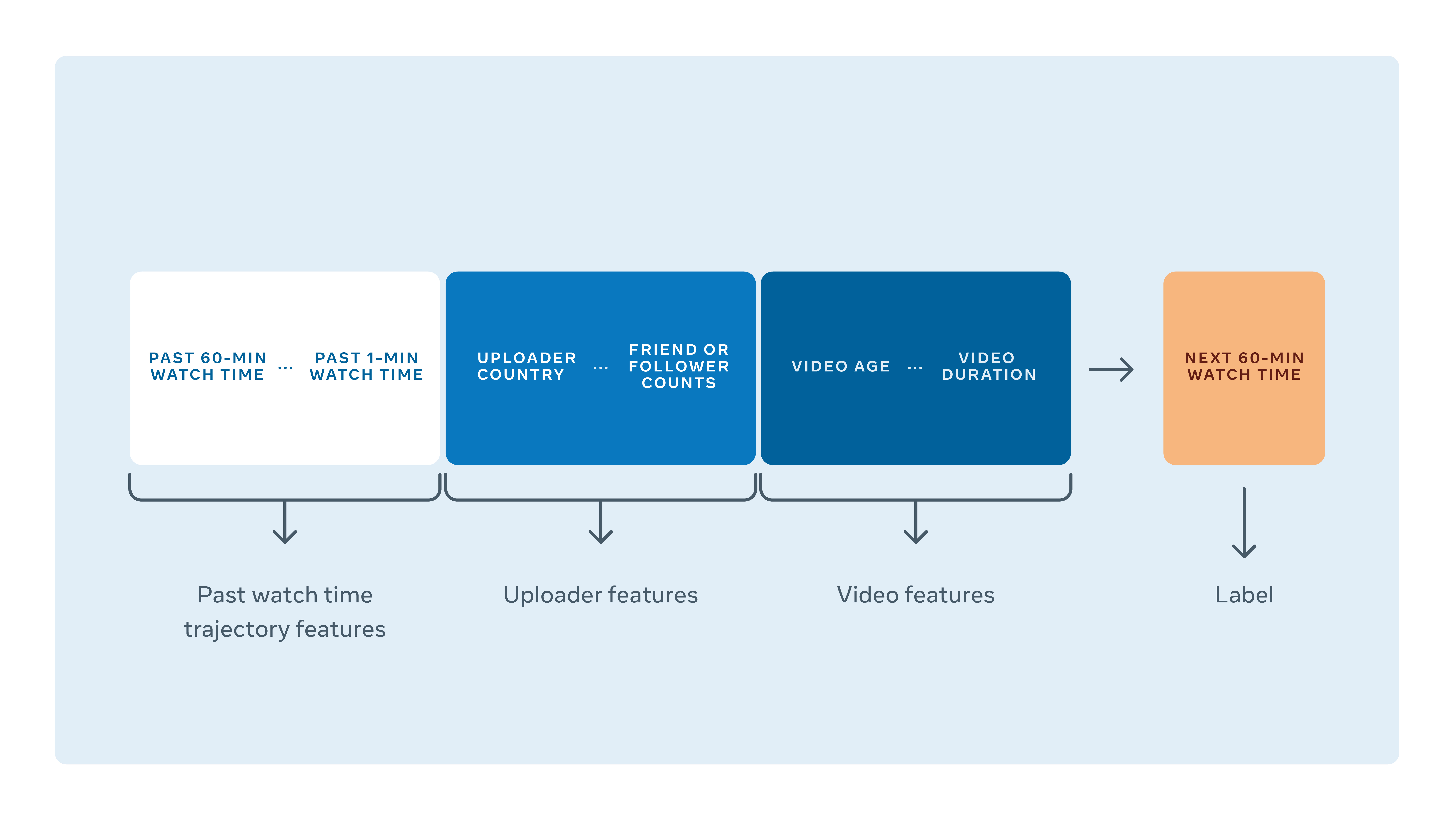
Для решения этих сложностей мы решили обучать нашу модель, используя данные о просмотрах. Каждая строка данных в обучении/оценке соответствует точке принятия решений, для которой система должна сделать прогноз.
Поскольку, как уже говорилось, данные о просмотрах могут быть «перекошенными» или диспропорциональными во многих отношениях, мы выполняли очистку данных, трансформацию, бакетирование и взвешенную выборку по интересующей нас размерности.
Также, поскольку у свежевыложенных видео нет траектории, на которую можно опираться, мы решили создать две модели: одну для запросов при публикации новых видео, другую для запросов по уже опубликованным ранее видео. Вторая модель использует три набора признаков, упомянутые выше. Модель для новых видео смотрит на то, как показывали себя другие видео от того же автора, и использует это вместо траектории времени просмотра. Когда видео находится на Facebook достаточно долго для наличия информации о прошлом, мы переключаем его на вторую модель.
При разработке моделей мы отбирали лучшие варианты, учитывая как корень из среднеквадратической ошибки (RMSE), так и среднюю абсолютную процентную ошибку (Mean Absolute Percentage Error, MAPE). Мы используем обе эти метрики, потому что RMSE чувствительна к выбросам, а MAPE — к малым значениям.
У нашей метки времени просмотра — высокая дисперсия, поэтому мы используем MAPE для оценки результатов популярных или умеренно популярных видеозаписаписей, а RMSE — для менее просматриваемых.
Нам также важно, чтобы модель была способна к хорошей генерализации для видео различных типов, различного «возраста», различных уровней популярности. Поэтому при оценке мы также всегда включаем метрики по категориям.
MAPE и RMSE — хорошие суммирующие метрики для выбора моделей, но они не обязательно отражают прямое улучшение продукта. Порой, когда у двух моделей похожие результаты RMSE и MAPE, мы также переводим их оценки в плоскость классификации, чтобы понять трейдофф. Например, если видео получает 1000 минут просмотра, в то время как модель А предсказывала 10 минут, то MAPE модели А составляет 99%. Если модель B предсказала 1990 минут, то MAPE у нее будет таким же (99%), но при этом ее предсказание будет означать, что видео с куда большей вероятностью получит высококачественное кодирование.
Мы также оцениваем то, как видео классифицируются, потому что хотим уловить трейдофф между применением продвинутого кодирования слишком часто и упущенными возможностями применить его, когда это принесло бы пользу. Например, для порога в 10 секунд мы смотрим, у скольки видеозаписей время просмотра оказалось меньше 10 секунд и у скольки это прогнозировалось, а в итоге высчитываем число ложноположительных и ложноотрицательных срабатываний модели. Мы повторяем такие подсчеты для нескольких порогов. Это позволяет нам понять больше о том, как модель справляется с видеозаписями на разных уровнях популярности, и она предлагает больше задач кодировки, чем стоило бы, или упускает возможности.
Влияние новой модели кодирования видео
Помимо улучшения пользовательского опыта для новых видео, новая модель также может идентифицировать давно загруженные видео, которые стоило бы перекодировать, и направляет ресурсы на них. Благодаря этому большая часть времени, которое пользователи проводят за просмотром видео, перешла к современному кодированию, а в итоге стало меньше буферизации без необходимости выделять на это дополнительные вычислительные ресурсы. Улучшенное сжатие также позволило пользователям Facebook с ограничениями по трафику (например, людям из развивающихся стран) смотреть больше видеозаписей с более высоким качеством.
Кроме того, когда мы вводим новые рецепты кодирования, нам больше не нужно тратить много времени на оценку, где в списке приоритетов их расположить. Вместо этого, в зависимости от стоимости и выгод, модель автоматически назначает приоритет, который максимизирует общую выгоду. Например, мы можем ввести очень требовательный к мощностям рецепт, который становится осмысленным только в применении к безумно популярным видеозаписям, и модель может выявлять такие. В целом это упрощает для нас вложения в новые и более продвинутые кодеки, чтобы дать людям лучшее качество видео.
Комментариев нет:
Отправить комментарий