Введение
Наверняка каждый читающий имел счастье просверлить дыру в стене чтобы повесить картину или ТВ, ну или по крайней мере слышал, как это делает «сосед с перфоратором». Поэтому в данной статье, для облегчения понимания, будут иногда приводится параллели между бурением скважиной глубиной от 2-х до 4-х км и сверлением дыры в стене.
Ожидается, что данный текст будут читать люди не только из нефтянки, поэтому он был немного адаптирован для лучшего понимания процесса. Поэтому заранее прошу профессиональных буровиков и геологов отнестись с пониманием.
Моя профессиональная деятельность связана с геологией и разработкой месторождений. Закончив специализацию Data Science и оглянувших в поисках куда бы "прикрутить" полученные знания, я пришел к выводу, что на проекте где я работаю только в отчетах по бурению я могу найти представительный объем данных.
Постановка задачи
Бурение скважин всегда было и будет дорогостоящим занятием, а бурение в таких местах планеты как пустыня Сахара тем более. В объеме капитальных затрат на обустройство месторождений, затраты на бурение добычных скважин могут составлять более 50%, и оптимизация стоимости скважин является одним из основных способов улучшить экономику проекта. Стоимость услуг бурового подрядчика рассчитывается исходя из продолжительности бурения (daily rate). Иными слова – чем быстрее мы бурим, т.е. чем меньший период времени мы арендуем станок с бригадой, тем дешевле скважина.
Имея в распоряжении результаты бурения 5 скважин, я решил оценить возможность оптимизации буровых параметров т.е. увеличить скорость бурения.
расшифровка названий буровых параметров использованных в данной работе
ROP – rate of penetration или скорость бурения (м/ч). Тот самый параметр, который определят в конечном итоге продолжительность бурения.
WOB – weight on bit или нагрузка на долото (тонн). При сверлении стен – это усилие которые вы прикладываете к дрели.
RPM – revolution per minute или скорость вращения долота. На ручной дрели вы так же этот параметр можете отрегулировать (больше/меньше).
SPP – stand pipe pressure или давление под которым специальный раствор подается в бурильную трубу на поверхности для того чтобы выносить/вымывать из скважины породу (шлам) разрушенную долотом (пыль, которая получается при сверлении стены).
Flow_in – это расход того самого специального раствора для вымыва шлама из скважины, измеряется в л/мин.
Torque – крутящий момент. Самый сложный для понимания параметр. Это расчетная величина (М), которая характеризует действие приложенного усилия для создания вращения долота.

BDT – bit drill time или время эксплуатации долота.
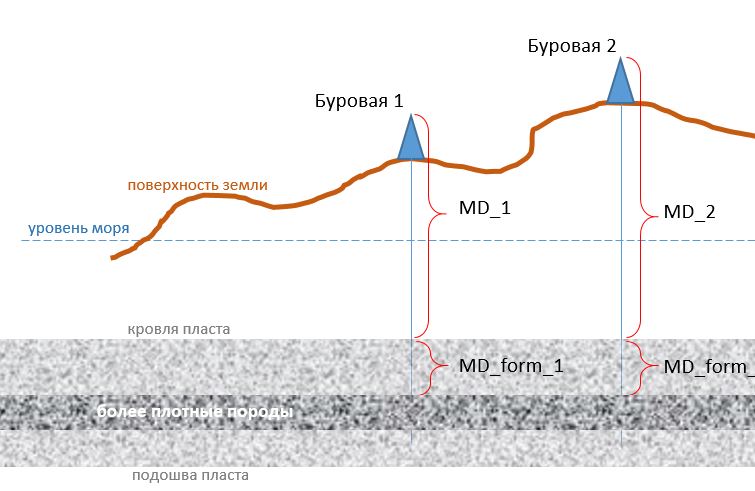
MD – measured depth или измеренная глубина. Это расстояние от площадки на поверхности (где стоит буровик и что-то делает) и долотом. Используется для измерения расстояния от поверхности до границ пластов и других объектов под землей, измеряется в метрах. Так как скважины не всегда идеально прямые, то эта величина всегда немного больше вертикального расстояния.
MD_form– расстояние от кровли (верхней границы) пласта. Гораздо более полезная для анализа величина. В силу неровности земной поверхности расстояние от поверхности до кровли пласта может быть разное
(MD_1 < MD_2). При этом, в силу принципов формирования отложений горной породы, мы понимаем, что с большой долей вероятности те или иные породы будут расположены примерно на одинаковом расстоянии от кровли пласта (MD_form_1 == MD_form_2) во всех рассматриваемых скважинах. Так это работает. Поэтому для анализа нам желательно анализировать параметры бурения в одинаковых по свойству породах и расстояние от кровли пласта нам поможет в данном случае.
Конструкция скважины
Любая скважина, если это только не артезианская скважина у вас на даче, имеет телескопическую конструкцию, как удочка. Зачем это и почему, нам для оптимизации бурения знать не нужно. Важно отметить, что в данной работе были использованы данные только по одной секции. Длина этой секции около 2-х километров.
рисунок

Геология и пласты
Есть такой торт – «Наполеон», который состоит из множества коржей. И каждый корж уникален по-своему – толще/тоньше, более/менее прожаренный и так далее. С пластами примерно так же. В пределах изучаемой секции у нас имеется 11 пластов. И все они разные по составу пород (глина, песок, известняки, доломиты и т.д.). К примеру, по пласту form_A мы имеем один состав и % соотношение между породами, в пласте form_C совершенно другое.
пласт form_A

Для простоты визуализации названия пород, указанные в отчете, были сокращены:
Limestone general: LM
Limestone dolomitic: LM_DLM
Limestone dolomitic: LM_DLM
Dolomite: DLM
Dolomite calcareous: DLM_C
Evaporite Gypsum & Anhydrite: E_GA
Evaporite Salts Na, K, Mg: E_KMN
Rock extrusive: EXTR
Shale clay: SHC
Shale silty: SHS
Siltstone: SILT
Unassigned: UNS
Sand all: SND
пласт form_B

На рисунке ниже мы видим, как изменяется литологический состав от пласта к пласту. Из-за различных механических свойств, некоторые породы бурятся быстрее чем другие при тех же самых параметрах бурения. Это примерно, как вам нужно просверлить несколько дыр в несущей стене и межкомнатной перегородке, кто сверлил, тот поймет о чем я.

В силу того, что под воздействием веса вышележащих пород происходит их сдавливание (уплотнение) , тот же самый песчаник в верхней части секции является менее плотным, чем тот, который расположен 2-мя километрами глубже (очень упрощённо и есть нюансы). И чтобы пробурить нижний песчаник нам потребуются уже другие параметры бурения.
Именно этот фактор не позволил мне в самом начале пути получить приемлемый уровень точности при прогнозе ROP используя единую модель для всей секции. В данной работе секция разбита на пласты и для каждого пласта был произведен подбор наиболее оптимальной модели. Ну об этом подробнее дальше.
Обзор входных данных
Предварительно данные из различных источников были объединены в единый датасет. Незначительные пропуски и отрицательные значения удалены.

Что мы видим на рисунке выше. По 2-м параметрам бурения (BDT и Flow_in) отсутствует большой объем данных ~ 18%. Выясняется, что по скважине well_W эти данные не были переданы в свое время подрядчиком по бурению. Возникает дилемма: well_W удаляется из датасета скважина и далее модели обучаются на меньшем датасете; либо удаляются признаки BDT и Flow_in в остальных 4-х скважинах и далее модели обучаются на сокращенном наборе признаков.
Параметр BDT несомненно важный. Кто сверлил, тот помнит, что происходит когда сверло становится тупым. Но в данном случае, с учетом того, что долота (сверла) могли использоваться на нескольких скважинах, то использовать данный параметр для обучения моделей пожалуй не стоит.
Если взглянуть на распределение буровых параметров по каждому пласту в отдельности, становится очевидно, что каждая скважина пробурена со своим уникальным набором (комбинацией) буровых параметров и удаление одной из скважин приведет к уменьшению диапазона данных для обучения. По этой же причине закончилась неудачей попытка использовать одну из скважин для «blind test», т.е. проверки качества прогноза ROP.



С целью сохранить ширину диапазона данных, было решено удалить Flow_in во всех скважинах.
ВАЖНО
Чтобы не режим конфиденциальности, все использованные данные, включая MD, были изменены, т.е. параметры не пригодны для какого-либо геологического анализа.
Первичный анализ данных
Для выбора стратегии по оптимизации параметров бурения, в первую очередь были визуализированы их распределения в целом по скважине и по каждому пласту в отдельности. Эти же распределения и помогли разобраться с причиной провала «blind» теста. Следует обратить внимание, что на данных рисунках данные до удаления выбросов.


Стандартный обзор данных с целью удостовериться, что у нас нет отрицательных значений.

Кластеризация
Кластеризация выполнена с целью корректного разделения датасета на train и test, т.е. соотношение 80:20 будет сохранятся не только в масштабе пласт/скважина, но и внутри каждого кластера, выделенного в пределах пласта.
С учетом того, что буровые параметры характеризуют процесс бурения, а не свойства пласта (упрощенно, есть нюансы), для разделения пласта на кластеры используются результаты геофизических исследований скважины – параметры записанные приборами в скважине сразу после бурения и характеризующие непосредственно свойства пласта.
В данном интервале доступны параметры ГК (GR), плотность (RHOB), акустика (DTC). Параметры RHOB и DTC были использованы для K-Means clustering.

С учетом ограниченного набора данных по некоторым пластам, а так же исходя из сопоставления значения целевой функции на рисунке выше, каждый пласт был разделен на 4 кластера.


На рисунке ниже RHOB и DTС представлены с разбивкой на кластеры. Визуально подтверждается корреляция между данными параметрами для одноименных кластеров.

Необходимые наборы признаков для обучения

Для прогноза ROP обучение моделей будет выполнено на следующих наборах признаков:
-
MD, MD_form + WOB, RPM, Torque, SPP (анализ аномалий производится в 4 признаках и 1 таргете).
-
MD, MD_form + WOB, RPM, SPP (проверяем прогноз ROP без Torque. (этот параметр не замеряется, а рассчитывается на основании других параметров). анализ аномалий производится в 3 признаках и 1 таргете).
Для оптимизации параметров бурения через PSO нам потребуются следующие наборы данных:
-
WOB, RPM, SPP (при оптимизации данные параметры будут генерироваться рандомно в заданном диапазоне, поэтому мы не можем использовать данные по глубине и расстоянию от кровли пласта. анализ аномалий производится в 3 признаках и 1 таргете).
-
WOB, RPM (проверяем прогноз ROP без SPP. анализ аномалий производится в 2 признаках и 1 таргете).
Маркировка аномальных значений
При проведении первичного анализа данных ГИС (RHOB, DTC и GR), в отличие от параметров бурения, удаление выбросов не производится. Связано это с тем, что параметры ГИС характеризуют свойства пород, которые от метра к метру могут меняться в широком диапазоне, в то время как в изменениях параметров бурения присутствует человеческий и технологический фактор (остановки, смены режимов бурения, осложнения при бурении и т.д.).
Для того чтобы избежать удаления данных в признаках, которые не используются для обучения моделей, произведем маркировку аномальных значений для каждого набора признаков.
Рассматриваемая секция состоит из 11 пластов, по каждому из которых имеется 5 буровых параметров и это всё по каждой из 5 скважин. Это значит, что мы должны проанализировать выбросы в 275 кейсах.
Прежде всего выполним тест на нормальность распределения. Я использовал normaltest. Лишь в 12 кейсах из 275 данные имют нормальное распределение. В данном случае идентификация аномальных значений выполняется через IQR (Q1 – 1.5*IQR и Q3 + 1.5*IQR).

В случае ненормального распределения использование IQR непригодно. Удаление значений за пределами определенных процентилей (2,5% и 97,5%) так же не дает результата так как данные зачастую имеют мультимодальное распределение, либо имеют длинные «хвосты», в которые попадают значения с более низкой плотностью вероятности

Чтобы решить данную задачу, для каждого значения кейса было найдено соответствующее значение вероятности (kde_pdf = kde.pdf(sample[i])). Данные, вероятность которых составляет 10% от максимального значения вероятности для каждого кейса маркируются как выбросы.
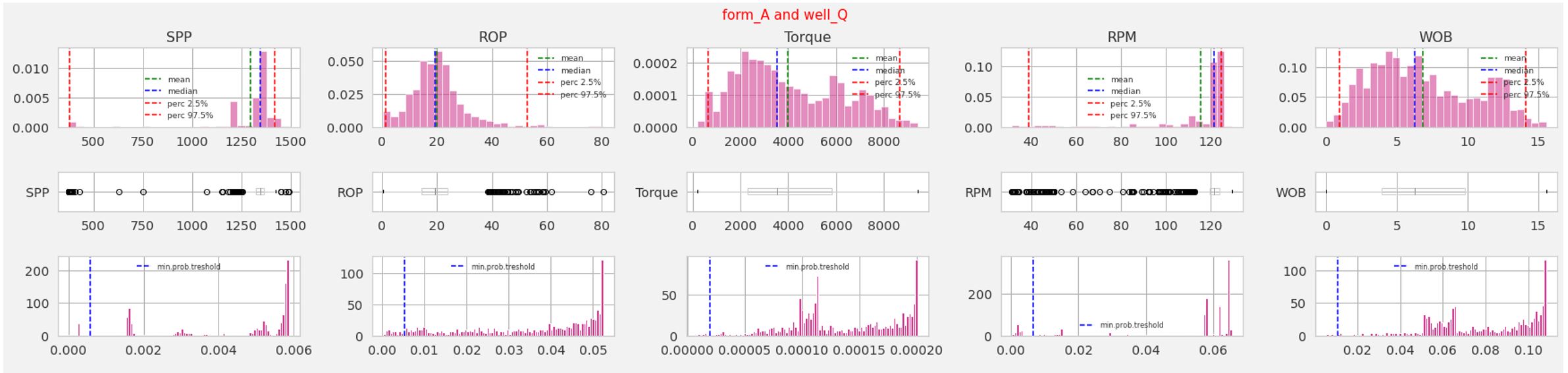
Визуальный контроль полученных результатов показывает удовлетворительное качество результата. При необходимости, для более получения более или менее шумного набора данных 10% значение отсечки может быть пересмотрено. Один из примеров полученных результатов представлен ниже.

Изменение количества удаленных значений в зависимости от числа рассматриваемых признаков происходило в следующем порядке:

Разбивка по пластам выглядит следующим образом:

Следует отметить, что в данной таблице для каждого пласта указаны суммарные значения выбросов по всему набору признаков. Сопоставление параметра RPM по всем пластам секции – до и после удаления выбросов:

Разделение на train и test
Так как в рамках данной работы не предполагается производить настройку гиперпараметров моделей, разделение произведено только на train и test в соотношении 80:20.
Как было сказано выше, предполагается произвести прогноз ROP для различных комбинаций признаков. По этой причине, удаление выбросов не производилось перед разделением на обучающую и тестовую выборки. В обе выборки были включены маркеры обозначающие аномальные значения.
Разделение данных производилось по каждому кластеру в пределах пласта по каждой скважине. Сделано это того, чтобы получить представительный набор данных для теста. Результаты разделения на train и test параметра ROP для пласта «form_E»:

Для оценки качества выполненного разделения взглянем на параметры распределения буровых параметров в обучающей и тестовой выборках по всей секции. Полученные значения стандартного отклонения и MAE свидетельствуют о том, что мы имеем представительную выборку для оценки качества выполненного прогноза.


Пример распределения данных ГИС в обучающей и тестовой выборках по всей секции. Удаление выбросов в этих параметрах не производилось.

Выбор наилучших моделей для прогноза ROP
Для выбора наилучшей модели для прогноза ROP использовался следующий набор моделей (параметры по умолчанию): LGBMRegressor, XGBRegressor, DecisionTreeRegressor, RandomForestRegressor, KNeighborsRegressor, GradientBoostingRegressor, CatBoostRegressor, LinearRegression.
Для понимания эффекта от удаления аномалий произведена проверка прогноза на тестовых данных без удаления аномалий и на данных где аномалии были удалены.

В каждом из кейсов мы видим, что для 3-4 пластов удаление выбросов не привело к улучшению качества прогноза ROP. Для данных пластов обучение моделей производится на полных данных. Как результат мы видим незначительное увеличение среднего значения R2 по всем кейсам.

Взглянем на полученные результаты. Объединять результаты прогноза на одном графике нецелесообразно, так как в каждом кейсе использовался различный набор данных.
Сопоставление результатов прогноза для пласта form_A для вариантов с 6, 5, 3 и 2 признаками.


Наибольшее снижение качество прогноза (R2) при снижении числа признаков у пласта form_D – с 0,8 до 0,4:


После выбора наилучших моделей и наборов данных для их обучения проиведем обучение данных моделей уже на полных данных (без разделения на tain и test).
Вывод:
-
Произведен выбор моделей дающих минимальную ошибку при прогнозе ROP.
-
Коэффициент детерминации при проведении тестовых расчетов находится в диапазоне от 0,8 до 0,94 (в зависимости от пласта) для наборов данных с 6 признаками (MD, MD_form, WOB, RPM, SPP, Torque).
-
В результате данной работы получен набор обученных моделей для каждого пласта пригодный для прогноза ROP в режиме реального времени.
Прогноз данных ГИС

Так как для прогноза ROP производилось обучение моделей для каждого пласта в отдельности, то возникает логичный вопрос, как мы узнаем, что мы пробурили один пласт и начали бурить следующий и нам необходимо начать использовать для прогноза ROP уже следующую модель. Как было сказано выше, в нашем распоряжении имеются геофизические данные (гамма каротаж, плотностной и акустический каротажи) описывающие/характеризующие свойства пласта. В большинстве случаев данные параметры записываются ПОСЛЕ завершения бурения. Иногда, в зависимости от того, какие пласты бурятся, какова стоимость бурения или же если необходимо принимать решение о том, куда бурить в процессе бурения, геофиз. параметры могут записываться в процессе бурения. Но это не наш случай.
Как правило, границы пластов характеризуются резким/характерным изменением одного или даже нескольких параметров (GR, RHOB, DTC). Это значит что происходит изменение свойств пласта, в том числе и геомеханических, и параметры бурения должны отреагировать соответственно. В нашем же случае, мы можем решить обратную задачу – через анализ поведения параметров бурения, мы можем произвести прогноз геофизических параметров.
Таким образом, для понимания того, был ли вскрыт бурением тот или иной пласт, нам необходимо научиться прогнозировать параметры ГИС используя параметры бурения.
Прогноз данных ГИС выполнялся в том же порядке, что и прогноз ROP, только в данном случае, праметр ROP был добавлен в признаки для обучения моделей.

Подготовка данных

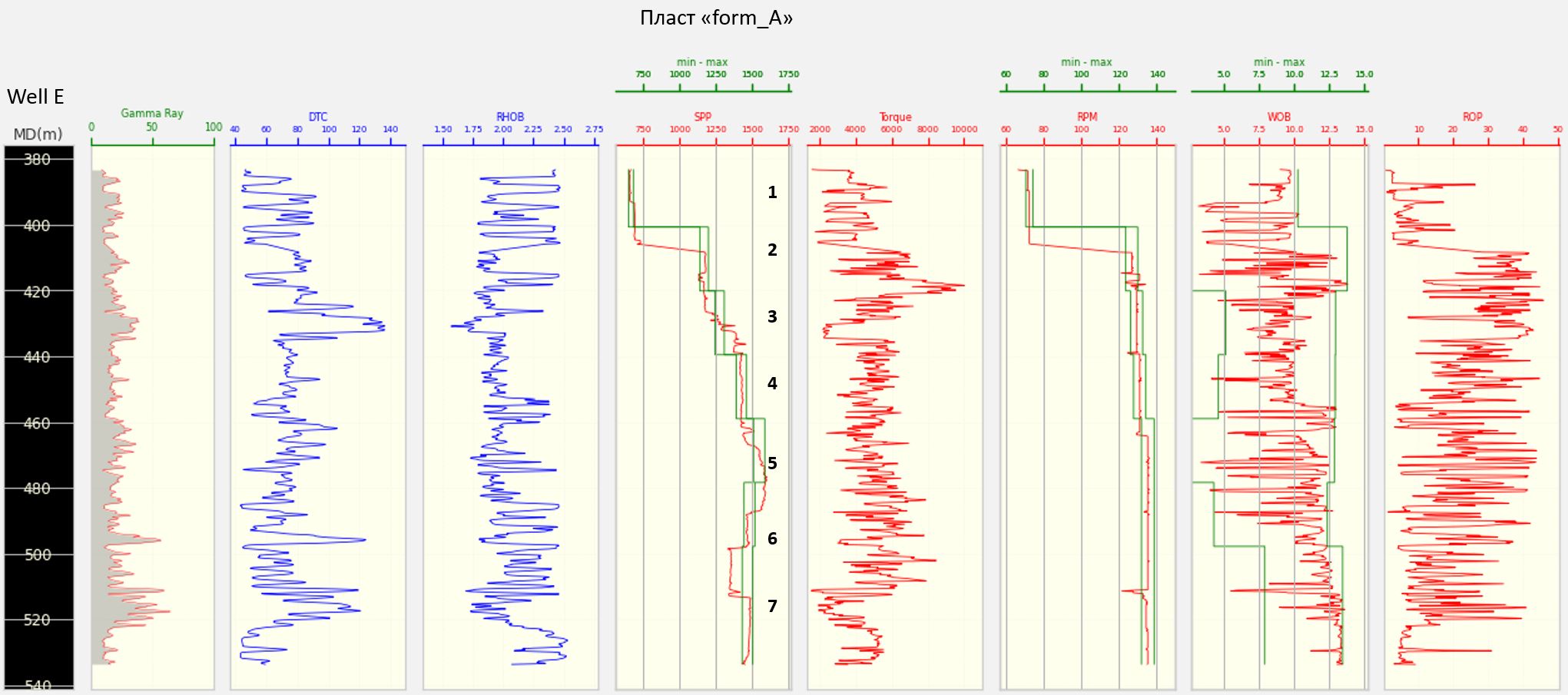
Для обучения моделей, к фактическому набору данных по каждому пласту были добавлены данные из нижележащего пласта в размере 120 строк. 120 строк – это минимальное значение мощности одного из пластов в одной из 5 скважин. Увеличение объема данных для обучения было сделано для того, чтобы получить уверенный прогноз данных ГИС на границе верхнего и нижнего пласта. На рисунке справа 1-й стрелкой указан случай резкого изменения синей кривой на границе между пластами А и В, и 2-мя стрелками граница между пластами В и С.
При сопоставлении результатов прогноза параметров ГИС на данных с выбросами и без выбросов, выясняется, что лучшее качество прогноза демонстрируют модели, обученные на полном наборе данных (с выбросами). С учетом того, что для прогноза данных ГИС использовался максимально доступный набор признаков, коэффициент детерминации имеет значения 0,75 и выше.

Результаты прогноза параметров ГИС по пласту А для всех скважин.

Результаты прогноза параметров ГИС по пласту А для скважины Q.

Выводы:
-
Прогноз данных ГИС по данным бурения показывает высокий уровень точности.
-
Это позволяет с высокой надежностью визуально идентифицировать границы пластов и своевременно использовать модели, обученные для соответствующих пластов.
-
В данной работе не предполагалась разработка инструмента для автоматизированного разделения (классификация, проверка гипотез).
Оптимизация параметров бурения на этапе подготовки Программы бурения
В силу ряда причин, связанных с принципами накопления осадочных пород, мы можем с большой долей уверенности сказать, что на расстоянии в несколько сот метров от пробуренной скважины, в пределах одного пласта, мы встретим примерно такой же разрез, т.е. характер изменения свойств пород от кровли пласта до подошвы будет примерно одинаковый (есть нюансы). Но чем дальше мы отходим скважины, тем всё большая разница будет возникать (как между скважинами Q и W ).

Это будет выражаться в изменении толщины слоев различных пород, их литологического состава (т.е. одних пород в них будет меньше, других больше), что соответственно приведет и к изменению геомеханических свойств, которые повлияют в свою очередь на параметры бурения.
Если же нам нужно пробурить новые скважины, то более высокая надежность рекомендаций может быть сделана для скважин, планируемых к бурению в непосредственной близости от уже пробуренных. На рисунке ниже это скважины Q-1 и W-1. После разбуривания этих скважин и получения новых данных, производится новый цикл обучения и подготовки рекомендаций уже скважин Q-2, Q-3 и W-2, W-3.

Получается, что подготовка единых рекомендаций по параметрам бурения (для всех будущих скважин) для того или иного конкретного пласта в разных частях месторождения является ошибочным.
А вот выполнить расчет оптимальных параметров бурения для каждой пробуренной скважины и использовать полученные рекомендации при бурении проектных скважин расположенных в непосредственной близости от данных скважин – это вполне рабочий вариант.
Так как толщина (мощность) некоторых пластов имеет 200 и более метров, при подготовке рекомендаций выполнено разбиение каждого пласта на интервалы с минимальной мощностью ~ 23 м (150 строк данных). Размеры интервала могут быть изменены в соответствии с рекомендациями Отдела бурения. Но следует помнить, что увеличивая данный интервал (интервал прогноза), мы теряем точность предсказания, так как при увеличении интервала все больше разных слоев с различными свойствами попадают в него. Представляется, что чем меньше этот интервал, тем лучше.
Так на рисунке ниже, мы видим, что пласт form_A был разбит на 7 интервалов. В случае, если размер нижнего интервала меньше чем заданное значение, то последний интервал объединяется с предпоследним.
Оптимизация буровых параметров будет осуществляться с помощью алгоритма Particle Swarm Optimization (PSO). https://towardsdatascience.com/particle-swarm-optimization-visually-explained-46289eeb2e14
По сути, данный алгоритм находит минимальное значение функции, но добавив знак «-» в функцию расчета мы находим максимально возможное значение функции для множества вариантов комбинаций входных параметров. Данный алгоритм генерирует наборы входных параметров и, с помощью обученной модели (для каждого пласта), мы производим прогнозный расчет ROP.

Так как данные параметры генерируются стохастически и никак не привязаны к положению относительно кровли и подошвы пласта, использование таких параметров как глубина и расстояние от кровли пласта не представляется возможным.

По причине того, что параметры WOB и Torque взаимосвязаны, независимое генерирование данных параметров так же не подходит. Torque должен быть рассчитан для каждого сгенерированного параметра WOB. С целью получения входных параметров максимально приближенных к реальным, для каждого рассматриваемого интервала производится поиск оптимальной модели воспроизводящей Torque по данным WOB с максимальной точностью. Т.е. реализован тот же принцип машинного обучения, только для обучения используется не 4 параметра, а 1 (WOB).


К сожалению, так происходит не во всех интервалах секции. В данной работе все пласты были разбиты на интервалы определенной мощности. Общее количество выделенных интервалов для 5 скважин и 11 пластов составляет 344. Из 344 интервалов в 177 интервалах качество предсказания Torque очень низкое (R2 < 0.5).

Пример для пласта form_K. Как видно из данного графика, никакой зависимости здесь не наблюдается. Предполагается, что данное поведение параметра Torque вызвано техническими причинами возникшими в ходе бурения скважины. Становится очевидным, что необходимо отказаться от использования параметра Torque.
Таким образом список параметров для обучения базовой модели сокращается с 6 до 3 признаков: SPP, RPM, WOB.
Размеры диапазона, в пределах которого с помощью PSO алгоритма генерируются параметры для предварительно обученной модели, задаются следующим образом:
1. SPP – в силу того, что данный параметр не регулируется буровиками «каждый метр», мин и макс границы интервала задаются как ± 2.5% от его среднего значения в каждом интервале.
2. PRM – так же как и SPP данный параметр не регулируется «каждый метр», мин и макс границы интервала задаются как ± 2.5% от его среднего значения.
3. WOB – мин и макс границы интервала задаются соответстветственно как процентили 1,25 и 98,75 значений в рассматриваемом интервале.
Минимальные и максимальные границы для генерации входных параметров на примере скважины well_E для пласта form_A:

Та же скважина но в масштабе секции:

Результаты оптимизации параметров бурения (well_E) в пределах пласта:

И для всей секции:

Рекомендации по оптимизированным параметрам (на примере скважины well_E) сведены в таблицу:

Время бурения (ROP x ∆ MD) данной секции уменьшается практически в 2 раза. Конечно, к этому значению нужно относиться с определенной долей скепсиса. Оптимизация параметров бурения в интервале 23 метра приводит к осреднению геомеханических свойств в данном интервале, что несомненно негативно скажется на фактической скорости бурения. Использованный алгоритм позволят дать рекомендаци по параметрам бурения для интервала любой мощности, вплоть до 1 метра. Но поиск золотой середины требует обсуждения с командой бурения.
Summary:
-
Данную работу следует рассматривать лишь как некий ориентир для тех кто решит заняться оптимизацией буровых параметров с помощью методов машинного обучения.
-
Надеюсь это поможет, так как я прошел этот путь самостоятельно. Было множество тупиков, ошибок, заблуждений и разочарований)).
-
Каждый этап данной работы выполнен с параметрами по умолчанию, и, несомненно, все этапы могут быть переработаны и дополнены в зависимости от задач и уровня подготовки специалиста.
-
Для улучшения качества оптимизации буровых параметров и подготовки более качественной программы бурения, видится необходимимым поработать больше с параметром SPP. Данный параметр непосредственно связан с flow_in и все его изменения являются индикацией проблем связанных с вымывом разбуренной породы на поверхность.
Комментариев нет:
Отправить комментарий