
В этом посте я расскажу историю появления Open Source библиотеки Albumentations как я ее запомнил. В технические детали углубляться не буду. Основная задача текста - логирование, то есть надо написать историю, которую мне будет интересно прочитать через 20 лет.
История будет затянутая, с лишними подробностями, более того - основная часть будет о том, как все начиналось, а процесс итеративных улучшений будет освещен меньше.
Albumentations - это еще одна python библиотека, которая позволяет аугментировать изображения, что полезно в задачах компьютерного зрения.
Что такое аугментации изображений?
Аугментация - это способ генерировать новые изображения по тем, что у нас есть. Это могут быть простые, вроде отражений или поворотов, а могут быть гораздо более замороченные, например, добавления эффекта дождя или перенос стиля с другой фотографии.

Нужно это для увеличения тренировочного датасета. Чем больше датасет - тем лучше работают нейронные сети, которые на нем натренированы. Датасет можно увеличивать собирая и размечая новые данные - это долго и дорого, но пользы больше.
Аугментации дают меньше, но докидывать аугментации и экспериментировать с ними менее затратно.
На практике это означает, что в схему: считать картинку с диска => подать ее на вход сети добавляется промежуточный шаг.
Считать картину с диска => аугментировать картинку случайным образом => подать на вход сети.
Причем в большинстве пайплайнов первые два шага идут на CPU, а уже последний шаг, тренировка сети, на GPU.
Июнь 2017 года. Kaggle организовал соревнование Planet: Understanding The Amazon From Space. Задача multilabel classification, каждой картинке необходимо присвоить несколько меток - лес, река, дорога и т. п.
Задача не очень интересная, идеологически близка классификации на MNIST. Много сил тратить не хотелось. С другой стороны и заморачиваться сильно не надо было - за вечер писался весь необходимый код и после этого оставалось, в пассивном режиме, запускать этот код с различными гиперпараметрами и аугментациями.
Аугментации - это хорошая регуляризация, и чем больше я их докидывал, тем точнее получались сети.
По итогам, наша команда финишировала 7 из 936, то есть денег мы не получили, но каждый приблизил получение кагловой шашечки Kaggle Grandmaster. (Описание нашего решения на хабре от Артура Кузина).
В разрезе аугментация важным было то, что:
-
На тот момент бытовало мнение, что при тренировке сетей bottleneck - это GPU. Чем мощнее GPU, тем быстрее тренируется сеть.
-
С призовых соревнования DSTL (пост с описанием решения) я собрал DevBox с 4 x 1080Ti
-
Для аугментаций мы использовали библиотеку ImgAug, которая имеет много классных преобразований, но не оптимизирована под скорость.

Выяснилось, что все упиралось в скорость аугментаций, то есть bottleneck - CPU, а утилизация GPU была далека от 100%.
Я, как и остальные участники команды, включая Александра Буслаева, начали пилить свои аугментационные велосипеды, которые планировалось сделать быстрее и удобнее.
Следующий важный для меня и этой истории шаг произошел через четыре месяца.
Я ушел со старой работы и бездельничал перед выходом на новую. (Блог пост на хабре о том как я эту работу искал).
На Kaggle тогда проходило соревнование Carvana Image Masking Challenge, задача - бинарная сегментация. Я переиспользовал пайплайн с предыдущего соревнования, и улетел в топ 10 на публичном лидерборде. Команда, которая также была в 10 - Александр Буслаев и Артем Санакоев предложили объединиться.
Я согласился, мы финишировали первыми, лотерейно обойдя на одну миллионную непобедимого на тот момент китайского анонима Bestfitting.
Во время работы над задачей мы шарили код друг с другом и я подглядел у Саши пайплайн для аугментаций. Как программист Саша сильнее меня, и мои наработки выглядели коряво по сравнению с тем, что обнаружилось у него. Да, я выигрывал соревнования и на своем коде, но к тому моменту я умаялся его дебажить и расширять.
Я подрезал Сашину вариант и следующие пол года мы его развивали независимо. Еще несколько соревнований и в феврале 2018 я закрыл шашечку Kaggle Grandmaster, а Саша той зимой выиграл SpaceNet и Urban3D, и купил квартиру с призовых.
В апреле 2018 года Саша Буслаев, Селим Сефербеков и Виктор Дурнов выиграли соревнование Data Science Bowl 2018. ($50,000 призовых + DGX) и расслаблялись после многомесячного марафона.
Я же как закрыл Kaggle Grandmaster прекратил активно участвовать и сфокуировался на карьеризме. Лифт, где я работал, платил заметно больше чем возможные призовые с соревнований, да и новые знания с соревнований шли уже не таким плотным потоком как раньше.
Еще мне хотелось раскачать свой Google Scholar статьями про Deep Learning, и эксперимент показал, что решения с соревнований, при грамотном оформлении хорошо публикуются.
Я обнаружил Workshop про спутниковые снимки, который проходил в рамках конференции CVPR 2018. Там было три соревнования. При сабмите надо было отсылать не только предсказание на тестовых данных, но и статью с описанием решения.
Обнаружил я его дней за 10 до дедлайна.
10 дней на соревнование это очень мало, но большей части академических соревнований не получается привлечь сильных участников. Академики заточены под то, чтобы показать новизну. Соревнования же про то, как сделать сильное решение из 100500 грамотных идей. Это совсем другой спорт.
Я подбил Сашу Буслаева, Селима Сефербекова и Сашу Швеца зайти на эти сореванования с ноги. Сказано - сделано. Оказалось достаточным бахнуть fit predict на пайплайнах, что у нас остались с предыдущих задач и мы финишировали в топ 3 в каждом (2, 2, 3). (статья 1 , статья 2, статья 3)
В аспирантуре меня бомбило, что кодовая база для квантовых Monte Carlo симуляций, которую я использовал для движения науки, гуляет между двигателями этой самой науки как tar файлы в email’ах. Каждый двигатель независимо улучшает / фиксит баги и эти 100500 версий живут своей независимой жизнью.
Тут проглядывалось что-то похожее, поэтому я предложил выложить аугментации как open source библиотеку, и улучшать ее коллективно. Причем мне хотелось успеть выложить до CVPR, то есть чтобы на постерах, которые мы должны были подготовить, были красивые слова про библиотеку + большая ссылка на нее.
Я, как человек испорченный долиной, топил за то, чтобы выкладывать как есть, а уже потом итерационно улучшать.
Саша перфекционист, и долго сопротивлялся с аргументами - "Ну как так? Она же не вылизана. Надо делать все правильно с первого раза. Сделаем вот тут фабрику фабрик и будет круто". Это звучало так, что будем ждать еще пару лет.
Название выбирали так - Саша, в разговоре с коллегой, упомянул библиотеку, и тот на дурака предложил “Albumentations”, то есть микс между Augmentations и Albu - nickname Саши (ALBU = ALexander BUslaev). Название длинное, не по долинным канонам, и даже, возможно, мы его поставили, как временное, но нет ничего более постоянного чем временное, и название прижилось.
В этот момент к инициативе присоединился Алекс Паринов. Он понимал важность инфраструктуры для эффективного решения задач, активно участвовал в соревнованиях, активно контрибьютил в open source. Алекс взялся за то, чтобы привести кодовую базу в человеческий вид, и это было то, чего нам не хватало для релиза.
5 июня, 2018 года, за несколько дней до CVPR первый комит ушел в жизнь
Самое первое Readme выглядело вот так:

На самой конференции всем, конечно, было ортогонально до наших постеров и ссылок на github с Albumentations. И даже то, что мы выбрали место стратегически, рядом с бесплатным кофе, нас не спасло.

17 июня 2018 Алекс добавил тесты.
21 июня 2018 Алекс добавил автоматически генерируемую документацию через Sphinx .
1 июля 2018 Алекс добавил benchmark, который для сравнивал Albumentations с другими библиотеками. У нас появилась уверенность, что в среднем мы быстрее других + в будущем, когда выяснялось, что кто-то где-то нас обошел, мы лезли в код конкурента, учились их трюкам и адаптировали.
В этой фазе мы добавляли все аугментации, которые подворачивались под руку, причем, делали это потому что можем, не тратя время на продумывание деталей. С одной стороны это все ускоряло и добавляло драйва. Мы видели прогресс, но с другой, какие-то решения принятые тогда, скажем названия преобразований, или параметры по умолчанию часто были далеки от оптимального, а потом их стало уже не поменять.
В конце июля пришел первый PR от кого-то не из Core Team.
В августе 2018 в проект ворвался Женя Хведченя. К тому моменту он активно рубился на Kaggle и ему была очевидна необходимость серьезных аугментаций. Свой путь он начинал с Keras, встроенных аугментаций которого ему крайне не хватало. Решая Data Science Bowl 2018 он переехал на PyTorch, в котором и начал пилить свой аугментационный велосипед. На Albumentations он переехал практически сразу после релиза, так как библиотека была похожа на то, что было в решении победителей DSBowl 2018 и ему понравился подход. К августу он решил добавить свои наработки по аугментации bounding boxes в Albumentations. Глубокое понимание кодовой базы, высокое качество Pull Request’ов сделали свое дело, было решено узаконить отношения и Женя стал членом Core Team.
В течение лета:
-
Рефакторили код
-
Улучшали тестовое покрытие
-
Добавили линтеры, форматеры, улучшали Docstring’и и Readme.
Добавили несколько Jupyter Notebooks с примерами использования и пример того как безболезненно перелезть аугментаций, предлагаемых torchvision.
28 ноября - Саша добавил возможность применять преобразование к пачке картинок, масок и боксов. Мы добавили jupyter notebook с примером использования, описали в документации, и тем не менее нас постоянно продолжали спрашивать когда мы ее добавим => позже, в 2020 я набил блог пост и запросы прекратились :)
3 января 2019 - Женя добавил поддержку keypoints. Никто из нас на тот момент их не использовал, но были запросы от пользователей, так что Женя закрыл вопрос.
7 апреля 2019 Женя добавил Lambda transform. Теперь стало возможным без боли добавлять кастомные преобразования, на основе своих наработок или других библиотек.
18 мая 2019 Алекс добавил сериализацию преобразований. До этого аугментационный пайплайн можно было определять только в Python коде. Это неудобно, хочется, как и все остальные гиперпараметры определять в конфигах. Теперь же можно было загружать / сохранять из python dictionary, JSON, YAML.
В Августе 2019 на сцену вышел Миша Дружинин. Она давно хотел присоединиться к Open Source проекту, но все проекты, которые его интересовали, казались или слишком сложными или он не мог придумать, что бы он мог в них внести.
Для одного из своих проектов ему нужны были сложные аугментации. Он вышел на ImgAug, нашел там проблемы. С болью создал Pull Request. Потом ему нужны были свои преобразования, но из-за архитектуры ImgAug их было больно встраивать, так что он просто писал свои велосипеды.
Миша залез в соревнование Severstal: Steel Defect Detection и в кернелах увидел, что участники используют Albumentations. Тоже попробовал, залез в код. Ему понравилась простота и понятность интерфейса. Примерно тогда я в очередной раз призывал ребят с ods.ai попробовать себя в open source и обещал, что мы всем будем рады.
Миша в своих пайплайнах смог и Albumentations упереть по скорости. Он прикинул как можно еще все ускорить, нашел пачку простых, но эффективных приемов для картинок, хранимых в int8. Более того, имея опыт работы на слабом железе он представлял где может в первую очередь упираться код и что с этим можно сделать. Как следствие он начал создавать Pull Request’ы с новыми преобразованиями, багфиксами, улучшениями.
Он не спрашивал как ему помочь проекту, он не обещал золотых гор если ему дать доступ к репе, он просто делал много качественных Pull Request’ов. И 12 сентября влился в Core Team.
27 сентября 2019 Саша добавил Replay mode. Идея в том, что в силу того, что пачка аугментаций применяется последовательно с разными вероятностями очень тяжело все воспроизводить и дебажить. Хорошо бы иметь возможность 100 процентную воспроизводить вероятностного пайплайна когда надо. Такую возможность Саша и добавил.
Февраль 2020 Алекс освежил документация и написал вебсайт с человеческим лицом albumentations.ai. Сайт был столь хорош, что автор Insightface его подрезал и адаптировал под себя: https://insightface.ai/
Июль 2020 Миша при помощи Алекса создал Albumentations-experimental куда добавляются экспериментальные преобразования. Скажем, там есть преобразование, которое отработает как ожидается на лице с keypoints.
Сентябрь 2020 Алекс создал AutoAlbument - инструмент, который позволяет автоматически подбирать правильные аугментации под задачу. Я к тому моменту уже отошел от машинного обучения, так что сам не пробовал.
После этого фундаментальных изменений не было. По большей части:
-
Улучшали документацию.
-
Добавляли новые, часто экзотически преобразования.
-
Улучшали качество кода.
Апрель 2021 - первый раз вживую встретилс Мишу и Алекса. Неожиданно оказалось, что робкий Миша - это дядя под два метра, на голову меня выше :)

А как поддерживать мотивацию чтобы тратить свободное время на проект?
Поначалу все было просто прикольно. Ты видишь как меняется проект. Ты делаешь улучшения которые хочешь именно ты.
Потом дофамин шел с того, что мы видели как библиотека используется, и кто-то даже благодарил. Приятно делать добрые дела - хорошо мотивировало.
Когда библиотека стала еще популярнее все изменилось. Мы уже добавили и отполировали все то, что использовали в своих проектах, то есть вышли на стабильную фазу.
А с другой стороны пошли bug report’ы, которые были не про баги, а про то, что пользователи неправильно поняли документацию или просто не читали ее.
Молодежная разработка поменялась на корпоративную поддержку. К такому состоянию мы вырулили где-то весной 2019 и было принятно решение сильно не загоняться и делать только то, что приносит удовольствие.
У такого подхода есть издержки - Pull Request’ы рассматриваются не так быстро как могли бы, а bug report’ы могут висеть неделями, но это жизнь. Кому надо быстрее - форкайте и ага, лицензия позволяет.
А как мы библиотеку продвигали?
Eсть много библиотек для аугментации изображений (хороший обзорный пост). Мы создаем свою. Как сделать так, чтобы она была популярной?
Хотелось:
-
Библиотека должна быть быстрой. Как минимум быстрее конкурентов.
-
Библиотека должна быть удобной. Добавить сложную аугментацию должно занимать не больше одной строки.
-
Библиотеку должно быть удобно использовать нам.
-
Библиотеку должно быть удобно использовать остальным.
-
О библиотеке должны знать кто-то кроме нас.
-
Пользователи должны сами рекомендовать друг другу библиотеку, без нашей помощи.
И если первые 4 пункта мы постепенно закрывали, то что было делать с остальными?
И тут мы просто экспериментировали.
Академия
В августе 2018 я договорился с Сашей Калининым и он набил preprint на Arxiv о библиотеке. Главная цель - академикам должно быть просто нас цитировать. Да, можно было вставить BibTex в Readme, но цитирование GitHub репозиториев еще не стало мэйнстримом.
Поначалу пошло самоцитирование. В 2018-2020 я активно публиковал статьи и всегда ссылался на наш препринт. Но постепенно и другие люди начали цитировать препринт в своих работах.
Летом 2019 Саша Калинин читал лекции вместе с Sebastian Rachka в летней школе в Польше. За завтраком Себастиан упомянул, что он редактирует special issue в журнал MDPI и спросил нет ли чего у нас. Саша вспомнил о нашем препринте в две страницы, показал. Себастиану понравилось и он сделал приглашение на бесплатную публикацию.
Мы (в основном Саша Калинин) сделали и теперь наша статья - самая цитируемая в том special issue, опережая статью про FastAI от Jeremy Howard’а.
Что еще можно усугубить? Часто академики придумывают новое преобразование, кто-то читает их статьи, реализовывает и добавляет в библиотеку. По уму надо авторам этих статей написать, поблагодарить за их наработки и сказать, что у нас есть имплементация их преобразования.
Соревнования
Мы работали над библиотекой, параллельно участвуя в соревнованиях. Когда уходили в топ - в описании решения четко описывали, что использовали библиотеку и как это делали. То есть сыграла роль инфлюенсеров, где мы сами этими инфлюенсерами и были.
Также надо было уменьшить головняк при использовании Albumentations на Kaggle в кернелах. В апреле 2019 библиотеку добавили в Kaggle Docker.
Также я активно пинал других победителей. Если они описывали решение, использовали библиотеку, но не указывали - я писал, и просил, чтобы они добавили это упоминание.
На самом деле сильно подпинывать и не надо было. Ребята с ods.ai знали, что мы работаем над библиотекой, и понимали, когда они ее упоминают - это их возможность сказать нам спасибо за работу.
Создали страницу в документации, где есть список соревнований в которых топовые решения использовали библиотеку + описания решений. Она, к сожалению, не в самом актуальном состоянии. Есть стойкое чувство, что ее используют примерно 100% победителей соревнований по компьютерному зрению в мире, но вручную парсить сайты соревнований нам, конечно, лень. :(
Про соревнования была вот такая история - осенью 2019 я помогал организовывать соревнование Lyft: 3D Object Detection for AUtonomous Vehicles. Соревнование было частью конференции NeurIPS 2019 и в какой-то момент там был ужин для организаторов. Рядом со мной сидел организатор какого-то другого соревнования. Я между делом понтанулся, что я Kaggle Grandmaster. Ему это было побоку. Но потом, в разговоре всплыло, что для его компании самое большое откровение от соревнования было - что все в топе используют Albumentations. Они не стали ждать конца соревнования и вкрутили ее в прод с сильным улучшением моделей. И вот когда он узнал, что я из Core Team - тут же проявил интерес и захотел сделать со мной Selfie. :)
Индустрия
По слухам с полей библиотеку используют все подряд, включая Yandex и весь FAANG.
Но вот как сделать так, чтобы информация об этом появилась у нас на сайте непонятно. Мы не можем такое добавлять, только работники компании с разрешения менеджмента.
Когда я работал в Lyft и использовал библиотеку своих пайплайнах я получил разрешение добавить лого в Readme. Также я попинговал народ с других компаний и еще несколько лого появилось.
Как-то мы узнали, что Comma.AI использует нашу библиотеку, но имеет много боли из-за ImgAug, которая была в зависимостях. Мы пошли навстречу и переписали преобразования, которые зависели от ImgAug, и убрали зависимость.
В целом я пока не придумал, как это масштабировать, то есть чтобы люди сами добавлялись
Open Source
Мне сейчас показывает, что 5700 других репозиториев, и 144 пакетов имеет Albumentations как зависимость.
Тут понятно, что надо делать - надо брать популярный репозиторий с тренировкой сетей и перебивать аугментации, которые там используются на Albumentations. Потом повторить эту процедуру много раз.
Я уже почти готов был это сделать, но разбираться в чужом, да еще и скорее всего академическом коде было лень. Но, как только библиотека набрала популярность это все начало происходить и без моего участия.
Топ 10 по звездам, кто имеет Albumentations как зависимость. (Полный список)
Что можно усугубить?
-
Под эгидой менторства найти студентов которые добавят библиотеку в чужие репозитории.
-
Шерстить Stack Overflow на наличие вопросов про библиотеку и отвечать там.
Другие эксперименты
Играть в маркетолога я учился не только на Albumentations. 2017-2019 года меня постоянно приглашали выступить на подкастах, конференциях, митапах. Про работу рассказывать нельзя, так что рассказывал я про Albumentations.
Я живу в штатах, мне интереснее англоязычная аудитория, так что продвигал библиотеку именно на английском.
Остальные занимались ровно тем же, но на русском.
В октябре 2019 мы закинули заявку на включение библиотеки в PyTorch Ecosystem. Они берут всех подряд, но тогда нам казалось что это очень круто. Есть даже конференция про PyTorch Ecosystem на которую нас приглашают. Там можно попытаться продвинуть библиотеку. Но нам то некогда, то руки не доходят, то снова лень.
Февраль 2020 - попали в Nvidia Inception Program. Нам дали $100,000 AWS кредитов на год. Мы туда особо не стремились. Кто-то нас сказал, что так можно, мы подали и ага. Теперь у нас на сайте есть надпись, что мы Member of the NVIDIA Inception program. Кредиты, кстати, мы потратили не все и несколько десятков тысяч долларов сгорело.
Если посмотреть на то, откуда идут переходы в репозиторий - там видны link.zhihu.com и link.csdn.net. Это китайские версии хабра.
Блог пост про multiple transforms я перевел на китайский, вернее не сам это сделал, а нашел китайского товарища, который за $50 перевел мой текст с английского и выложил в нужных местах. Мысль была такая - деньги небольшие, текст и картинки я уже набил. Китай большой. Хотелось посмотреть, что из этого получится.

Это статистика всех переходов на сайт за год.
На первом месте Китай. Может и есть какая связь между переводом поста на китайский и этой статистикой, хотя, наверное, и без этого было бы то же самое. Компьютерное зрение в Китае на подъеме.
Я думаю, что мысль с китайскими переводами оказалась раскрыта не до конца, так что этот блог пост я тоже попрошу перевести.
При выпуске каждой версии мы делали анонс на:
-
Twitter
-
Reddit
-
LinkedIn
Не все, но какие-то анонсы расходились хорошо. У меня 6k подписчиков на Twitter и больше 10k на LinkedIn. У Саши Калинина поменьше, зато у него в подписчиках пачка ML инфлюенсеров. Возможно это помогало.
Продукт удался когда люди сами начинают о нем писать. По такой метрике библиотека удалась. Регулярно выходят блог посты с упоминанием Albumentations.
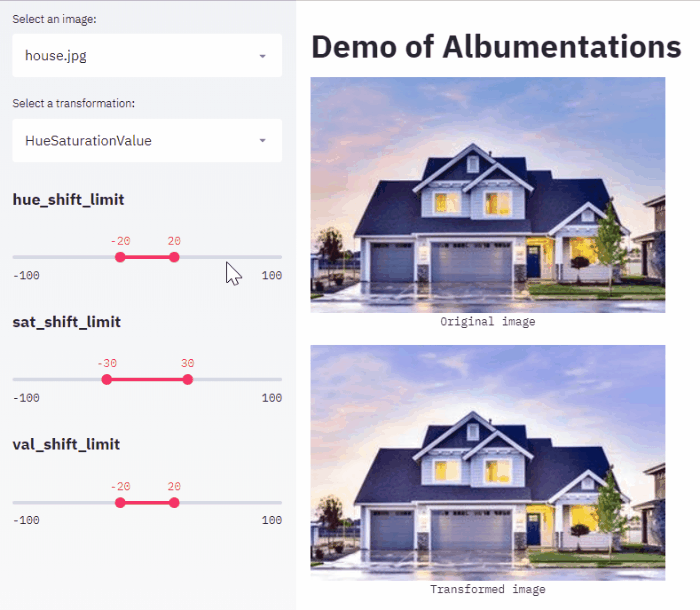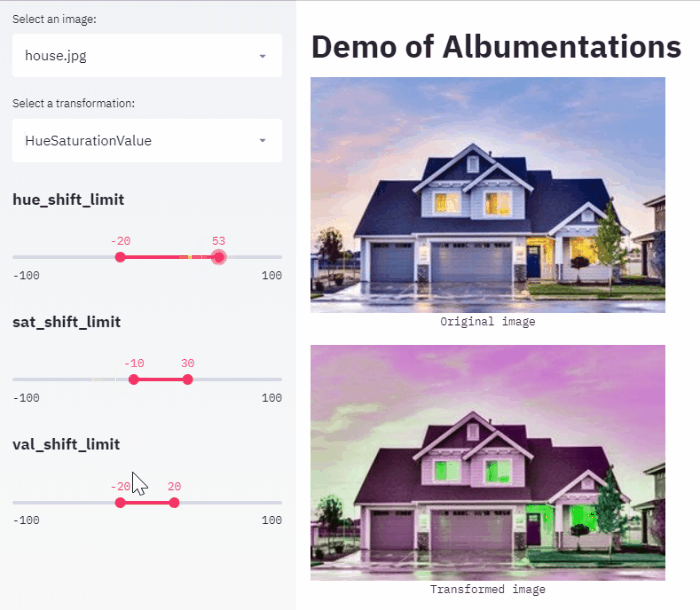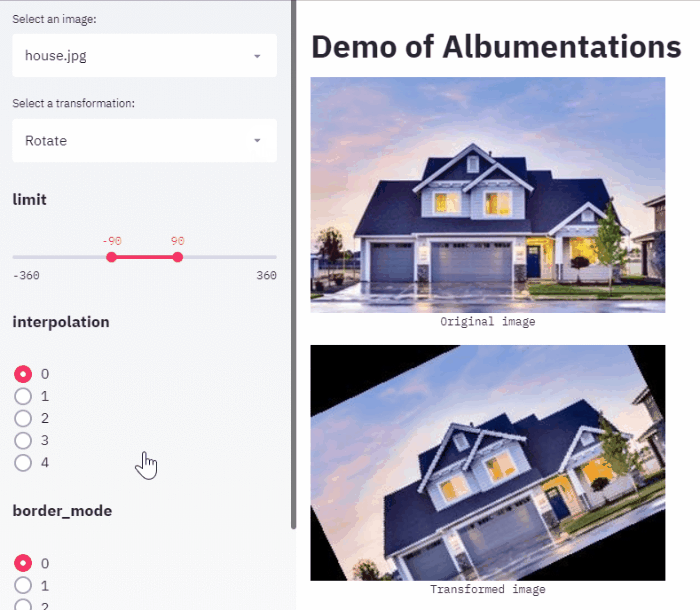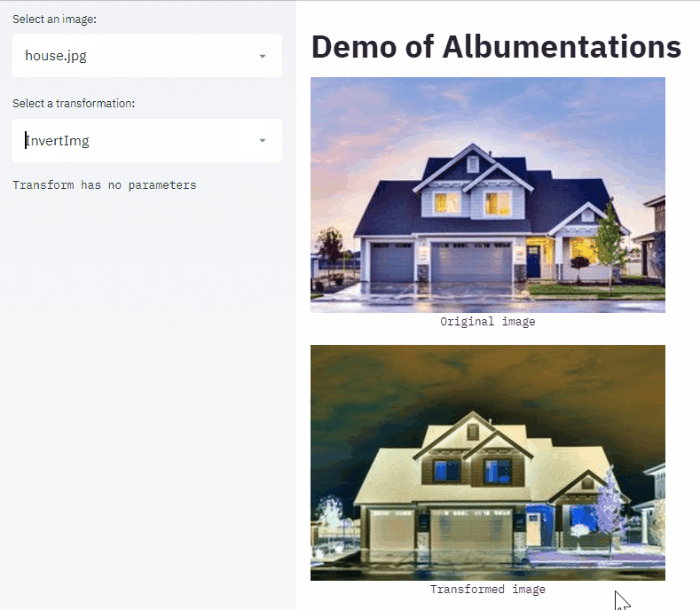
Хочется отдельно отметить пост Ильи Ларченко который написал web app позволяющий удобно выбирать аугментации и свои параметры для своей задачи.
А что бы я делал, если бы делал что-то такое же с нуля?
Сложно сказать. Сейчас я ушел с работы и учусь играть в стартапера, так что
если в будущем я буду вкладывать много сил в Open Source проект - то это должно быть что-то с прицелом на деньги. Скажем Open Core - основные фичи в Open Source, а те, что нужны компаниям - за отдельные деньги.
А можно ли Albumentations перевести в такой формат? Наверное можно. Но как это сделать правильно я не соображу, тут может кто подскажет.
А какой ROI? Вообще стоило оно тратить на это время?
Наверное да, но это не точно. Сначала библиотекой мы занимались от безысходности - хотелось более внятной кодовой базы, хотелось уменьшить свою же боль.
Потом потому что это прикольно, то есть получали свою порцию дофамина каждый раз когда нам кто-то говорил спасибо, либо даже просто упоминал в хорошем смысле этого слова.
Бонусом я поднял свой навык программирования, ну и, наверное, как шашечка это тоже имеет какое-то значение. Теперь я везде гордо пишу: Co-creator of Albumentations.
И использую море open source проектов и понятия не имею кто их разрабатывает. Тут похожая ситуация, многие знают библиотеку, но не знают что мы имеем к ней хоть какое-то отношение.
Хотя была вот такая история - летом заезжал в Киев и пошел гулять по ночному городу с девушкой, которая занимается Data Science. Она активно использовала Albumentations по работе и, скорее всего, выбралась со мной только потому что ей было интересно пообщаться с её разработчиком :)
Что мы по метрикам?
Заключение
В конце хотелось бы сказать спасибо Core Team и всем контрибьютерам за работу. Open Source - это очень странный зверь. Уходит куча времени, чтобы понять как правильно его готовить.
Если вы до этого момент дочитали - хотелось бы попросить:
-
Если вы используете библиотеку на работе, спросите у менеджера - можно ли добавить лого вашей компании к нам? И если разрешит - то создайте добавьте по этой ссылке, пожайлуста - ссылка на добавление лого компании.
-
Если вы используете библиотеку в научных проектах, было бы классно, если бы вы нас процитировали.
-
Если вы нашли баг или есть идея как улучшить библиотеку, Pull Request был бы очень кстати.
-
И всегда приветствуется поставить звездочку на GitHub :)
Отельное спасибо Саше Буслаеву, Алексу Паринову, Жене Хведщеня, Мише Дружинину и Саше Калинину, за то что помогли написать этот пост. Времени прошло всего ничего, а я уже половину деталей забыл, особенно те, которые не знал.
Комментариев нет:
Отправить комментарий