 Для меня это началось шесть с половиной лет назад, когда волею судеб меня затянуло в один закрытый проект. Чей проект — не спрашивайте, не расскажу. Скажу лишь, что идея его была проста как грабли: встроить clang front-end в IDE. Ну, как это недавно сделали в QtCreator, в CLion (в некотором смысле), и т. п. Clang тогда был восходящей звездой, многие тащились от появившейся, наконец, возможности использовать полноценный C++-парсер почти на халяву. И идея, так сказать, буквально витала в воздухе (да и встроенный в clang API автокомплит кода как бэ намекал), надо было просто взять и сделать. Но, как говорил на Боромир, "Нельзя просто так взять, и...". Так получилось и в этом случае. За подробностями — велкам под кат.
Для меня это началось шесть с половиной лет назад, когда волею судеб меня затянуло в один закрытый проект. Чей проект — не спрашивайте, не расскажу. Скажу лишь, что идея его была проста как грабли: встроить clang front-end в IDE. Ну, как это недавно сделали в QtCreator, в CLion (в некотором смысле), и т. п. Clang тогда был восходящей звездой, многие тащились от появившейся, наконец, возможности использовать полноценный C++-парсер почти на халяву. И идея, так сказать, буквально витала в воздухе (да и встроенный в clang API автокомплит кода как бэ намекал), надо было просто взять и сделать. Но, как говорил на Боромир, "Нельзя просто так взять, и...". Так получилось и в этом случае. За подробностями — велкам под кат.
Сначала о хорошем
Бенефиты от использования clang'а в качестве встроенного в IDE C++-парсера, безусловно, есть. В конце концов, функции IDE не сводятся только и исключительно к редактированию файлов. Это и база данных символов, и задачи навигации, и зависимости, и многое другое. И вот тут полноценный компилятор рулит во весь рост, ибо осилить всю мощь препроцессора и шаблонов в относительно простом самописном парсере — задача нетривиальная. Ибо обычно приходится идти на массу компромиссов, что очевидным образом влияет на качество разбора кода. Кому интересно — может посмотреть, скажем, на встроенный парсер QtCeator'а здесь: Qt Creator C++ parser
Там же, в исходниках QtCreator'а, можно увидеть, что перечисленное выше — далеко не всё, что требуется IDE от парсера. Кроме того нужно как минимум:
- подсветка синтаксиса (лексическая и семантическая)
- всяческие хинты "на лету" с отображением информации по символу
- подсказки о том, что с кодом не так и как это можно исправить/дополнить
- автодополнение (Code Completion) в самых разнообразных контекстах
- самый разнообразный рефакторинг
Поэтому на ранее перечисленных преимуществах (действительно серьёзных!) плюсы заканчиваются и начинается боль. Чтобы лучше эту боль понять, можно для начала посмотреть доклад Анастасии Казаковой (anastasiak2512) о том, что же на самом деле требуется от встроенного в IDE парсера кода:
Суть проблемы
А она проста, хоть может быть и неочевидна с первого взгляда. Если в двух словах, то: clang — это компилятор. И к коду относится как компилятор. И заточен на то, что код ему дают уже законченный, а не огрызок файла, который открыт сейчас в редакторе IDE. Огрызки файлов компиляторы не любят, как и незавершенные конструкции, неправильно написанные идентификаторы, retrun вместо return и прочие прелести, которые могут возникнуть здесь и сейчас в редакторе. Разумеется, перед компиляцией всё это будет вычищено, поправлено, приведено в соответствие. Но здесь и сейчас, в редакторе, оно такое, какое есть. И именно в таком виде попадает на стол встроенному в IDE парсеру с периодичностью раз в 5-10 секунд. И если самописная его версия прекрасно "понимает", что имеет дело с полуфабрикатом, то вот clang — нет. И очень сильно удивляется. Что получится в результате такого удивления — зависит "от", как говорится.
К счастью, clang достаточно толерантен к ошибкам в коде. Тем не менее, могут быть и сюрпризы — пропадающая вдруг подсветка, кривой автокомплит, странная диагностика. Ко всему этому нужно быть готовым. Кроме того, clang не всеяден. Он вполне имеет право не принимать что-нибудь в заголовках компилятора, который здесь и сейчас используется для сборки проекта. Хитрые интринсики, нестандартные расширения и прочие, эм..., особенности — все это может приводить к ошибкам разбора в самых неожиданных местах. Ну и, конечно же, перформанс. Редактировать файл с грамматикой на Boost.Spirit или работать над llvm-based-проектом будет одно удовольствие. Но, обо всём подробнее.
Код-полуфабрикат
Вот, скажем, начали вы новый проект. Вам среда сгенерировала дефолтную болванку для main.cpp, и в ней вы написали:
#include <iostream>
int main()
{
foo(10)
}
Код, с точки зрения C++, прямо скажем, невалидный. В файле нет определения функции foo(...), строка не завершена и т. п. Но… Вы только начали. Этот код имеет право именно на такой вид. Как этот код воспринимает IDE с самописным парсером (в данном случае CLion)?
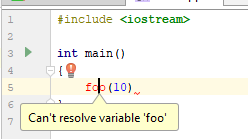
И если нажать на лампочку, то можно увидеть вот что:
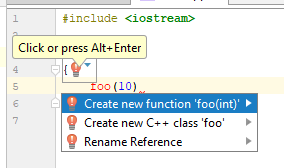
Такое IDE зная нечто, гм, большее о том, что происходит, предлагает вполне ожидаемый вариант: создать функцию из контекста использования. Отличное предложение, я считаю. Как же ведёт себя IDE на базе clang (в данном случае — Qt Creator 4.7)?
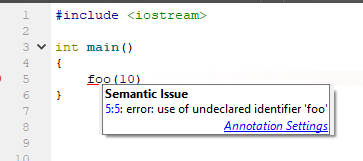
И что предлагается для того, чтобы исправить ситуацию? А ничего! Только стандартный rename!
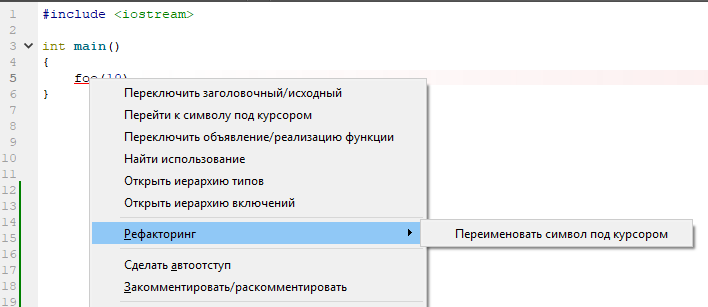
Причина такого поведения весьма проста: для clang'а этот текст является законченным (а ничем другим он и не может быть). И AST он строит исходя из этого предположения. А дальше всё просто: clang видит неопределённый ранее идентификатор. Это — текст на C++ (не на C). Никаких предположений о характере идентификатора не делается — он не определён, значит фрагмент кода — невалиден. И в AST для этой строчки ничего не появляется. Её просто нет. А чего нет в AST — то невозможно анализировать. Обидно, досадно, ну ладно.
Встроенный в IDE парсер исходит немного из других предположений. Он знает, что код — не закончен. Что у программиста вот прям сейчас прёт мысль и пальцы за ней не успевают. Поэтому не все идентификаторы могут быть определены. Такой код, конечно, некорректен с точки зрения высоких стандартов качества компилятора, но парсер знает, что с таким кодом можно сделать и предлагает варианты. Вполне разумные варианты.
Как минимум до версии 3.7 (включительно) похожие проблемы возникали в таком коде:
#include <iostream>
class Temp
{
public:
int i;
};
template<typename T>
class Foo
{
public:
int Bar(Temp tmp)
{
Tpl(tmp);
}
private:
template<typename U>
void Tpl(U val)
{
Foo<U> tmp(val);
tmp.
}
int member;
};
int main()
{
return 0;
}
Внутри методов шаблонного класса автокомплит на основе clang'а не работал. Насколько мне удалось выяснить, причина была в двухпроходном парсинге шаблонов. Автокомплит в clang'е срабатывает на первом проходе, когда информации о фактически используемых типах может быть недостаточно. В clang 5.0 (судя по Release Notes) это починили.
Так или иначе, ситуации, в которых компилятор не в состоянии построить корректное AST (или сделать правильные выводы из контекста), в редактируемом коде вполне могут быть. И в этом случае IDE просто не будет "видеть" соответствующие участки текста и ничем не сможет помочь программисту. Что, разумеется, не здорово. Способность эффективно работать с некорректным кодом — это то, что жизненно необходимо парсеру в IDE, и что совершенно не нужно обычному компилятору. Поэтому парсер в IDE может использовать множество эвристик, которые для компилятора могут оказаться не только бесполезны, но и вредны. А реализовывать в нём два режима работы — ну, это ещё разработчиков убедить нужно.
"Эта роль — ругательная!"
IDE у программиста обычно одна (ну хорошо, две), а вот проектов и тулчейнов — много. И, разумеется, лишних телодвижений, чтобы переключиться с тулчейна на тулчейн, с проекта на проект, делать не хочется. Один-два клика, и конфигурация сборки меняется с Debug на Release, а компилятор — с MSVC на MinGW. А вот парсер кода в IDE остаётся прежним. И он должен, вместе с системой сборки, переключиться с одной конфигурации на другую, с одного тулчейна на другой. А тулчейн может быть какой-нибудь экзотический, или кросс. И задача парсера здесь — продолжить корректно разбирать код. По возможности с минимумом ошибок.
clang — достаточно всеяден. Его можно заставить принимать расширения компиляторов от Microsoft, компилятора gcc. Ему можно передать опции в формате этих компиляторов, и clang их даже поймёт. Но всё это не гарантирует, что clang примет какой-нибудь заголовок из потрохов собранного из танка gcc. Какие-нибудь __builtin_intrinsic_xxx могут стать для него камнем преткновения. Или языковые конструкции, которые текущая версия clang в IDE просто не поддерживает. На качество построения AST для текущего редактируемого файла это, вероятнее всего, не повлияет. А вот построение глобальной базы символов или сохранение precompiled-заголовков может сломаться. И это может оказаться серьёзной проблемой. Ещё большей проблемой может оказаться подобный код не в заголовках тулчейнов или thirdparty, а в заголовках или исходниках проекта. Кстати, всё это — достаточно существенная причина явно сообщать системе сборки (и IDE) о том, какие именно заголовочные файлы для вашего проекта "чужие". Это может упростить жизнь.
Опять же, IDE изначально рассчитана на то, что её будут использовать с разными компиляторами, настройками, тулчейнами и прочим. Рассчитана на то, что придётся иметь дело с кодом, часть элементов которого не поддерживается. Релизный цикл у IDE (не всех :) ) более короткий, чем у компиляторов, следовательно, есть потенциальная возможность более оперативно подтягивать новые фичи, реагировать на найденные проблемы. В мире компиляторов всё немного иначе: релизный цикл минимум в год, проблемы кросскомпиляторной совместимости решаются условной компиляцией и перекладываются на плечи разработчика. Компилятор не обязан быть универсальным и всеядным — его сложность и без того высока. clang тут не является исключением.
Борьба за скорость
Ту часть времени, проведенную за IDE, когда программист не сидит в отладчике, он редактирует текст. И его естественное желание здесь — это чтобы было комфортно (иначе зачем IDE? Можно и блокнотом обойтись!) Комфорт, в том числе, предполагает высокую скорость реакции редактора на изменения текста и нажатие хоткеев. Как верно заметила Анастасия в своём докладе, если через пять секунд после нажатия Ctrl+Space среда не отреагировала появлением менюшки или списка автокомплита — это ужасно (я серьёзно, сами попробуйте). В цифрах это означает, что у встроенного в IDE парсера есть примерно одна секунда, чтобы оценить изменения в файле и перестроить AST, и ещё полторы-две — чтобы предложить разработчику контекстно-зависимый выбор. Секунда. Ну, может две. Кроме того, ожидаемым поведением считается, что если разработчик поменял .h-ник, а потом переключился на .cpp-шник, то сделанные изменения будут "видны". Файлы то вот они, открытые в соседних окошках. А теперь простая калькуляция. Если clang, запущенный из командной строки, справляется с исходником секунд за десять-двадцать, то где основания полагать, что будучи запущенным из IDE он справится с исходником существенно быстрее и уложится в эту самую секунду-две? То есть сработает на порядок быстрее? В общем, на этом можно было бы и закончить, но я не буду.
Про десять-двадцать секунд на исходик я, конечно, утрирую. Хотя, если туда инклюдится какое-нибудь тяжёлое API или, скажем, boost.spirit с Hana наперевес, а потом всё это активно используется в тексте — то 10-20 секунд это ещё хорошие значения. Но даже если AST будет готово секунды через три-четыре после запуска встроенного парсера — это уже долго. При том условии, что такие запуски должны быть как регулярными (поддерживать модель кода и индекс в консистентном состоянии, подсвечивать, подсказывать и т. п.), а также по требованию — ведь code completion это тоже запуск компилятора. Можно ли как-то уменьшить это время? К сожалению, в случае использования clang в качестве парсера возможностей не так много. Причина: это thirdparty tool в который (в идеале) изменения вносить нельзя. То есть покопаться в коде clang'а perftool'ом, пооптимизировать, упросить какие-нибудь ветки — эти возможности недоступны и приходится обходиться тем, что предоставляет внешнее API (в случае использования libclang — оно ещё и достаточно узкое).
Первое, очевидное, и, на самом деле, единственное решение — это использовать динамически генерируемые precompiled headers. При адекватной реализации решение — убойное. Повышает скорость компиляции в разы как минимум. Суть его проста: среда собирает в один .h-файл все thirdparty-заголовки (или заголовки за пределами project root), делает из этого файла pch, после чего неявно включает этот pch в каждый исходник. Разумеется, появляется очевидный сайдеэффект: в исходниках (на этапе редактирования) могут быть видны символы, которые в него не include'ятся. Но это плата за скорость. Приходится выбирать. И всё было бы прекрасно, если бы не одна маленькая проблемка: clang это таки компилятор. И, будучи компилятором, он не любит ошибки в коде. И если вдруг (внезапно! — см. предыдущий раздел) в заголовках находятся ошибки, то .pch-файл не создаётся. По крайней мере так было вплоть до версии 3.7. Изменилось ли что-то с тех пор в этом отношении? Не знаю, есть подозрение, что нет. Возможности проверить тоже увы, уже нет.
Альтернативные варианты увы, недоступны всё по той же причине: clang — это компилятор и вещь "в себе". Активно вмешаться в процесс генерации AST, каким-либо образом заставить его мерджить AST из разных кусков, вести внешние базы символов и тэ дэ и тэ пэ — увы, все эти возможности недоступны. Только внешнее API, только хардкор и настройки, доступные через опции компиляции. А потом анализ результирующей AST. Если садиться на C++-версию API, то возможностей становится доступно чуть больше. Например, можно поиграться с кастомными FrontendAction'ами, сделать более тонкую настройку опций компиляции и т. п. Но и в данном случае основная суть не изменится — редактируемый (или индексируемый) текст будет откомпилирован независимо от других и полностью. Всё. Точка.
Возможно (возможно!) когда-нибудь появится форк апстрима clang'а, специально заточенный на использование в составе IDE. Возможно. Но пока что всё так, как оно есть. Скажем, у команды Qt Creator'а интеграция (до стадии "окончательно") с libclang'ом заняла семь лет. Я попробовал QtC 4.7 с движком на базе libclang — признаюсь, старый вариант (на самописном) лично мне нравится больше, просто потому, что на моих кейсах он работает лучше: и подсказывает, и подсвечивает, и всё остальное. Не возьмусь оценивать, сколько человекочасов они на эту интеграцию потратили, но рискну предположить, что за это время можно было бы свой собственный парсер допилить. Насколько я могу судить (по косвенным признакам), команда, работающая над CLion, в сторону интеграции с libclang/clang++ смотрит с опаской. Но это сугубо личные предположения. Интеграция на уровне Language Server Protocol — интересный вариант, но конкретно для случая C++ я склонен рассматривать это больше как паллиатив по перечисленным выше причинам. Просто переносит проблемы с одного уровня абстракции на другой. Но, возможно, я ошибаюсь и за LSP — будущее. Посмотрим. Но так или иначе, жизнь разработчиков современных IDE для C++ полна приключений — с clang'ом в качестве бэкенда, или без него.
Комментариев нет:
Отправить комментарий