Вступление
В последнее время активно изучаю язык программирования Python. Особенно меня заинтересовало использование Python в распознавании и классификации лиц. В статье я попробую применить распознавание лиц для сериала «Теория Большого взрыва».

Сериал повествует о жизни двух молодых талантливых физиков (Шелдон Купер и Леонард Хофстедтер), их привлекательной соседке по лестничной площадке, официантке и начинающей актрисе — Пенни, а также об их друзьях — астрофизике Раджеше Кутраппали и инженере Говарде Воловице. Действие сериала происходит в городе Пасадена, штат Калифорния. На данный момент снято 265 серий (12 сезонах).
Рейтинг IMDB — 8.2.
Я — непрофессиональный программист. Программирование — моё хобби. Весь код ужасен, но я учусь и стараюсь сделать его лучше.
В качестве инструмента для распознавания и классификации лиц использовал Face Recognition Project on MXNet.
In this repository, we provide training data, network settings and loss designs for deep face recognition. The training data includes the normalised MS1M and VGG2 datasets, which were already packed in the MxNet binary format. The network backbones include ResNet, InceptionResNet_v2, DenseNet, DPN and MobileNet. The loss functions include Softmax, SphereFace, CosineFace, ArcFace and Triplet (Euclidean/Angular) Loss.
Также к нему необходимы предобученные модели Face Recognition models и Gender-Age model(для определения пола и возраста).
Остальной инструментарий:
- ноутбук (Intel Core i5-7200, NVIDIA GeForce 940MX 2Gb, 8 Gb DDR4 RAM, операционная система Manjaro KDE);
- Python 3;
- CUDA Toolkit 10.0;
- mxnet с поддержкой CUDA;
- tensorflow с поддержкой CUDA;
- opencv;
- pandas;
- скачанный полностью сериал «Теория Большого взрыва» (265 серий).
Большинство дополнительных пакетов для Python устанавливается командой:
pip install имя_пакета
Этап 1. Подготовительный
Для классификации необходимо создать подборку изображений лиц(разных по ракурсу, сезону) по каждому интересующему нас персонажу. Для этого взял буквально первый попавшийся ролик из Youtube по запросу «смешные моменты теории большого взрыва». C помощью opencv извлек изображения из видеоролика с интервалом в 1 секунду, вручную отобрал их и переименовал с помощью скрипта по персонажам.

Дальше с помощью нейронной сети и использованию предобученной модели прошелся по всем отобранным изображениям. Из каждого обнаруженного лица извлекается 512-мерное векторное представление, которое его характеризует. Данное представление и имя персонажа сохраняется в pandas.dataframe.
for filename in glob.glob('knownimage/*.jpg'):
img = cv2.imread(filename)
ret = detector.detect_face(img, det_type=0)
if ret is not None:
bbbox, points = ret
#draw = img.copy()
for inum, bbox in enumerate(bbbox):
bbox = bbox[0:4]
#cv2.rectangle(draw, (int(bbox[0]), int(bbox[1])), (int(bbox[2]), int(bbox[3])), (255, 255, 255))
pp = points[inum]
pp = pp.reshape((2, 5)).T
# print(bbox)
# print(points)
nimg = preprocess(img, bbox, pp, image_size='112,112')
nimg = cv2.cvtColor(nimg, cv2.COLOR_BGR2RGB)
aligned = np.transpose(nimg, (2, 0, 1))
f1 = get_feature(mmodel, aligned)
df = df.append({'name': filename.split('.')[0], 'np': f1}, ignore_index=True)
df.to_pickle('known.pkl')
Для 24 главных и второстепенных персонажей сериала было отобрано 382 файла.
- Говард Джоэл Воловиц(govard, здесь и далее в скобках указано имя персонажа в системе распознования лиц) — инженер аэрокосмических систем, муж Бернадетт Ростенковски-Воловиц, отец Хэлли Воловиц, лучший друг Раджеша Кутраппали. Окончил Массачусетский технологический институт.
- Доктор Раджеш Рамаян Кутраппали(rajesh) — астрофизик из Индии, лучший друг Говарда Воловица.
- Прия Кутраппали(priya) — младшая сестра Раджа, дочь доктора и миссис Кутраппали.
- Пенни Хофстедтер(penny) — жена Леонарда Хофстедтера, торговый представитель фармацевтической компании.
- Доктор Бернадетт Мэриэнн Ростенковски-Воловиц(bernaded) — микробиолог, жена Говарда Воловица, мать Хэлли Воловиц и Майкла Воловиц.
- Доктор Беверли Хофстедтер(mama_leonarda) — мать Леонарда Хофстедтера, психиатр и нейробиолог
- Леонард Лики Хофстедтер(leonard) — физик-экспериментатор, сотрудник Калифорнийского технологического института, обладатель докторской степени.
- Доктор Лесли Уинкл(lesly) — сотрудница Калифорнийского университета, работающая вместе с Леонардом Хофстедтером.
- Доктор Шелдон Ли Купер(sheldon) — физик-теоретик, работающий в Калифорнийском технологическом институте. У него несколько учёных степеней, включая степень доктора наук.
- Мелисса «Мисси» Купер(sestra_sheldona) — сестра-близнец Шелдона Купера.
- Мэри Купер(mama_sheldona) — мать Шелдона Купера.
- Доктор Эми Фарра Фаулер(emmy) — нейробиолог, жена Шелдона Купера.
- Уил Уитон(will) — актёр сериала «Стар Трек: Новое Поколение», которого Шелдон считал своим злейшим врагом.
- Стюарт Дэвид Блум(stuart) — владелец магазина комиксов, после пожара ставший безработным и переехавший жить к Говарду Воловицу.
- Доктор В. М. Кутраппали(papa_rajesh) — отец Раджеша Кутраппали.
- Барри Крипке(barry) — коллега главных героев по университету.
- Рамона Новицки(navitsky) — аспирантка кафедры физики.
- Доктор Гейблхаузер(geibelhauser) — новый глава факультета физики.
- Зак(bivshiy_penny) — бывший парень Пенни.
- Миссис Кутраппали(mama_rajesh) — мать Раджеша Кутраппали.
- Dr. Stephanie Barnett(medik_leonarda) — одна из девушек Леонарда.
Этап 2. Обработка видео
Теперь начинаем обрабатывать весь сериал. С помощью opencv из каждого видео извлекаем 1 кадр в секунду, находим на нем лица. Для этих лиц получаем 512-мерное векторное представление, которое его характеризует и сравниваем с той базой, которую мы получили на предыдущем этапе. Также определяем предположительный возраст и пол.
Для каждого найденного и классифицированного лица в csv файл сохраняем имя, пол, возраст, номер кадра, серия, сезон. Обнаруженные, но не классифицированные лица сохраняем в отдельную директорию.
Обработка всех серий заняла ~30 часов, извлечено 263775 кадров, классифицировано 353031 лиц персонажей. Обработка одного кадра занимает от 0.2 до 1 секунды в зависимости от количества лиц. В папке с неклассифицированными лицами — ~ 20000 лиц (т.е. 6%). Это в основном массовка, редкие персонажи или неудачный ракурс основных героев сериала.


home_video = '/run/media/home/DATA/torrent/The.Big.Bang.Theory/'
all_series = (len(glob.glob(home_video+'*.avi')))
now_series = 0
for filename1 in glob.glob(home_video+'*.avi'):
now_series = now_series + 1
print(filename1)
cam = cv2.VideoCapture(filename1)
fps = cam.get(cv2.CAP_PROP_FPS) # Gets the frames per second
fps = fps
#print(fps)
total_frames = cam.get(7)
#print(total_frames)
rer = round(total_frames/fps)
for kk in range(0,rer):
#while True:
start_time = time.time()
cam.set(1, round(kk*fps))
ret_val, img = cam.read()
scale_percent = 170 # percent of original size
width = int(img.shape[1] * scale_percent / 100)
height = int(img.shape[0] * scale_percent / 100)
dim = (width, height)
# resize image
img = cv2.resize(img, dim, interpolation=cv2.INTER_AREA)
#print(ret_val)
#img, draw = get_input(detector,img)
ret = detector.detect_face(img, det_type = 0)
if ret is not None:
bbbox, points = ret
draw = img.copy()
for inum,bbox in enumerate(bbbox):
bbox = bbox[0:4]
pp = points[inum]
pp = pp.reshape((2,5)).T
#print(bbox)
#print(points)
nimg = preprocess(img, bbox, pp, image_size='112,112')
nimg = cv2.cvtColor(nimg, cv2.COLOR_BGR2RGB)
aligned = np.transpose(nimg, (2,0,1))
f1 = get_feature(mmodel,aligned)
for index, row in df.iterrows():
np1 = row['np']
name = row['name']
dist = np.sum(np.square(np1 - f1))
if dist<1.1:
#print(name, dist)
dd = dist
nnn = name.split('/')[1]
break
else:
nnn = 'None'
dd = dist
if (nnn=='None') and (int(bbox[3])-int(bbox[1]))>112:
crop_img = draw[int(bbox[1]):int(bbox[3]), int(bbox[0]):int(bbox[2])]
cv2.imwrite('unknown/' + str(int(time.time())) + '.jpg', crop_img)
#cv2.rectangle(draw, (int(bbox[0]), int(bbox[1])), (int(bbox[2]), int(bbox[3])), (255, 255, 255))
if (nnn != 'None'):
gender, age =3, 100
gender, age = get_ga(mga_model,aligned)
font = cv2.FONT_HERSHEY_SIMPLEX
bottomLeftCornerOfText = (10, 20)
fontScale = 1
fontColor = (255, 255, 255)
lineType = 2
cv2.putText(draw, nnn + ' ' + str(round(dd, 2)),
(int(bbox[0]), int(bbox[1])),
font,
fontScale,
fontColor,
lineType)
# with open('test_10_1.txt', "a") as myfile:
# myfile.write(name + ';' + str(kk) + ';' + str(age)+';'+str(gender)+';'+ str(dist) + ';' + filename1 + '\n')
else:
gender, age = 3, 100
if cv2.waitKey(1) == 27:
#df.to_pickle('test.pkl')
print('exit')
cv2.destroyAllWindows()
#break # esc to quit
quit()
cv2.imshow("detection result", draw)
tt =round(time.time() - start_time,2)
print('Обработано '+ str(kk) + '/'+str(rer) + ' > '+str(now_series)+'/'+str(all_series)+'; ' + 'время на кадр: '+str(tt)+'; ~~'+str(round((rer*tt)*(all_series-now_series)/60))+'м', end= "\r")
Этап 3. Небольшой анализ
В начале хотел использовать для анализа полученных данных Pandas, но, к сожалению, я его не освоил в нужной степени. На просторах Интернета была найдена программа Falcon SQL Client, в которую и были загружены все полученные данные. Также обращаю внимание, что 12 сезон не снят до конца.
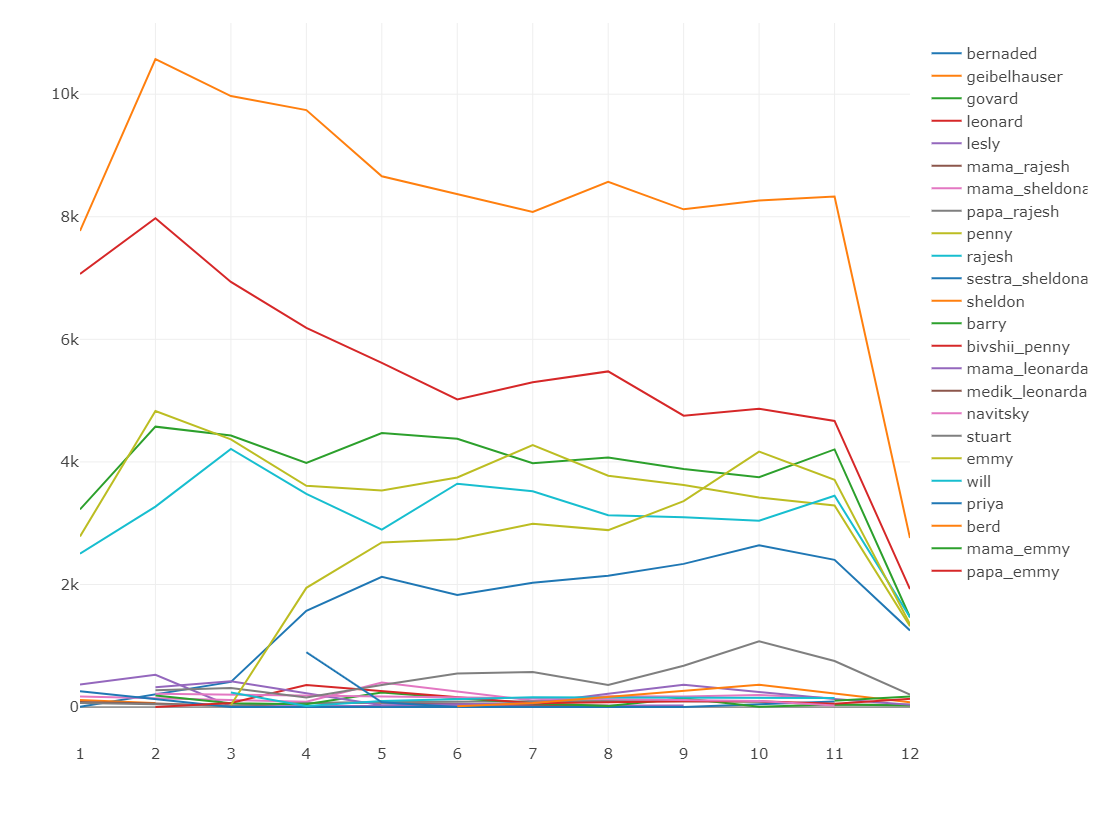
На рисунке ниже представлен график количества кадров с основными и второстепеннными персонажами по сезонам. Здесь явно видно, что уменьшается доля Шелдона и Леонарда, но растет роль Бернадед и Эмми.
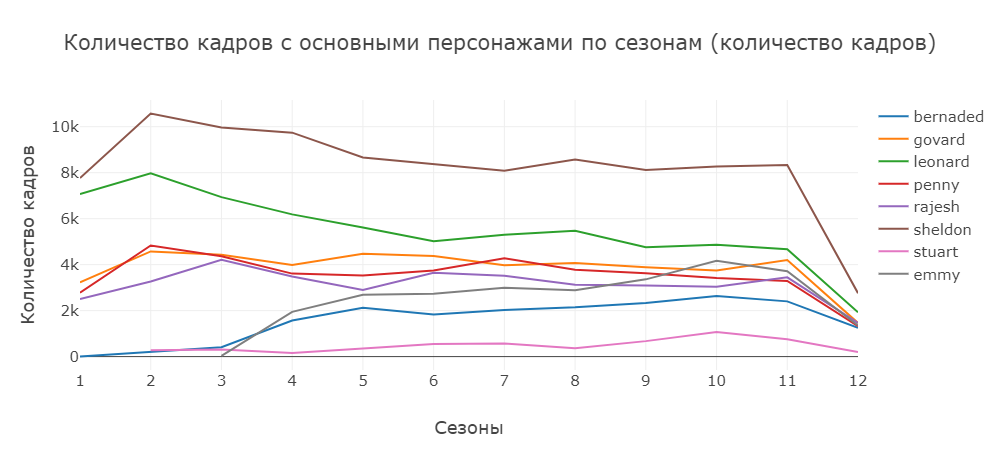
Здесь отдельно вынесены главные герои сериалы.
Главные герои сериала в процентном соотношении. Явный лидер — Шелдон Купер.

Я предположил, что появление «пары» в сериале должно коррелировать с совместным появлением в кадре, т.е. чем более близкие отношения — тем чаще появляются вместе в одном кадре. Был построен график для «пар»: Леонард — Пенни, Леонард — Шелдон, Шелдон — Эмми, Говард — Раджеш, Говард — Бернадед.

На графике явно видны зависимости. Давайте отдельно расмотрим «пары» Леонард — Пенни и Леонард — Шелдон.

Мы видим, что по мере развития отношении у Леонарда и Пенни, Шелдон все больше остается в «пролете». Также точно известно, что Пенни и Леонард начинают встречаться в 3 сезоне, что также видно на графике.
Рассмотрим отдельно Шелдон-Эмми и Шелдон-Леонард.

Пик развития отношений Шелдон-Эмми приходится на 10 сезон, что мы и видим на графике.
Следующие пару «пар», которую рассмотрим отдельно — Говард-Эмми и Говард-Раджеш.
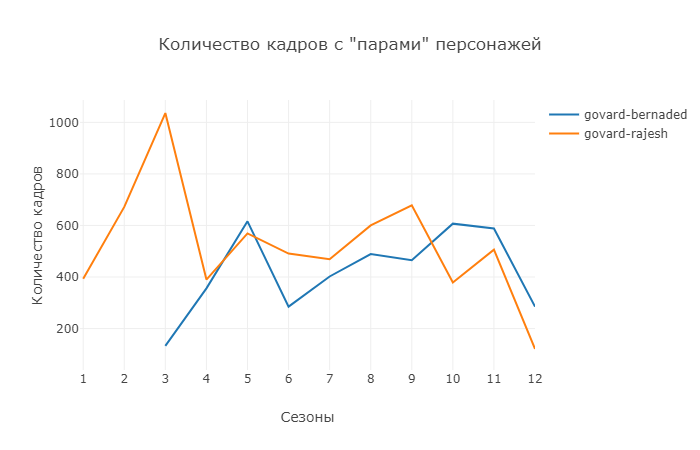
Судя по этому графику, «крепкую мужскую дружбу» никто не разрушит и Раджеш продолжает свое общение с Говардом. Также отмечаем, что пик отношений Говард-Бернадед приходится на 5 сезон (в этом сезоне у них подготовка и сама свадьба).
Теперь проверим как работает предобученная модель по определению возраста и пола. Начнем с возраста: я взял для каждого главного героя средний возраст в эпизоде и вынес в отдельную таблицу(в скобках указан реальный возраст героя на момент съемок сезона).

Видно, что макияж, правильный свет и постобработка делает свое дело и нейронная сеть плохо справляется с определением возраста. Однако, она обнаруживает рост возраста с каждым следующим сезоном.
Посмотрим на определение пола для основных героев (ближе к 1 — мужской, к 0 — женский).

Здесь нейронная сеть справляется гораздо лучше и показывает результаты, близкие к реальным. Только с Эмми результат немного подозрительный.
Мне показалось интересным использовать нейронную сеть для обнаружения и классификации лиц. Видно, что она не обеспечивает 100% точность, но этого и не должно быть. В дальнейшем думаю упростить этап создания первоначальной выборки, используя поиск по картинке в Интернете и использование данного проекта в видеонаблюдении.
Спасибо за внимание.
Комментариев нет:
Отправить комментарий