Это руководство охватывает лучшие практики и рекомендуемую архитектуру для создания надежных приложений. Эта страница предполагает базовое знакомство с Android Framework. Если вы новичок в разработке приложений для Android, ознакомьтесь с нашими руководствами для разработчиков, чтобы начать работу и узнать больше о концепциях, упомянутых в этом руководстве. Если вы интересуетесь архитектурой приложений и хотели бы ознакомиться с материалами этого руководства с точки зрения программирования на Kotlin, ознакомьтесь с курсом Udacity «Разработка приложений для Android с помощью Kotlin».
Опыт пользователя мобильного приложения
В большинстве случаев настольные приложения имеют единую точку входа с рабочего стола или программы запуска, а затем запускаются как единый монолитный процесс. Приложения на Android имеют гораздо более сложную структуру. Типичное приложение для Android содержит несколько компонентов приложения, включая Activities, Fragments, Services, ContentProviders и BroadcastReceivers.
Вы объявляете все или некоторые из этих компонентов приложения в манифесте приложения. Затем ОС Android использует этот файл, чтобы решить, как интегрировать ваше приложение в общий пользовательский интерфейс устройства. Учитывая, что правильно написанное приложение Android содержит несколько компонентов, и пользователи часто взаимодействуют с несколькими приложениями за короткий промежуток времени, приложения должны адаптироваться к различным типам рабочих процессов и задач, управляемых пользователями.
Например, рассмотрим, что происходит, когда вы делитесь фотографией в своем любимом приложении для социальных сетей:
- Приложение вызывает намерение (Intent) камеры. Android запускает приложение камеры для обработки запроса. На данный момент пользователь покинул приложение для социальных сетей, и его опыт как пользователя безупречен.
- Приложение камеры может вызывать другие намерения, например запуск средства выбора файлов, которое может запустить еще одно приложение.
- В конце концов, пользователь возвращается в приложение социальной сети и делится фотографией.
В любой момент процесса пользователь может быть прерван телефонным звонком или уведомлением. После действия, связанного с этим прерыванием, пользователь ожидает, что сможет вернуться и возобновить этот процесс обмена фотографиями. Такое поведение переключения приложений распространено на мобильных устройствах, поэтому ваше приложение должно правильно обрабатывать эти моменты (задачи).
Помните, что мобильные устройства также ограничены в ресурсах, поэтому в любой момент операционная система может уничтожить некоторые процессы приложения, чтобы освободить место для новых.
Учитывая условия этой среды, компоненты вашего приложения могут запускаться по отдельности и не по порядку, а операционная система или пользователь могут уничтожить их в любое время. Поскольку эти события не находятся под вашим контролем, вы не должны хранить какие-либо данные или состояния в ваших компонентах приложения, и ваши компоненты приложения не должны зависеть друг от друга.
Общие архитектурные принципы
Если вы не должны использовать компоненты приложения для хранения данных и состояния приложения, как вы должны разрабатывать свое приложение?
Разделение ответственности
Самый важный принцип, которому нужно следовать, — это разделение ответственности. Распространена ошибка, когда вы пишете весь свой код в Activity или Fragment. Это классы пользовательского интерфейса которые должны содержать только логику обрабатывающую взаимодействие пользовательского интерфейса и операционной системы. Как можно больше разделяя ответственность в этих классах (SRP), вы можете избежать многих проблем, связанных с жизненным циклом приложения.
Управление пользовательским интерфейсом из модели
Другой важный принцип заключается в том, что вы должны управлять своим пользовательским интерфейсом из модели, предпочтительнее из постоянной модели. Модели — это компоненты, которые отвечают за обработку данных для приложения. Они не зависят от объектов View и компонентов приложения, поэтому на них не влияют жизненный цикл приложения и связанные с ним проблемы.
Постоянная модель идеально подходит по следующим причинам:
- Ваши пользователи не потеряют данные, если ОС Android уничтожит ваше приложение, чтобы освободить ресурсы.
- Ваше приложение продолжает работать в тех случаях, когда сетевое соединение нестабильно или недоступно.
Организовывая основу вашего приложение на модельных классах с четко определенной ответственностью по управлению данными, ваше приложение становится более тестируемым и поддерживаемым.
Рекомендуемая архитектура приложения
Этот раздел демонстрирует как структурировать приложение, используя компоненты архитектуры, работая в сквозном сценарии использования.
Примечание. Невозможно иметь один способ написания приложений, который лучше всего подходит для каждого сценария. При этом рекомендованная архитектура является хорошей отправной точкой для большинства ситуаций и рабочих процессов. Если у вас уже есть хороший способ написания приложений для Android, соответствующий общим архитектурным принципам, менять его не стоит.
Представьте, что мы создаем пользовательский интерфейс, который показывает профиль пользователя. Мы используем приватный API и REST API для извлечения данных профиля.
Обзор
Для начала рассмотрим схему взаимодействия модулей архитектуры готового приложения:
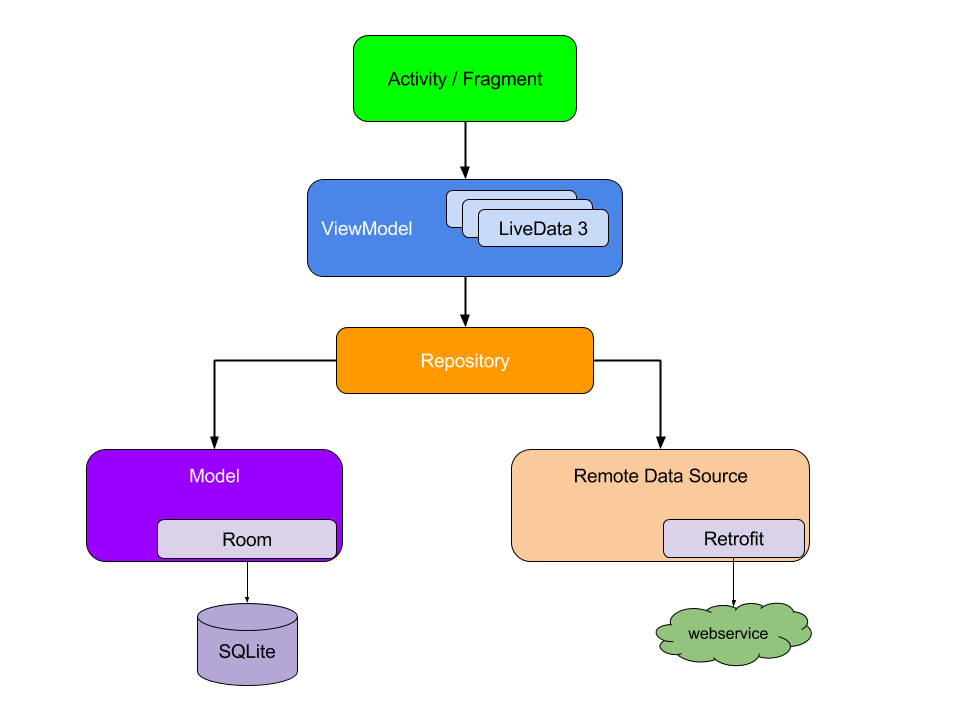
Обратите внимание, что каждый компонент зависит только от компонента на один уровень ниже его. Например, Activity и Fragments зависят только от модели представления. Repository является единственным классом, который зависит от множества других классов; в этом примере хранилище зависит от постоянной модели данных и удаленного внутреннего источника данных.
Этот дизайн паттерн создает последовательный и приятный пользовательский опыт. Независимо от того, вернется пользователь к приложению через несколько минут после его закрытия или спустя несколько дней, он мгновенно увидит информацию пользователя о том, что приложение сохраняется локально. Если эти данные устарели, модуль хранилища приложения начинает обновлять данные в фоновом режиме.
Создаём пользовательский интерфейс
Пользовательский интерфейс состоит из фрагмента
UserProfileFragment и соответствующего ему файла макета user_profile_layout.xml.
Для управления пользовательским интерфейсом наша модель данных должна содержать следующие элементы данных:
- User ID: идентификатор пользователя. Лучшим решением является передача этой информации во фрагмент, используя аргументы фрагмента. Если ОС Android разрушает наш процесс, эта информация сохраняется, поэтому идентификатор будет доступен при следующем запуске нашего приложения.
- User object: класс данных, который содержит сведения о пользователе.
Мы используем
UserProfileViewModel, основанный на компоненте архитектуры ViewModel, чтобы сохранить эту информацию.
Объект ViewModel предоставляет данные для определенного компонента пользовательского интерфейса, таких как fragment или Activity, и содержит бизнес-логику обработки данных для взаимодействия с моделью. Например, ViewModel может вызывать другие компоненты для загрузки данных и может пересылать запросы пользователей на изменение данных. ViewModel не знает о компонентах пользовательского интерфейса, поэтому на него не влияют изменения конфигурации, такие как воссоздание Activity при повороте устройства.
Теперь мы определили следующие файлы:
user_profile.xml: определили макет пользовательского интерфейса.UserProfileFragment: описали контроллер пользовательского интерфейса, который отвечает за отображение информации пользователю.UserProfileViewModel: класс отвечающий за приготовление данных для отображения их вUserProfileFragmentи реагирует на взаимодействие с пользователем.
В следующих фрагментах кода показано начальное содержимое этих файлов. (Файл макета опущен для простоты.)
class UserProfileViewModel : ViewModel() {
val userId : String = TODO()
val user : User = TODO()
}
class UserProfileFragment : Fragment() {
private val viewModel: UserProfileViewModel by viewModels()
override fun onCreateView(
inflater: LayoutInflater, container: ViewGroup?,
savedInstanceState: Bundle?
): View {
return inflater.inflate(R.layout.main_fragment, container, false)
}
}
Теперь, когда у нас есть эти модули кода, как мы их соединяем? После того как пользовательское поле установлено в классе UserProfileViewModel, нам нужен способ информировать пользовательский интерфейс.
Примечание. SavedStateHandle позволяет ViewModel получить доступ к сохраненному состоянию и аргументам связанного фрагмента или действия.
// UserProfileViewModel
class UserProfileViewModel(
savedStateHandle: SavedStateHandle
) : ViewModel() {
val userId : String = savedStateHandle["uid"] ?:
throw IllegalArgumentException("missing user id")
val user : User = TODO()
}
// UserProfileFragment
private val viewModel: UserProfileViewModel by viewModels(
factoryProducer = { SavedStateVMFactory(this) }
...
)
Теперь нам нужно сообщить нашему Фрагменту, когда получен пользовательский объект. Вот тут-то и появляется компонент архитектуры LiveData.
LiveData — это наблюдаемый держатель данных. Другие компоненты в вашем приложении могут отслеживать изменения объектов, используя этот держатель, не создавая явных и жестких путей зависимости между ними. Компонент LiveData также учитывает состояние жизненного цикла компонентов вашего приложения, таких как Activities, Fragments и Services, и включает логику очистки для предотвращения утечки объектов и чрезмерного потребления памяти.
Примечание. Если вы уже используете такие библиотеки, как RxJava или Agera, вы можете продолжать использовать их вместо LiveData. Однако при использовании библиотек и подобных подходов убедитесь, что вы правильно обрабатываете жизненный цикл своего приложения. В частности, убедитесь, что вы приостановили свои потоки данных, когда связанный LifecycleOwner остановлен, и уничтожили эти потоки, когда связанный LifecycleOwner был уничтожен. Вы также можете добавить артефакт android.arch.lifecycle: реактивные потоки, чтобы использовать LiveData с другой библиотекой реактивных потоков, такой как RxJava2.
Чтобы включить компонент LiveData в наше приложение, мы меняем тип поля в UserProfileViewModel на LiveData . Теперь UserProfileFragment информируется об обновлении данных. Кроме того, поскольку это поле LiveData поддерживает жизненный цикл, оно автоматически очищает ссылки, когда они больше не нужны.
class UserProfileViewModel(
savedStateHandle: SavedStateHandle
) : ViewModel() {
val userId : String = savedStateHandle["uid"] ?:
throw IllegalArgumentException("missing user id")
val user : LiveData<User> = TODO()
}
Теперь модифицируем
UserProfileFragment для наблюдения за данными во ViewModel и для обновления пользовательского интерфейса в соответствии с изменениями:
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
viewModel.user.observe(viewLifecycleOwner) {
// обновляем UI
}
}
Каждый раз, когда данные профиля пользователя обновляются, вызывается обратный вызов onChanged(), и пользовательский интерфейс обновляется.
Если вы знакомы с другими библиотеками, в которых используются наблюдаемые обратные вызовы, возможно, вы поняли, что мы не переопределили метод onStop() фрагмента, чтобы прекратить наблюдать за данными. Этот шаг не является обязательным для LiveData, поскольку он поддерживает жизненный цикл, это означает, что он не вызовет обратный вызов onChanged(), если фрагмент находится в неактивном состоянии; то есть он получил вызовonStart(), но еще не получил onStop()). LiveData также автоматически удаляет наблюдателя при вызове метода onDestroy() у фрагмента.
Мы не добавили никакой логики для обработки изменений конфигурации, таких как поворот экрана устройства пользователем. UserProfileViewModel автоматически восстанавливается при изменении конфигурации, поэтому, как только создается новый фрагмент, он получает тот же экземпляр ViewModel, и обратный вызов вызывается немедленно с использованием текущих данных. Учитывая, что объекты ViewModel предназначены для того, чтобы пережить соответствующие объекты View, которые они обновляют, вы не должны включать прямые ссылки на объекты View в вашу реализацию ViewModel. Для получения дополнительной информации о сроке службы ViewModel соответствует жизненному циклу компонентов пользовательского интерфейса, см. Жизненный цикл ViewModel.
Получение данных
Теперь, когда мы использовали LiveData для подключения
UserProfileViewModel к UserProfileFragment, как мы можем получить данные профиля пользователя?
В этом примере мы предполагаем, что наш backend предоставляет REST API. Мы используем библиотеку Retrofit для доступа к нашему backend, хотя вы можете использовать другую библиотеку, которая служит той же цели.
Вот наше определение Webservice , который связывается с нашим backend-ом:
interface Webservice {
/**
* @GET declares an HTTP GET request
* @Path("user") annotation on the userId parameter marks it as a
* replacement for the {user} placeholder in the @GET path
*/
@GET("/users/{user}")
fun getUser(@Path("user") userId: String): Call<User>
}
Первая идея для реализации
ViewModel может включать прямой вызов Webservice для извлечения данных и назначения этих данных нашему объекту LiveData. Этот дизайн работает, но с его использованием наше приложение становится все сложнее поддерживать по мере роста. Это дает слишком большую ответственность классу UserProfileViewModel, что нарушает принцип разделения интересов. Кроме того, область действия ViewModel связана с жизненным циклом Activity или Fragment, что означает, что данные из Webservice теряются, когда заканчивается жизненный цикл связанного объекта пользовательского интерфейса. Такое поведение создает нежелательный пользовательский опыт.
Вместо этого наша ViewModel делегирует процесс извлечения данных новому модулю, хранилищу.
Модули репозитория обрабатывают операции с данными. Они предоставляют чистый API, так что остальная часть приложения может легко получить эти данные. Они знают, откуда взять данные и какие вызовы API следует выполнять при обновлении данных. Вы можете рассматривать репозитории как посредники между различными источниками данных, такими как постоянные модели, веб-службы и кэши.
Наш класс UserRepository, показанный в следующем фрагменте кода, использует экземпляр WebService для извлечения данных пользователя:
class UserRepository {
private val webservice: Webservice = TODO()
// ...
fun getUser(userId: String): LiveData<User> {
// Это не оптимальная реализация. Мы исправим это позже.
val data = MutableLiveData<User>()
webservice.getUser(userId).enqueue(object : Callback<User> {
override fun onResponse(call: Call<User>, response: Response<User>) {
data.value = response.body()
}
// Случай ошибки опущен для краткости.
override fun onFailure(call: Call<User>, t: Throwable) {
TODO()
}
})
return data
}
}
Хотя модуль хранилища выглядит ненужным, он служит важной цели: он абстрагирует источники данных от остальной части приложения. Теперь наш
UserProfileViewModel не знает, как извлекаются данные, поэтому мы можем предоставить модели представления данные, полученные из нескольких различных реализаций извлечения данных.
Примечание. Мы упустили случай сетевых ошибок для простоты. Для альтернативной реализации, которая выставляет ошибки и статус загрузки, см. Приложение: раскрытие статуса сети.
Управление зависимостями между компонентами
Классу UserRepository выше необходим экземпляр Webservice для извлечения данных пользователя. Он мог бы просто создать экземпляр, но для этого ему также необходимо знать зависимости класса Webservice. Кроме того, UserRepository, вероятно, не единственный класс, которому нужен веб-сервис. Эта ситуация требует от нас дублирования кода, поскольку каждый класс, которому нужна ссылка на Webservice, должен знать, как его создать и его зависимости. Если каждый класс создает новый WebService, наше приложение может стать очень ресурсоемким.
Для решения этой проблемы вы можете использовать следующие шаблоны проектирования:
- Внедрение зависимостей (DI). Внедрение зависимостей позволяет классам определять свои зависимости, не создавая их. Во время выполнения, другой класс отвечает за предоставление этих зависимостей. Мы рекомендуем библиотеку Dagger 2 для реализации внедрения зависимостей в приложениях Android. Dagger 2 автоматически создает объекты, обходя дерево зависимостей, и обеспечивает гарантии времени компиляции для зависимостей.
- (Service location) Локатор службы: шаблон локатора службы предоставляет реестр, в котором классы могут получать свои зависимости вместо их построения.
Реализовать реестр служб проще, чем использовать DI, поэтому, если вы не знакомы с DI, вместо этого используйте шаблон: локация служб.
Эти шаблоны позволяют вам масштабировать ваш код, потому что они предоставляют четкие шаблоны для управления зависимостями без дублирования или усложнения кода. Кроме того, эти шаблоны позволяют быстро переключаться между тестовыми и производственными реализациями выборки данных.
В нашем примере приложения используется Dagger 2 для управления зависимостями объекта Webservice.
Подключите ViewModel и хранилище
Теперь мы модифицируем наш
UserProfileViewModel для использования объекта UserRepository:
class UserProfileViewModel @Inject constructor(
savedStateHandle: SavedStateHandle,
userRepository: UserRepository
) : ViewModel() {
val userId : String = savedStateHandle["uid"] ?:
throw IllegalArgumentException("missing user id")
val user : LiveData<User> = userRepository.getUser(userId)
}
Кеширование
Реализация
UserRepository абстрагирует вызов объекта Webservice, но поскольку он опирается только на один источник данных, он не очень гибок.
Основная проблема с реализацией UserRepository заключается в том, что после получения данных из нашего бэкэнда эти данные нигде не хранятся. Поэтому, если пользователь покидает UserProfileFragment, а затем возвращается к нему, наше приложение должно повторно извлечь данные, даже если они не изменились.
Эта конструкция является неоптимальной по следующим причинам:
- Это тратит ценные ресурсы трафика.
- Это заставляет пользователя ожидать завершения нового запроса.
Чтобы устранить эти недостатки, мы добавляем новый источник данных в наш
UserRepository, который кэширует объекты User в памяти:
//Информируем Dagger, что этот класс должен быть создан только единожды.
@Singleton
class UserRepository @Inject constructor(
private val webservice: Webservice,
// Простой кэш в памяти. Детали опущены для краткости.
private val userCache: UserCache
) {
fun getUser(userId: String): LiveData<User> {
val cached = userCache.get(userId)
if (cached != null) {
return cached
}
val data = MutableLiveData<User>()
userCache.put(userId, data)
// Эта реализация все еще неоптимальная, но лучше, чем раньше.
// Полная реализация также обрабатывает случаи ошибок.
webservice.getUser(userId).enqueue(object : Callback<User> {
override fun onResponse(call: Call<User>, response: Response<User>) {
data.value = response.body()
}
// Случай ошибки опущен для краткости.
override fun onFailure(call: Call<User>, t: Throwable) {
TODO()
}
})
return data
}
}
Постоянные данные
Используя нашу текущую реализацию, если пользователь поворачивает устройство или уходит и немедленно возвращается в приложение, существующий пользовательский интерфейс становится видимым мгновенно, потому что хранилище извлекает данные из нашего кеша в памяти.
Тем не менее, что произойдет, если пользователь покинет приложение и вернется через несколько часов после того, как ОС Android завершит процесс? Полагаясь на нашу текущую реализацию в этой ситуации, нам нужно снова получить данные из сети. Этот процесс обновления не просто плохой пользовательский опыт; это также расточительно, потому что он потребляет ценные мобильные данные.
Вы можете решить эту проблему, кэшируя веб-запросы, но это создает ключевую новую проблему: что произойдет, если те же пользовательские данные будут отображены в запросе другого типа, например при получении списка друзей? Приложение будет отображать противоречивые данные, что в лучшем случае сбивает с толку. Например, наше приложение может отображать две разные версии данных одного и того же пользователя, если пользователь отправлял запрос списка друзей и однопользовательский запрос в разное время. Наше приложение должно было бы выяснить, как объединить эти противоречивые данные.
Правильный способ справиться с этой ситуацией — использовать постоянную модель. Нам на помощь приходит библиотека сохранения постоянных данных (БД) Room.
Room — это библиотека объектно-реляционного отображения (object-mapping), которая обеспечивает локальное сохранение данных с минимальным стандартным кодом. Во время компиляции он проверяет каждый запрос на соответствие вашей схеме данных, поэтому неработающие запросы SQL приводят к ошибкам во время компиляции, а не к сбоям во время выполнения. Room абстрагируется от некоторых базовых деталей реализации работы с необработанными таблицами SQL и запросами. Это также позволяет вам наблюдать за изменениями в данных БД, включая коллекции и запросы на соединение, выставляя такие изменения с помощью объектов LiveData. Он даже явно определяет ограничения выполнения, которые решают общие проблемы с потоками, такие как доступ к хранилищу в основном потоке.
Примечание. Если ваше приложение уже использует другое решение, такое как объектно-реляционное отображение SQLite (ORM), вам не нужно заменять существующее решение на Room. Однако, если вы пишете новое приложение или реорганизуете существующее приложение, мы рекомендуем использовать Room для сохранения данных вашего приложения. Таким образом, вы можете воспользоваться возможностями абстракции библиотеки и проверки запросов.
Чтобы использовать Room, нам нужно определить нашу локальную схему. Сначала мы добавляем аннотацию @Entity в наш класс модели данных User и аннотацию @PrimaryKey в поле id класса. Эти аннотации помечают User как таблицу в нашей базе данных, а id — как первичный ключ таблицы:
@Entity
data class User(
@PrimaryKey private val id: String,
private val name: String,
private val lastName: String
)
Затем мы создаем класс базы данных, реализуя
RoomDatabase для нашего приложения:
@Database(entities = [User::class], version = 1)
abstract class UserDatabase : RoomDatabase()
Обратите внимание, что
UserDatabase является абстрактной. Библиотека Room автоматически обеспечивает реализацию этого. Подробности смотрите в документации по Room.
Теперь нам нужен способ вставки пользовательских данных в базу данных. Для этой задачи мы создаем объект доступа к данным (DAO).
@Dao
interface UserDao {
@Insert(onConflict = REPLACE)
fun save(user: User)
@Query("SELECT * FROM user WHERE id = :userId")
fun load(userId: String): LiveData<User>
}
Обратите внимание, что метод
load возвращает объект типа LiveData. Room знает, когда база данных изменена, и автоматически уведомляет всех активных наблюдателей об изменении данных. Поскольку Room использует LiveData, эта операция эффективна; он обновляет данные только при наличии хотя бы одного активного наблюдателя.
Примечание: Room проверяет недействительность на основе модификаций таблицы, что означает, что она может отправлять ложные положительные уведомления.
Определив наш класс UserDao, мы затем ссылаемся на DAO из нашего класса базы данных:
@Database(entities = [User::class], version = 1)
abstract class UserDatabase : RoomDatabase() {
abstract fun userDao(): UserDao
}
Теперь мы можем изменить наш
UserRepository, чтобы включить источник данных Room:
// Информирует Dagger, что этот класс должен быть создан только один раз.
@Singleton
class UserRepository @Inject constructor(
private val webservice: Webservice,
// Простой кэш в памяти. Детали опущены для краткости.
private val executor: Executor,
private val userDao: UserDao
) {
fun getUser(userId: String): LiveData<User> {
refreshUser(userId)
// Возвращает объект LiveData непосредственно из базы данных.
return userDao.load(userId)
}
private fun refreshUser(userId: String) {
// Работает в фоновом потоке.
executor.execute {
// Проверьте, если пользовательские данные были получены недавно.
val userExists = userDao.hasUser(FRESH_TIMEOUT)
if (!userExists) {
// Обновляем данные.
val response = webservice.getUser(userId).execute()
// Проверьте на ошибки здесь.
// Обновляем базу данных. Объект LiveData автоматически обновляется,
// поэтому нам здесь больше ничего не нужно делать.
userDao.save(response.body()!!)
}
}
}
companion object {
val FRESH_TIMEOUT = TimeUnit.DAYS.toMillis(1)
}
}
Обратите внимание, что даже если мы изменили источник данных в
UserRepository, нам не нужно было менять наш UserProfileViewModel или UserProfileFragment. Это небольшое обновление демонстрирует гибкость, которую обеспечивает архитектура нашего приложения. Он также отлично подходит для тестирования, потому что мы можем предоставить поддельный UserRepository и одновременно протестировать нашу производственную UserProfileViewModel.
Если пользователи вернутся через несколько дней, то приложение использующее эту архитектуру, вполне вероятно, покажет устаревшую информацию, пока хранилище не получит обновленную информацию. В зависимости от вашего варианта использования вы можете не отображать устаревшую информацию. Вместо этого вы можете отобразить данные-заполнители (placeholder data), которые показывают фиктивные значения и указывают, что ваше приложение в настоящее время загружает и загружает актуальную информацию.
Единственный источник правды
Обычно разные конечные точки REST API возвращают одни и те же данные. Например, если у нашего бэкэнда есть другая конечная точка, которая возвращает список друзей, один и тот же пользовательский объект может исходить из двух разных конечных точек API, возможно, даже с использованием разных уровней детализации. Если бы UserRepository возвращал ответ от запроса Webservice как есть, без проверки согласованности, наши пользовательские интерфейсы могли бы показывать запутанную информацию, потому что версия и формат данных из хранилища зависели бы от последней вызванной конечной точки.
По этой причине наша реализация UserRepository сохраняет ответы веб-служб в базе данных. Изменения в базе данных затем вызывают обратные вызовы для активных объектов LiveData. Используя эту модель, база данных служит единственным источником правды, и другие части приложения получают к ней доступ через наш UserRepository. Независимо от того, используете ли вы дисковый кэш, мы рекомендуем, чтобы ваш репозиторий определял источник данных как единственный источник правды для остальной части вашего приложения.
Показывать прогресс операции
В некоторых случаях использования, таких как pull-to-refresh, важно, чтобы пользовательский интерфейс показывал пользователю, что в данный момент выполняется сетевая операция. Рекомендуется отделять действие пользовательского интерфейса от фактических данных, поскольку данные могут обновляться по разным причинам. Например, если мы получили список друзей, тот же пользователь может быть снова выбран программным образом, что приведет к обновлению LiveData. С точки зрения пользовательского интерфейса, факт наличия запроса в полете — это просто еще одна точка данных, аналогичная любой другой части данных в самом объекте
User.
Мы можем использовать одну из следующих стратегий для отображения согласованного статуса обновления данных в пользовательском интерфейсе независимо от того, откуда поступил запрос на обновление данных:
- Измените
getUser (), чтобы он возвращал объект типаLiveData. Этот объект будет включать в себя статус работы сети. Для примера, смотрите реализацию NetworkBoundResource в проекте GitHub android-Architecture-components. - Предоставьте другую общедоступную функцию в классе
UserRepository, которая может возвращать состояние обновления пользователя. Этот вариант лучше использовать, если вы хотите отображать состояние сети в вашем пользовательском интерфейсе только в том случае, если процесс извлечения данных возник из явного действия пользователя, такого как pull-to-refresh.
Протестируйте каждый компонент
В разделе о разделении интересов мы упомянули, что одним из ключевых преимуществ следования этому принципу является тестируемость.
В следующем списке показано, как протестировать каждый модуль кода из нашего расширенного примера:
- Пользовательский интерфейс и взаимодействие: используйте инструментарий Android UI тест. Лучший способ создать этот тест — использовать библиотеку Espresso. Вы можете создать фрагмент и предоставить ему макет
UserProfileViewModel. Поскольку фрагмент связывается только сUserProfileViewModel, насмешка над этим одним классом достаточна для полного тестирования пользовательского интерфейса вашего приложения. - ViewModel: вы можете протестировать класс
UserProfileViewModelс помощью теста JUnit. Вам нужно только смоделировать один класс,UserRepository. - UserRepository: вы также можете протестировать
UserRepositoryс помощью теста JUnit. Вам нужно испытыватьWebserviceиUserDao. В этих тестах проверьте следующее поведение:- Хранилище делает правильные вызовы веб-службы.
- Репозиторий сохраняет результаты в базе данных.
- Хранилище не делает ненужных запросов, если данные кэшируются и обновляются.
- Поскольку и
Webservice, иUserDaoявляются интерфейсами, вы можете имитировать их или создавать поддельные реализации для более сложных тестовых случаев. - UserDao: тестируйте классы DAO с помощью инструментальных тестов. Поскольку эти инструментальные тесты не требуют каких-либо компонентов пользовательского интерфейса, они выполняются быстро. Для каждого теста создайте базу данных в памяти, чтобы убедиться, что у теста нет побочных эффектов, таких как изменение файлов базы данных на диске…
Внимание: Room позволяет указать реализацию базы данных, поэтому можно протестировать DAO, предоставив реализацию JSQL для SupportSQLiteOpenHelper. Однако такой подход не рекомендуется, поскольку работающая на устройстве версия SQLite может отличаться от версии SQLite на компьютере разработчика.
- Веб-сервис: в этих тестах избегайте сетевых вызовов на ваш сервер. Для всех тестов, особенно веб-, важно быть независимым от внешнего мира. Несколько библиотек, включая MockWebServer, могут помочь вам создать поддельный локальный сервер для этих тестов.
- Тестирование артефактов: Компоненты архитектуры предоставляют артефакт maven для управления фоновыми потоками. Артефакт тестирования ядра
androidx.arch.core: содержит следующие правила JUnit:InstantTaskExecutorRule:Используйте это правило для мгновенного выполнения любой фоновой операции в вызывающем потоке.CountingTaskExecutorRule:Используйте это правило для ожидания фоновых операций компонентов архитектуры. Вы также можете связать это правило с Espresso в качестве ресурса в режиме ожидания.
Лучшие практики
Программирование — это творческое поле, и создание приложений для Android не является исключением. Существует много способов решения проблемы, будь то передача данных между несколькими действиями или фрагментами, извлечение удаленных данных и их локальное сохранение в автономном режиме, или любое количество других распространенных сценариев, с которыми сталкиваются нетривиальные приложения.
Хотя следующие рекомендации не являются обязательными, наш опыт показывает, что их выполнение делает вашу кодовую базу более надежной, тестируемой и поддерживаемой в долгосрочной перспективе:
Избегайте обозначения точек входа вашего приложения — таких как действия, службы и широковещательные приемники — в качестве источников данных.
Вместо этого они должны координировать свои действия только с другими компонентами, чтобы получить подмножество данных, относящихся к этой точке входа. Каждый компонент приложения довольно недолговечен, в зависимости от взаимодействия пользователя с его устройством и общего текущего состояния системы.
Создайте четкие границы ответственности между различными модулями вашего приложения.
Например, не распространяйте код, который загружает данные из сети, по нескольким классам или пакетам в вашей кодовой базе. Точно так же не определяйте множественные несвязанные обязанности — такие как кэширование данных и связывание данных — в одном классе.
Выставляйте как можно меньше от каждого модуля.
Не поддавайтесь соблазну создать ярлык «всего один», который раскрывает детали внутренней реализации из одного модуля. Вы можете выиграть немного времени в краткосрочной перспективе, но затем вы будете нести технический долг много раз по мере развития вашей кодовой базы.
Подумайте, как сделать каждый модуль тестируемым изолированно.
Например, наличие четко определенного API для извлечения данных из сети облегчает тестирование модуля, который сохраняет эти данные в локальной базе данных. Если вместо этого вы смешиваете логику этих двух модулей в одном месте или распределяете свой сетевой код по всей базе кода, тестирование становится намного сложнее — в некоторых случаях даже не невозможным.
Сосредоточьтесь на уникальном ядре вашего приложения, чтобы оно выделялось среди других приложений.
Не изобретайте велосипед заново, снова и снова записывая один и тот же шаблон. Вместо этого сосредоточьте свое время и энергию на том, что делает ваше приложение уникальным, и позвольте компонентам архитектуры Android и другим рекомендуемым библиотекам справиться с повторяющимся образцом.
Сохраняйте как можно больше актуальных и свежих данных.
Таким образом, пользователи могут наслаждаться функциональностью вашего приложения, даже если их устройство находится в автономном режиме. Помните, что не все ваши пользователи пользуются постоянным высокоскоростным подключением.
Назначьте один источник данных единственным источником истинны.
Всякий раз, когда вашему приложению требуется доступ к этому фрагменту данных, оно всегда должно происходить из этого единственного источника истины.
Дополнение: раскрытие статуса сети
В приведенном выше разделе рекомендуемой архитектуры приложения мы пропустили сетевые ошибки и состояния загрузки для упрощения фрагментов кода.
В этом разделе показано, как отобразить состояние сети с помощью класса Resource, который инкапсулирует как данные, так и их состояние.
Следующий фрагмент кода предоставляет пример реализации Resource:
// Общий класс, который содержит данные и статус о загрузке этих данных.
sealed class Resource<T>(
val data: T? = null,
val message: String? = null
) {
class Success<T>(data: T) : Resource<T>(data)
class Loading<T>(data: T? = null) : Resource<T>(data)
class Error<T>(message: String, data: T? = null) : Resource<T>(data, message)
}
Поскольку загрузка данных из сети при отображении копии этих данных является обычной практикой, полезно создать вспомогательный класс, который можно повторно использовать в нескольких местах. Для этого примера мы создаем класс с именем
NetworkBoundResource.
На следующей диаграмме показано дерево решений для NetworkBoundResource:

Он начинается с наблюдения за базой данных для ресурса. Когда запись загружается из базы данных в первый раз, NetworkBoundResource проверяет, является ли результат достаточно хорошим, чтобы его можно было отправить, или его нужно получить из сети заново. Обратите внимание, что обе эти ситуации могут возникать одновременно, учитывая, что вы, вероятно, хотите показывать кэшированные данные при обновлении их из сети.
Если сетевой вызов завершается успешно, он сохраняет ответ в базе данных и повторно инициализирует поток. В случае сбоя сетевого запроса NetworkBoundResource отправляет сбой напрямую.
Примечание. После сохранения новых данных на диск мы повторно инициализируем поток из базы данных. Однако обычно нам не нужно этого делать, потому что сама база данных отправляет изменения.
Имейте в виду, что полагаться на базу данных для отправки изменений включает в себя использование связанных побочных эффектов, что не очень хорошо, потому что неопределенное поведение этих побочных эффектов может произойти, если база данных не отправит изменения, потому что данные не изменились.
Кроме того, не отправляйте результаты, полученные из сети, поскольку это нарушит принцип единого источника истины. В конце концов, возможно, база данных содержит триггеры, которые изменяют значения данных во время операции сохранения. Точно так же не отправляйте `SUCCESS` без новых данных, потому что тогда клиент получит неверную версию данных.
В следующем фрагменте кода показан открытый API, предоставленный классом NetworkBoundResource для его подклассов:
// ResultType: Введите данные ресурса.
// RequestType: Введите ответ API.
abstract class NetworkBoundResource<ResultType, RequestType> {
// Вызывается для сохранения результата ответа API в базу данных.
@WorkerThread
protected abstract fun saveCallResult(item: RequestType)
// Вызывается с данными в базе данных, чтобы решить, следует ли извлекать
// потенциально обновленные данные из сети.
@MainThread
protected abstract fun shouldFetch(data: ResultType?): Boolean
// Вызывается для получения кэшированных данных из базы данных.
@MainThread
protected abstract fun loadFromDb(): LiveData<ResultType>
// Вызывается для создания вызова API.
@MainThread
protected abstract fun createCall(): LiveData<ApiResponse<RequestType>>
// Вызывается, когда получение не удается. Дочерний класс
// может захотеть сбросить компоненты, такие как ограничитель скорости.
protected open fun onFetchFailed() {}
// Возвращает объект LiveData, представляющий ресурс,
// реализованный в базовом классе.
fun asLiveData(): LiveData<ResultType> = TODO()
}
Обратите внимание на следующие важные детали определения класса:
- Он определяет два параметра типа,
ResultTypeиRequestType, поскольку тип данных, возвращаемый из API, может не соответствовать типу данных, используемому локально. - Он использует класс
ApiResponseдля сетевых запросов.ApiResponse— это простая оболочка для классаRetrofit2.Call, которая преобразует ответы в экземплярыLiveData.
Полная реализация класса
NetworkBoundResource появляется как часть проекта GitHub android-Architecture-components.
После создания NetworkBoundResource мы можем использовать его для записи наших привязанных к диску и сети реализаций User в классе UserRepository:
// Информирует Dagger2, что этот класс должен быть создан только один раз.
@Singleton
class UserRepository @Inject constructor(
private val webservice: Webservice,
private val userDao: UserDao
) {
fun getUser(userId: String): LiveData<User> {
return object : NetworkBoundResource<User, User>() {
override fun saveCallResult(item: User) {
userDao.save(item)
}
override fun shouldFetch(data: User?): Boolean {
return rateLimiter.canFetch(userId) && (data == null || !isFresh(data))
}
override fun loadFromDb(): LiveData<User> {
return userDao.load(userId)
}
override fun createCall(): LiveData<ApiResponse<User>> {
return webservice.getUser(userId)
}
}.asLiveData()
}
}
Комментариев нет:
Отправить комментарий