
Что важно для команды разработчиков, которая только начинает строить систему, базирующуюся на машинном обучении? Архитектура, компоненты, возможности тестирования с помощью интеграционных и юнит тестов, сделать прототип и получить первые результаты. И далее к оценке трудоемкости, планированию разработки и реализации.
В этой статье речь пойдет как раз о прототипе. Который был создан через некоторое время после разговора с Product Manager: а почему бы нам не «пощупать» Machine Learning? В частности, NLP и Sentiment Analysis?
«А почему бы и нет?» — ответил я. Все-таки занимаюсь backend-разработкой более 15 лет, люблю работать с данными и решать проблемы производительности. Но мне еще предстояло узнать, «насколько глубока кроличья нора».
Выделяем компоненты
Чтобы как-то очертить набор компонентов, реализующих логику нашего ML-ядра, взглянем на простой пример реализации сентимент-анализа, один из множества, доступных на GitHub.
import collections
import nltk
import os
from sklearn import (
datasets, model_selection, feature_extraction, linear_model
)
def extract_features(corpus):
'''Extract TF-IDF features from corpus'''
# vectorize means we turn non-numerical data into an array of numbers
count_vectorizer = feature_extraction.text.CountVectorizer(
lowercase=True, # for demonstration, True by default
tokenizer=nltk.word_tokenize, # use the NLTK tokenizer
stop_words='english', # remove stop words
min_df=1 # minimum document frequency, i.e. the word must appear more than once.
)
processed_corpus = count_vectorizer.fit_transform(corpus)
processed_corpus = feature_extraction.text.TfidfTransformer().fit_transform(
processed_corpus)
return processed_corpus
data_directory = 'movie_reviews'
movie_sentiment_data = datasets.load_files(data_directory, shuffle=True)
print('{} files loaded.'.format(len(movie_sentiment_data.data)))
print('They contain the following classes: {}.'.format(
movie_sentiment_data.target_names))
movie_tfidf = extract_features(movie_sentiment_data.data)
X_train, X_test, y_train, y_test = model_selection.train_test_split(
movie_tfidf, movie_sentiment_data.target, test_size=0.30, random_state=42)
# similar to nltk.NaiveBayesClassifier.train()
model = linear_model.LogisticRegression()
model.fit(X_train, y_train)
print('Model performance: {}'.format(model.score(X_test, y_test)))
y_pred = model.predict(X_test)
for i in range(5):
print('Review:\n{review}\n-\nCorrect label: {correct}; Predicted: {predict}'.format(
review=X_test[i], correct=y_test[i], predict=y_pred[i]
))
Разбирать такие примеры — это отдельный челлендж для разработчика.
Всего лишь 45 строк кода, и сразу 4 (четыре, Карл!) логических блока:
- Загрузка данных для обучения модели (строки 25-26)
- Подготовка загруженных данных — feature extraction (строки 31-34)
- Создание и обучение модели (строки 36-39)
- Тестирование обученной модели и вывод результата (строки 41-45)
Каждый из этих пунктов достоин отдельной статьи. И уж точно требует оформления в отдельном модуле. Хотя бы для нужд юнит-тестирования.
Отдельно стоит выделить компоненты подготовки данных и обучения модели.
В каждый из способов сделать модель точнее вложены сотни часов научного и инженерного труда.
Благо, для того, чтобы быстро начать с NLP, есть готовое решение – библиотеки NLTK и TextBlob. Второе является оберткой над NLTK, которая делает рутинную работу – делает feature extraction из тренировочного набора, а затем обучает модель при первом запросе классификации.
Но прежде чем обучить модель, необходимо подготовить для нее данные.
Готовим данные
Загружаем данные
Если говорить о прототипе, то загрузка данных из CSV/TSV файла элементарна. Вы просто вызываете функцию read_csv из библиотеки pandas:
import pandas as pd
data = pd.read_csv(data_path, delimiter)
Но это не будут данные, готовые к использованию в модели.
Во-первых, если немного абстрагироваться от csv-формата, то нетрудно ожидать, что каждый источник будет предоставлять данные со своими особенностями, и, следовательно, нам потребуется некая, зависящая от источника, подготовка данных. Даже для простейшего случая CSV-файла, чтобы просто его распарсить, нам надо знать разделитель.
Кроме этого, следует определить, какие записи являются позитивными, а какие негативными. Конечно, это информация указана в аннотации к датасетам, которые мы хотим использовать. Но дело в том, что в одном случае признаком pos/neg является 0 или 1, в другом – логическое True/False, в третьем — это просто строка pos/neg, а в каком-то случае вообще кортеж целых чисел от 0 до 5. Последнее актуально для случая мультиклассовой классификации, но кто сказал, что такой набор данных нельзя использовать для бинарной классификации? Нужно просто адекватно обозначить границу позитивного и негативного значения.
Мне бы хотелось попробовать модель на разных наборах данных, при этом требуется, чтобы после обучения модель возвращала результат в каком-то одном формате. А для этого следует привести ее разнородные данные к единому виду.
Итак, можно выделить три функции, необходимых нам на этапе загрузки данных:
- Подключение к источнику данных – для CSV, в нашем случае это реализовано внутри функции read_csv;
- Поддержка особенностей формата;
- Предварительная подготовка данных.
Вот так это выглядит в коде.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import logging
log = logging.getLogger()
class CsvSentimentDataLoader():
def __init__(self, file_path, delim, text_attr, rate_attr, pos_rates):
self.data_path = file_path
self.delimiter = delim
self.text_attr = text_attr
self.rate_attr = rate_attr
self.pos_rates = pos_rates
def load_data(self):
# Здесь данные вычитываются из csv или tsv файла
data = pd.read_csv(self.data_path, self.delimiter)
data.head()
# Отбрасываются все колонки,
# кроме текста и классифицирующего атрибута
data = data[[self.text_attr, self.rate_attr]]
# Значения классифицирующего атрибута
# приводятся к текстовым значениям ‘pos’ и ‘neg’
data[self.rate_attr] = np.where(
data[self.rate_attr].isin(self.pos_rates), 'pos', 'neg')
return data
Был сделан класс CsvSentimentDataLoader, которому в конструкторе передается путь к csv, разделитель, наименования текстового и классифицирующего атрибутов, а также перечень значений, советующих позитивному значению текста.
Сама загрузка происходит в методе load_data.
Разделяем данные на тестовый и тренировочный наборы
Ок, мы загрузили данные, но нам их еще надо разделить на тренировочный и тестовый наборы.
Делается это функцией train_test_split из библиотеки sklearn. Эта функция может принимать на вход множество параметров, определяющих, как именно этот dataset будет разделен на train и test. Эти параметры значительно влияют на получаемые тренировочные и тестовые наборы, и, вероятно, нам будет удобно сделать класс (назовем его SimpleDataSplitter), который будет управлять этими параметрами и агрегировать в себе вызов этой функции.
from sklearn.model_selection import train_test_split # to split the training and testing data
import logging
log = logging.getLogger()
class SimpleDataSplitter():
def __init__(self, text_attr, rate_attr, test_part_size=.3):
self.text_attr = text_attr
self.rate_attr = rate_attr
self.test_part_size = test_part_size
def split_data(self, data):
x = data[self.text_attr]
y = data[self.rate_attr]
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size = self.test_part_size)
return x_train, x_test, y_train, y_test
Сейчас этот класс включает в себя простейшую реализацию, которая при разделении будет учитывать только один параметр – процент записей, который следует взять в качестве тестового набора.
Датасеты
Для обучения модели я использовал свободно доступные наборы данных в формате CSV:
И чтобы было еще чуть удобнее, для каждого из датасетов я сделал класс, который загружает данные из соответствующего CSV-файла и разбивает их на тренировочный и тестовый наборы.
import os
import collections
import logging
from web.data.loaders import CsvSentimentDataLoader
from web.data.splitters import SimpleDataSplitter, TdIdfDataSplitter
log = logging.getLogger()
class AmazonAlexaDataset():
def __init__(self):
self.file_path = os.path.normpath(os.path.join(os.path.dirname(__file__), 'amazon_alexa/train.tsv'))
self.delim = '\t'
self.text_attr = 'verified_reviews'
self.rate_attr = 'feedback'
self.pos_rates = [1]
self.data = None
self.train = None
self.test = None
def load_data(self):
loader = CsvSentimentDataLoader(self.file_path, self.delim, self.text_attr, self.rate_attr, self.pos_rates)
splitter = SimpleDataSplitter(self.text_attr, self.rate_attr, test_part_size=.3)
self.data = loader.load_data()
x_train, x_test, y_train, y_test = splitter.split_data(self.data)
self.train = [x for x in zip(x_train, y_train)]
self.test = [x for x in zip(x_test, y_test)]
Да, для загрузки данных получилось немного больше, чем 5 строк кода в исходном примере.
Зато теперь появилась возможность создавать новые датасеты, жонглируя источниками данных и алгоритмами подготовки тренировочного набора.
Плюс отдельные компоненты гораздо удобнее при юнит-тестировании.
Тренируем модель
Модель обучается довольно долго. И это надо делать один раз, при старте приложения.
Для этих целей был сделан небольшой враппер, позволяющий загрузить и подготовить данные, а также обучить модель в момент инициализации приложения.
class TextBlobWrapper():
def __init__(self):
self.log = logging.getLogger()
self.is_model_trained = False
self.classifier = None
def init_app(self):
self.log.info('>>>>> TextBlob initialization started')
self.ensure_model_is_trained()
self.log.info('>>>>> TextBlob initialization completed')
def ensure_model_is_trained(self):
if not self.is_model_trained:
ds = SentimentLabelledDataset()
ds.load_data()
# train the classifier and test the accuracy
self.classifier = NaiveBayesClassifier(ds.train)
acr = self.classifier.accuracy(ds.test)
self.log.info(str.format('>>>>> NaiveBayesClassifier trained with accuracy {}', acr))
self.is_model_trained = True
return self.classifier
Сначала получаем тренировочные и тестовые данные, затем делаем feature extraction, и наконец обучаем классификатор и проверяем точность на тестовом наборе.
Тестируем
При инициализации получаем лог, судя по которому, данные загрузились и модель была успешно обучена. Причем обучена с весьма неплохой (для начала) точностью – 0.8878.
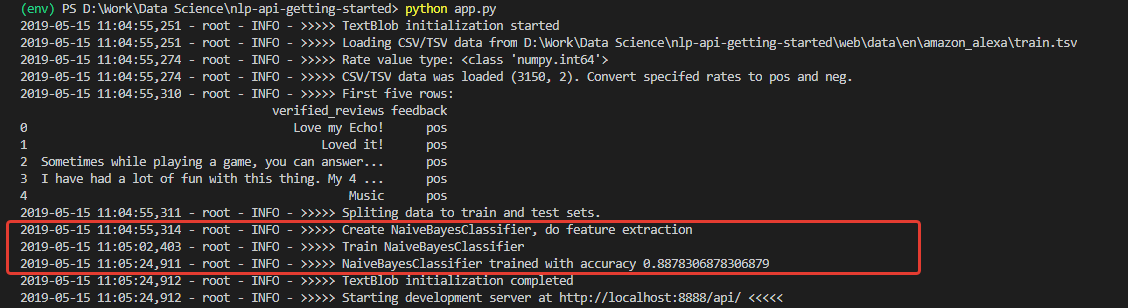
Получив такие цифры, я был весьма воодушевлен. Но моя радость, к сожалению, была не долгой. Модель, обученная на этом сете, является непробиваемым оптимистом и в принципе не способна распознавать негативные комментарии.
Причина этого — в данных обучающего набора. Количество позитивных отзывов в сете – более 90 %. Соответственно, при точности модели около 88 % негативные отзывы просто попадают в ожидаемые 12% неверных классификаций.
Иными словами, при таком обучающем наборе просто невозможно натренировать модель для распознавания негативных комментариев.
Чтобы действительно убедиться в этом, я сделал юнит-тест, который прогоняет классификацию отдельно для 100 позитивных и 100 негативных фраз из другого набора данных — для тестирования я взял Sentiment Labelled Sentences Data Set от Калифорнийского университета.
@loggingtestcase.capturelogs(None, level='INFO')
def test_classifier_on_separate_set(self, logs):
tb = TextBlobWrapper() # Going to be trained on Amazon Alexa dataset
ds = SentimentLabelledDataset() # Test dataset
ds.load_data()
# Check poisitives
true_pos = 0
data = ds.data.to_numpy()
seach_mask = np.isin(data[:, 1], ['pos'])
data = data[seach_mask][:100]
for e in data[:]:
# Model train will be performed on first classification call
r = tb.do_sentiment_classification(e[0])
if r == e[1]:
true_pos += 1
self.assertLessEqual(true_pos, 100)
print(str.format('\n\nTrue Positive answers - {} of 100', true_pos))
Алгоритм для тестирования классификации позитивных значений следующий:
- Загружаем тестовые данные;
- Берем 100 записей с меткой ‘pos’
- Каждую из них прогоняем через модель и подсчитываем кол-во верных результатов
- Выводим итоговый результат в консоль
Аналогично делается подсчет для негативных комментариев.
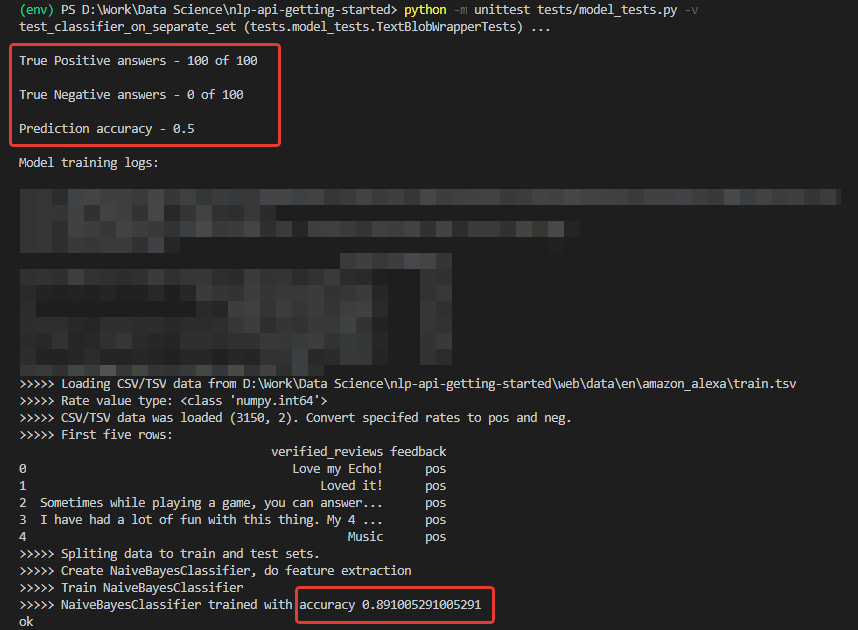
Как и предполагалось, все негативные комментарии распознались как позитивные.
А если натренировать модель на датасете, использованном для тестирования – Sentiment Labelled? Там распределение негативных и позитивных комментариев – ровно 50 на 50.
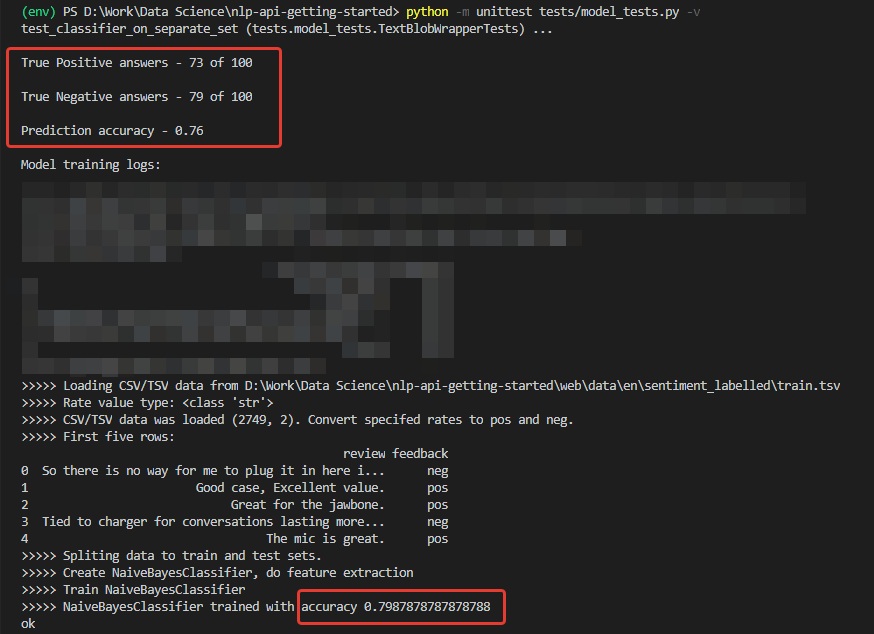
Уже что-то. Фактическая точность на 200 записей из стороннего набора – 76%, при точности классификации негативных комментариев – 79%.
Конечно, 76% — сгодится для прототипа, но недостаточно для продакшена. Это значит, что потребуется предпринимать дополнительные меры для повышения точности алгоритма. Но это уже тема для другого доклада.
Итоги
Во-первых, получилось приложение с десятком классов и 200+ строк кода, что несколько больше исходного примера на 30 строк. И следует быть честным — это лишь наметки на структуру, первое прояснение границ будущего приложения. Прототип.
И этот прототип дал возможность осознать, насколько велика дистанция между подходами к коду с точки зрения специалистов по Machine Learning и с точки зрения разработчиков традиционных приложений. И в этом, на мой взгляд, заключается основная сложность для девелоперов, решивших попробовать машинное обучение.
Следующая вещь, которая может поставить новичка в ступор – данные не менее важны, чем выбранная модель. Это было наглядно показано.
Далее, всегда остается вероятность, что обученная на одних данных модель покажет себя неадекватно на других, или в какой-то момент ее точность начнет деградировать.
Соответственно, требуются метрики контроля состояния модели, гибкость при работе с данными, технические возможности скорректировать обучение на лету. И так далее.
Как по мне, все это следует учитывать еще при проектировании архитектуры и выстраивании процессов разработки.
В общем, «кроличья нора» оказалась не только весьма глубокой, но и чрезвычайно хитро проложенной. Но тем интереснее для меня, как разработчика, изучать эту тему в дальнейшем.
Комментариев нет:
Отправить комментарий