Программирование устройства графического процессора (GPU) является заоблачным миром для Java программистов. Это понятно, так как обычные задачи для Java не подходят для GPU. Тем не менее, GPU обладают терафлопсами производительности, так давайте исследуем их возможности.
Для того чтобы сделать топик доступным, я потрачу некоторое время объясняя архитектуру GPU вместе с небольшой историей, которая облегчит погружение в программирование железа.
Однажды мне показали отличия GPU от CPU вычислений, я покажу как использовать GPU в мире Java. Наконец, я опишу главные фреймворки и библиотеки доступные для написания кода на Java и запуска их на GPU, и я приведу некоторые примеры кода.
Немного бекграунда
GPU было впервые популяризовано NVIDIA в 1999. Это специальный процессор, разработанный для обработки графических данных до того, как они будут переданы на дисплей. Во многих случаях, это делает возможным некоторые вычисления для разгрузки CPU, таким образом высвобождая ресурсы CPU которые ускоряют эти разгруженные вычисления. Результат в том, что большие входные данные могут быть обработаны и представлены в более высоком выходном разрешении, делая визуальное представление более привлекательным и частоту кадров более плавной.
Суть 2D/3D обработки состоит в основном в манипулировании матрицами, это может быть управляемо с помощью распределенного подхода. Что будет эффективным подходом для обработки изображений? Ответим на это, давайте сравним стандартную архитектуру CPU (показанную на рис. 1.) и GPU.
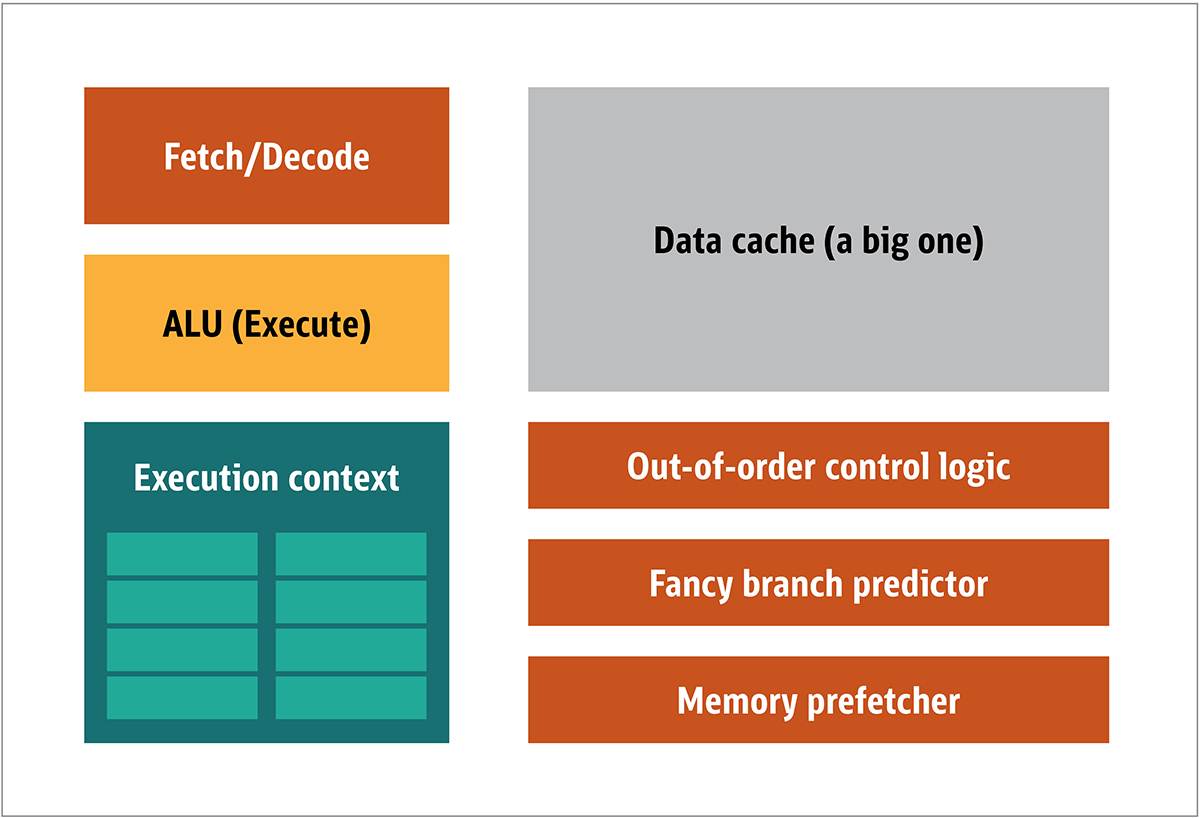
Рис. 1. Блоки архитектуры CPU
В CPU, фактические элементы обработки – регистры, арифметико-логический блок(ALU) и контексты выполнения – лишь маленькие части всей системы. Для ускорения нерегулярных расчетов, поступающих в непредсказуемом порядке, здесь присутствует большой, быстрый, и дорогой кеш; различные виды сборщиков; и предсказатели ветвлений.
Вам не нужно все это на GPU, потому что получены данные в предсказуемой манере, и GPU производит очень ограниченное множество операций над данными. Таким образом, возможно сделать их очень маленькими и не дорогой процессор с блочной архитектурой, похожую на эту, показан на рис. 2.
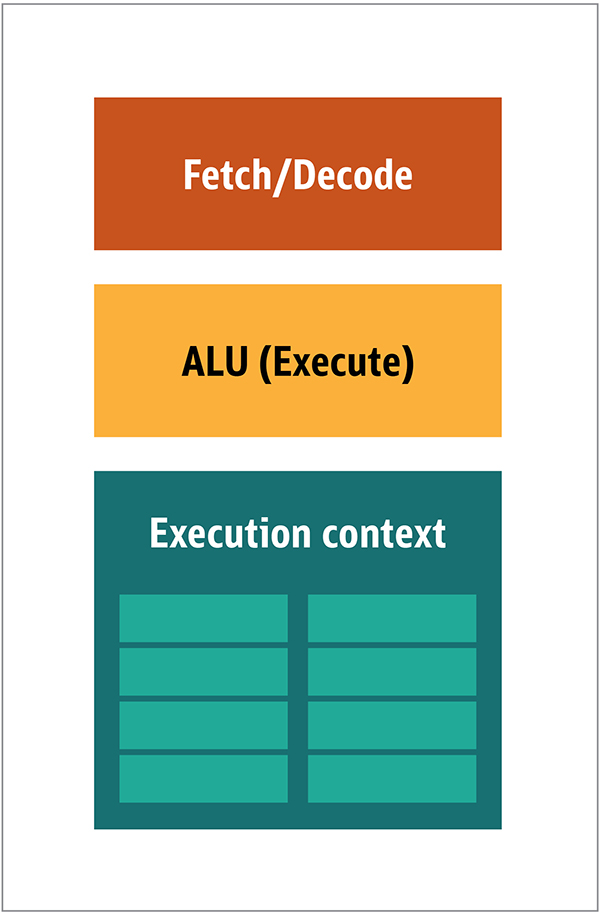
Рис. 2. Блоковая архитектура для простого ядра GPU
Потому что такие процессоры дешевле и обрабатываемые данные в них в параллельных кусках, это просто заставить многие из них работать параллельно. Это разработано, ссылаясь на множественные инструкции, множественные данные или MIMD (произносится «mim-dee»).
Второй подход базируется на факте, что часто одиночная инструкция, применяется к множественным частям данных. Это известно как единичная инструкция, множественные данные или SIMD (произносится «sim-dee»). В этом дизайне, единственный GPU содержит множественные ALU и контексты выполнения, маленькие области, переданные на разделяемые данные контекста, как показано на рис. 3.
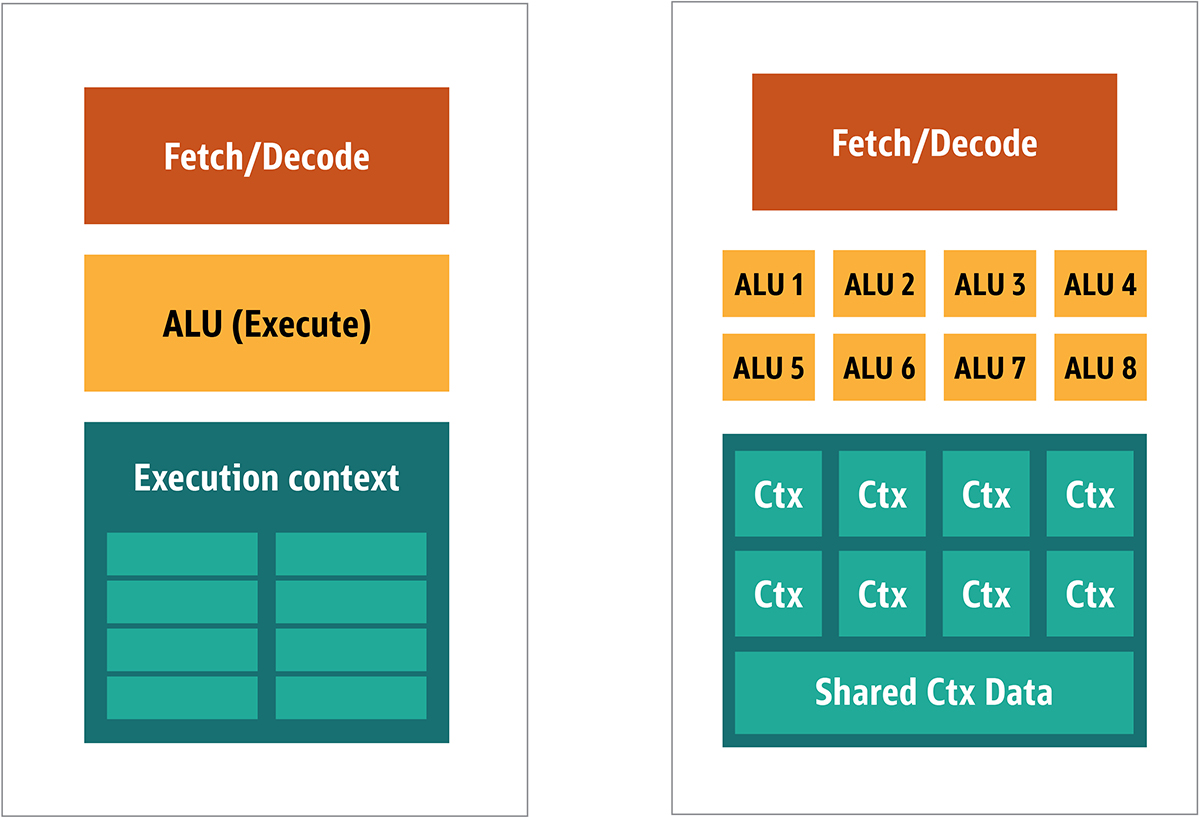
Рис. 3. Сравнение MIMD-стиля архитектуры GPU блоков (с лево), с SIMD дизайном (с право)
Смешивая SIMD и MIMD обработку обеспечивается максимальная пропускная способность, которую я обойду стороной. В этом дизайне, вы имеете множественные SIMD процессоры, работающие параллельно, как на рис. 4.

Рис. 4. Работающие множественные SIMD процессоры в параллели; здесь 16 ядер с 128 ALU
Так как вы имеете связку маленьких, простых процессоров, вы можете программировать их для получения специального эффекта в выводе.
Запуская программы на GPU
Большинство ранних графических эффектов в играх было действительно жестко запрограммированных маленьких программ выполняющихся на GPU и применялись к потокам данных из CPU.
Это было очевидно, даже тогда, когда жестко запрограммированные алгоритмы были недостаточными, особенно в дизайне игр, где визуальные эффекты являются одним из главных магических направлений. В ответ, большие продавцы открыли доступ к GPU, и затем сторонние разработчики могли программировать их.
Типичный подход был в написании маленькой программы, называемой shaders, на специальном языке (обычно на подвиде C) и компилируя их с помощью специальных компиляторов под нужную архитектуру. Термин shaders был выбран по той причине, что shaders часто используются для контроля света и эффектов тени, но это не значит, что они могут управлять другими специальными эффектами.
Каждый продавец GPU имел свой собственный язык программирования и инфраструктуру для создания shaders для их архитектуры. На этом подходе было создано множество платформ.
Главные из них:
- DirectCompute: частные shader язык/API от Microsoft, которые являются частью Direct3D, начиная с DirectX 10.
- AMD FireStream: частные технологии ATI/Radeon, которые устарели по мнению AMD.
- OpenACC: мультивендор-консорциум, решение для параллельных вычислений
- С++ AMP: частная библиотека Microsoft для параллельных данных на C++
- CUDA: частная платформа Nvidia, которая использует подмножество языка С
- OpenСL: общий стандарт, оригинально разработанный Apple, но сейчас не управляем консорциумом Khronos Group
Большую часть времени, работа с GPU это низко уровневое программирование. Для того чтобы сделать это немного более понятным для разработчиков, для кодирования, были обеспеченны несколько абстракций. Самая известная это DirectX, от Microsoft, и OpenGL, от Khronos Group. Эти API для написания высокоуровневого кода, который затем может быть затем упрощен для GPU, более семантически, для программиста.
Насколько я знаю, не существует инфраструктуры Java для DirectX, но есть хорошее решение для OpenGL. JSR 231 запустилось в 2002 и адресовано GPU программистам, но оно было заброшено в 2008 и поддерживает только OpenGL 2.0.
Поддержка OpenGL продолжается в независимом проекте JOCL, (который также поддерживает OpenCL), и он доступен аудитории. Таким образом, знаменитая игра Minecraft была написана с использованием JOCL.
Приход GPGPU
До сих пор, Java и GPU не имели точек соприкосновения, хотя они должны быть. Java часто используется на предприятиях, в науке о данных, и в финансовом секторе, где много вычислений и где нужно много вычислительных сил. Это о том, как идея general-purpose GPU (GPGPU). Идея использование GPU по этому пути начали, когда производители видео адаптеров начали давать доступ к программному буферу кадров, давая разработчикам считывать содержимое. Некоторые хакеры определили, что они могут использовать всю силу GPU для универсальных вычислений.
Рецепт был таким:
- Закодировать данные как растровый массив.
- Написать shaders для обработки их.
- Отправьте их обоих на видеокарту.
- Получить результат из буфера кадра
- Декодировать данные из растрового массива.
Это очень простое объяснение. Я не уверен будет ли это работать в продакшене, но это действительно работает.
Затем начались множественные исследования от Стенфордского Института для упрощения использования GPU. В 2005 они сделали BrookGPU, которая была маленькой экосистемой, которая включала язык программирования, компилятор, и среду запуска.
BrookGPU компилировала программы написанные на языке программирования потоков Brook, который был вариантом ANSI C. Он может быть нацелен на OpenGL v1.3 +, DirectX v9 + или AMD Close to Metal для вычислительной серверной части, и он запускается на Microsoft Windows и Linux. Для отладки, BrookGPU может также симулировать виртуальную графическую карту на CPU.
Однако это не взлетело, из-за оборудования, доступного в то время. В мире GPGPU, тебе надо копировать данные на устройство (в это контексте, устройство ссылается на GPU и устройстве, на котором он расположен), ждать GPU для вычисления данных, и затем копировать данные обратно в управляющую программу. Это создает множество задержек. И в середине 2000-х, когда проект был в активной разработке, эти задержки также исключали интенсивное использование GPU для базовых вычислений.
Тем не менее, многие компании видели будущее в этой технологии. Несколько разработчиков видео адаптеров начали обеспечивать GPGPU с их фирменными технологиями, и другие сформированные альянсы обеспечивали менее базово, разносторонние модели программирования работали на большом количестве железа.
Теперь, когда я вам все рассказал, давайте проверим две самые удачные технологии для вычисления на GPU – OpenCL и CUDA – смотри также как Java работает с ними.
OpenCL и Java
Как и другие инфраструктурные пакеты, OpenCL обеспечивает базовую имплементацию на C. Это технически доступно с помощью Java Native Interface (JNI) или Java Native Access (JNA), но такой подход будет слишком тяжёлым для большинства разработчиков.
К счастью, эта работа была уже сделана несколькими библиотеками: JOCL, JogAmp, и JavaCL. К несчастью, JavaCL стал мертвым проектом. Но проект JOCL жив и очень даже адаптирован. Я буду использовать его для следующих примеров.
Но сначала я должен объяснить, что из себя представляет OpenCL. Я упоминал ранее, что OpenCL обеспечивает очень базовую модель, подходящую для программирования всех видов устройств – не только GPU и CPU, но даже DSP процессоры и FPGA.
Давайте посмотрим на самый простой пример: складывание векторов, наверное, самый яркий и простой пример. Вы имеете два массива чисел для сложение и один для результата. Вы берете элемент из первого массива и элемент из второго массива, и затем вы кладете сумму в массив результатов, показано на рис. 5.
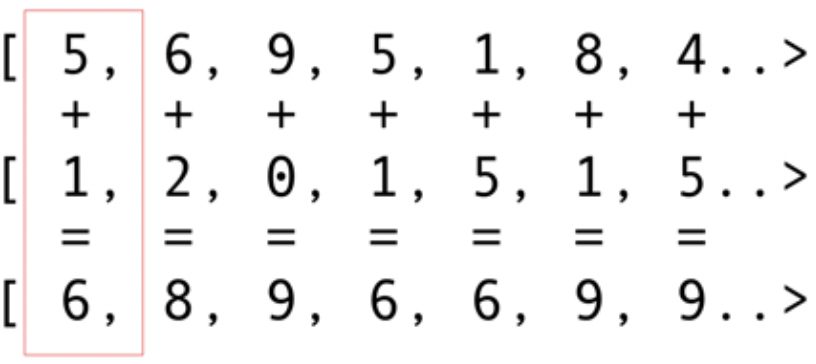
Рис. 5. Сложение элементов двух массивов и сохранение суммы в результирующий массив
Как вы можете видеть, операция очень согласованная и тем не менее распределяемая. Вы можете запихнуть каждую операцию сложения в разные GPU ядра. Это значит, что, если вы имеете 2048 ядер, как на Nvidia 1080, вы можете выполнить 2048 операций сложения одновременно. Это означает что здесь потенциальные терафлопсы компьютерной мощи ждут вас. Этот код для массива из 10 миллионов чисел взят с сайта JOCL:
public class ArrayGPU {
/**
* The source code of the OpenCL program
*/
private static String programSource =
"__kernel void "+
"sampleKernel(__global const float *a,"+
" __global const float *b,"+
" __global float *c)"+
"{"+
" int gid = get_global_id(0);"+
" c[gid] = a[gid] + b[gid];"+
"}";
public static void main(String args[])
{
int n = 10_000_000;
float srcArrayA[] = new float[n];
float srcArrayB[] = new float[n];
float dstArray[] = new float[n];
for (int i=0; i<n; i++)
{
srcArrayA[i] = i;
srcArrayB[i] = i;
}
Pointer srcA = Pointer.to(srcArrayA);
Pointer srcB = Pointer.to(srcArrayB);
Pointer dst = Pointer.to(dstArray);
// The platform, device type and device number
// that will be used
final int platformIndex = 0;
final long deviceType = CL.CL_DEVICE_TYPE_ALL;
final int deviceIndex = 0;
// Enable exceptions and subsequently omit error checks in this sample
CL.setExceptionsEnabled(true);
// Obtain the number of platforms
int numPlatformsArray[] = new int[1];
CL.clGetPlatformIDs(0, null, numPlatformsArray);
int numPlatforms = numPlatformsArray[0];
// Obtain a platform ID
cl_platform_id platforms[] = new cl_platform_id[numPlatforms];
CL.clGetPlatformIDs(platforms.length, platforms, null);
cl_platform_id platform = platforms[platformIndex];
// Initialize the context properties
cl_context_properties contextProperties = new cl_context_properties();
contextProperties.addProperty(CL.CL_CONTEXT_PLATFORM, platform);
// Obtain the number of devices for the platform
int numDevicesArray[] = new int[1];
CL.clGetDeviceIDs(platform, deviceType, 0, null, numDevicesArray);
int numDevices = numDevicesArray[0];
// Obtain a device ID
cl_device_id devices[] = new cl_device_id[numDevices];
CL.clGetDeviceIDs(platform, deviceType, numDevices, devices, null);
cl_device_id device = devices[deviceIndex];
// Create a context for the selected device
cl_context context = CL.clCreateContext(
contextProperties, 1, new cl_device_id[]{device},
null, null, null);
// Create a command-queue for the selected device
cl_command_queue commandQueue =
CL.clCreateCommandQueue(context, device, 0, null);
// Allocate the memory objects for the input and output data
cl_mem memObjects[] = new cl_mem[3];
memObjects[0] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcA, null);
memObjects[1] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcB, null);
memObjects[2] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_WRITE,
Sizeof.cl_float * n, null, null);
// Create the program from the source code
cl_program program = CL.clCreateProgramWithSource(context,
1, new String[]{ programSource }, null, null);
// Build the program
CL.clBuildProgram(program, 0, null, null, null, null);
// Create the kernel
cl_kernel kernel = CL.clCreateKernel(program, "sampleKernel", null);
// Set the arguments for the kernel
CL.clSetKernelArg(kernel, 0,
Sizeof.cl_mem, Pointer.to(memObjects[0]));
CL.clSetKernelArg(kernel, 1,
Sizeof.cl_mem, Pointer.to(memObjects[1]));
CL.clSetKernelArg(kernel, 2,
Sizeof.cl_mem, Pointer.to(memObjects[2]));
// Set the work-item dimensions
long global_work_size[] = new long[]{n};
long local_work_size[] = new long[]{1};
// Execute the kernel
CL.clEnqueueNDRangeKernel(commandQueue, kernel, 1, null,
global_work_size, local_work_size, 0, null, null);
// Read the output data
CL.clEnqueueReadBuffer(commandQueue, memObjects[2], CL.CL_TRUE, 0,
n * Sizeof.cl_float, dst, 0, null, null);
// Release kernel, program, and memory objects
CL.clReleaseMemObject(memObjects[0]);
CL.clReleaseMemObject(memObjects[1]);
CL.clReleaseMemObject(memObjects[2]);
CL.clReleaseKernel(kernel);
CL.clReleaseProgram(program);
CL.clReleaseCommandQueue(commandQueue);
CL.clReleaseContext(context);
}
private static String getString(cl_device_id device, int paramName) {
// Obtain the length of the string that will be queried
long size[] = new long[1];
CL.clGetDeviceInfo(device, paramName, 0, null, size);
// Create a buffer of the appropriate size and fill it with the info
byte buffer[] = new byte[(int)size[0]];
CL.clGetDeviceInfo(device, paramName, buffer.length, Pointer.to(buffer), null);
// Create a string from the buffer (excluding the trailing \0 byte)
return new String(buffer, 0, buffer.length-1);
}
}
Этот код не похож на код на Java, но он им является. Я объясню код далее; не тратте на него много времени сейчас, потому что я буду кратко обсуждать сложные решения.
Код будет документированным, но давайте сделаем маленькое прохождение. Как вы можете видеть, код очень похож на код на С. Это нормально, потому что JOCL – это всего лишь OpenCL. В начале, здесь некоторый код в строке, и этот код самая важная часть: Она компилируется с помощью OpenCL и затем отправляется на видео карту, где и выполняется. Этот код называется Kernel. Не путайте этот термин с OC Kernel; это код устройства. Этот код написан на подмножестве C.
После kernel идет Java код для установки и настроить устройство, разбить данные, и создать соответствующие буферы памяти для результирующих данных.
Подведем итог: тут «хостовый код», что обычно является языковой привязкой (в нашем случае на Java), и «код устройства». Вы всегда выделяете, что будет работать на хосте и что должно работать на устройстве, потому что хост контролирует устройство.
Предшествующий код должен показать GPU эквивалент «Hello World!». Как вы видите, большая его часть огромна.
Давайте не забудем об SIMD возможностях. Если ваше устройство поддерживает SIMD расширение, вы можете сделать арифметический код более быстрым. Для примера, давайте взглянем на kernel код умножения матриц. Этот код в простой строке на языке Java в приложении.
__kernel void MatrixMul_kernel_basic(int dim,
__global float *A,
__global float *B,
__global float *C){
int iCol = get_global_id(0);
int iRow = get_global_id(1);
float result = 0.0;
for(int i=0; i< dim; ++i)
{
result +=
A[iRow*dim + i]*B[i*dim + iCol];
}
C[iRow*dim + iCol] = result;
}
Технически, этот код будет работать на кусках данных, которые были установлены для вас фреймворком OpenCL, с инструкциями, которые вы вызвали в подготовительной части.
Если ваша видео карта поддерживает SIMD инструкции и может обработать вектор из четырех чисел с плавающей точкой, маленькие оптимизации могут превратить предыдущий код в следующий:
#define VECTOR_SIZE 4
__kernel void MatrixMul_kernel_basic_vector4(
size_t dim, // dimension is in single floats
const float4 *A,
const float4 *B,
float4 *C)
{
size_t globalIdx = get_global_id(0);
size_t globalIdy = get_global_id(1);
float4 resultVec = (float4){ 0, 0, 0, 0 };
size_t dimVec = dim / 4;
for(size_t i = 0; i < dimVec; ++i) {
float4 Avector = A[dimVec * globalIdy + i];
float4 Bvector[4];
Bvector[0] = B[dimVec * (i * 4 + 0) + globalIdx];
Bvector[1] = B[dimVec * (i * 4 + 1) + globalIdx];
Bvector[2] = B[dimVec * (i * 4 + 2) + globalIdx];
Bvector[3] = B[dimVec * (i * 4 + 3) + globalIdx];
resultVec += Avector[0] * Bvector[0];
resultVec += Avector[1] * Bvector[1];
resultVec += Avector[2] * Bvector[2];
resultVec += Avector[3] * Bvector[3];
}
C[dimVec * globalIdy + globalIdx] = resultVec;
}
С этим кодом вы можете удвоить производительность.
Круто. Вы только что открыли GPU для Java мира! Но будучи Java разработчиком, неужели вы хотите делать всю эту грязную работу, с С кодом, и работы с столь низкоуровневыми деталями? Я не хочу. Но сейчас, когда вы имеете некоторые знания о том, как GPU используется, давайте посмотрим на другое решение отличающееся от JOCL кода, который я только что представил.
CUDA и Java
CUDA это решение Nvidia на этот вопрос программирования. CUDA обеспечивает много больше готовых к использованию библиотек для стандарта GPU операций, такие как матрицы, гистограммы, и даже глубокие нейронные сети. Появился список библиотек уже имеющих кучу готовых решений. Это все из проекта JCuda:
- JCublas: все для матриц
- JCufft: быстрое преобразование Фурье
- JCurand: все для случайных чисел
- JCusparse: редкие матрицы
- JCusolver: факторизация чисел
- JNvgraph: все для графов
- JCudpp: CUDA библиотека примитивных параллельных данных и некоторые алгоритмы сортировки
- JNpp: обработка картинок на GPU
- JCudnn: библиотека глубоких нейронных сетей
Я рассматриваю использование JCurand, которая генерирует случайные числа. Вы можете использовать это из Java кода без другого специального языка Kernel. Для примера:
...
int n = 100;
curandGenerator generator = new curandGenerator();
float hostData[] = new float[n];
Pointer deviceData = new Pointer();
cudaMalloc(deviceData, n * Sizeof.FLOAT);
curandCreateGenerator(generator, CURAND_RNG_PSEUDO_DEFAULT);
curandSetPseudoRandomGeneratorSeed(generator, 1234);
curandGenerateUniform(generator, deviceData, n);
cudaMemcpy(Pointer.to(hostData), deviceData,
n * Sizeof.FLOAT, cudaMemcpyDeviceToHost);
System.out.println(Arrays.toString(hostData));
curandDestroyGenerator(generator);
cudaFree(deviceData);
...
Здесь используется GPU для создания большого числа случайных чисел очень высокого качества, основано на очень сильной математике.
В JCuda вы можете также написать общий CUDA код и вызвать это из Java с помощью вызова некоторого JAR файла в вашем classpath. Смотрите документацию JCuda для больших примеров.
Оставаться выше низкоуровневого кода
Это все выглядит замечательным, но тут слишком много кода, слишком много установки, слишком много различных языков для запуска всего этого. Есть ли способ использовать GPU хотя бы частично?
Что если вы не хотите задумываться о всей этой OpenCL, CUDA, и других ненужных вещей? Что если вы хотите только программировать на Java и не думать обо всем не очевидном? Aparapi проект может помочь. Aparapi базируется на «параллельном API». Я думаю об этом как об какой-то части Hibernate для GPU программирования, которая использует OpenCL под капотом. Давайте взглянем на пример сложения векторов.
public static void main(String[] _args) {
final int size = 512;
final float[] a = new float[size];
final float[] b = new float[size];
/* fill the arrays with random values */
for (int i = 0; i < size; i++){
a[i] = (float) (Math.random() * 100);
b[i] = (float) (Math.random() * 100);
}
final float[] sum = new float[size];
Kernel kernel = new Kernel(){
@Override public void run() {
I int gid = getGlobalId();
sum[gid] = a[gid] + b[gid];
}
};
kernel.execute(Range.create(size));
for(int i = 0; i < size; i++) {
System.out.printf("%6.2f + %6.2f = %8.2f\n", a[i], b[i], sum[i])
}
kernel.dispose();
}
Здесь чистый Java код (взятый из документации Aparapi), также здесь и там, вы можете видеть некий термин Kernel и getGlobalId. Вам все еще нужно понимать, как программировать GPU, но вы можете использовать подход GPGPU в более близкой к Java манере. Более того, Aparapi обеспечивает простой путь к использованию OpenGL контекста к слою OpenCL – тем самым позволяя данным полностью оставаться на видеокарте — и тем самым избежать проблем с задержкой памяти.
Если нужно сделать много независимых вычислений, посмотрите на Aparapi. Там много примеров дающих понять, как использовать параллельные вычисления.
В добавок, есть некоторый проект под названием TornadoVM — он автоматически переносит подходящие вычисления из CPU в GPU, таким образом, обеспечивая массовую оптимизацию из коробки.
Выводы
Есть много приложений, где графические процессоры могут принести некоторые преимущества, но вы могли бы сказать, что есть еще некоторые препятствия. Тем не менее, Java и GPU могут делать великие дела вместе. В этой статье я только коснулся этой обширной темы. Я намеревался показать различные варианты высокого и низкого уровня для доступа к графическому процессору из Java. Изучение этой области обеспечит огромные преимущества в производительности, особенно для сложных задач, которые требуют многочисленных вычислений, которые могут выполняться параллельно.
Комментариев нет:
Отправить комментарий