Дэвид обучает отдельных лиц и компании всему, что связано с Microsoft Azure и Azure DevOps (бывшему VSTS) и до сих пор занимается практическим консультированием и инфракодированием. Он уже 5 лет является обладателем премии Microsoft MVP (Самый ценный профессионал Майкрософт), а недавно получил награду MVP Azure. Как соорганизатор Melbourne Microsoft Cloud и Datacentre Meetup, О’Брайен регулярно выступает на международных конференциях, сочетая свой интерес к путешествиям по миру со страстью делиться ИТ-историями с сообществом. Блог Дэвида находится по адресу david-obrien.net, он также публикует свои онлайн-тренинги по Pluralsight.
В выступлении рассказывается о важности метрик для понимания того, что происходит в вашей среде и того, как работает ваше приложение. Microsoft Azure имеет мощный и простой способ отображения метрик для всех видов рабочих нагрузок, и в лекции говорится, как можно все их использовать.
В 3 часа ночи, в воскресенье, во время сна вас внезапно будит сигнал текстового сообщения: “сверхкритическое приложение снова не отвечает”. Что же происходит? Где и в чем причина «тормозов»? Из этого доклада вы узнаете про сервисы, которые Microsoft Azure предлагает клиентам для сбора логов и, в частности, метрик ваших облачных рабочих нагрузок. Дэвид расскажет, какие метрики должны вас интересовать при работе на облачной платформе и как до них добраться. Вы узнаете об инструментах с открытым исходным кодом и построении панелей мониторинга и в результате приобретете достаточно знаний для создания своих собственных панелей.
И если вас в 3 часа ночи снова разбудит сообщение о падении критического приложения, вы сможете быстро разобраться в его причине.
Добрый день, сегодня мы будем говорить о метриках. Меня зовут Дэвид О’Брайен, я сооснователь и владелец небольшой консалтинговой австралийской компании Xirus. Еще раз благодарю за то, что пришли сюда провести со мной свое время. Итак, зачем мы здесь? Чтобы поговорить о метриках, вернее, я расскажу вам о них, и прежде чем делать какие-то вещи, начнем с теории.

Я расскажу, что такое метрики, что можно с ними сделать, на что нужно обратить внимание, как собирать и включать сбор метрик в Azure и что такое визуализация метрик. Я покажу вам, как выглядят эти вещи в облаке Microsoft и как работать с этим облаком.
Прежде чем начать, я попрошу поднять руки тех, кто использует Microsoft Azure. А кто работает с AWS? Я вижу, немногие. А с Google? ALI Cloud? Один человек! Отлично. Итак, что такое метрики? Официальное определение Национального института стандартов и технологий США выглядит так: «Метрика – это стандарт измерения, который описывает условия и правила выполнения измерения какого-либо свойства и служит для понимания результатов измерения». Что это значит?
Рассмотрим для примера метрику для изменения свободного пространства диска виртуальной машины. Например, нам выдается число 90, и это число означает проценты, то есть объем свободного пространства диска составляет 90%. Отмечу, что не слишком интересно читать описание определения метрик, которое занимает 40 страниц в формате pdf.
Однако метрика не говорит, каким образом получен результат измерения, она только показывает этот результат. Что же мы делаем с метриками?
Во-первых, измеряем значение чего-либо, чтобы затем использовать результат измерения.

Например, мы узнали объем свободного пространства диска и теперь можем его использовать, использовать эту память и т.д. После того, как мы получили результат метрики, мы должны его интерпретировать. Например, метрика выдала результат 90. Мы должны знать, что означает это число: объем свободного пространства или объем занятого пространства диска в процентах или гигабайтах, латентность сети, равную 90 мс, и так далее, то есть нам нужно истолковать смысл значения метрики. Для того, чтобы метрики вообще имели смысл, после интерпретации одного значения метрики нам нужно обеспечить сбор множества значений. Это очень важно, поскольку многие люди не осознают необходимости сбора метрик. Microsoft сделала очень легким процесс получения метрик, но вы сами должны обеспечить их сбор. Эти метрики хранятся всего 41 день и на 42-й день исчезают. Поэтому в зависимости от свойств вашего внешнего или внутреннего оборудования вы должны озаботиться тем, как сохранять метрики более чем 41 день — в виде логов, журналов и т.д. Таким образом, после сбора вы должны разместить их в каком-то месте, позволяющем при необходимости поднять всю статистику изменения результатов метрик. Поместив их туда, вы сможете начать с ними эффективную работу.
Только после того, как вы получите значения метрик, интерпретируете их и соберете, вы сможете создать SLA – соглашение об уровне предоставления услуги. Этот SLA может не иметь особого значения для ваших клиентов, он более важен для ваших коллег, менеджеров, тех, кто обеспечивает работу системы и озабочен ее функциональностью. Метрика может измерять количество тикетов — например, вы получаете 5 тикетов в день, и в данном случае она показывает скорость реагирования на запросы пользователей и быстроту устранения неполадок. Метрика не должна просто сообщать, что ваш сайт загружается за 20 мс или скорость ответа составляет 20 мс, метрика – это больше, чем просто один технический показатель.
Поэтому задача нашего разговора – представить вам развернутую картину сути метрик. Метрика служит для того, чтобы взглянув на нее, вы смогли получить полную картину процесса.
Как только мы получили метрику, то можем на 99% гарантировать рабочее состояние системы, потому что это не просто взгляд на лог-файл, в котором написано, что система работает. Гарантия 99% работоспособности означает, что, например, в 99% случаев API отвечает с нормальной скоростью 30 мс. Это именно то, что интересует ваших пользователей, ваших коллег и менеджеров. Многие наши клиенты отслеживают логи веб-серверов, при этом они не замечают в них никаких ошибок и думают, что все в порядке. Например, они видят показатель скорости сети 200 мб/с и думают: «ок, все отлично!». Но чтобы добиться этих 200, пользователям требуется скорость ответа в 30 миллисекунд, и это именно тот показатель, который не измеряется и не собирается в лог-файлах. При этом пользователи удивляются, что сайт очень медленно загружается, потому что, не располагая нужной метрикой, не знают причины подобного поведения.
Но поскольку у нас есть SLA, гарантирующий 100% работоспособности, клиенты начинают высказывать возмущение, так как в действительности сайтом очень трудно пользоваться. Поэтому для создания объективного SLA необходимо видеть полную картину процесса, создаваемую собираемыми метриками. Это является предметом моего постоянного спора с некоторыми провайдерами, которые при создании SLA не представляют, что означает термин «uptime», и в большинстве случаев не объясняют своим клиентам, как работает их API.
Если вы создали сервис, например, API для третьей особы, вы должны понимать, что означает полученная метрика 39,5 – ответ, удачный ответ, ответ на скорости 20 мс или на скорости 5 мс. Именно вы должны адаптировать их SLA к своему собственному SLA, к своим собственным метрикам.
Выяснив все это, можно приступить к созданию шикарной панели мониторинга. Скажите, кто-нибудь уже пользовался приложением для интерактивной визуализации Grafana? Отлично! Я большой фанат этого open source, потому что эта штука бесплатная и ею легко пользоваться.

Если вы еще не пользовались Grafana, я расскажу, как с ней работать. Кто родился в 80-90-х, наверное, помнит заботливых медвежат CareBears? Не знаю, насколько эти мишки были популярны в России, но в отношении метрик мы должны выступать такими же «заботливыми мишками». Как я сказал, вам нужна развернутая картина работы всей системы, и она не должна касаться только лишь вашего API, вашего веб-сайта или службы, запущенной на виртуальной машине.

Вы должны организовать сбор тех метрик, которые наиболее полно отражают работу всей системы. Большинство из вас являются разработчиками ПО, поэтому ваша жизнь постоянно меняется, приспосабливаясь к новым требованиям продукта, и точно так же, как вы озабочены процессами кодирования, вы должны озаботиться метриками. Вы должны знать, каким образом метрика касается каждой строки написанного вами кода. Например, на следующей неделе вы начинаете новую маркетинговую компанию и ожидаете, что ваш сайт посетит большое количество пользователей. Для анализа этого события вам понадобятся метрики, и возможно, нужна будет целая панель для отслеживания активности этих людей. Метрики понадобятся вам для того, чтобы разобраться, насколько удачна и как в действительности работает ваша маркетинговая компания. Они помогут вам, например, разработать эффективную CRM — систему управления взаимоотношений с клиентами.
Итак, давайте приступим к нашему облачному сервису Azure. В нем очень легко находить и организовывать сбор метрик, потому что здесь имеется Azure Monitor. Этот монитор централизует управление конфигурацией вашей системы. Каждый из элементов Azure, который вы хотите применить в своей системе, имеет множество включенных по умолчанию метрик. Это бесплатное приложение, которое работает прямо «из коробки» и не требует никаких предварительных настроек, вам не нужно ничего писать и «прикручивать» к своей системе. Мы убедимся в этом, просмотрев следующее демо.

Кроме того, имеется возможность отправлять эти метрики сторонним приложениям, таким как система хранения и анализа логов Splunk, облачное приложение по управлению логами SumoLogic, инструмент для обработки логов ELK, IBM Radar. Правда, тут имеются небольшие различия, которые зависят от используемых вами ресурсов – виртуальной машины, сетевых сервисов, баз данных Azure SQL, то есть использование метрик отличается в зависимости от функций вашей рабочей среды. Не скажу, что эти различия серьезны, но, к сожалению, они все же присутствуют, и это следует учитывать. Включение и пересылка метрик возможна несколькими способами: через Portal, CLI/Power Shell или с помощью шаблонов ARM.
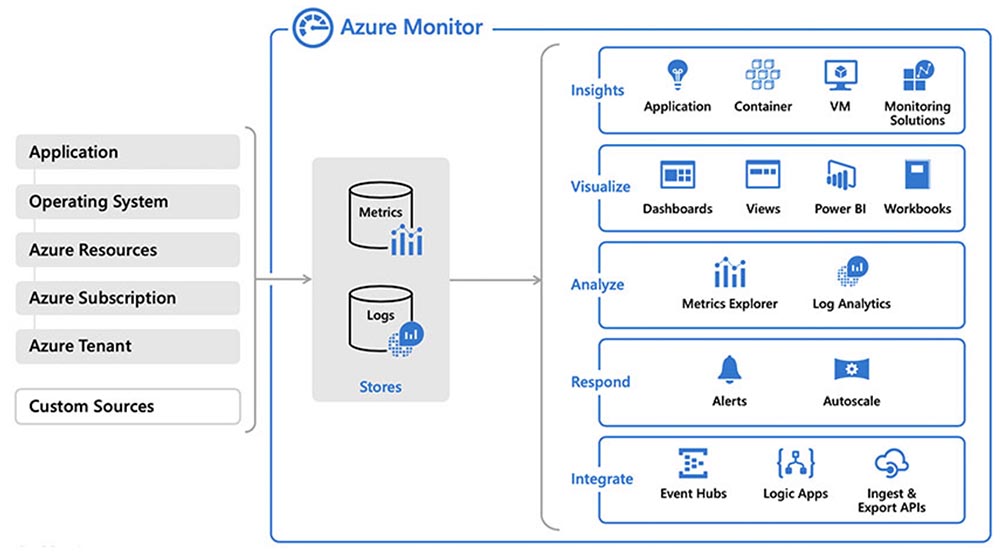
Прежде чем приступить к первой демонстрации, я отвечу на имеющиеся у вас вопросы. Если вопросов нет, приступим. На экране показано, как выглядит страница Azure Monitor. Кто-нибудь из вас может сказать, что этот монитор не работает?
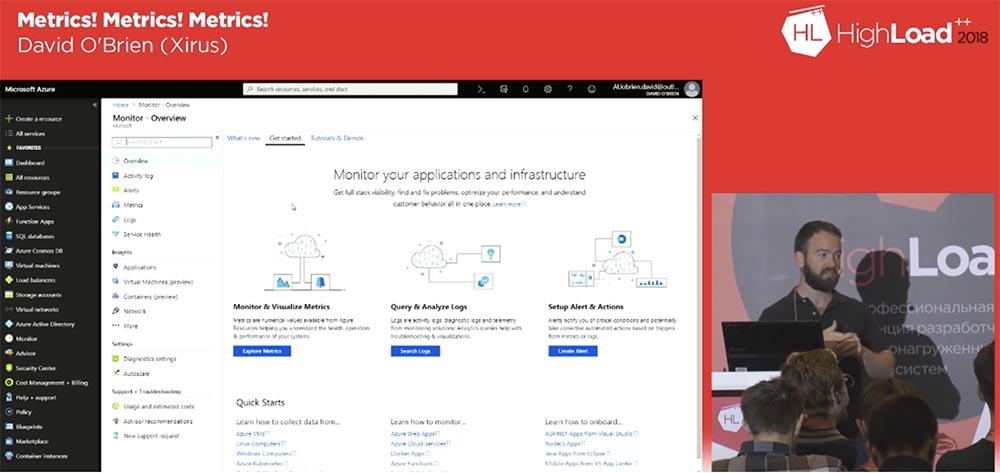
Итак, теперь все в порядке, вы видите, как выглядят сервисы монитора. Могу сказать, что это отличный и очень простой инструмент для повседневной работы. С его помощью можно осуществлять мониторинг приложений, сети и инфраструктуры. Недавно интерфейс мониторинга был улучшен, и если раньше сервисы располагались в разных местах, то сейчас вся информация по сервисам консолидируется на домашней странице монитора.
Таблица метрик – это вкладка по пути Home\Monitor\Metrics, на которую можно зайти, чтобы увидеть все имеющиеся метрики и выбрать необходимые. Но если вам нужно включить сбор метрик, нужно использовать путь каталога Home\Monitor\Diagnostic settings и проверить чекбоксы метрик Enabled/Disabled. По умолчанию практически все метрики находится во включенном состоянии, но если нужно включить что-то дополнительное, то вам понадобится изменить статус диагностики с Disabled на Enabled.
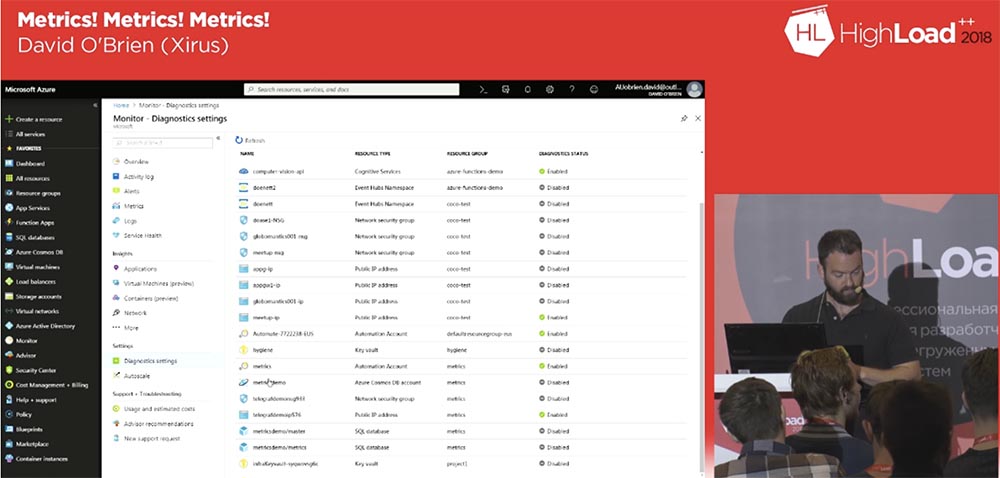
Для этого нужно кликнуть по строке выбранной метрики и на открывшейся вкладке включить режим диагностики. Если вы собираетесь анализировать выбранную метрику, то после нажатия на ссылку Turn on diagnostic нужно отметить в появившемся окне чекбокс Send to Log Analytics.
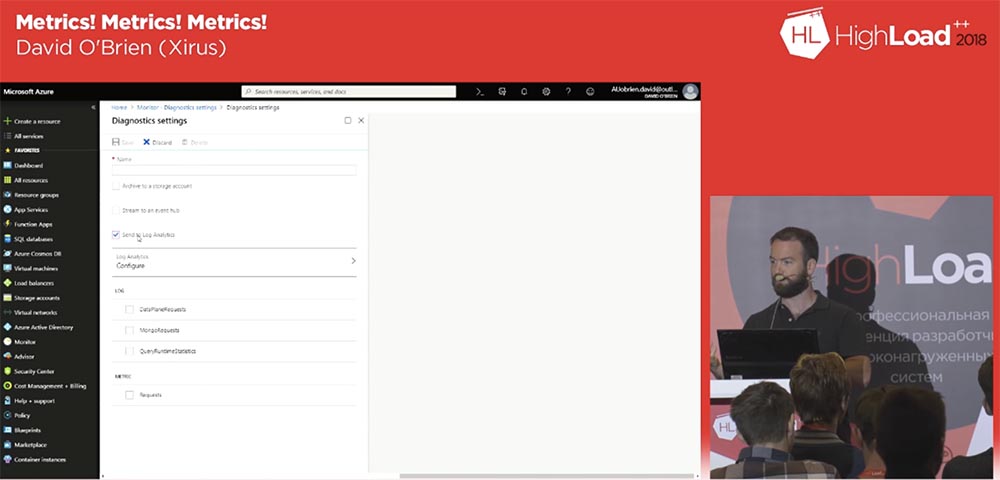
Log Analytics немного похож на Splunk, но стоит дешевле. Этот сервис позволяет собирать все ваши метрики, логи и все, что вам понадобится, и размещать их в рабочем пространстве Log Analytics. Сервис использует специальный язык обработки запросов KQL – Kusto Quarry Language, его работу мы рассмотрим в следующем демо. Пока что отмечу, что с его помощью вы можете формировать запросы относительно метрик, логов, терминов, тенденций, шаблонов и т.д. и создавать панели мониторинга.
Итак, мы отмечаем чекбокс Send to Log Analytics и чекбоксы панели LOG: DataPlaneRequests, MongoRequests и QueryRuntimeStatistics, а ниже на панели METRIC – чекбокс Requests. Затем присваиваем какое-либо имя и сохраняем настройки. В командной строке это представляет собой две строчки кода. Кстати, оболочка Azure Cloud в этом смысле напоминает Google, который тоже позволяет использовать командную строку в вашем веб-браузере. AWS не имеет ничего подобного, так что Azure в этом смысле намного удобнее.
Например, я могу запустить демо через веб-интерфейс, не используя для этого никакого кода на своем ноутбуке. Для этого я должен пройти аутентификацию с помощью своего аккаунта Azure. Далее можно использовать, например, terrafone, если вы им уже пользуетесь, дождаться подключения к сервису и получить рабочую среду Linux, которую Microsoft использует по умолчанию.

Далее я использую Bash, встроенный в Azure Cloud Shell. Очень полезной штукой является встроенный в браузер IDE, облегченная версия VS Code. Далее я могу зайти в свой шаблон метрики ошибок, изменить его и настроить под свои потребности.
Настроив в этом шаблоне сбор метрик, вы можете применить его для создания метрик для всей своей инфраструктуры. После того, как мы применили метрики, собрали и сохранили их, нам понадобится их визуализировать.

Azure Monitor занимается только метриками и не дает возможность получить общую картину состояния вашей системы. У вас может использоваться ряд других приложений, которые запущены вне среды Azure. Так что если вам нужно мониторить все процессы, визуализировав все собранные метрики в одном месте, то Azure Monitor для этого не подойдет.
Для решения этой задачи Microsoft предлагает инструмент Power BI – комплексное ПО для бизнес анализа, включающее в себя визуализацию самых различных данных. Это довольно дорогой продукт, стоимость которого зависит от необходимого вам набора функций. По умолчанию он предлагает вам 48 видов обрабатываемых данных и связан с хранилищами данных SQL Azure, Azure Data Lake Storage, cлужбами машинного обучения Azure и Azure Databricks. Используя масштабируемость, вы каждые 30 минут можете получать новые данные. Этого может быть достаточно для ваших потребностей или не достаточно, если вам нужна визуализация мониторинга в режиме реального времени. В этом случае рекомендуется использовать такие приложения, как упомянутую мною Grafanа. Кроме того, в документации Microsoft описана возможность отправки метрик, логов и таблиц событий с помощью SIEM — инструментов в системы визуализации Splunk, SumoLogic, ELK и IBM radar.
23:40 мин
Продолжение будет совсем скоро…
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас:Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Комментариев нет:
Отправить комментарий