
Yelp — это крупнейшее в США приложение для заказа еды и услуг. Оно установлено более чем на 30 млн уникальных устройств, в нём зарегистрировано более 5 млн. компаний. Для хранения и доступа к данным в Yelp используют Cassandra. Как и для каких задач применяется эта база данных, на конференции Cassandra Day Russia 2021 рассказал Александр Широков, Database Reliability Engineer в Yelp.
Cassandra — это база данных из семейства NoSQL. Согласно полному определению, это distributed wide-column NoSQL datastore. Cassandra оптимизирована для write’ов, и consistency запросов можно двигать на очень низком уровне.
Не углубляясь в детали, я расскажу, как мы используем Cassandra в Yelp. У нас это один из самых популярных инструментов. Мы применяем MySQL и Cassandra. Если MySQL все девелоперы знают, то Cassandra нет. Но это то, что мы используем постоянно и на довольно большом масштабе.
Я расскажу:
- Как мы автоматизируем изменение схемы: как девелоперы изменяют таблицы, добавляют таблицы или колонки. Если позволить им делать это по своему усмотрению, то получается очень много проблем. Чтобы их избежать, мы этот процесс автоматизировали.
- Как разработчик получает доступ к Cassandra. Один из вариантов — находить каждый инстанс Cassandra-кластера через host и port, но это решение не масштабируется. Я покажу статистику по нашим кластерам и вы увидите, что на нашем масштабе нужно что-то другое.
- Закончу одним из проектов, над которым мы работаем сейчас, и который выглядит довольно многообещающим.
Как используется Cassandra в Yelp
В любой месяц отправляется около 90 млрд запросов, в любой момент времени задеплоено около 60 Kubernetes-кластеров и около 500 подов (один под — один инстанс Cassandra).
С точки зрения нагрузки на кластеры, наша самая высокая Read Load — около 600 тыс. RPS на один из наших кластеров, Write Load — около 400 RPS. В целом довольно высокая нагрузка.

В Yelp мы поддерживаем широкий спектр пользовательских кейсов. Мы поддерживаем и аналитический процессинг, и процессинг транзакций. Например, есть какой-то batch-сервис, онлайн или веб-сервис, который отправляет запросы в Cassandra и что-то пишет в Cassandra.
Также наша стриминг-инфраструктура зависит от Cassandra. Плюс мы собираем в Cassandra данные для аналитики, агрегируем какие-то метрики; от Cassandra зависит наша caching-инфраструктура и distributed tracing — возможность для разработчиков трейсить жизненный цикл реквеста в Yelp, смотреть, как реквест движется между микросервисами (трейсинг инфраструктуры).
Как вы видите, спектр юзкейсов довольно широкий.
Мы деплоим Cassandra в основном в двух регионах: us-east и us-west.
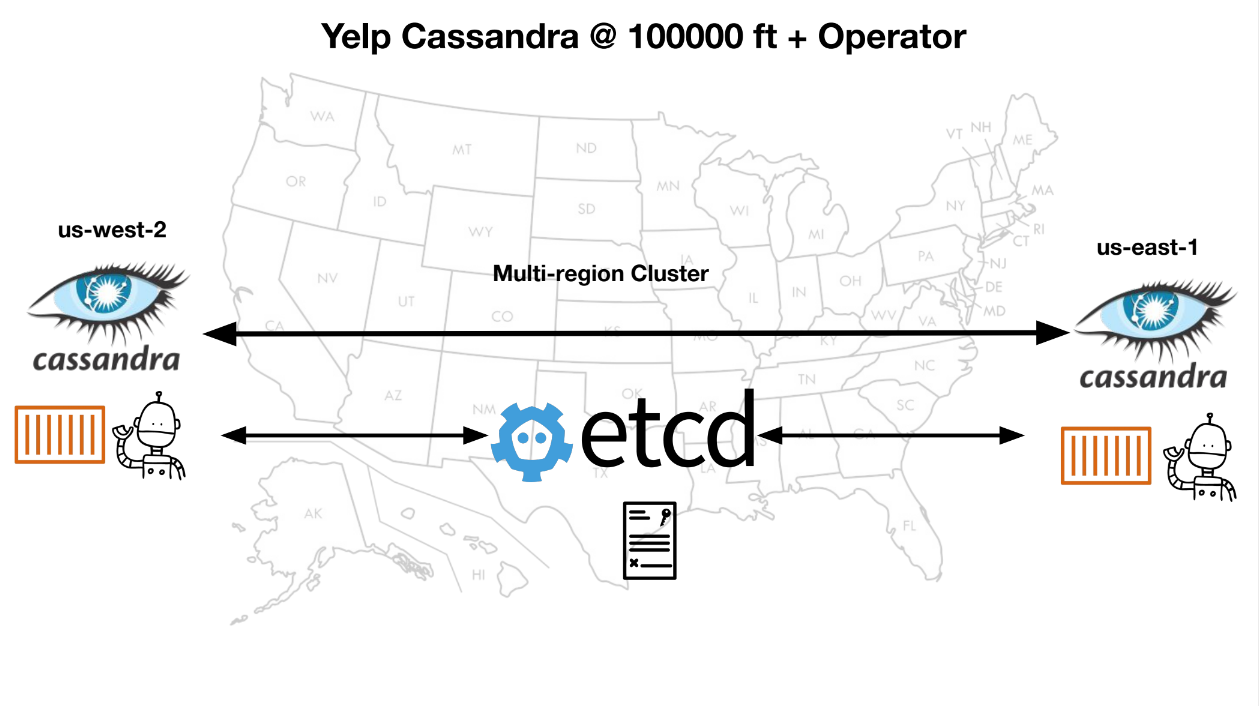
Несмотря на то, что мы деплоим на us-east и us-west, каждый наш кластер называется multi region cluster. Если клиент хочет написать в us-east, а тот недоступен, тогда он напишет в us-west.
В каждом регионе мы деплоим (так как у нас инфраструктура основана на Kubernetes) наш собственный разработанный Kubernetes-оператор. Роль этого оператора — мы даём ему кастомные ресурсы смотреть на Cassandra: количество подов, которые должны быть в любой момент времени, или какие-то значения CPU и памяти. Оператор просто сравнивает те значения, которые мы ему даём, с тем, что происходит на самом деле — мониторит кластер. И если случается несовпадение, то оператор поднимет ещё один под.
Например, оператору сказали, что нужно пять подов, а сейчас задеплоено только четыре, он поднимет ещё один. Это снимает много работы с нас, как с команды, которая занимается поддержкой инфраструктуры. Синхронизация происходит с помощью etcd. Etcd — это простенький distributed key-value store.
Мы деплоим всё на AWS, для хранения самих данных используем EBS volumes — Amazon Elastic Block Storage. Вся инфраструктура основана на Kubernetes, плюс мы разработали собственный оператор.
Для подключения клиента к каждому кластеру, каждому инстансу кластера мы используем продукт Smartstack, а в следующей итерации Envoy.
Как в Yelp делают изменение схемы (Schema Changes)
С чего можно начать автоматизировать этот процесс: можно взять все схемы (schema), которые есть, и засунуть в один репозиторий — самый простой вариант. И потом на каждой Cassandra node запустить процесс, который будет смотреть на то, что у нас в репозитории и то, что у нас в Cassandra, сравнивать, и если у нас тут есть какая-нибудь схема (например, какая-то таблица), а в кластере Cassandra она не существует, она просто создаст новую таблицу — так, чтобы они просто совпадали.
Если, например, несовпадение, так, чтобы мы знали, что происходит, что делает этот процесс, процесс файлит Jira-тикет.
Это то как мы начинали. Но в этом есть несколько проблем: довольно сложно поддерживать Alter Table стейтменты. Сложно понять, куда это вообще, как это поддерживать. Разработчики не знали про это. Каждый раз, когда разработчикам нужно было изменить таблицу, они шли к нам и спрашивали. Это такая проблема, о которой нам нужно было бы рассказывать разработчикам каждый раз. Можно было бы, конечно, записать это куда-то в документацию, но у кого есть время её читать?
Если разработчики создают какую-то схему, они засабмитят в гит-репозиторий, но у них никакого фидбека, нет обратной связи, когда эта схема будет применена на сам кластер, потому что процесс, который запускается на Cassandra, он, естественно, не постоянный, как butch-процесс, который периодически пулит и пытается применить изменения. Также изменения схем были применены в очень рандомном порядке в наших окружениях. То есть у нас есть несколько окружений: development, staging, production, и возможен был такой вариант, когда production была применена ранее, чем development.
Вторая проблема — это то, что нет контекста. Когда разработчики самбитили новую схему или новую таблицу, то мы получали вот такую историю в гит-комит, и непонятно было, что произошло.
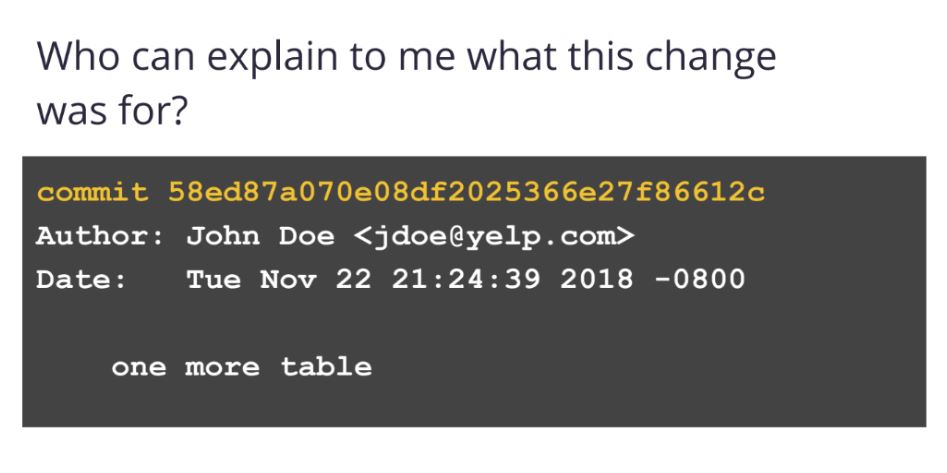
Если нам нужно было ревью каждого изменения схемы, не было процессов, когда мы, как инженеры по Database Reliability, обязательно бы это делали. И в том числе, когда разработчики пишут их SQL-команды, чтобы создать таблицу, например, не было никакой обратной связи с точки зрения ошибок: они написали, но не было возможности им сказать, что, например, вот этот тип колонки не поддерживается, или вы что-то делаете не так.
То есть довольно много проблем с таким процессом. Даже несмотря на то, что он работал изначально, мы открыли такие небольшие сюрпризы. И нам нужно было объяснять это разработчикам каждый раз, что вот это происходит, и если какие-то изменения были закомичены, то очень сложно найти, где была проблема. Нужен был постоянный дебаг — что произошло. Если какая-то SQL statement была написана неправильно или неоптимально.
Как всё работает сейчас
Для начала надо дать терминологию. В Yelp используется pushplan — это файл, который хранит инструкции по тому, как задеплоить какой-то код. Мы используем это в довольно широком контексте. Например, в контексте любой инфраструктурной работы. Если нам надо изменить часть инфраструктуры, добавить значение в конфиг, то мы обычно пишем pushplan. И эта pushplan-терминология используется и в случае с Cassandra.
Расскажу буквально в паре слов, как процесс выглядит сейчас с точки зрения инженера в Yelp. Если они хотят создать новую таблицу или новый keyspace в Cassandra, они создают папку pushplan и на каждом dev-боксе, который инженер использует, есть utility-функция или команда, которая называется pushplan. Они создают этот pushplan, этот текстовый файл с инструкциями, где они задают буквально пару значений: Jira-тикет, кластер, где они хотят создать, название keyspace, название таблицы и тип базы данных. В итоге эта функция генерирует SQL-файл.
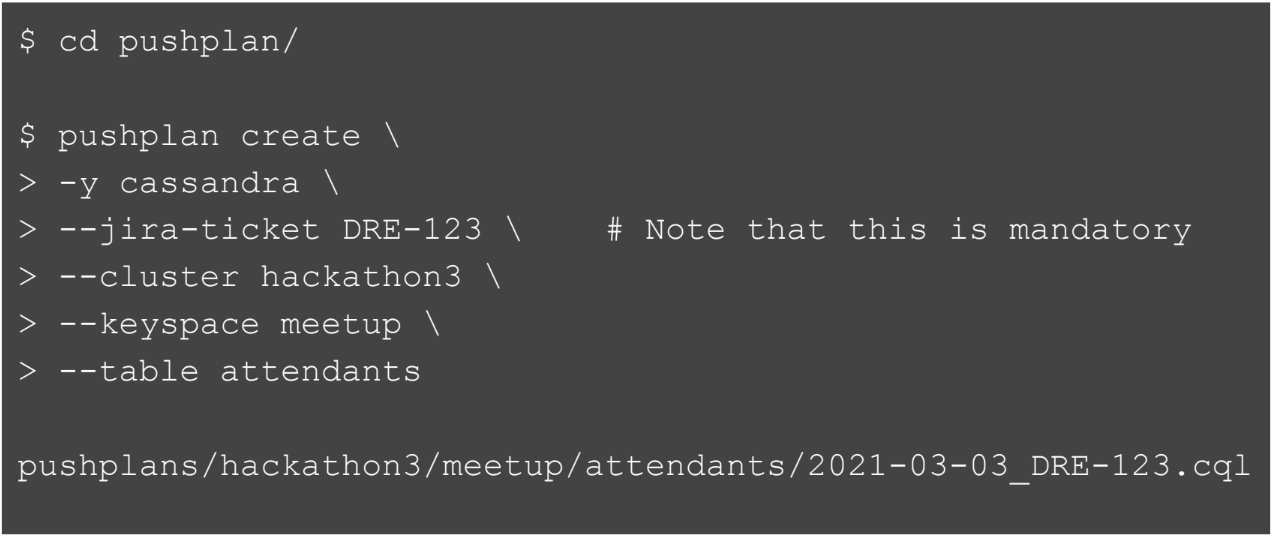
Затем они пишут саму SQL-команду. То есть разработчики пишут, например, create table. Когда они пытаются «сгенерировать» pushplan, мы тут же можем применить… так как всё автоматизировано, у нас есть контроль по тому, что мы можем делать с SQL-командами.
Разработчики видят, вот прямо сейчас, получают этот фидбек на их команду. Они видят, например, что стринг — это не вали
дный тип данных. Рядом с указанием на ошибку мы даём ссылку на информацию о том, как пофиксить эту ошибку.
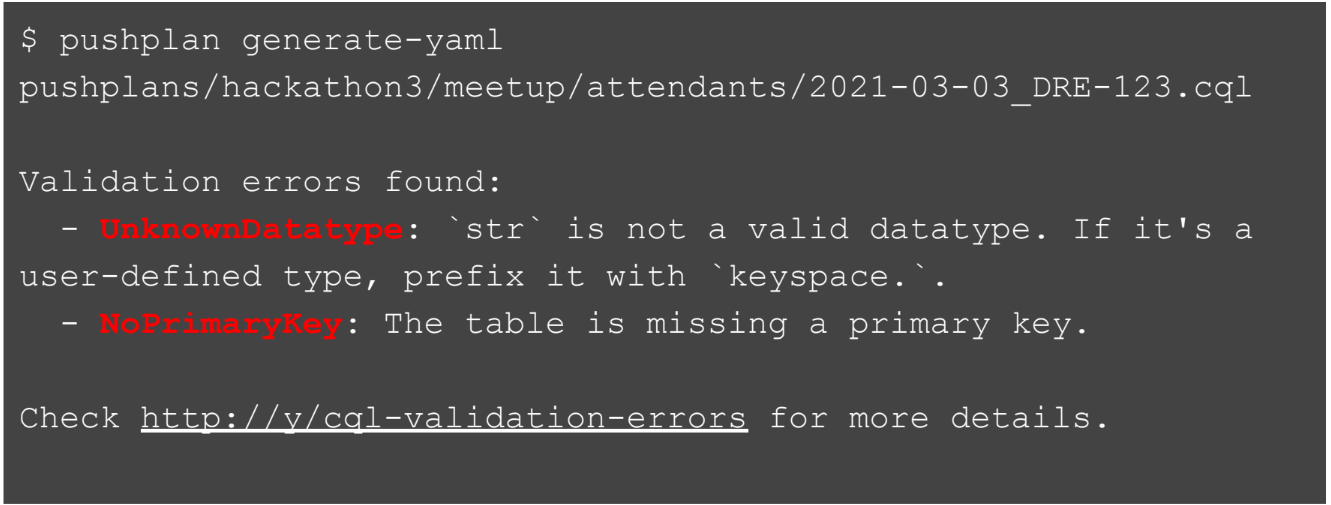
Разработчик исправляет ошибку, генерирует файл снова, теперь всё сработало отлично.

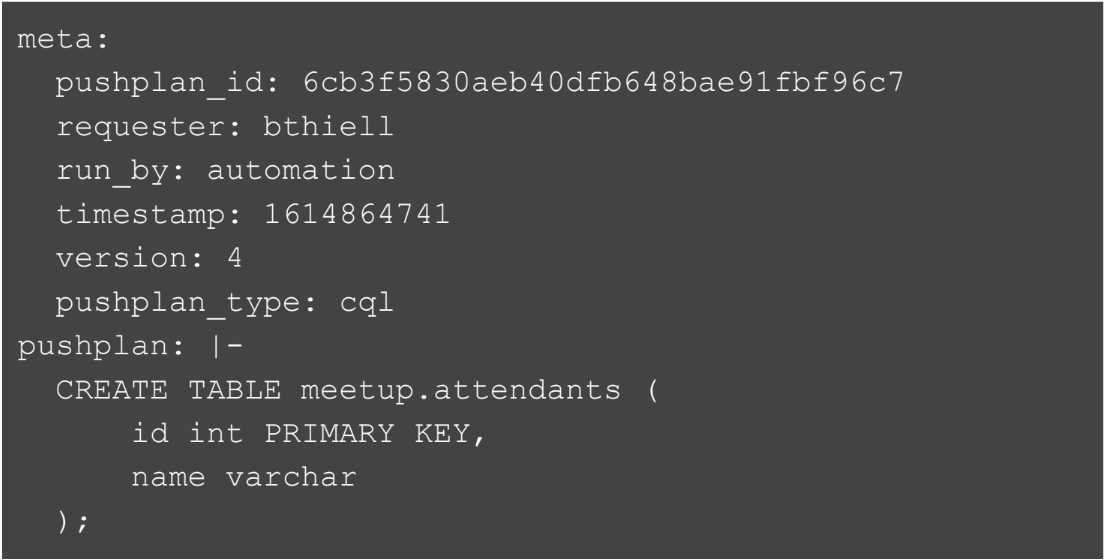
Пример файла, который сгенерируется: есть уникальный ID, имя автора, время, версия и сама команда.
Дальше разработчики открывают пул-реквест. Кто-то из команды DRE проверяет и говорит, что всё отлично, и мы мёрджим этот коммит.
После того, как мы замёрджили коммит, девелопер получает уведомление в слаке с результатами его pushplan. То есть он может увидеть в реальном времени, что их команда применилась сначала на окружение dev, потом на stage и prod. И видит, когда это случилось. Разработчики также могут запрашивать статус и видеть, на каких окружениях уже применяется и на каких нет. Если где-то ошибка, то могут увидеть, где она произошла. Для каждого кластера можно видеть историю, как изменялась схема всех таблиц.
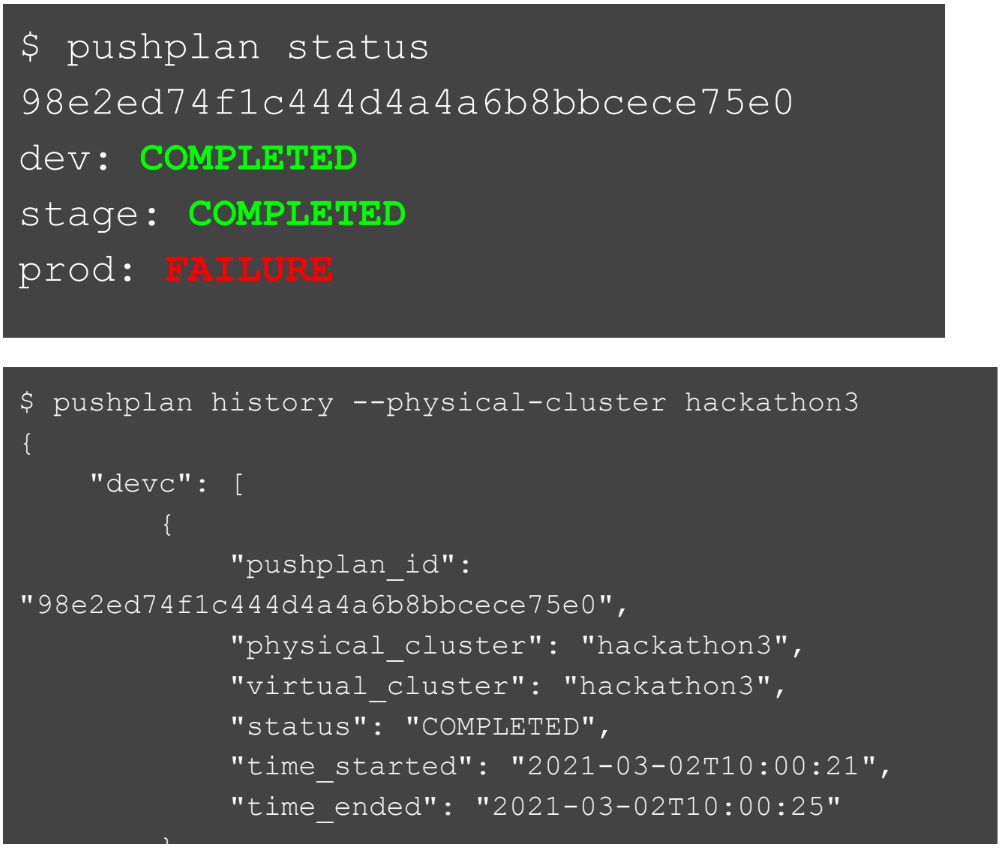
Какие преимущества мы получили:
- Разработчикам не надо вручную тестировать SQL-команды. Им не нужно переживать, что они не смогут исправить ошибку, если вдруг допустят её. Мы дадим им фидбек сразу, как только они напишут, довольно автоматизированным способом.
- Мы как DRE-команда можем делиться best practices. Мы можем им сказать, например, что каждая таблица должна содержать как минимум один primary key; не нужно изменять какие-то колонки или что 20 колонок в одном pushplan — это не лучшее решение. Мы также можем добавить правила проверки.
Вот так это и работает.
Cassandra для разработчиков
Теперь я немного расскажу, как Cassandra используется разработчиками: как они получают доступ к Cassandra-кластерам или Cassandra-инстансам.
Снова начну с истории. Около семи или восьми лет назад, когда мы начали использовать Cassandra, у нас был один главный web application и буквально несколько сервисов.
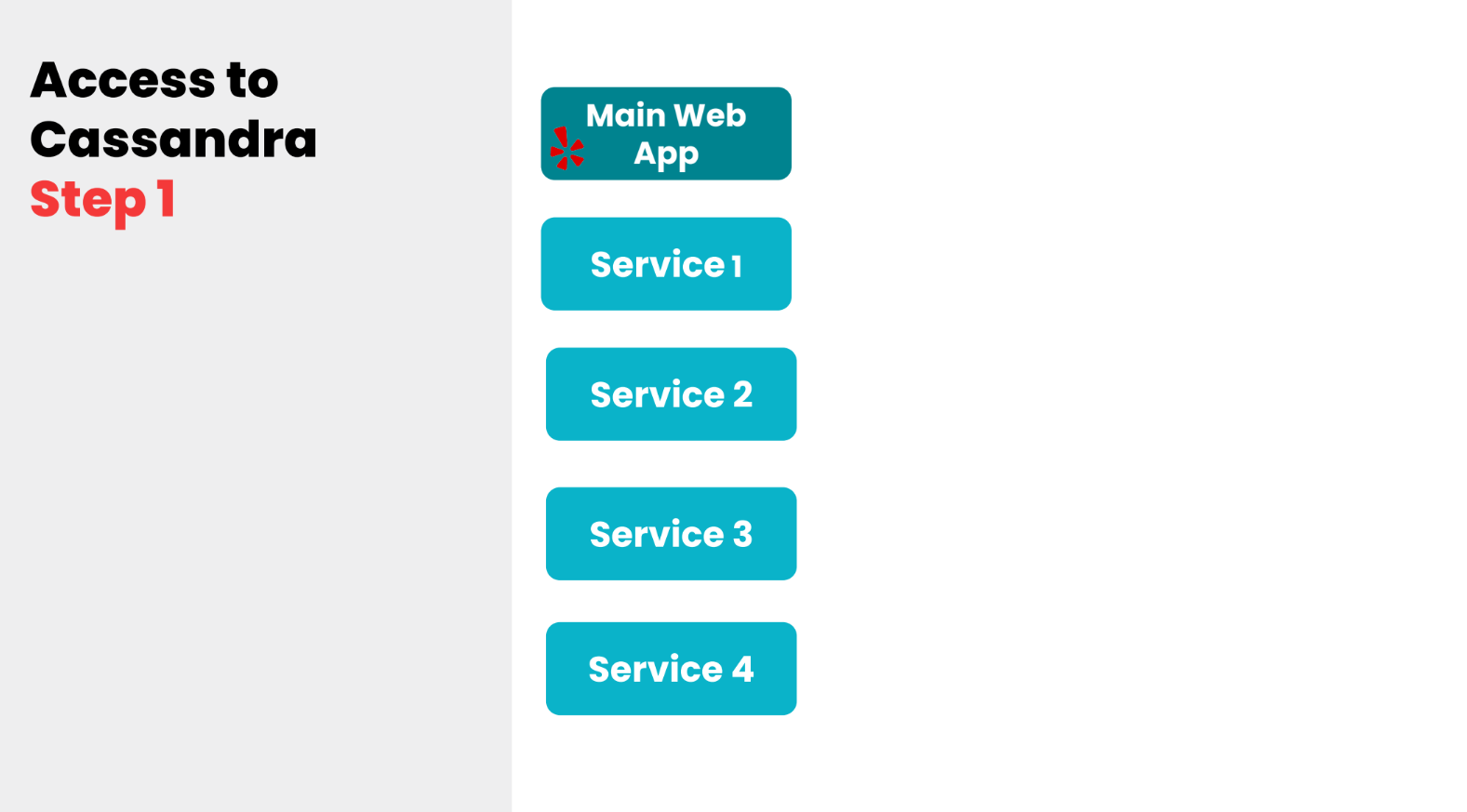
Потом мы задеплоили несколько Cassandra-кластеров и каждый сервис или каждая команда, которая работала с этим сервисом, должна была искать Cassandra-кластер вручную: искать host-порт, забивать это вручную в конфиг. С другой стороны, им тоже нужно было искать какой-то драйвер, чтобы отправлять запросы на Cassandra, эти драйверы имели разную версию — получалась очень беспорядочная ситуация. И как вы видите, нагрузка между кластерами распределялась неравномерно.
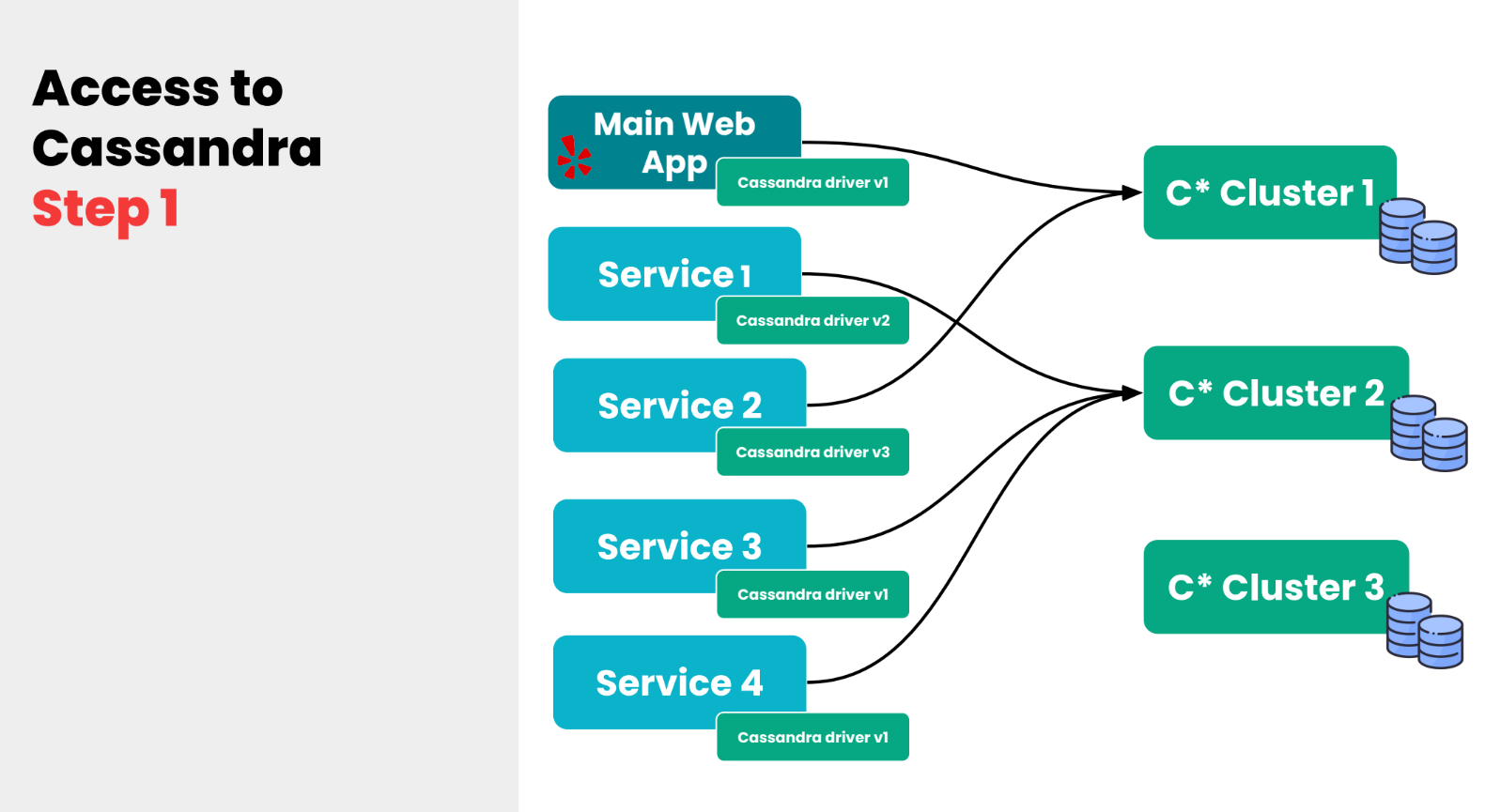
К чему мы в итоге пришли довольно рано, это мы задеплоили proxy-сервис, который мы назвали Apollo. По сути это очень простой сервис на Python, который находится между сервисами и между Cassandra-кластерами.
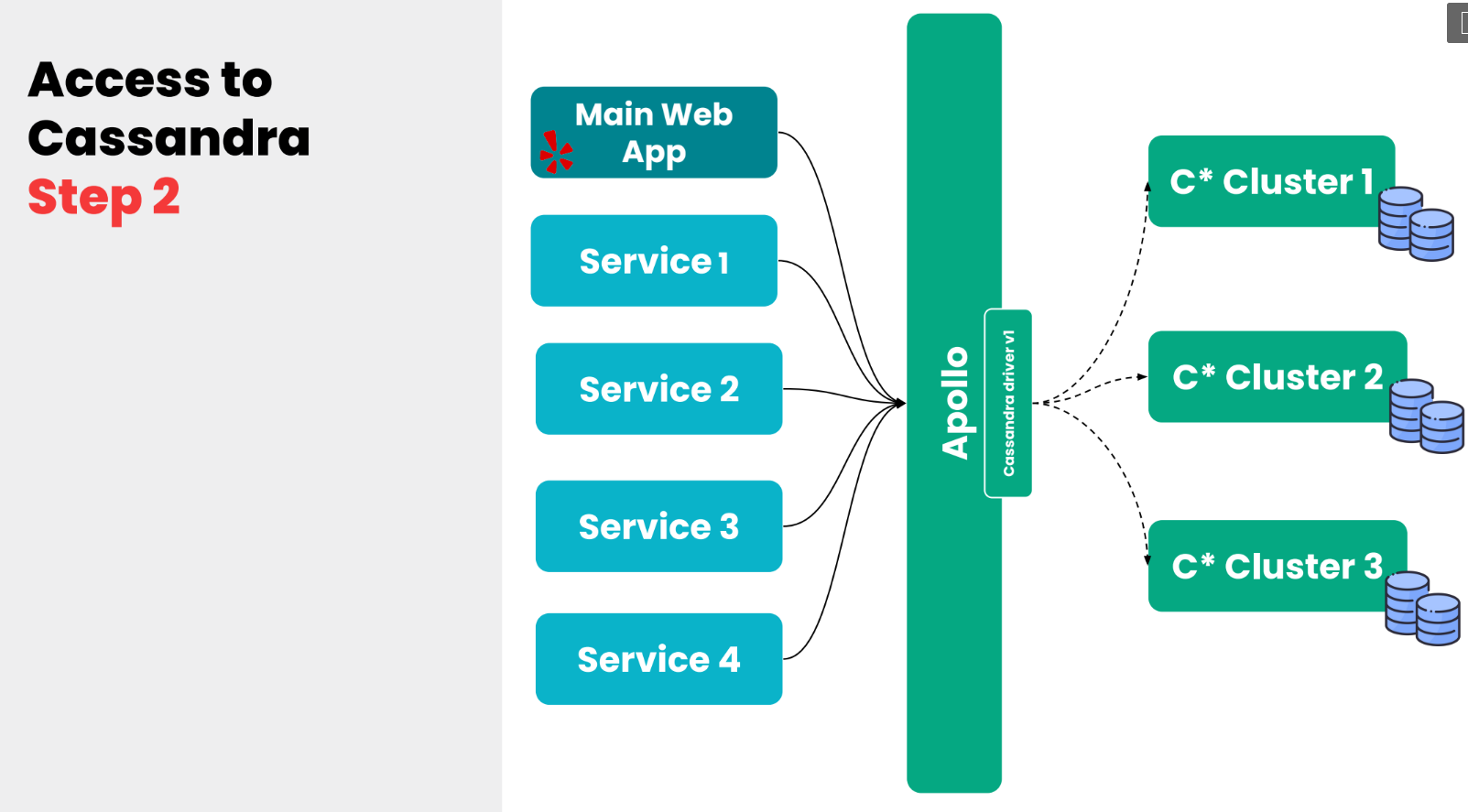
Эта абстракция позволила нам решить несколько интересных проблем. Во-первых, разработчикам больше не нужно было думать, как подключиться к Cassandra, какие host и port, не искать всё это вручную, не поддерживать драйверы Cassandra. То есть вся сложность инфраструктуры была абстрагирована от разработчиков. Всё что им нужно знать — это host и port сервиса Apollo.

Мы используем SmartStack, который я уже упоминал ранее, чтобы автоматически найти инстанс Apollo. То есть сервисам даже не нужно искать host и port, им просто нужно сказать: «подключись к Apollo», и SmartStack найдёт нужный инстанс.
Это одна проблема, которую мы решили.
Другая решённая проблема — это то, что сейчас мы, как команда DRE, могли производить эксперименты над нашим Cassandra-кластером. Мы могли, например, изменить версию драйвера Cassandra, если нам хотелось, или сделать scale up или scale down кластера, в зависимости от нагрузки, которую мы получаем. Это позволило нам равномерно распределить нагрузку на кластеры.
То есть одним proxy-сервисом мы решили несколько проблем.
Также мы могли изолировать клиентов в их собственный Apollo-кластер. Если, например, есть какие-то клиенты или сервисы, юзкейсы которых очень важны для бизнеса, мы просто изолируем их в отдельный кластер.
Ну и то что я сказал: изолирование сложности инфраструктуры от разработчиков — это большая победа. Разработчикам стало очень легко работать над их Query-кодом. Нам было очень легко работать над инфраструктурой. Но проблема в том, что за семь лет, которые этот сервис существует, сервис вырос до довольно большого размера.

Идея сервиса в том, чтобы разработчики могли там создавать свой код — добавлять бизнес-логику… И мы заметили буквально недавно, что сервис вырос и сейчас поддерживает где-то около 140 юзкейсов и коннектится практически к 40 кластерам. И этот сервис хранит около 60 тыс. строк только бизнес-логики. И каждый раз, когда мы деплоим, мы раним 60 тысяч строк integration-тестов, что занимает около часа. Масштаб сервиса расширился до сотен инстансов.
Если разработчикам нужно написать самую простую команду, select-команду, им нужно написать довольно много кода.

Например, тут вы видите, что если они хотят написать простую функцию GET_REVIEWS, им нужно писать клиент, им нужно писать стейтменты, вызвать SQL-команду и возвратить результат.
Так же нужно писать unit-тесты, нужно писать swagger spec, потому что каждый клиент — это end point или API в Apollo, и надо писать fake data и конфиги — чтобы end-to-end тесты работали правильно.

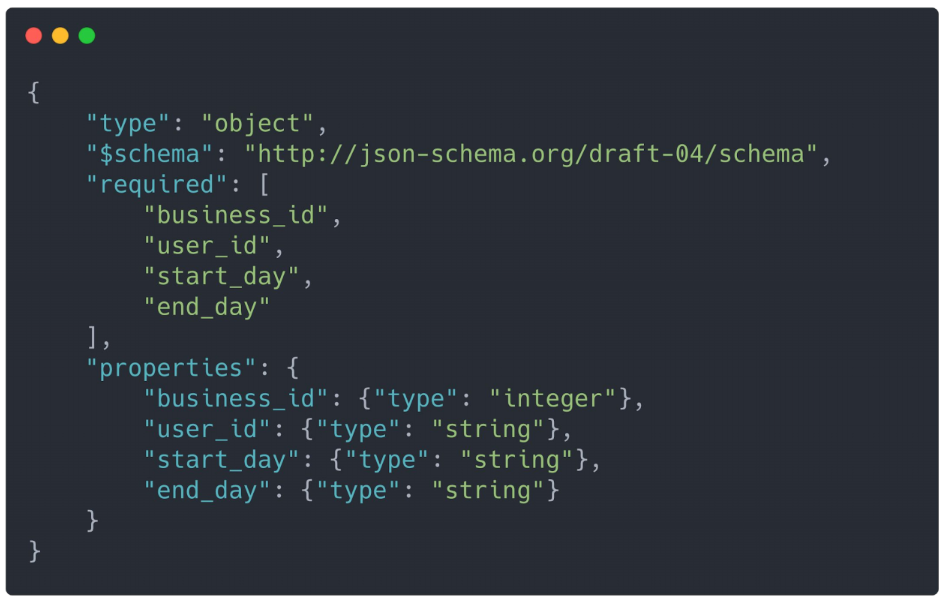
Мы заметили, что (как и с pushplan) то, что работало вначале, сейчас не работает. Просто потому, что масштаб уже совсем другой. Мы заметили, что нужен какой-то другой, новый подход к решению этой проблемы, но мы не хотели начинать с абсолютного нуля. У Apollo есть некоторые преимущества, которые решали интересные проблемы: например, изоляция сложности в доступе и управлении инфраструктурой. Это важная проблема.
Но с другой стороны, с каким-то новым продуктом, с заменой Apollo, решить несколько проблем:
- Увеличить скорость итераций над клиентским кодом. Избавить инженеров от необходимости писать так много кода.
- Облегчить доступ к Cassandra-кластеру, ну и в целом модернизировать технологии, которые существовали.
В итоге мы пришли к продукту, который называется Stargate. Это Open Source продукт, который сделан и используется компанией DataStax. Про него можно думать как про API для базы данных. По сути это очень лёгкий слой между слоем приложения и базой данных.
Как это работает
Вы можете думать о Cassandra-кластере, как о коллекции нод, инстансов, организованных в кольцо. Когда приходит запрос от клиента, одна из нод выбирается как координатор, и её задача — скоординировать запрос. Выбрать метрики, которые приходят от consistency requirements, от клиента, и отправить результат обратно клиенту.
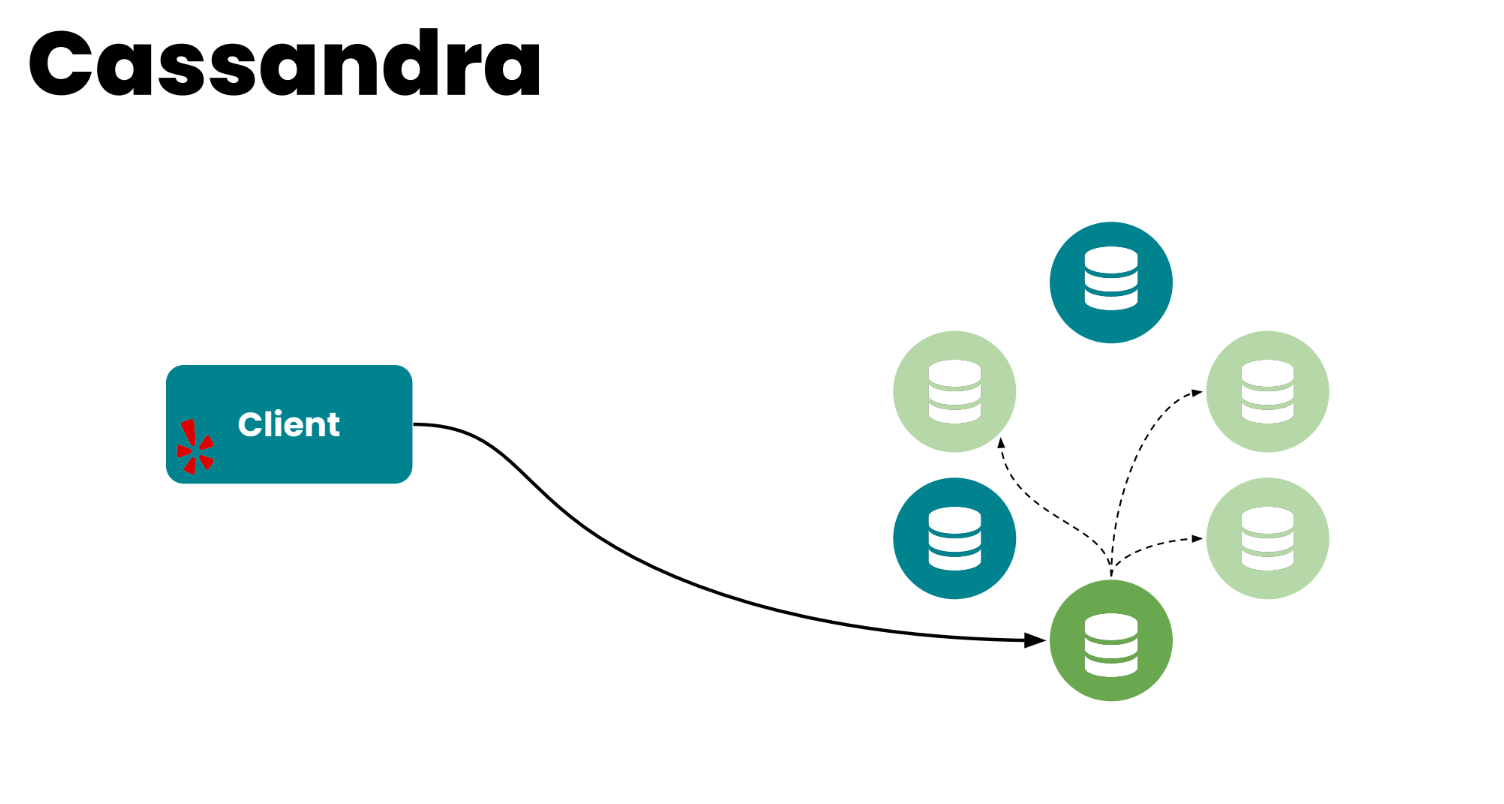
Как это работает со Stargate. Stargate присоединяется к Cassandra-кластеру как координатор нод. И его задача просто скоординировать запрос: найти реплики… Но единственное отличие в том, что Stargate не хранит никакие данные. То есть он решает две проблемы: работает как координатор, и он очень лёгкий просто потому, что ему не нужно думать о том, как хранить данные. Мы добавили небольшой proxy поверх Stargate.
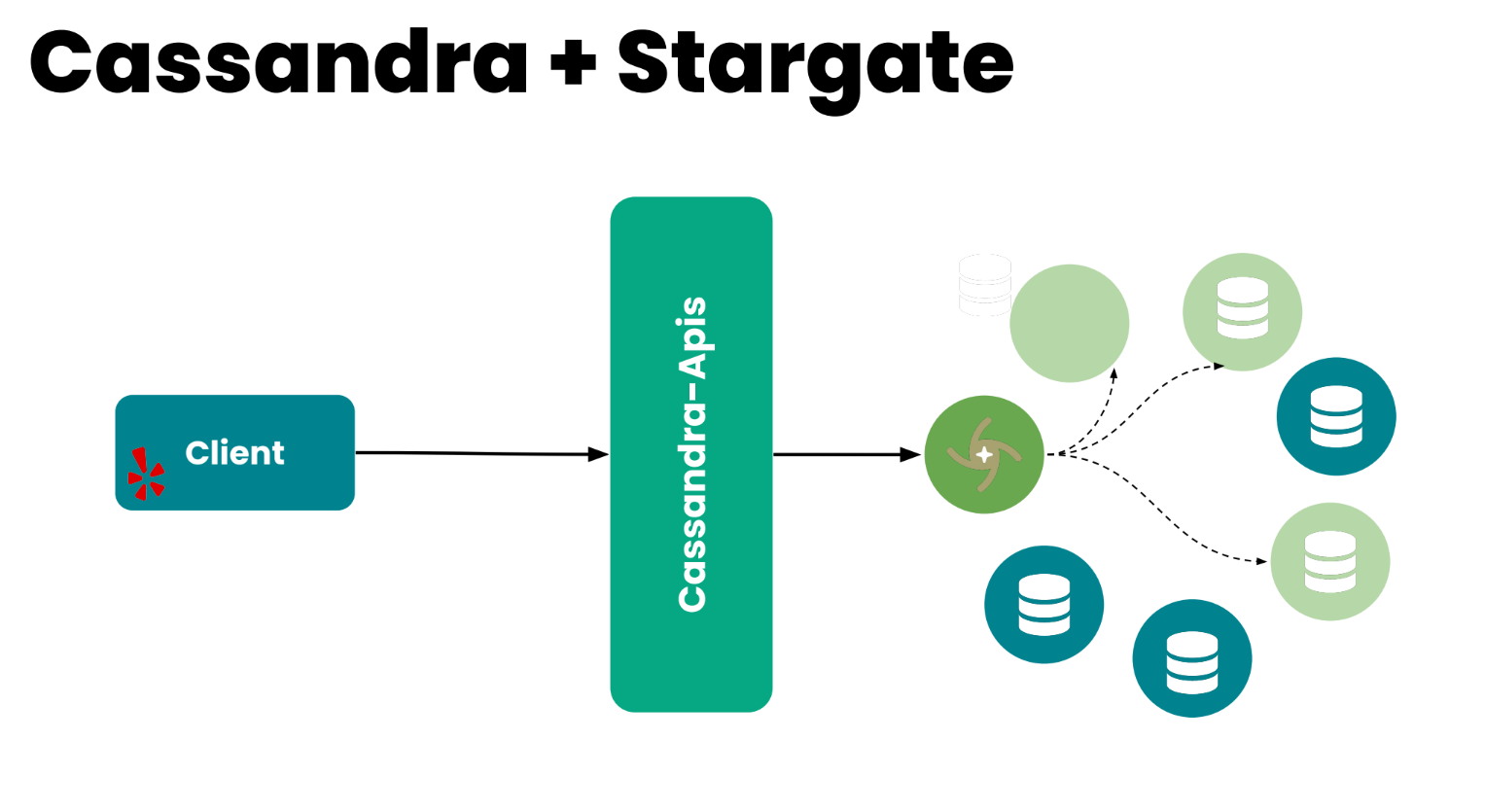
Ну и вообще, Stargate… можно думать об этом слое поверх Cassandra, который работает как координатор, но также предоставляет API для разработчиков. Он предоставляет REST API, можно коннектиться через gRPC, WebSocket или GraphQL.

Мы выбрали GraphQL API.
Почему GraphQL
Stargate берёт Cassandra schema — все таблицы, которые в key space существуют, и автоматически генерирует GraphQL-запросы. Что это даёт разработчикам: Type-safe API. GraphQL решает очень интересную проблему over и under fetching. То есть клиенты могут очень чётко сказать: нам нужно вот такие колонки возвратить. Например, то что раньше было сложнее сделать с Apollo. И также мы можем запускать несколько Cassandra-запросов в одном запросе. Если нам нужно, например, синхронизировать какие-то таблицы в разных кластерах в одном запросе.
В целом GraphQL становится новым стандартом в API development и используется в больших технологических компаниях. Например, в Facebook (откуда он и произошёл), в Twitter, Github. В Yelp мы тоже довольно давно используем GraphQL.
Что дальше
Расскажу, что мы планируем делать с проектом дальше. Надеюсь, это вам даст немного больше информации о том, как мы делаем какие-то вещи в Yelp. Расскажу, как мы задеплоили MVP (взяли Stargate и просто задеплоили одну ноду) и потом расскажу немного про клиентские библиотеки — то, как микросервисы взаимодействуют друг с другом в Yelp.
Тестирование Stargate
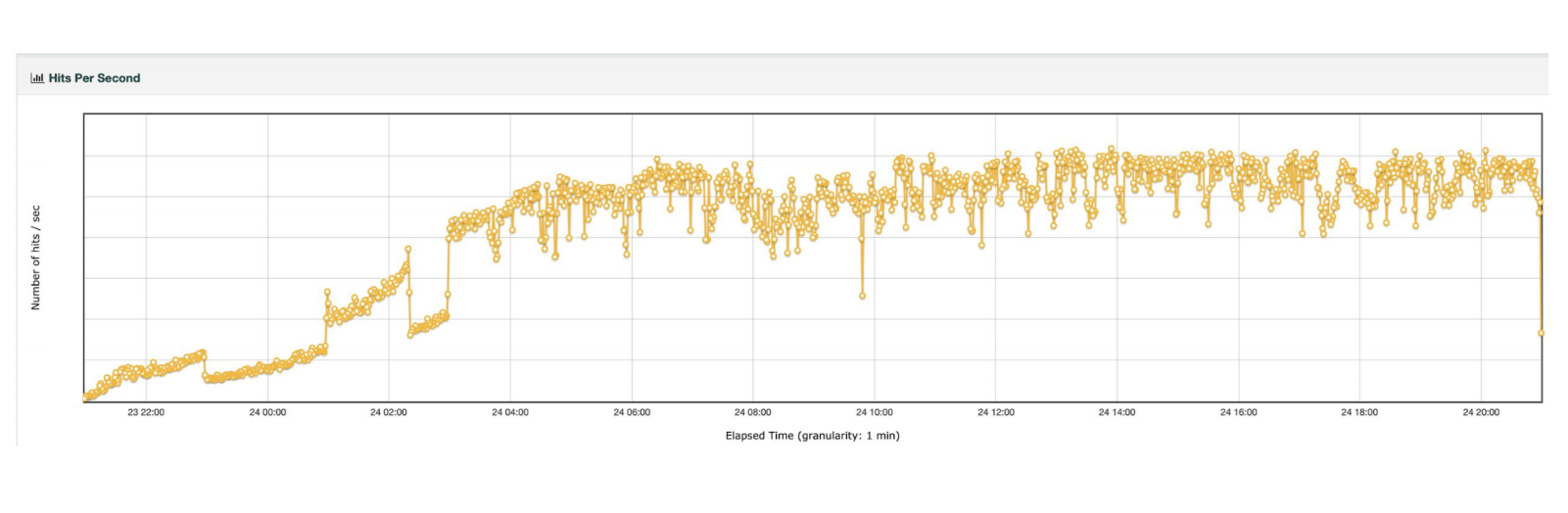
Перед тем как начать любую работу по замене Apollo, мы взяли Stargate и подумали: а что если мы задеплоим одну ноду (один node), которая присоединится к Cassandra-кластеру из трёх реплик, и потом запустим тестирование нагрузки — запустим 100 тредов, поднимем нагрузку до 3 тыс. RPS и будем ранить это в течение 24 часов. Что тогда произойдёт? А что если потестим парочку сценариев: зарестартим один из Cassandra нодов или зарестартим сам инстанс? Что произойдёт тогда?
На графике видно, что мы проводили этот тест в течение 24 часов и подняли нагрузку примерно до 3 тыс. RPS.
Если посмотреть на rage of latencies всех запросов, то они довольно в допустимом пределе. Если посмотреть на высокий хвост (high tail) задержек (99.9+), то он немного spite.
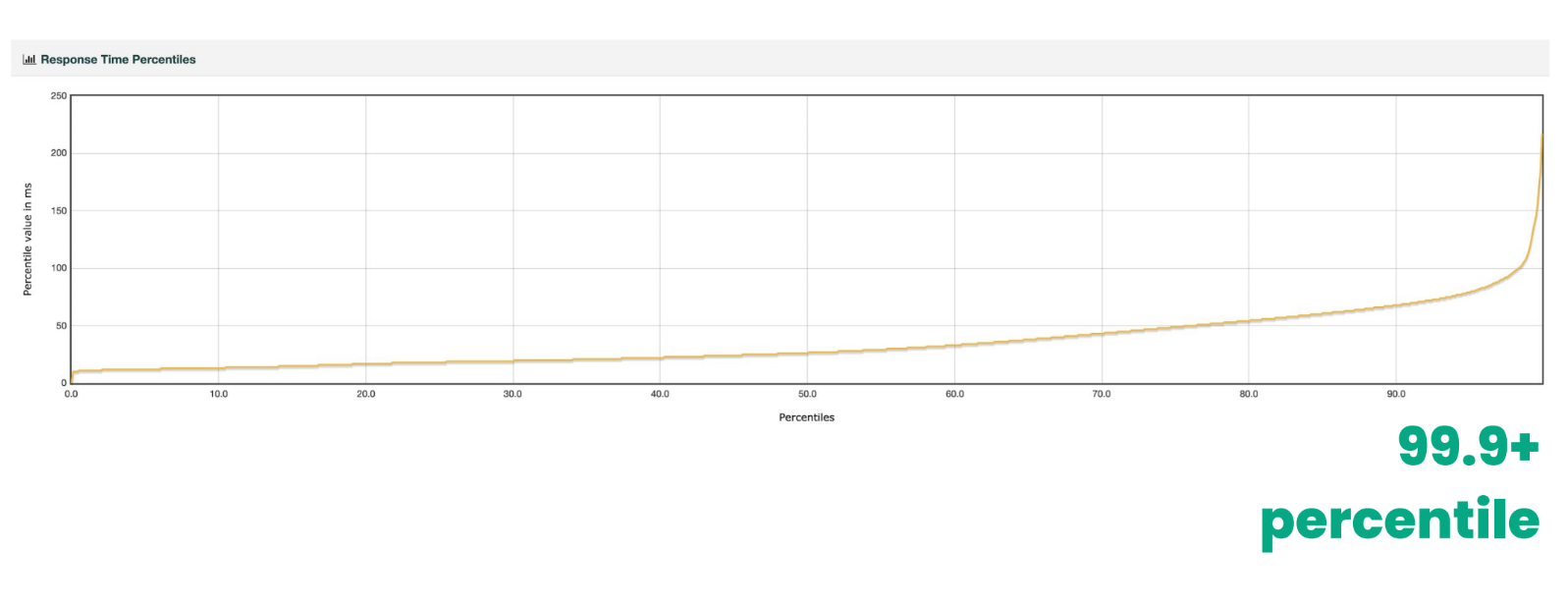
Это дало нам несколько интересных инсайтов по тому, как Stargate работает:
- Да, память стабильная, CPU повышается вместе с нагрузкой, которую мы даём на кластер. Чтобы немного понизить high tail latencies, мы немного подтюнили JVM, на которой Stargate основан.
- В конце мы автоматизировали это, чтобы мы могли ранить это в любой момент времени, как мы девелопим Stargate.
Client libraries
Если так подумать про микросервисы, то какие варианты того, как они могут общаться между собой? Один из вариантов: отправлять друг другу http-запросы, основанные на REST-интерфейсе. Но мы идём немного дальше и пытаемся облегчить этот процесс для разработчиков.
Каждый сервис определяет свой swagger spec — каждый endpoint, который экспозится сервисом. Для нашего сервиса есть один API endpoint — GraphQL/{keyspace}. То есть разработчики дают по сути keyspace и отправляют их GraphQL-запрос. Что происходит дальше: мы берём swagger spec и генерируем Client Libraries.
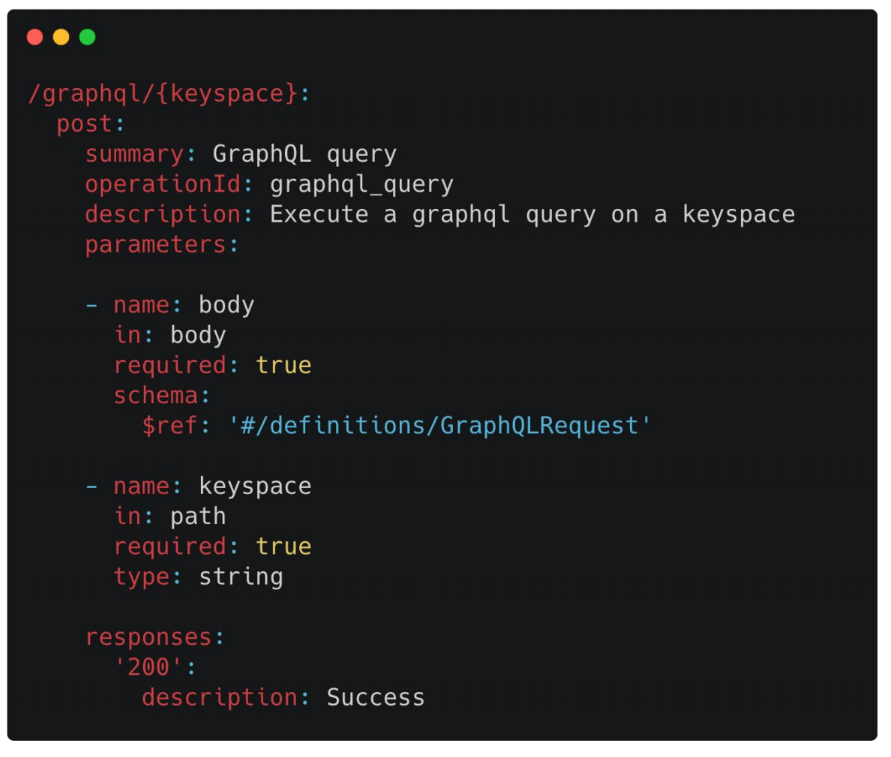
На другой стороне сервис, который хочет законнектиться в наш сервис, работает с Client Libraries как с пакетом или локальной функцией, несмотря на то, что внизу, внутри этого пакета, на самом деле абстрагируется сложность отправления всех запросов, таймауты, ретраи.
Вот пример, как клиент коннектился бы к нашему Stargate-клиенту. Ему надо просто зарепортить Client Library, вызвать GraphQL Query метод и отправить запрос.

Что это даёт:
- Мы автоматически можем абстрагировать сложность Service Discovery (обратите внимание, другой сервис нигде не пишет host и port).
- Мы имеем тонкий контроль над request budget. Например, говорим, что на какую-то страницу в Yelp максимально можем потратить 2 секунды. Запрос идёт между кучей микросервисов и мы можем сказать, что некие два микросервиса имеют бюджет 100 миллисекунды. Если мы превышаем этот бюджет, то отправлять таймаут-ответ.
- Мы можем работать с distributed tracing — инженеры могут следить, что происходит с их запросами.
- Можем обеспечивать метрики прозрачности: количество запросов, количество запросов, которые отправили ответ со статусом 200 или другим.
GraphQL Playground
Playground — это интерактивный development environment, который экспозится. Если у вас бэкенд на GraphQL, вы можете использовать Playground. Stargate делает это out of the box. По сути это такой IDE, которому вы просто говорите /graphqlschema, и вы можете в интерактивном режиме ранить запросы на Cassandra-кластер, быстро итерировать над своим GraphQL Queries.
Что он даёт: автоматически можно экспозить, автоматически открыть все возможные операции, которые можно сделать над этим кластером.
Operability
С точки зрения Operability, когда мы работали над Stargate, то было буквально несколько вещей, которые нам нужно было сделать так, чтобы включить его в нашу Yelp-инфраструктуру. Первое — это Distributed Tracing Integration. Второе — это то, что нужно заэкспортить какие-то метрики Stargate. Опять же, Load… чтобы мы могли в реальном времени наблюдать, что происходит в кластере, смотреть CPU, память…
Так как Stargate присоединяется к Cassandra-кластеру, то это даёт нам такую интересную property, чтобы мы могли заэкспортить Cassandra-метрики из этого кластера. Потом нам нужно было сделать немного изменений с точки зрения логинга (чтобы могли логить какие-то ошибки) и добавить TLS между нодами.
Комментариев нет:
Отправить комментарий