Публикация рассказывает о CPU Manager — бета-фиче в Kubernetes. CPU Manager позволяет лучше распределять рабочие нагрузки в Kubelet, т.е. на агенте узла Kubernetes, с помощью назначения выделенных CPU на контейнеры конкретного пода.
Звучит здорово! Но поможет ли CPU Manager мне?
Зависит от рабочей нагрузки. Единственный вычислительный узел в кластере Kubernetes может запускать множество подов, а некоторые из них могут запускать активные в потреблении CPU нагрузки. При таком сценарии поды могут конкурировать за ресурсы процесса, доступные на этом узле. Когда эта конкуренция обостряется, рабочая нагрузка может переместиться на другие CPU в зависимости от того, был ли погашен (throttled) под и какие CPU доступны на момент планирования. Кроме того, могут быть случаи, когда рабочая нагрузка чувствительна к переключениям контекста. Во всех этих сценариях может пострадать производительность рабочей нагрузки.
Если ваша рабочая нагрузка чувствительна по отношению к таким сценариям, можно включить CPU Manager для обеспечения лучшей изоляции производительности за счёт выделения конкретных CPU на нагрузку.
CPU Manager способен помочь нагрузкам со следующими характеристиками:
- чувствительные к эффектам CPU throttling;
- чувствительные к переключениям контекста;
- чувствительные к промахам кэша процессора;
- выигрывающие от разделения ресурсов процессора (например, кэша данных и инструкций);
- чувствительные к трафику памяти между сокетами процессора (подробное пояснение тому, что имеют в виду авторы, дано на Unix Stack Exchange — прим. перев.);
- чувствительные к hyperthreads от одного и того же физического ядра CPU или требующие их.
Ок! Как этим воспользоваться?
Использовать CPU Manager просто. Во-первых, включите его с помощью Static Policy в Kubelet, запущенных на вычислительных узлах кластера. Затем настройте гарантированный класс Guaranteed Quality of Service (QoS) для пода. Запросите целое число ядер CPU (например,
1000m или 4000m) для контейнеров, которым нужны выделенные ядра. Создайте под прежним способом (например, kubectl create -f pod.yaml)… и вуаля — CPU Manager назначит выделенные ядра процессора каждому контейнеру пода в соответствии с их потребностями к CPU.
apiVersion: v1
kind: Pod
metadata:
name: exclusive-2
spec:
containers:
- image: quay.io/connordoyle/cpuset-visualizer
name: exclusive-2
resources:
# Pod is in the Guaranteed QoS class because requests == limits
requests:
# CPU request is an integer
cpu: 2
memory: "256M"
limits:
cpu: 2
memory: "256M"
Спецификация пода, запрашивающего 2 выделенных CPU.
Как работает CPU Manager?
Мы рассматриваем три типа контроля ресурсов CPU, доступных в большинстве Linux-дистрибутивов, что будет актуально применительно к Kubernetes и собственно целям этой публикации. Первые два — это CFS shares (какова моя взвешенная «честная» доля времени CPU в системе) и CFS quota (каков максимум выделенного мне времени CPU за период). CPU Manager также использует третий, который называется CPU affinity (на каких логических CPU мне разрешено производить вычисления).
По умолчанию все поды и контейнеры, запущенные на узле Kubernetes-кластера, могут исполняться на любых доступных ядрах системы. Общее количество назначаемых shares и quota ограничены ресурсами CPU, зарезервированными для Kubernetes и системных демонов. Однако лимиты по используемому времени CPU могут быть определены с помощью лимитов на CPU в спецификации пода. Kubernetes использует CFS quota для введения в действие лимитов по CPU на контейнеры пода.
При включении CPU Manager с политикой Static он управляет выделенным пулом CPU. Изначально этот пул содержит все CPU вычислительного узла. Когда Kubelet создаёт контейнер в поде с гарантированным количеством выделенных ядер процессоров, назначенные этому контейнеру CPU выделяются ему на время его жизни и удаляются из разделяемого пула. Нагрузки от остальных контейнеров переносятся с этих выделенных ядер на другие.
Все контейнеры без выделенных CPU (Burstable, BestEffort и Guaranteed with non-integer CPU) запускаются на ядрах, оставшихся в разделяемом пуле. Кода контейнер с выделенными CPU прекращает работу, его ядра возвращаются в разделяемый пул.
Поподробнее, пожалуйста…

Приведённая выше схема демонстрирует анатомию CPU Manager. Он использует метод UpdateContainerResources из интерфейса исполняемой среды контейнера (Container Runtime Interface, CRI) для смены CPU, на которых запускаются контейнеры. Manager периодически приводит в соответствие с cgroupfs текущее состояние (State) ресурсов CPU для каждого запущенного контейнера.
CPU Manager использует политики (Policies) для принятия решения о назначении ядер CPU. Реализованы две политики: None и Static. По умолчанию начиная с версии Kubernetes 1.10 он включён с политикой None.
Политика Static назначает выделенные CPU контейнерам пода с гарантированным классом QoS, который запрашивает целое количество ядер. Политика Static пытается назначать CPU наилучшим топологическим образом и в такой последовательности:
- Назначать все CPU одного процессорного сокета, если таковые доступны и контейнер требует CPU в количестве не менее целого сокета CPU.
- Назначать все логические CPU (hyperthreads) одного физического ядра CPU, если они доступны и контейнер требует CPU в количестве не менее целого ядра.
- Назначать любые доступные логические CPU с предпочтением к CPU из одного сокета.
Как CPU Manager улучшает изоляцию вычислений?
С включённой политикой Static в CPU Manager рабочие нагрузки могут показывать лучшую производительность по одной из следующих причин:
- Выделенные CPU могут быть назначены на контейнер с рабочей нагрузкой, но не другие контейнеры. Эти (другие) контейнеры не используют те же ресурсы CPU. Как результат, мы ожидаем лучшей производительности благодаря изоляции в случаях появления «агрессора» (требовательных к ресурсам CPU процессов — прим. перев.) или соседствующей рабочей нагрузки.
- Снижается конкуренция за ресурсы, используемые рабочей нагрузкой, поскольку мы можем разделить CPU по самим нагрузкам. Эти ресурсы могут включать в себя не только CPU, но и иерархии кэшей, и пропускную способность памяти. Таким образом улучшается производительность рабочих нагрузок в целом.
- CPU Manager назначает CPU в топологическом порядке, основываясь на наилучших доступных вариантах. Если целый сокет свободен, он назначит все его CPU рабочей нагрузке. Так улучшается производительность рабочей нагрузки благодаря отсутствию трафика между сокетами.
- Контейнеры в подах с Guaranteed QoS подлежат ограничению по CFS quota. Рабочие нагрузки, склонные к резким всплескам, могут быть запланированы и превысить свою квоту до окончания выделенного им периода, в результате чего — погашены (throttled). У задействованных в это время CPU может быть как значимая, так и не очень полезная работа. Однако такие контейнеры не будут подвержены CFS throttling, когда CPU quota дополнена политикой распределения выделенных CPU.
Ок! Есть ли у вас какие-то результаты?
Чтобы увидеть в действии улучшения производительности и изоляцию, предоставляемую включением CPU Manager в Kubelet, мы провели эксперименты на вычислительном узле с двумя сокетами (Intel Xeon CPU E5-2680 v3) и включённым hyperthreading. Узел состоит из 48 логических CPU (24 физических ядра, каждое с hyperthreading). Ниже показана польза от CPU Manager в производительности и изоляции, зафиксированная benchmark'ами и рабочими нагрузками из реальной жизни в трёх различных сценариях.
Как интерпретировать графики?
Для каждого сценария показаны графики (диаграммы размаха, box plots), иллюстрирующие нормализованное время исполнения и его вариативность при запуске benchmark'а или реальной нагрузки с включенным и выключенным CPU Manager. Исполняемое время нормализовано к лучшим по производительности запускам (1.00 на оси Y представляет лучшее время запуска: чем меньше значение графика, тем лучше). Высота участка на графике показывает вариативность в производительности. Например, если участок — линия, то вариативность в производительности для этих запусков отсутствует. На самих этих участках средняя линия — медиана, верхняя — 75-й процентиль, а нижняя — 25-й процентиль. Высота участка (т.е. разница между 75-м и 25-м процентилями) определена как интерквартильный интервал (IQR). «Усы» показывают данные вне этого интервала, а точки — выбросы. Выбросы определены как любые данные, отличающиеся от IQR в 1,5 раза — меньше или больше соответствующего квартиля. Каждый эксперимент был проведен 10 раз.
Защита от нагрузок-агрессоров
Мы запустили шесть benchmark'ов из набора PARSEC (рабочие нагрузки-«жертвы») [подробнее о victim workloads можно почитать, например, здесь — прим. перев.] по соседству с контейнером, нагружающим CPU (рабочая нагрузка-«агрессор») с включённым и выключенным CPU Manager.
Контейнер-агрессор запущен как под с QoS-классом Burstable, запрашивающим 23 CPU флагом --cpus 48. Benchmark'и запущены как поды с QoS-классом Guaranteed, требующим набора CPU из полного сокета (т.е. 24 CPU на этой системе). На графиках ниже показано нормализованное время запуска пода с benchmark'ом по соседству с подом-агрессором, с политикой Static у CPU Manager и без неё. Во всех случаях тестирования можно увидеть улучшенную производительность и сниженную вариативность в производительности при включённой политике.

Изоляция для соседствующих нагрузок
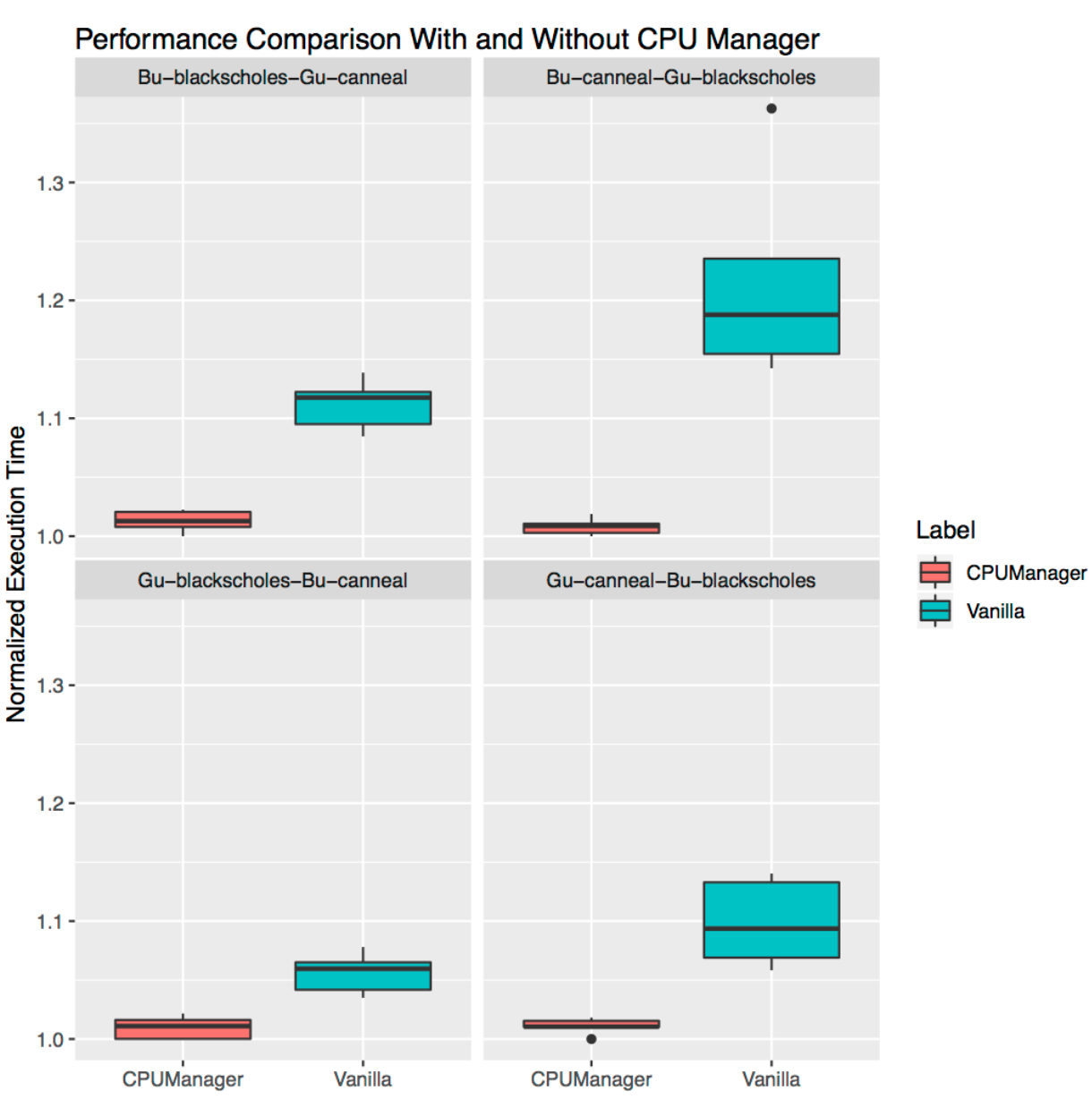
Здесь продемонстрировано, как полезен может быть CPU Manager для случая множества совместно размещённых рабочих нагрузок. На диаграммах размаха ниже показана производительность двух benchmark'ов из набора PARSEC (Blackscholes и Canneal), запущенных для QoS-классов Guaranteed (Gu) и Burstable (Bu), соседствующих друг с другом, с включённой и выключенной политикой Static.
Следуя по часовой стрелке с верхнего левого графика, мы видим производительность Blackscholes для Bu QoS (верхний левый), Canneal для Bu QoS (верхний правый), Canneal для Gu QoS (нижний правый) и Blackscholes для Gu QoS (нижний левый). На каждом из графиков они расположены (снова идём по часовой стрелке) совместно с Canneal для Gu QoS (верхний левый), Blackscholes для Gu QoS (верхний правый), Blackscholes для Bu QoS (нижний правый) и Canneal для Bu QoS (нижний левый) соответственно. Например, график Bu-blackscholes-Gu-canneal (верхний левый) показывает производительность для Blackscholes, запущенных с Bu QoS и расположенных рядом с Canneal с классом Gu QoS. В каждом случае под с классом Gu QoS требует ядра полного сокета (т.е. 24 CPU), а под с классом Bu QoS — 23 CPU.
Наблюдается лучшая производительность и меньший разброс в производительности для обеих соседствующих рабочих нагрузок во всех тестах. Например, посмотрите на Bu-blackscholes-Gu-canneal (верхний левый) и Gu-canneal-Bu-blackscholes (нижний правый). Они показывают производительность одновременно запущенных Blackscholes и Canneal с включённым и выключенным CPU Manager. В данном случае Canneal получает больше выделенных ядер от CPU Manager, поскольку он относится к классу Gu QoS и запрашивает целое число ядер CPU. Однако и Blackscholes получает выделенный набор CPU, поскольку это единственная рабочая нагрузка в разделяемом пуле. В результате, и Blackscholes, и Canneal пользуются преимуществами изоляции нагрузок в случае применения CPU Manager.
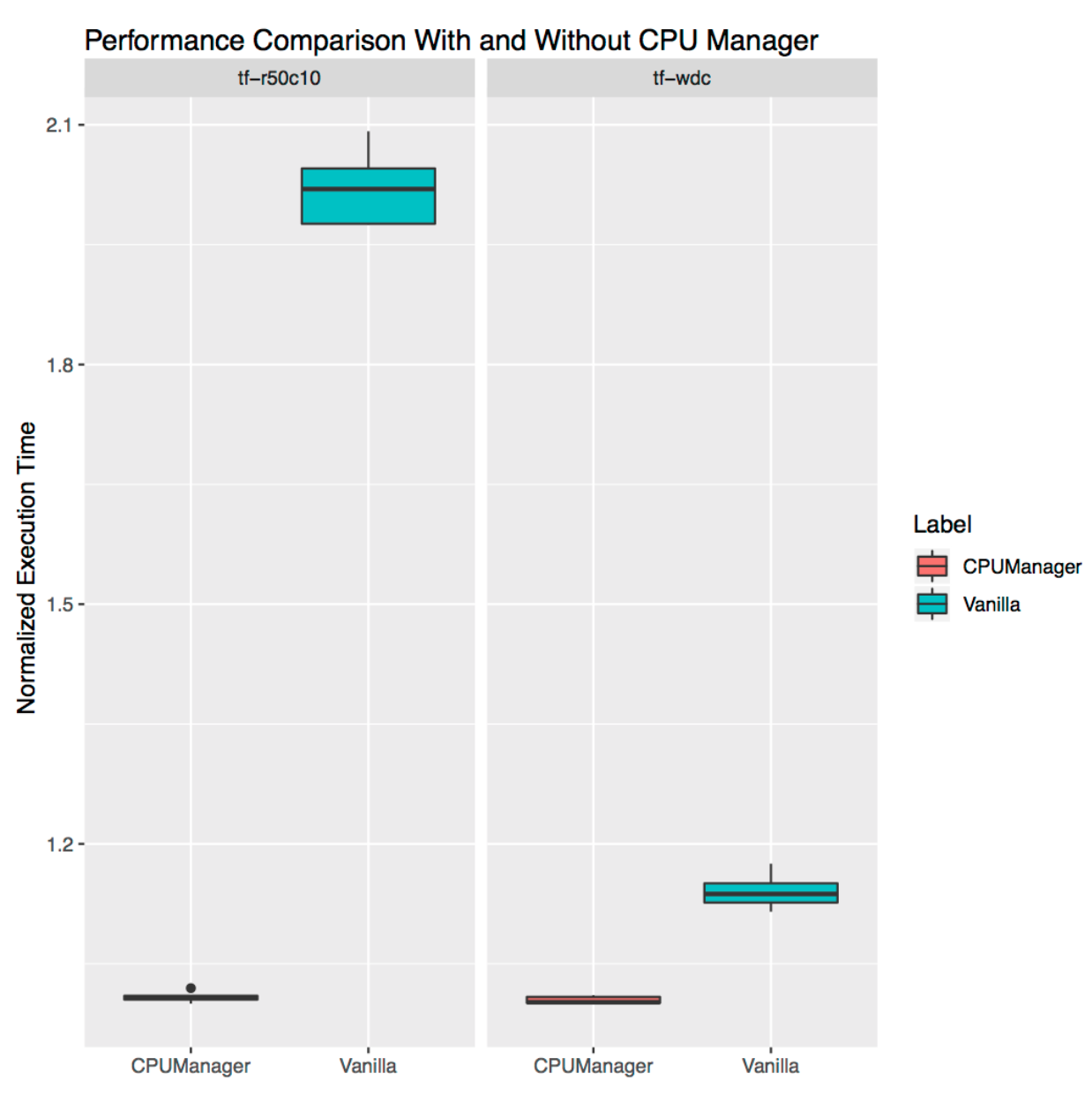
Изоляция для отдельно стоящих нагрузок
Здесь продемонстрировано, как полезен может быть CPU Manager для отдельно стоящих рабочих нагрузок из реальной жизни. Мы взяли две нагрузки из официальных моделей TensorFlow: wide and deep и ResNet. Для них используются типовые наборы данных (census и CIFAR10 соответственно). В обоих случаях поды (wide and deep, ResNet) требуют 24 CPU, что соответствует полному сокету. Как показано на графиках, в обоих случаях CPU Manager обеспечивает лучшую изоляцию.
Ограничения
Пользователи могут захотеть получить CPU, выделенные на сокете поблизости к шине, соединяющей с внешним устройством вроде акселератора или высокопроизводительной сетевой карты, во избежание трафика между сокетами. Такой вид настройки пока не поддерживается в CPU Manager. Поскольку CPU Manager обеспечивает наилучшее возможное распределение CPU, принадлежащих сокету или физическому ядру, он чувствителен к крайним случаям и может привести к фрагментации. CPU Manager не учитывает параметр загрузки Linux-ядра
isolcpus, хотя он применяется как популярная практика для некоторых случаев (подробнее об этом параметре см., например, здесь — прим. перев.).
P.S. от переводчика
Читайте также в нашем блоге:
Комментариев нет:
Отправить комментарий